Counterfactual Reasoning for Fine-Grained Evidence Disentanglement in VideoQA
Pith reviewed 2026-06-27 16:54 UTC · model grok-4.3
The pith
A structural causal model with feature-level interventions disentangles causal visual evidence from confounders in VideoQA.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
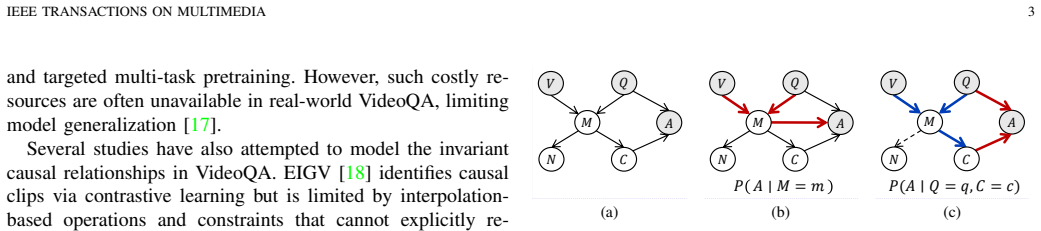
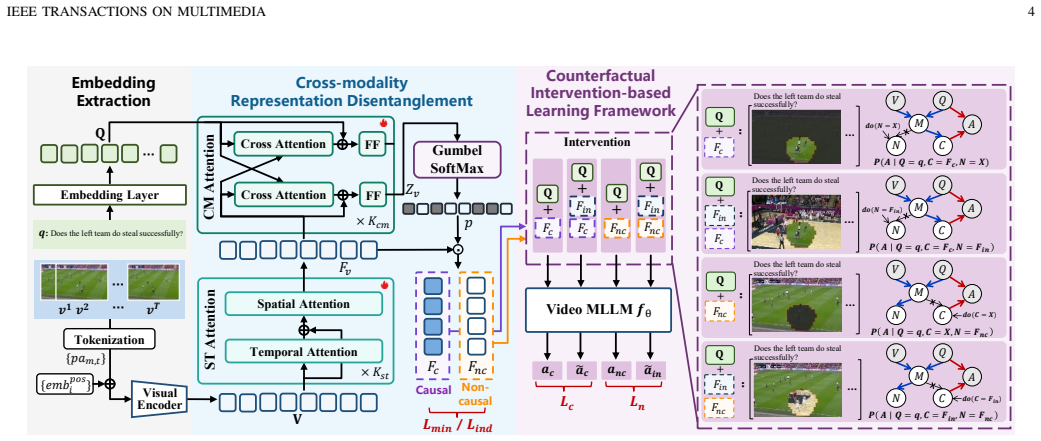
CREDiT formulates the VideoQA process using a structural causal model and learns cross-modality representations that are explicitly decomposed into causal and non-causal components under independence and minimality constraints. To facilitate faithful disentanglement, feature-level causal interventions construct counterfactual inputs that approximate causal effects while suppressing non-causal correlations.
What carries the argument
Feature-level causal interventions that construct counterfactual inputs to approximate causal effects while suppressing non-causal correlations within a structural causal model.
