Temporal-Aware Reasoning Optimization for Video Temporal Grounding
Pith reviewed 2026-06-27 17:19 UTC · model grok-4.3
The pith
TaRO improves video temporal grounding in MLLMs by constructing timestamped reasoning paths and rewarding sensitivity to event boundaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
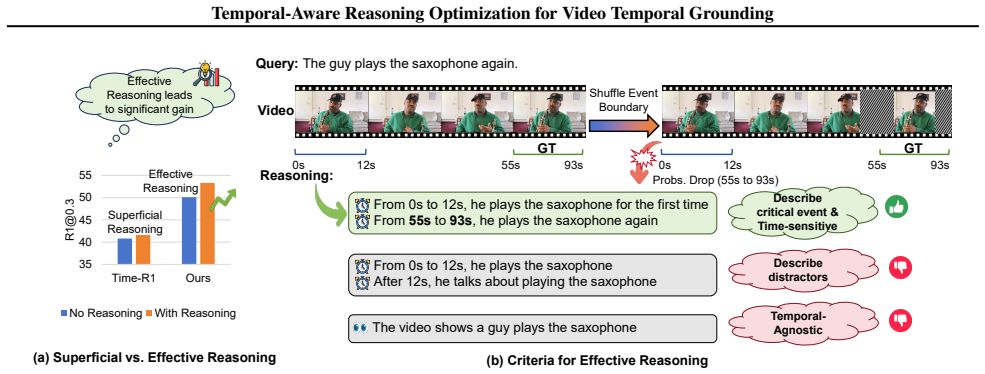
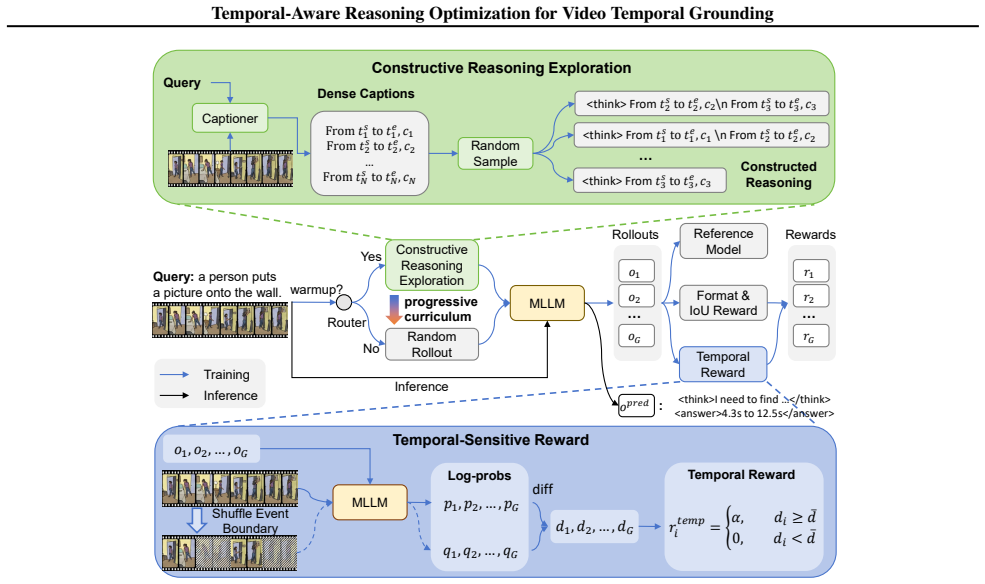
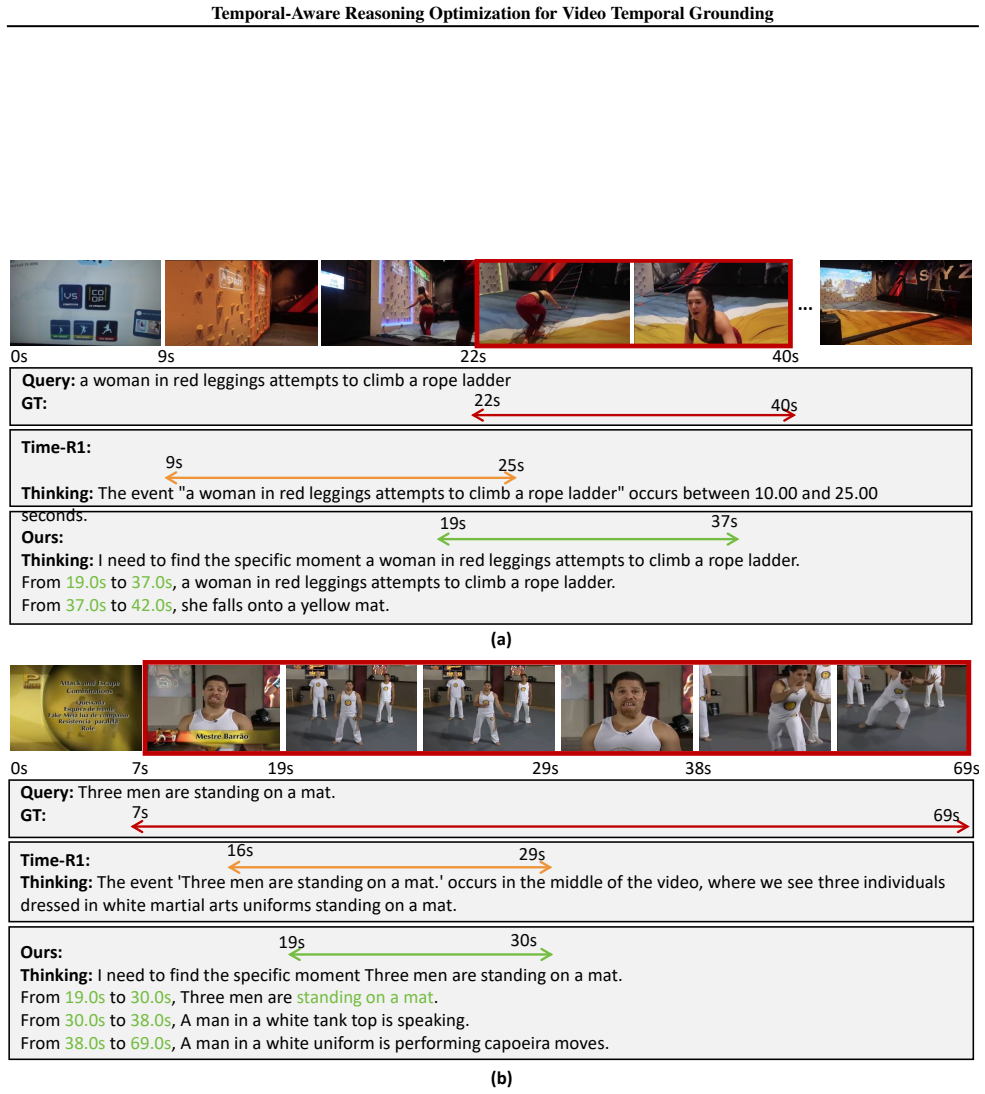
The central claim is that explicitly enhancing the model's ability of thinking with time, by leveraging pre-generated dense captions to construct reasoning paths grounded in visual cues and timestamps and by using the drop in logit of the reasoning path when the event boundary is disrupted as a critique of reasoning quality, produces more precise temporal localization.
What carries the argument
The Temporal-Sensitivity Reward, which evaluates reasoning quality by measuring the drop in the logit of the reasoning path when the event boundary under thinking is disrupted.
Load-bearing premise
The assumption that a drop in the logit of a reasoning path when an event boundary is disrupted constitutes a valid and reliable critique of reasoning quality.
What would settle it
An experiment that measures whether logit drops from boundary disruptions consistently predict better localization accuracy, or finds drops occurring for low-quality reasoning or absent for high-quality reasoning, would settle whether the reward works as claimed.
