Back to the Familiar Future: Failure Recovery for VLA Policies via Pre-Imagined Milestone Selection
Pith reviewed 2026-06-27 16:41 UTC · model grok-4.3
The pith
Pre-imagined milestones let VLAs recover from trajectory deviations by mapping off-path observations back to familiar futures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
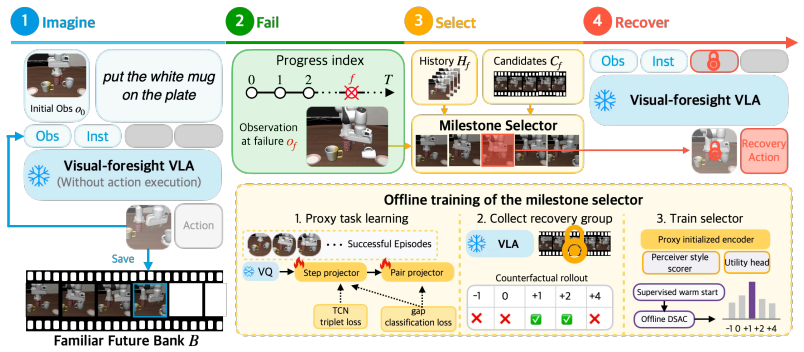
B2FF generates a milestone bank of familiar future states conditioned on the clean initial observation, then at recovery time a recoverability-aware selector chooses one milestone and enforces it as a fixed visual goal so that the VLA can map off-trajectory observations back onto a familiar future without any fine-tuning of its action generator.
What carries the argument
A pre-execution milestone bank of future visual states together with a recoverability-aware selector that enforces the chosen milestone as a visual goal.
If this is right
- Recovery succeeds without retraining or altering the low-level action generator.
- The policy is guided only by visual goals drawn from its own earlier predictions rather than from external replanning.
- The method works on tasks that remain physically feasible but have pushed the policy into unfamiliar state regions.
- Controlled recovery timing aligned with injected failures is sufficient to realize the reported gain.
Where Pith is reading between the lines
- The same pre-imagined bank could be reused across multiple failures within a single long-horizon episode.
- If the selector were replaced by a learned policy the framework might scale to settings where failures occur at unpredictable times.
- The approach separates foresight generation from low-level control, suggesting it could be paired with any VLA that already conditions on future images.
- Extending the bank to include alternative feasible futures rather than only nominal ones might further increase robustness.
Load-bearing premise
The VLA can generate a milestone bank of familiar future states conditioned on the clean initial observation before execution, and a recoverability-aware selector can identify a suitable recovery milestone from this bank at runtime.
What would settle it
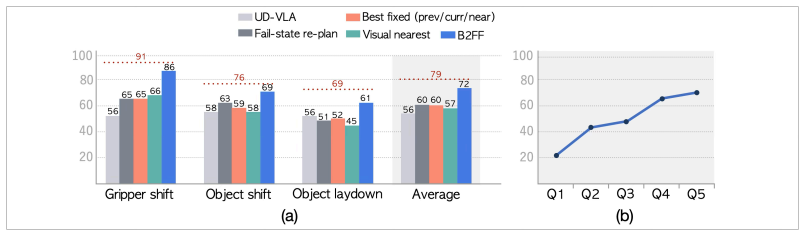
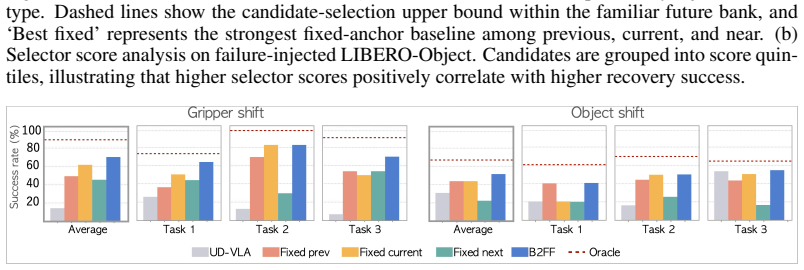
Run the same failure-injected LIBERO episodes with controlled recovery timing; if average success rate does not rise from 56.3 percent to 74.0 percent when the milestone bank and selector are added, the central claim is falsified.