If this is right
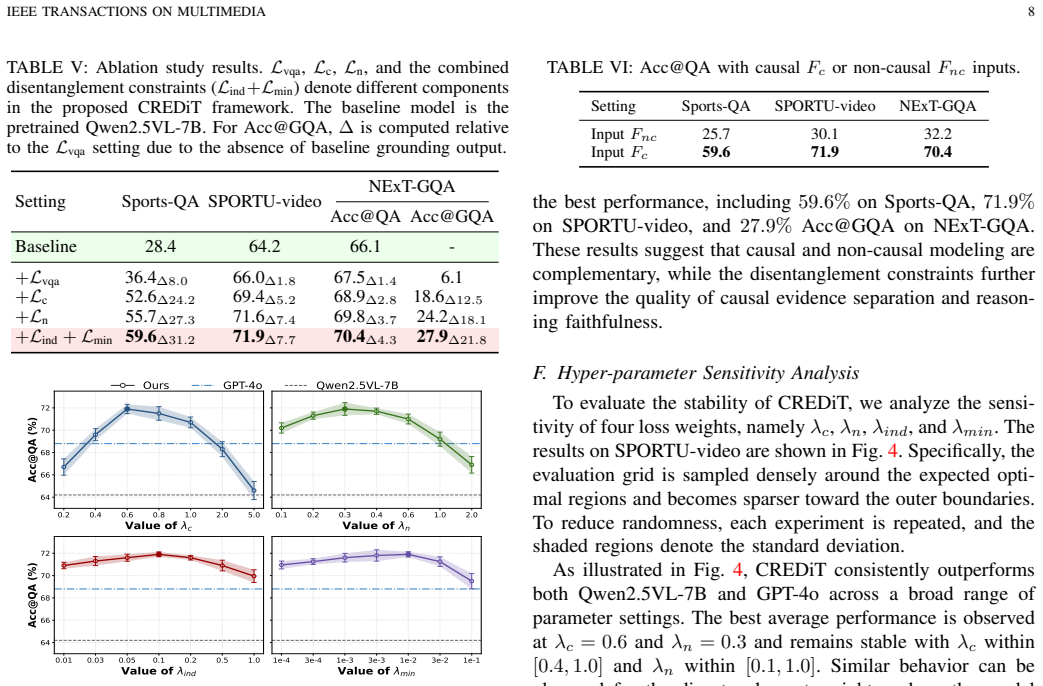
- Answer accuracy rises on NExT-GQA, SportsQA, and SPORTU-video.
- Reasoning reliability improves across both generic and complex sports scenarios.
- Fine-grained evidence localization becomes feasible at the feature level.
- VideoQA systems gain trustworthiness by depending on causal evidence rather than statistical shortcuts.
Where Pith is reading between the lines
- The same decomposition could apply to other multimodal tasks that suffer from spurious correlations, such as image captioning or visual grounding.
- If the interventions prove robust, the need for large curated causal datasets might decrease.
- Extending the approach to temporal sequences longer than current benchmarks would test whether the fine-grained disentanglement scales.
Load-bearing premise
The structural causal model accurately captures the VideoQA generative process and that feature-level causal interventions can construct counterfactual inputs that approximate causal effects while suppressing non-causal correlations.
What would settle it
A controlled test in which the decomposed causal components fail to improve accuracy over a non-causal baseline or where the constructed counterfactuals do not suppress the same spurious correlations identified in the original model.
Figures


read the original abstract
Recent advances in video multimodal models have significantly improved VideoQA performance. However, these systems often rely on spurious statistical correlations rather than answer-relevant causal evidence, resulting in unfaithful and brittle reasoning, especially in complex real-world scenarios. Existing methods either rely on cross-modality correlations, costly curated training resources, or insufficient causal assumptions and constraints, and typically operate at the time-interval level. As a result, they fail to explicitly disentangle causal visual cues from confounders and provide limited fine-grained evidence localization. To address this issue, we propose a Counterfactual Reasoning framework for fine-grained Evidence Disentanglement (CREDiT). CREDiT formulates the VideoQA process using a structural causal model and learns cross-modality representations that are explicitly decomposed into causal and non-causal components under independence and minimality constraints. To facilitate faithful disentanglement, we introduce feature-level causal interventions and construct counterfactual inputs that approximate causal effects while suppressing non-causal correlations. Extensive experiments on NExT-GQA, SportsQA, and SPORTU-video demonstrate that CREDiT consistently improves answer accuracy and reasoning reliability across both generic and complex sports scenarios, leading to more trustworthy VideoQA systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CREDiT, a counterfactual reasoning framework for fine-grained evidence disentanglement in VideoQA. It formulates the task with a structural causal model (SCM) that decomposes cross-modality representations into causal and non-causal components under independence and minimality constraints, introduces feature-level causal interventions to build counterfactual inputs, and reports improved answer accuracy plus reasoning reliability on NExT-GQA, SportsQA, and SPORTU-video.
