RPO-PDT: Demonstrating Role-Play-Based Knowledge Adaptation for Student Support Dialogue (Demonstration System)
Pith reviewed 2026-06-27 16:43 UTC · model grok-4.3
The pith
RPO-PDT demonstrates a dialogue system that adapts tutor strategies by replaying unresolved student interactions from the student perspective to build reusable memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
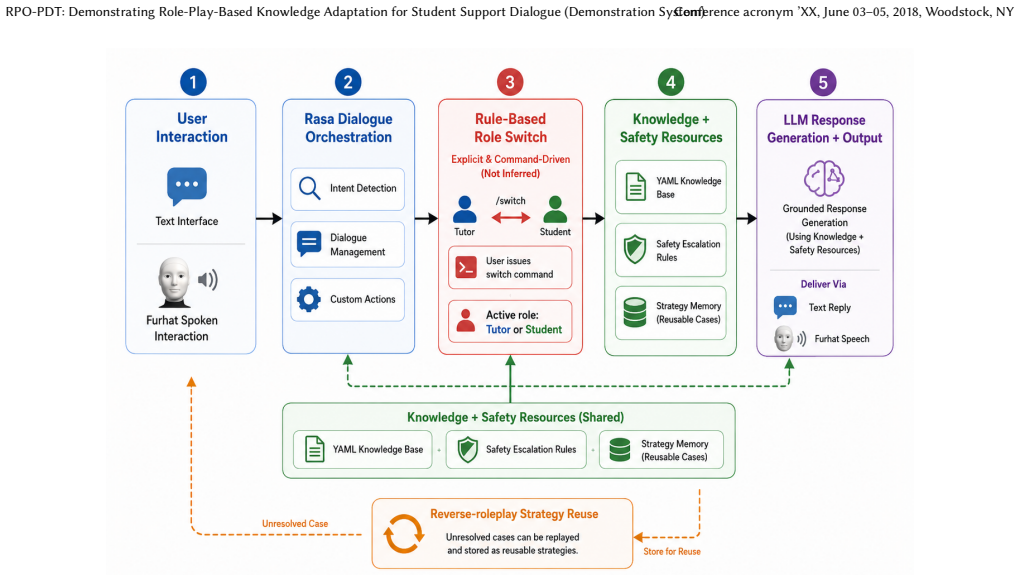
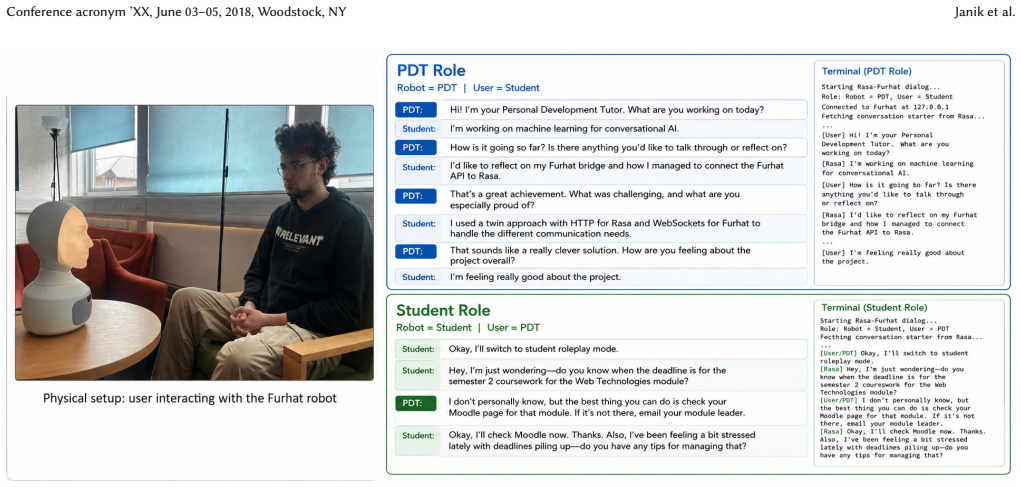
RPO-PDT is a retrieval-grounded, role-play-based dialogue system for adaptive student support in higher education that provides institution-specific Personal Development Tutor guidance using structured knowledge sources, remains constrained by explicit persona, boundary, confidentiality, and safety policies, and is built around a reverse-roleplay loop in which unresolved interactions are replayed from the student perspective so that alternative tutor strategies can be generated and stored as reusable strategy memory.