Figures


read the original abstract
Multi-modal Large Language Models (MLLMs) have achieved remarkable progress in video temporal grounding with reinforcement learning for generating reasoning paths. However, existing models often produce superficial reasoning, which offers limited guidance for precise temporal localization. This limitation stems from (1) inefficient random exploration and (2) reward functions that focus solely on the answer correctness while ignoring reasoning quality. To address these issues, we propose TaRO (Temporal-Aware Reasoning Optimization), a framework that explicitly enhances the model's ability of thinking with time. First, we introduce a Constructive Reasoning Exploration that leverages pre-generated dense captions to construct reasoning paths grounded in explicit visual cues and timestamps, enabling efficient exploration of high-quality time-aware reasoning. Second, to evaluate reasoning quality, we design a Temporal-Sensitivity Reward. High-quality reasoning should be anchored to specific events and timestamps. If the event boundary under thinking is disrupted, such reasoning should become invalid, leading to a drop in the logit of the reasoning path. We utilize this drop as a critique of reasoning quality. Finally, TaRO follows a progressive curriculum, which starts by utilizing this reward to select better constructed reasoning paths, and evolves to a free exploration phase where the model autonomously generates effective reasoning. Experiments demonstrate that TaRO achieves state-of-the-art performance on VTG benchmarks. Code is available at https://github.com/oceanflowlab/TaRO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TaRO, a reinforcement learning framework for multi-modal LLMs on video temporal grounding tasks. It introduces Constructive Reasoning Exploration that uses pre-generated dense captions and timestamps to build grounded reasoning paths, a Temporal-Sensitivity Reward that scores reasoning quality via the logit drop induced by disrupting an event boundary, and a progressive curriculum that begins with reward-guided path selection before shifting to free exploration. The central claim is that these components together yield state-of-the-art performance on standard VTG benchmarks.
Significance. If the logit-drop signal can be shown to causally improve temporal localization rather than merely reflecting surface-level probability shifts, the reward design would constitute a concrete advance over answer-correctness-only rewards in RL for MLLMs. The public code release is a clear strength for reproducibility.
major comments (2)
- [Abstract and §3.2] Abstract (second paragraph) and §3.2 (Temporal-Sensitivity Reward definition): the claim that a logit drop upon boundary disruption specifically measures temporal anchoring is load-bearing for the SOTA attribution, yet the manuscript provides no correlation analysis between this drop and grounding metrics such as IoU or human-rated reasoning quality; without such evidence the performance gain cannot be causally linked to the proposed critique.
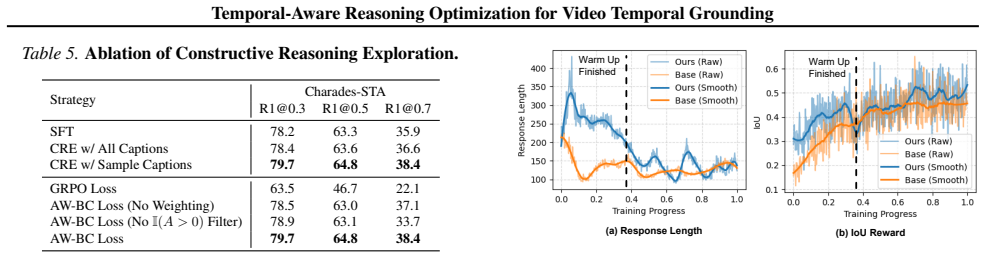
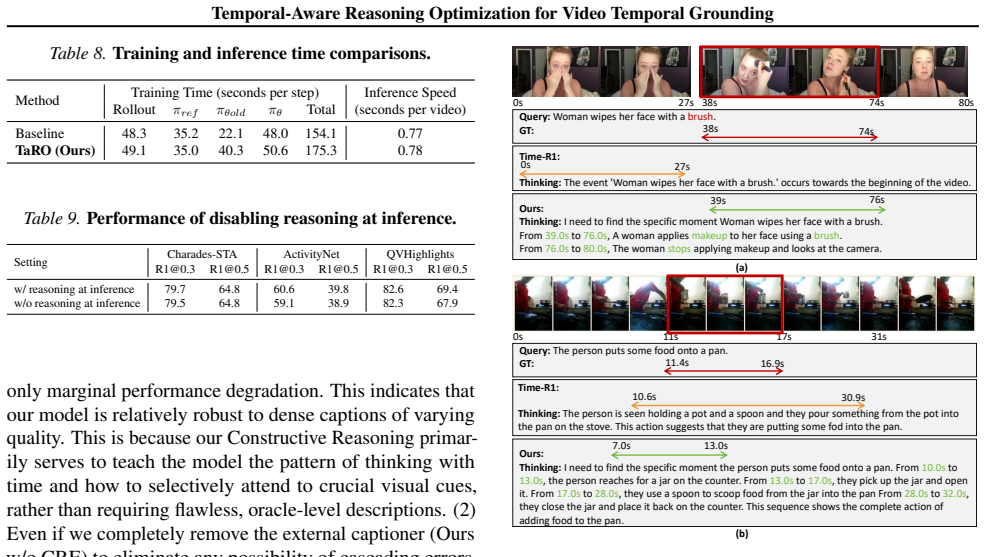
- [§4] §4 (Experiments): the SOTA claim on VTG benchmarks rests on comparisons and ablations that isolate the contribution of the Constructive Reasoning Exploration, the Temporal-Sensitivity Reward, and the curriculum schedule; if these tables or statistical tests are absent or under-powered, the central performance claim cannot be evaluated.