Significance. If the SCM and interventions are shown to produce faithful causal separation rather than statistical regularization, the approach could meaningfully improve robustness of VideoQA systems against spurious correlations, especially in complex domains like sports. The multi-dataset evaluation and focus on fine-grained localization are positive aspects.
major comments (3)
- [§3] §3 (method): The central claim that feature-level interventions under the proposed SCM isolate answer-relevant causal evidence while suppressing non-causal correlations rests on the unverified assumption that the chosen causal graph accurately captures all relevant confounders in the VideoQA generative process. No explicit validation, sensitivity analysis, or alternative graph specifications are provided to rule out misspecification.
- [§4] §4 (experiments): Reported accuracy gains on NExT-GQA and SportsQA are presented without ablation isolating the contribution of the counterfactual construction versus the independence/minimality losses or auxiliary objectives. This leaves open whether performance improvements arise from causal disentanglement or from standard regularization effects.
- [Abstract, §4.2] Abstract and §4.2: The claim of 'faithful disentanglement' and 'more trustworthy' reasoning is supported only by aggregate accuracy and reliability metrics; no error analysis, qualitative inspection of learned causal vs. non-causal features, or counterfactual intervention diagnostics are described to confirm that the constructed inputs approximate true causal effects.
minor comments (2)
- [§3] Notation for the SCM variables and intervention operator should be introduced with explicit equations early in §3 to allow readers to trace how independence constraints are enforced.
- [Abstract] The abstract states gains 'across both generic and complex sports scenarios' but does not quantify the difference in improvement magnitude between the two regimes; a table breaking this down would strengthen the claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment point by point below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [§3] The central claim that feature-level interventions under the proposed SCM isolate answer-relevant causal evidence while suppressing non-causal correlations rests on the unverified assumption that the chosen causal graph accurately captures all relevant confounders in the VideoQA generative process. No explicit validation, sensitivity analysis, or alternative graph specifications are provided to rule out misspecification.
Authors: The SCM is specified according to the standard VideoQA generative process, with causal paths from answer-relevant evidence and non-causal paths through confounders; the independence and minimality constraints are applied to enforce separation under this graph. We agree that additional validation would strengthen the presentation. In the revised manuscript we will add a sensitivity analysis over plausible alternative graph structures and report the resulting performance variations. revision: yes
-
Referee: [§4] Reported accuracy gains on NExT-GQA and SportsQA are presented without ablation isolating the contribution of the counterfactual construction versus the independence/minimality losses or auxiliary objectives. This leaves open whether performance improvements arise from causal disentanglement or from standard regularization effects.
Authors: The current experiments contain ablations on the loss terms. To isolate the specific contribution of the feature-level counterfactual interventions, we will add a new ablation in the revision that holds the independence and minimality losses fixed while removing the intervention mechanism. revision: yes
-
Referee: [Abstract, §4.2] The claim of 'faithful disentanglement' and 'more trustworthy' reasoning is supported only by aggregate accuracy and reliability metrics; no error analysis, qualitative inspection of learned causal vs. non-causal features, or counterfactual intervention diagnostics are described to confirm that the constructed inputs approximate true causal effects.
Authors: The quantitative metrics show consistent gains, yet we concur that qualitative and diagnostic evidence would better support the disentanglement claims. The revised manuscript will include visualizations of the learned causal and non-causal features, an error analysis on selected failure and success cases, and intervention diagnostics that measure prediction changes under the constructed counterfactuals. revision: yes
Circularity Check
No circularity; derivation relies on external dataset validation
full rationale
The paper introduces CREDiT via an SCM formulation, independence/minimality constraints, and feature-level interventions to produce counterfactuals for disentanglement. These steps are presented as modeling choices whose validity is assessed through accuracy and reliability gains on held-out benchmarks (NExT-GQA, SportsQA, SPORTU-video). No equations or claims reduce a prediction to a fitted input by construction, no self-citation chain is load-bearing for the core premise, and no ansatz or uniqueness result is imported from prior author work. The derivation chain is therefore self-contained against external empirical benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption VideoQA process can be formulated using a structural causal model
- domain assumption Independence and minimality constraints suffice to separate causal from non-causal components
Reference graph
Works this paper leans on
-
[1]
Video-LLaV A: Learning United Visual Representation by Alignment Before Projection
B. Lin, Y . Ye, B. Zhu, J. Cui, M. Ning, P. Jin, and L. Yuan, “Video-llava: Learning united visual representation by alignment before projection,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2024, p. 5971–5984. [Online]. Available: http://dx.doi.org/10.18653/v1/2024.e...