What carries the argument
The reverse-roleplay loop, which replays unresolved tutor-student interactions from the student perspective to generate and store alternative tutor strategies as reusable memory.
If this is right
- The system generates reusable strategy memory from role-play replays without external retraining.
- Explicit persona, boundary, confidentiality, and safety policies remain active constraints during both text and embodied interactions.
- Structured knowledge sources allow institution-specific guidance while the role-play mechanism supplies adaptation.
- The same architecture supports both text-based and Furhat-based embodied student interactions.
Where Pith is reading between the lines
- The stored strategy memory could be inspected or edited by human staff before reuse.
- The approach might extend to other constrained professional dialogues if the replay step generalizes beyond student support.
- Long-term use would require tracking whether the growing memory begins to duplicate or conflict with the original policy constraints.
Load-bearing premise
Replaying interactions from the student perspective will reliably produce effective and reusable alternative tutor strategies that improve the system's performance over time.
What would settle it
Run a sequence of unresolved student-tutor exchanges through the loop, then measure whether the newly generated strategies produce higher resolution rates on matched follow-up cases compared with the original strategies.
Figures
read the original abstract
We present RPO-PDT: a retrieval-grounded, role-play-based dialogue system for adaptive student support in higher education. RPO-PDT is: (1) able to provide institution-specific Personal Development Tutor (PDT) guidance using structured knowledge sources; (2) constrained by explicit persona, boundary, confidentiality, and safety policies; and (3) designed around a reverse-roleplay loop where unresolved interactions are replayed from the student perspective, enabling alternative tutor strategies to be generated and stored as reusable strategy memory. RPO-PDT supports both text-based and Furhat-based embodied interaction for demonstrating grounded, safe, and adaptive student-support dialogue.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents RPO-PDT, a retrieval-grounded, role-play-based dialogue system for adaptive student support in higher education. It claims to (1) deliver institution-specific Personal Development Tutor (PDT) guidance from structured knowledge sources, (2) enforce explicit persona, boundary, confidentiality, and safety policies, and (3) incorporate a reverse-roleplay loop in which unresolved interactions are replayed from the student perspective to generate alternative tutor strategies that are stored as reusable strategy memory. The system is shown in both text-based and Furhat embodied interaction modes.
Significance. If the reverse-roleplay loop reliably produces effective, reusable strategies, the work could advance safe, policy-constrained dialogue systems for educational support and contribute to self-adaptive tutoring architectures. The explicit emphasis on grounding and safety policies is a constructive element for responsible deployment in higher education. However, the absence of any evaluation, examples, or ablation data means the practical significance remains that of an architectural description rather than a validated adaptive mechanism.
major comments (2)
- [Abstract] Abstract: The central claim that the reverse-roleplay loop 'enables alternative tutor strategies to be generated and stored as reusable strategy memory' is presented as a core design feature, yet the manuscript supplies no qualitative examples of generated strategies, no comparison against non-roleplay baselines, and no indication of whether memory reuse produces measurable improvements in dialogue quality or support outcomes.