minor comments (1)
- [§3.2] Notation for the logit drop (e.g., how the disrupted path is constructed and which tokens are masked) should be formalized with an equation in §3.2 to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. Below we respond point-by-point to the major comments, providing clarifications from the existing experiments and committing to targeted revisions where they will strengthen the causal claims.
read point-by-point responses
-
Referee: [Abstract and §3.2] Abstract (second paragraph) and §3.2 (Temporal-Sensitivity Reward definition): the claim that a logit drop upon boundary disruption specifically measures temporal anchoring is load-bearing for the SOTA attribution, yet the manuscript provides no correlation analysis between this drop and grounding metrics such as IoU or human-rated reasoning quality; without such evidence the performance gain cannot be causally linked to the proposed critique.
Authors: We appreciate the referee's emphasis on establishing a stronger causal connection. The Temporal-Sensitivity Reward is motivated by the observation that high-quality time-aware reasoning paths should exhibit sensitivity to event boundaries; disrupting those boundaries renders the reasoning invalid and produces a logit drop. While §4 already shows that ablating this reward leads to measurable degradation on VTG benchmarks, we agree that an explicit correlation analysis would provide additional support. In the revised manuscript we will add a supplementary analysis reporting Pearson/Spearman correlations between per-example logit drops and IoU scores (and, where feasible, human ratings of reasoning quality) on the validation splits. revision: yes
-
Referee: [§4] §4 (Experiments): the SOTA claim on VTG benchmarks rests on comparisons and ablations that isolate the contribution of the Constructive Reasoning Exploration, the Temporal-Sensitivity Reward, and the curriculum schedule; if these tables or statistical tests are absent or under-powered, the central performance claim cannot be evaluated.
Authors: Section 4 already contains the requested isolation: Table 2 reports full benchmark comparisons against prior SOTA methods, while Tables 3–5 present controlled ablations that remove Constructive Reasoning Exploration, the Temporal-Sensitivity Reward, and the curriculum schedule one at a time, each with mean performance and standard deviation computed over three random seeds. These results directly quantify the contribution of each component to the final SOTA numbers. We therefore maintain that the experimental evidence is sufficient to evaluate the central claims. revision: no
Circularity Check
No significant circularity; components presented as independent additions
full rationale
The paper introduces TaRO via two explicitly described additions—Constructive Reasoning Exploration using pre-generated dense captions and a Temporal-Sensitivity Reward based on logit drop upon boundary disruption—without any equations, fitted parameters, or self-citations that reduce the claimed SOTA gains or reasoning quality metric back to quantities defined by the method itself. The abstract frames these as solutions to stated limitations in prior RL approaches, with final performance evaluated externally on VTG benchmarks; no load-bearing step collapses by construction to an input or self-referential definition.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pre-generated dense captions provide accurate visual cues and timestamps suitable for constructing high-quality reasoning paths.