-
[2]
arXiv preprint arXiv:2407.00634 (2024)
J. Wang, L. Yuan, Y . Zhang, and H. Sun, “Tarsier: Recipes for training and evaluating large video description models,”arXiv, 2024. [Online]. Available: https://arxiv.org/abs/2407.00634 1, 6
-
[3]
M. Arjovsky, L. Bottou, I. Gulrajani, and D. Lopez-Paz, “Invariant risk minimization,”arXiv, 2019. [Online]. Available: https://arxiv.org/abs/ 1907.02893 1, 4
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[4]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models
W. Chen, Y . Liu, B. Chen, J. Su, Y . Zheng, and L. Lin, “Cross-modal causal relation alignment for video question grounding,” in2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Jun. 2025, p. 24087–24096. [Online]. Available: http://dx.doi.org/10.1109/cvpr52734.2025.02243 1, 2, 3, 6, 7
-
[5]
Can i trust your answer? visually grounded video question answering,
J. Xiao, A. Yao, Y . Li, and T.-S. Chua, “Can i trust your answer? visually grounded video question answering,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 13 204–13 214. 1, 2, 5, 6, 7
2024
-
[6]
Sports-qa: A large-scale video question answering benchmark for complex and professional sports,
H. Li, A. Deng, J. Liu, H. Rahmani, Y . Guo, B. Schiele, M. Ben- namoun, and Q. Ke, “Sports-qa: A large-scale video question answering benchmark for complex and professional sports,”International Journal of Computer Vision, vol. 134, no. 5, p. 196, 2026. 1, 5, 6
2026
-
[7]
K. Kim, G. Park, Y . Lee, W. Yeo, and S. J. Hwang, “Videoicl: Confidence-based iterative in-context learning for out-of-distribution video understanding,”arXiv, 2024. [Online]. Available: https://arxiv. org/abs/2412.02186 1, 6
-
[8]
Leadqa: Llm-driven context-aware temporal grounding for video ques- tion answering,
X. Dong, B. Peng, H. Ma, Y . Wang, Z. Dong, F. Hu, and X. Wang, “Leadqa: Llm-driven context-aware temporal grounding for video ques- tion answering,”arXiv preprint arXiv:2507.14784, 2025. 1, 2, 6, 7
-
[9]
A simple llm framework for long-range video question- answering,
C. Zhang, T. Lu, M. M. Islam, Z. Wang, S. Yu, M. Bansal, and G. Bertasius, “A simple llm framework for long-range video question- answering,” inProceedings of the 2024 Conference on Empirical Meth- ods in Natural Language Processing, 2024, pp. 21 715–21 737. 1, 2, 6, 7
2024
-
[10]
Tubedetr: Spatio- temporal video grounding with transformers,
A. Yang, A. Miech, J. Sivic, I. Laptev, and C. Schmid, “Tubedetr: Spatio- temporal video grounding with transformers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 442–16 453. 1
2022
-
[11]
Streaming long video understanding with large language models,
R. Qian, X. Dong, P. Zhang, Y . Zang, S. Ding, D. Lin, and J. Wang, “Streaming long video understanding with large language models,”Ad- vances in Neural Information Processing Systems, vol. 37, pp. 119 336– 119 360, 2024. 1, 7
2024
-
[12]
H. Wang, C. Lai, and W. Ge, “Adapting multimodal large language models for video question answering by capturing question-critical and coherent moments,”IEEE Transactions on Multimedia, vol. 27, p. 8737–8747, 2025. [Online]. Available: http://dx.doi.org/10.1109/tmm. 2025.3607780 1, 2
work page doi:10.1109/tmm 2025
-
[13]
Toga: Temporally grounded open-ended video qa with weak supervision,
A. Gupta, A. Roy, R. Chellappa, N. D. Bastian, A. Velasquez, and S. Jha, “Toga: Temporally grounded open-ended video qa with weak supervision,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 23 593–23 603. 1, 2, 6, 7
2025
-
[14]
Grounding answers for visual questions asked by visually impaired people,