- [Abstract] Abstract (system description): The assertion that the system achieves 'adaptive' knowledge adaptation rests on the untested assumption that replaying interactions from the student perspective will reliably yield effective and reusable tutor strategies; this assumption is load-bearing for the title's claim of demonstrating role-play-based knowledge adaptation but receives no supporting demonstration or validation.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. This is a demonstration paper describing the RPO-PDT system architecture rather than an empirical evaluation study. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the reverse-roleplay loop 'enables alternative tutor strategies to be generated and stored as reusable strategy memory' is presented as a core design feature, yet the manuscript supplies no qualitative examples of generated strategies, no comparison against non-roleplay baselines, and no indication of whether memory reuse produces measurable improvements in dialogue quality or support outcomes.
Authors: We agree the manuscript provides no examples or comparisons, consistent with its scope as a system demonstration. The reverse-roleplay loop is presented as an architectural mechanism for generating and storing strategies. In a revision we will add qualitative examples of the replay process and resulting strategy memory entries to illustrate the design. revision: yes
-
Referee: [Abstract] Abstract (system description): The assertion that the system achieves 'adaptive' knowledge adaptation rests on the untested assumption that replaying interactions from the student perspective will reliably yield effective and reusable tutor strategies; this assumption is load-bearing for the title's claim of demonstrating role-play-based knowledge adaptation but receives no supporting demonstration or validation.
Authors: The manuscript describes the reverse-roleplay loop as the mechanism intended to support adaptation but does not claim or demonstrate empirical effectiveness. We will revise the abstract to more precisely frame the contribution as a design for role-play-based adaptation in a demonstration system, removing any implication of validated outcomes. revision: yes
Circularity Check
No circularity: system description contains no derivations, fits, or self-referential claims
full rationale
The paper is a demonstration-system description of an architecture (retrieval-grounded role-play dialogue with explicit policies and a reverse-roleplay loop). No equations, parameters, predictions, or uniqueness theorems appear. The reverse-roleplay loop is presented as a design feature whose effectiveness is an untested assumption, but this is a validation gap rather than circularity. No step reduces to its own inputs by construction, self-citation, or renaming. The derivation chain is empty; the work is self-contained as an engineering demonstration.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Optimising strategies for learning visually grounded word meanings through interaction , Year =
Yanchao Yu , School =. Optimising strategies for learning visually grounded word meanings through interaction , Year =
-
[2]
arXiv preprint arXiv:2511.11881 , year=
Better LLM Reasoning via Dual-Play , author=. arXiv preprint arXiv:2511.11881 , year=
-
[3]
Alexa Prize Proceedings , title =
Papaioannou, Ioannis and Curry, Amanda Cercas and Part, Jose L and Shalyminov, Igor and Xu, Xinnuo and Yu, Yanchao and Du. Alexa Prize Proceedings , title =. 2017 , url =
2017
-
[4]
18th Workshop on the Semantics and Pragmatics of Dialogue (SemDial/DialWatt) , month =
Rieser, Verena and Janarthanam, Srinivasan and Taylor, Andy and Yu, Yanchao and Lemon, Oliver , title =. 18th Workshop on the Semantics and Pragmatics of Dialogue (SemDial/DialWatt) , month =. 2014 , address =
2014
-
[5]
and Yu, Yanchao and Siei