- domain assumption A drop in the logit of a reasoning path when an event boundary is disrupted indicates poor reasoning quality.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Understanding and constructing latent modality structures in multi-modal representation learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[2]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mad: A scalable dataset for language grounding in videos from movie audio descriptions , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[3]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scanning only once: An end-to-end framework for fast temporal grounding in long videos , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[4]
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Ego4D: Around the World in 3,000 Hours of Egocentric Video , author=. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=. 2022 , organization=
2022
-
[5]
Proceedings of the IEEE international conference on computer vision , pages=
Tall: Temporal activity localization via language query , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[6]
Proceedings of the IEEE international conference on computer vision , pages=
Dense-captioning events in videos , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[7]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Learning 2d temporal adjacent networks for moment localization with natural language , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[8]
Proceedings of the AAAI Conference on Artificial Intelligence , pages=
To find where you talk: Temporal sentence localization in video with attention based location regression , author=. Proceedings of the AAAI Conference on Artificial Intelligence , pages=
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Local-global video-text interactions for temporal grounding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[10]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Localizing moments in long video via multimodal guidance , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[11]
arXiv preprint arXiv:2209.10918 , year=
Cone: An efficient coarse-to-fine alignment framework for long video temporal grounding , author=. arXiv preprint arXiv:2209.10918 , year=
-
[12]
2008 , publisher=
Aspects of Brownian motion , author=. 2008 , publisher=
2008
-
[13]
arXiv preprint arXiv:2203.11370 , year=
Language modeling via stochastic processes , author=. arXiv preprint arXiv:2203.11370 , year=
-
[14]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Modeling Video As Stochastic Processes for Fine-Grained Video Representation Learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[15]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Negative sample matters: A renaissance of metric learning for temporal grounding , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[16]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
Temporally grounding natural sentence in video , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[17]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Dense regression network for video grounding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[18]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[19]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Swin transformer: Hierarchical vision transformer using shifted windows , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[20]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[21]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Slowfast networks for video recognition , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[22]
Information retrieval , volume=
A general approximation framework for direct optimization of information retrieval measures , author=. Information retrieval , volume=. 2010 , publisher=
2010
-
[23]
Proceedings of the 24th ACM international conference on Multimedia , pages=
Unitbox: An advanced object detection network , author=. Proceedings of the 24th ACM international conference on Multimedia , pages=
-
[24]
arXiv preprint arXiv:1807.03748 , year=
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
-
[25]
arXiv preprint arXiv:1711.05101 , year=
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
-
[26]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Vlg-net: Video-language graph matching network for video grounding , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[27]
Advances in Neural Information Processing Systems , volume=
Detecting moments and highlights in videos via natural language queries , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
IEEE transactions on pattern analysis and machine intelligence , volume=
Natural language video localization: A revisit in span-based question answering framework , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2021 , publisher=
2021
-
[29]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Msr-vtt: A large video description dataset for bridging video and language , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[30]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Howto100m: Learning a text-video embedding by watching hundred million narrated video clips , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[31]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Activitynet-qa: A dataset for understanding complex web videos via question answering , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[32]
ICCV , year=
Just Ask: Learning To Answer Questions From Millions of Narrated Videos , author=. ICCV , year=
-
[33]
2016 IEEE 4th International Conference on Future Internet of Things and Cloud Workshops (FiCloudW) , pages=
A survey on network security monitoring systems , author=. 2016 IEEE 4th International Conference on Future Internet of Things and Cloud Workshops (FiCloudW) , pages=. 2016 , organization=
2016
-
[34]
and Al-Halah, Ziad and Grauman, Kristen and Grauman, Kristen , booktitle =
Ramakrishnan, Santhosh K. and Al-Halah, Ziad and Grauman, Kristen and Grauman, Kristen , booktitle =. NaQ: Leveraging Narrations as Queries to Supervise Episodic Memory , year =
-
[35]
Advances in Neural Information Processing Systems , volume=
Egocentric video-language pretraining , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
arXiv preprint arXiv:2207.00383 , year=
Reler@ zju-alibaba submission to the ego4d natural language queries challenge 2022 , author=. arXiv preprint arXiv:2207.00383 , year=
arXiv 2022
-
[37]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
SnAG: Scalable and Accurate Video Grounding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[38]
arXiv preprint arXiv:1810.04805 , year=
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. arXiv preprint arXiv:1810.04805 , year=
-
[39]
Advances in neural information processing systems , volume=
Momentdiff: Generative video moment retrieval from random to real , author=. Advances in neural information processing systems , volume=
-