C. Chen, S. Anjum, and D. Gurari, “Grounding answers for visual questions asked by visually impaired people,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2022, pp. 19 098–19 107. 2
2022
-
[15]
Self-chained image-language model for video localization and question answering,
S. Yu, J. Cho, P. Yadav, and M. Bansal, “Self-chained image-language model for video localization and question answering,”Advances in Neural Information Processing Systems, vol. 36, pp. 76 749–76 771,
-
[16]
Videochat-r1.5: Visual test-time scaling to reinforce multimodal reasoning by iterative perception,
Z. Yan, Y . He, X. Li, Z. Yue, X. Zeng, Y . Wang, Y . Qiao, L. Wang, and Y . Wang, “Videochat-r1.5: Visual test-time scaling to reinforce multimodal reasoning by iterative perception,” inAdvances in Neural Information Processing Systems, D. Belgrave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghassemi, and N. Chen, Eds., IEEE TRANSACTIONS ON MULTIMEDIA ...
2025
-
[17]
Ravl: Discovering and mitigating spurious correlations in fine-tuned vision-language models,
A. Chaudhari, Z. Chen, J.-B. Delbrouck, C. Langlotz, and M. Varma, “Ravl: Discovering and mitigating spurious correlations in fine-tuned vision-language models,” inAdvances in Neural Information Processing Systems 37, ser. NeurIPS 2024. Neural Information Processing Systems Foundation, Inc. (NeurIPS), 2024, p. 82235–82264. [Online]. Available: http://dx.d...
-
[18]
Equivariant and invariant grounding for video question answering,
Y . Li, X. Wang, J. Xiao, and T.-S. Chua, “Equivariant and invariant grounding for video question answering,” inProceedings of the ACM International Conference on Multimedia, 2022, pp. 4714–4722. 2, 3
2022
-
[19]
Tgif-qa: Toward spatio- temporal reasoning in visual question answering,
Y . Jang, Y . Song, Y . Yu, Y . Kim, and G. Kim, “Tgif-qa: Toward spatio- temporal reasoning in visual question answering,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 2758–2766. 2
2017
-
[20]
Motion-appearance co-memory networks for video question answering,
J. Gao, R. Ge, K. Chen, and R. Nevatia, “Motion-appearance co-memory networks for video question answering,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 6576–
2018
-
[21]
Heterogeneous memory enhanced multimodal attention model for video question answering,
C. Fan, X. Zhang, S. Zhang, W. Wang, C. Zhang, and H. Huang, “Heterogeneous memory enhanced multimodal attention model for video question answering,” inProceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition, 2019, pp. 1999–2007. 2, 6
2019
-
[22]
Reasoning with heterogeneous graph alignment for video question answering,
P. Jiang and Y . Han, “Reasoning with heterogeneous graph alignment for video question answering,” inProceedings of the AAAI Conference on Artificial Intelligence, 2020, pp. 11 109–11 116. 2, 6
2020
-
[23]
Next-qa: Next phase of question-answering to explaining temporal actions,
J. Xiao, X. Shang, A. Yao, and T.-S. Chua, “Next-qa: Next phase of question-answering to explaining temporal actions,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, June 2021, pp. 9777–9786. 2, 6
2021
-
[24]
Mvbench: A comprehensive multi-modal video understanding benchmark,
K. Li, Y . Wang, Y . He, Y . Li, Y . Wang, Y . Liu, Z. Wang, J. Xu, G. Chen, P. Luoet al., “Mvbench: A comprehensive multi-modal video understanding benchmark,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2024, pp. 22 195–22 206. 2, 6
2024
-
[25]
Attention is all you need,
A. Vaswani, N. M. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems, vol. 30, 2017, pp. 5998–6008. [Online]. Available: https://api.semanticscholar. org/CorpusID:13756489 2, 3