Gunson, Nancie and Garcia, Daniel Hernandez and Part, Jose L. and Yu, Yanchao and Siei. Combining Visual and Social Dialogue for Human-Robot Interaction , booktitle =. 2021 , address =
2021
-
[6]
arXiv preprint arXiv:2310.10683 , year=
Large Language Model Unlearning , author=. arXiv preprint arXiv:2310.10683 , year=
-
[7]
arXiv preprint arXiv:2401.06121 , year=
TOFU: A Task of Fictitious Unlearning for LLMs , author=. arXiv preprint arXiv:2401.06121 , year=
-
[8]
arXiv preprint arXiv:2310.07579 , year=
In-context unlearning: Language models as few shot unlearners , author=. arXiv preprint arXiv:2310.07579 , year=
-
[9]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Unsupervised cross-lingual representation learning at scale , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[10]
2021 IEEE Symposium on Security and Privacy (SP) , pages=
Machine unlearning , author=. 2021 IEEE Symposium on Security and Privacy (SP) , pages=. 2021 , organization=
2021
-
[11]
Deep Learning for Micro-Expression Recognition: A Survey , year=
Li, Yante and Wei, Jinsheng and Liu, Yang and Kauttonen, Janne and Zhao, Guoying , journal=. Deep Learning for Micro-Expression Recognition: A Survey , year=
-
[12]
IEEE Transactions on Affective Computing , year=
An overview of facial micro-expression analysis: Data, methodology and challenge , author=. IEEE Transactions on Affective Computing , year=
-
[13]
Proceedings of the 22nd Annual ACM Interaction Design and Children Conference , pages=
Designing Parent-child-robot Interactions to Facilitate In-Home Parental Math Talk with Young Children , author=. Proceedings of the 22nd Annual ACM Interaction Design and Children Conference , pages=
-
[14]
Electronic Markets , volume=
Microexpressions in digital humans: perceived affect, sincerity, and trustworthiness , author=. Electronic Markets , volume=. 2022 , publisher=
2022
-
[15]
Neural Processing Letters , pages=
A Survey of Micro-expression Recognition Methods Based on LBP, Optical Flow and Deep Learning , author=. Neural Processing Letters , pages=. 2023 , publisher=
2023
-
[16]
Frontiers in psychology , volume=
Automatic micro-expression analysis: open challenges , author=. Frontiers in psychology , volume=. 2019 , publisher=
2019
-
[17]
Machine Learning and Knowledge Extraction , volume=
Review of automatic microexpression recognition in the past decade , author=. Machine Learning and Knowledge Extraction , volume=. 2021 , publisher=
2021
-
[18]
arXiv preprint arXiv:2307.09288 , year=
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
-
[19]
Transactions of the Association for Computational Linguistics , volume=
State of what art? a call for multi-prompt llm evaluation , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , publisher=
2024
-
[20]
arXiv preprint arXiv:2404.09971 , year=
Constructing Benchmarks and Interventions for Combating Hallucinations in LLMs , author=. arXiv preprint arXiv:2404.09971 , year=
-
[21]
arXiv preprint arXiv:2401.10019 , year=
R-judge: Benchmarking safety risk awareness for llm agents , author=. arXiv preprint arXiv:2401.10019 , year=
-
[22]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[23]
arXiv preprint arXiv:2310.10501 , year=
Nemo guardrails: A toolkit for controllable and safe llm applications with programmable rails , author=. arXiv preprint arXiv:2310.10501 , year=
-
[24]
2024 , url=
Malte Ostendorff and Pedro Ortiz Suarez and Lucas Fonseca Lage and Georg Rehm , booktitle=. 2024 , url=
2024
-
[25]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts , pages=
Unsupervised cross-lingual representation learning , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts , pages=
-
[26]
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model , author=
-
[27]
Xue, Linting and Constant, Noah and Roberts, Adam and Kale, Mihir and Al-Rfou, Rami and Siddhant, Aditya and Barua, Aditya and Raffel, Colin. m T 5: A Massively Multilingual Pre-trained Text-to-Text Transformer. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2...