[40]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Bridging the gap: A unified video comprehension framework for moment retrieval and highlight detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[41]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Towards balanced alignment: Modal-enhanced semantic modeling for video moment retrieval , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[42]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Multilevel language and vision integration for text-to-clip retrieval , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[43]
Advances in Neural Information Processing Systems , volume=
Semantic conditioned dynamic modulation for temporal sentence grounding in videos , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Temporally grounding language queries in videos by contextual boundary-aware prediction , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[45]
Proceedings of the AAAI Conference on Artificial Intelligence , pages=
Boundary proposal network for two-stage natural language video localization , author=. Proceedings of the AAAI Conference on Artificial Intelligence , pages=
-
[46]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Proposal-free video grounding with contextual pyramid network , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[47]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Structured multi-level interaction network for video moment localization via language query , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[48]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Context-aware biaffine localizing network for temporal sentence grounding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[49]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Adaptive proposal generation network for temporal sentence localization in videos , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[50]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
G2l: Semantically aligned and uniform video grounding via geodesic and game theory , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[51]
Proceedings of the 31st ACM International Conference on Multimedia , pages=
Temporal Sentence Grounding in Streaming Videos , author=. Proceedings of the 31st ACM International Conference on Multimedia , pages=
-
[52]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Cascaded prediction network via segment tree for temporal video grounding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[53]
Pattern Recognition: 36th German Conference, GCPR 2014, M
Coherent multi-sentence video description with variable level of detail , author=. Pattern Recognition: 36th German Conference, GCPR 2014, M. 2014 , organization=
2014
-
[54]
European Conference on Computer Vision , pages=
HAT: History-Augmented Anchor Transformer for Online Temporal Action Localization , author=. European Conference on Computer Vision , pages=. 2025 , organization=
2025
-
[55]
European Conference on Computer Vision , pages=
A sliding window scheme for online temporal action localization , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[56]
Computer Vision--ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part V 14 , pages=
Online action detection , author=. Computer Vision--ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part V 14 , pages=. 2016 , organization=
2016
-
[57]
ECCV , volume=
Online action detection in untrimmed, streaming videos-modeling and evaluation , author=. ECCV , volume=
-
[58]
Advances in Neural Information Processing Systems , volume=
Long short-term transformer for online action detection , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Temporal recurrent networks for online action detection , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[60]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Oadtr: Online action detection with transformers , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[61]
Pattern Recognition , volume=
Progressive privileged knowledge distillation for online action detection , author=. Pattern Recognition , volume=. 2022 , publisher=
2022
-
[62]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Learning to discriminate information for online action detection , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[63]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Gatehub: Gated history unit with background suppression for online action detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[64]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
E2e-load: end-to-end long-form online action detection , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[65]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Miniroad: Minimal rnn framework for online action detection , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[66]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Cag-qil: Context-aware actionness grouping via q imitation learning for online temporal action localization , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[67]
1994 , publisher=
Neural networks: a comprehensive foundation , author=. 1994 , publisher=
1994
-
[68]
arXiv preprint arXiv:1708.02002 , year=
Focal Loss for Dense Object Detection , author=. arXiv preprint arXiv:1708.02002 , year=
-
[69]
Faster and Better Learning for Bounding Box Regression., 2020, 34 , author=. DOI: https://doi. org/10.1609/aaai. v34i07 , volume=
-
[70]
Proceedings of the IEEE international conference on computer vision , pages=
Learning spatiotemporal features with 3d convolutional networks , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[71]
European Conference on Computer Vision (ECCV) , year=
Real-time Online Video Detection with Temporal Smoothing Transformers , author=. European Conference on Computer Vision (ECCV) , year=
-
[72]
arXiv preprint arXiv:1412.3555 , year=
Empirical evaluation of gated recurrent neural networks on sequence modeling , author=. arXiv preprint arXiv:1412.3555 , year=
-
[73]
and Bansal, Mohit , title =
Lei, Jie and Berg, Tamara L. and Bansal, Mohit , title =. Proceedings of the 35th International Conference on Neural Information Processing Systems , articleno =. 2021 , isbn =
2021
-
[74]
RGNet: A Unified Clip Retrieval and Grounding Network for Long Videos
Hannan, Tanveer and Islam, Md Mohaiminul and Seidl, Thomas and Bertasius, Gedas. RGNet: A Unified Clip Retrieval and Grounding Network for Long Videos. Computer Vision -- ECCV 2024. 2025
2024
-
[75]
The Thirteenth International Conference on Learning Representations , year=
TimeSuite: Improving MLLMs for Long Video Understanding via Grounded Tuning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[76]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Unloc: A unified framework for video localization tasks , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[77]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Vtimellm: Empower llm to grasp video moments , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[78]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Timechat: A time-sensitive multimodal large language model for long video understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[79]
Yongxin Guo and Jingyu Liu and Mingda Li and Qingbin Liu and Xi Chen and Xiaoying Tang , booktitle=
-
[80]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Univtg: Towards unified video-language temporal grounding , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.