2017
-
[26]
Violet: End-to-end video-language transformers with masked visual- token modeling,
T.-J. Fu, L. Li, Z. Gan, K. Lin, W. Y . Wang, L. Wang, and Z. Liu, “Violet: End-to-end video-language transformers with masked visual- token modeling,”arXiv preprint arXiv:2111.12681, 2021. 2
-
[27]
Video graph transformer for video question answering,
J. Xiao, P. Zhou, T.-S. Chua, and S. Yan, “Video graph transformer for video question answering,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 39–58. 2, 7
2022
-
[28]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
M. Maaz, H. Rasheed, S. Khan, and F. S. Khan, “Video-chatgpt: Towards detailed video understanding via large vision and language models,” arXiv, 2023. [Online]. Available: https://arxiv.org/abs/2306.05424 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y . Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y . Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin, “Qwen2.5-vl technical report,”CoRR, vol. abs/2502.13923, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2502.13923 2, 6
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923 2025
-
[30]
Tall: Temporal activity local- ization via language query,
J. Gao, C. Sun, Z. Yang, and R. Nevatia, “Tall: Temporal activity local- ization via language query,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 5267–5275. 2
2017
-
[31]
Multilevel language and vision integration for text-to-clip retrieval,
H. Xu, K. He, B. A. Plummer, L. Sigal, S. Sclaroff, and K. Saenko, “Multilevel language and vision integration for text-to-clip retrieval,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 9062–9069. 2
2019
-
[32]
Query-dependent video representation for moment retrieval and highlight detection,
W. Moon, S. Hyun, S. Park, D. Park, and J.-P. Heo, “Query-dependent video representation for moment retrieval and highlight detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 23 023–23 033. 2
2023
-
[33]
Tvqa+: Spatio-temporal ground- ing for video question answering,
J. Lei, L. Yu, T. Berg, and M. Bansal, “Tvqa+: Spatio-temporal ground- ing for video question answering,” inProceedings of the 58th annual meeting of the association for computational linguistics, 2020, pp. 8211–
2020
-
[34]
H. Fei, S. Wu, W. Ji, H. Zhang, M. Zhang, M.-L. Lee, and W. Hsu, “Video-of-thought: Step-by-step video reasoning from perception to cognition,”arXiv preprint arXiv:2501.03230, 2024. 2
-
[35]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models
H. Liu, F. Ilievski, and C. G. M. Snoek, “Commonsense video question answering through video-grounded entailment tree reasoning,” in2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Jun. 2025, p. 3262–3271. [Online]. Available: http://dx.doi.org/10.1109/cvpr52734.2025.00310 2
-
[36]
arXiv preprint arXiv:2410.03290 , year =
H. Wang, Z. Xu, Y . Cheng, S. Diao, Y . Zhou, Y . Cao, Q. Wang, W. Ge, and L. Huang, “Grounded-videollm: Sharpening fine-grained temporal grounding in video large language models,”arXiv preprint arXiv:2410.03290, 2024. 2, 7
-
[37]
Causal inference in statistics: An overview,
J. Pearl, “Causal inference in statistics: An overview,”Statistics Surveys, vol. 3, pp. 96–146, 2009. 3, 4
2009
-
[38]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A frontier large vision-language model with versatile abilities,”arXiv, 2023. [Online]. Available: https://arxiv.org/abs/2308.12966 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Is space-time attention all you need for video understanding?