-
[28]
ACM Computing Surveys , year=
Continual learning of large language models: A comprehensive survey , author=. ACM Computing Surveys , year=
-
[29]
arXiv preprint arXiv:2310.06762 , year=
Trace: A comprehensive benchmark for continual learning in large language models , author=. arXiv preprint arXiv:2310.06762 , year=
-
[30]
Proceedings of the AAAI Conference on Artificial Intelligence , series=
Memorybank: Enhancing large language models with long-term memory , author=. Proceedings of the AAAI Conference on Artificial Intelligence , series=
-
[31]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[32]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
Advances in Neural Information Processing Systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Nature , volume=
Role play with large language models , author=. Nature , volume=. 2023 , publisher=
2023
-
[35]
Proceedings of the 29th International Conference on Computational Linguistics , pages=
Topkg: Target-oriented dialog via global planning on knowledge graph , author=. Proceedings of the 29th International Conference on Computational Linguistics , pages=
-
[36]
2024 IEEE AITU: Digital Generation , pages=
Simulating life: The application of generative agents in virtual environments , author=. 2024 IEEE AITU: Digital Generation , pages=. 2024 , organization=
2024
-
[37]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[38]
arXiv preprint arXiv:2210.04185 , year=
Controllable dialogue simulation with in-context learning , author=. arXiv preprint arXiv:2210.04185 , year=
-
[39]
Extended abstracts of the CHI conference on human factors in computing systems , pages=
Generating personas using LLMs and assessing their viability , author=. Extended abstracts of the CHI conference on human factors in computing systems , pages=
-
[40]
Findings of the Association for Computational Linguistics: NAACL 2022 , pages=
BanglaBERT: Language model pretraining and benchmarks for low-resource language understanding evaluation in Bangla , author=. Findings of the Association for Computational Linguistics: NAACL 2022 , pages=
2022
-
[41]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
AmericasNLI: Evaluating zero-shot natural language understanding of pretrained multilingual models in truly low-resource languages , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[42]
Cross-Lingual Transfer Learning for Low-Resource NLP Tasks: Leveraging Multilingual Pretrained Models , author=
-
[43]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Unibridge: A unified approach to cross-lingual transfer learning for low-resource languages , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[44]
arXiv preprint arXiv:2305.15525 , year=
Large language models are few-shot health learners , author=. arXiv preprint arXiv:2305.15525 , year=
-
[45]
arXiv preprint arXiv:2402.08526 , year=
Can LLMs Learn New Concepts Incrementally without Forgetting? , author=. arXiv preprint arXiv:2402.08526 , year=
-
[46]
Recommendation as a Communication Game: Self-Supervised Bot-Play for Goal-oriented Dialogue
Kang, Dongyeop and Balakrishnan, Anusha and Shah, Pararth and Crook, Paul and Boureau, Y-Lan and Weston, Jason. Recommendation as a Communication Game: Self-Supervised Bot-Play for Goal-oriented Dialogue. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Pr...
-
[47]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[48]
LLM Alignment via Reinforcement Learning from Multi-role Debates as Feedback , author=
-
[49]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Continual Learning Using Only Large Language Model Prompting , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[50]
International conference on machine learning , pages=
Improving language models by retrieving from trillions of tokens , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[51]
Transactions of the Association for Computational Linguistics , volume=
Relational memory-augmented language models , author=. Transactions of the Association for Computational Linguistics , volume=. 2022 , publisher=
2022
-
[52]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 6: Tutorial Abstracts) , pages=
Retrieval-based language models and applications , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 6: Tutorial Abstracts) , pages=
-
[53]
2024 , eprint=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. 2024 , eprint=
2024
-
[54]
arXiv preprint arXiv:2406.05534 , year=
Online dpo: Online direct preference optimization with fast-slow chasing , author=. arXiv preprint arXiv:2406.05534 , year=
-
[55]
Advances in Neural Information Processing Systems , volume=
Jailbreaking large language models against moderation guardrails via cipher characters , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
arXiv preprint arXiv:2412.19437 , year=
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
-
[57]
arXiv preprint arXiv:1712.05181 , year=
Rasa: Open source language understanding and dialogue management , author=. arXiv preprint arXiv:1712.05181 , year=
-
[58]
Cognitive behavioural systems: COST 2102 international training school, dresden, Germany, february 21-26, 2011, revised selected papers , pages=
Furhat: a back-projected human-like robot head for multiparty human-machine interaction , author=. Cognitive behavioural systems: COST 2102 international training school, dresden, Germany, february 21-26, 2011, revised selected papers , pages=. 2012 , publisher=
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.