G. Bertasius, H. Wang, and L. Torresani, “Is space-time attention all you need for video understanding?” inInternational Conference on Machine Learning, 2021, pp. 813–824. 4
2021
-
[40]
Categorical reparameterization with gumbel-softmax,
E. Jang, S. Gu, and B. Poole, “Categorical reparameterization with gumbel-softmax,”International Conference on Learning Representa- tions, Nov 2016. 4
2016
-
[41]
Measuring statistical dependence with hilbert-schmidt norms,
A. Gretton, O. Bousquet, A. Smola, and B. Sch ¨olkopf, “Measuring statistical dependence with hilbert-schmidt norms,” inInternational conference on algorithmic learning theory. Springer, 2005, pp. 63–
2005
-
[42]
Z. Yang, H. Xia, J. Li, Z. Chen, Z. Zhu, and W. Shen, “Sports intelligence: Assessing the sports understanding capabilities of language models through question answering from text to video,”arXiv, 2024. [Online]. Available: https://arxiv.org/abs/2406.14877 5, 6, 7
-
[43]
Sportu: A comprehensive sports understanding benchmark for multimodal large language models,
H. Xia, Z. Yang, J. Zou, R. Tracy, Y . Wang, C. Lu, C. Lai, Y . He, X. Shao, Z. Xieet al., “Sportu: A comprehensive sports understanding benchmark for multimodal large language models,”arXiv, 2024. [Online]. Available: https://arxiv.org/abs/2410.08474 6
-
[44]
Invariant grounding for video question answering,
Y . Li, X. Wang, J. Xiao, W. Ji, and T.-S. Chua, “Invariant grounding for video question answering,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2022, pp. 2928–2937. 6, 7
2022
-
[45]
Video as conditional graph hierarchy for multi-granular question answering,
J. Xiao, A. Yao, Z. Liu, Y . Li, W. Ji, and T.-S. Chua, “Video as conditional graph hierarchy for multi-granular question answering,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2022, pp. 2804–2812. 6
2022
-
[46]
Attend what you need: Motion-appearance synergistic networks for video question answering,
A. Seo, G.-C. Kang, J. Park, and B.-T. Zhang, “Attend what you need: Motion-appearance synergistic networks for video question answering,” arXiv, 2021. [Online]. Available: https://arxiv.org/abs/2106.10446 6
-
[47]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Y . Zhang, J. Wu, W. Li, B. Li, Z. Ma, Z. Liu, and C. Li, “Video instruction tuning with synthetic data,”arXiv, 2024. [Online]. Available: https://arxiv.org/abs/2410.02713 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Geet al., “Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution,”arXiv preprint arXiv:2409.12191, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Introducing the next generation of claude,
Anthropic, “Introducing the next generation of claude,” Online, March 2024, [EB/OL], Accessed: 2024-04-19. [Online]. Available: https://www.anthropic.com/news/claude-3-family 6
2024
-
[50]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,
G. Team, P. Georgiev, V . I. Lei, R. Burnell, L. Bai, A. Gulati, G. Tanzer, D. Vincent, Z. Pan, S. Wanget al., “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,”arXiv,
-
[51]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
[Online]. Available: https://arxiv.org/abs/2403.05530 6
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Hello gpt-4o,
OpenAI, “Hello gpt-4o,” Online, 2024. [Online]. Available: https: //openai.com/index/hello-gpt-4o/ 6
2024
-
[53]
Llava-next: Improved reasoning, ocr, and world knowledge,
H. Liu, C. Li, Y . Li, B. Li, Y . Zhang, S. Shen, and Y . J. Lee, “Llava-next: Improved reasoning, ocr, and world knowledge,” Online, January 2024. [Online]. Available: https://llava-vl.github.io/ blog/2024-01-30-llava-next/ 6
2024
-
[54]
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
X. Li, Z. Yan, D. Meng, L. Dong, X. Zeng, Y . He, Y . Wang, Y . Qiao, Y . Wang, and L. Wang, “Videochat-r1: Enhancing spatio-temporal per- ception via reinforcement fine-tuning,”arXiv preprint arXiv:2504.06958,
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
An empirical study of end-to-end video-language transformers with masked visual modeling,
T.-J. Fu, L. Li, Z. Gan, K. Lin, W. Y . Wang, L. Wang, and Z. Liu, “An empirical study of end-to-end video-language transformers with masked visual modeling,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 22 898–22 909. 7
2023
-
[56]
Timecraft: Navigate weakly-supervised temporal grounded video question answering via bi- directional reasoning,
H. Liu, X. Ma, C. Zhong, Y . Zhang, and W. Lin, “Timecraft: Navigate weakly-supervised temporal grounded video question answering via bi- directional reasoning,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 92–107. 7
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.