Figures






read the original abstract
Vision-language-action (VLA) policies can deviate from nominal trajectories during manipulation, even when tasks remain physically feasible. Recovering from these deviations is challenging, as they push the policy into unfamiliar state spaces where direct re-planning frequently destabilizes action sequences. We propose Back to the Familiar Future (B2FF), a recovery framework for foresight-driven VLAs that leverages future visual conditioning as a recovery interface. Before execution, the VLA generates a milestone bank of familiar future states conditioned on the clean initial observation. At recovery time, a recoverability-aware selector selects a recovery milestone from this bank and enforces it as a fixed visual goal. This enables the VLA to robustly map off-trajectory observations back to a familiar future. On failure-injected LIBERO, under controlled recovery timing aligned with the injected failure, B2FF increases the average success rate of a baseline VLA from 56.3% to 74.0%, demonstrating that pre-imagined milestones can guide recovery without fine-tuning the low-level action generator.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Back to the Familiar Future (B2FF), a recovery framework for vision-language-action (VLA) policies. Before execution, the VLA generates a bank of milestone future visual states conditioned on the clean initial observation. At recovery time, a recoverability-aware selector chooses a milestone from this bank and enforces it as a fixed visual goal, enabling the policy to map off-trajectory observations back to familiar futures without fine-tuning the low-level action generator. On failure-injected LIBERO tasks, under controlled recovery timing aligned with the injected failure, B2FF raises average success rate from 56.3% to 74.0%.
Significance. If the result holds under autonomous recovery triggering, B2FF would provide a lightweight interface for improving VLA robustness in manipulation by exploiting pre-computed visual milestones. The approach avoids retraining the action model and could be relevant for tasks where deviations are frequent but physically recoverable. The current evaluation, however, is restricted to oracle-aligned timing, so the practical significance remains to be established.
major comments (1)
- [Abstract] Abstract: the reported lift from 56.3% to 74.0% is qualified as holding 'under controlled recovery timing aligned with the injected failure.' This means the recoverability-aware selector is invoked at the exact known failure instant rather than at a time determined by the policy or an autonomous detector. Consequently the experiment does not test whether the pre-imagined milestone bank plus selector can still produce the reported gain when recovery must be triggered without oracle knowledge of failure onset. This directly affects the weakest assumption (milestone generation and runtime selection) and is load-bearing for the claim of a deployable recovery framework.
Simulated Author's Rebuttal
We thank the referee for the precise identification of the evaluation scope. We agree that the reported gains are measured under oracle-aligned recovery timing and that autonomous triggering is required to fully substantiate deployability claims. In the revised version we will add experiments that close this gap while preserving the focus on the milestone-based recovery interface.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported lift from 56.3% to 74.0% is qualified as holding 'under controlled recovery timing aligned with the injected failure.' This means the recoverability-aware selector is invoked at the exact known failure instant rather than at a time determined by the policy or an autonomous detector. Consequently the experiment does not test whether the pre-imagined milestone bank plus selector can still produce the reported gain when recovery must be triggered without oracle knowledge of failure onset. This directly affects the weakest assumption (milestone generation and runtime selection) and is load-bearing for the claim of a deployable recovery framework.
Authors: We concur that the present results isolate the contribution of the pre-imagined milestone bank and recoverability-aware selector by invoking recovery at the known failure instant. This controlled setting was chosen to avoid confounding the core mechanism with the separate problem of failure detection. The abstract already qualifies the result accordingly. To address the referee's concern about practical significance, the revision will include a new set of experiments that replace the oracle trigger with an autonomous detector (e.g., based on action-prediction entropy or visual reconstruction error) and report success rates under that regime. We expect these additions to demonstrate that the milestone interface remains effective when recovery timing is determined without oracle knowledge. revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations or self-referential fits
full rationale
The paper proposes a recovery framework (pre-imagined milestone bank + recoverability-aware selector) and reports an empirical success-rate lift on failure-injected LIBERO under explicitly controlled (oracle-timed) recovery. No equations, parameter fits, uniqueness theorems, or derivation steps appear in the manuscript. The central claim is therefore a direct experimental comparison rather than any quantity that reduces to its own inputs by construction. The timing qualification noted by the skeptic is a limitation on experimental scope, not a circularity in any derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[2]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[3]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[4]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[5]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[6]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[7]
R ¨omer, A
R. R ¨omer, A. Kobras, L. Worbis, and A. Schoellig. Failure prediction at runtime for generative robot policies.Advances in Neural Information Processing Systems, 38:7631–7670, 2025
2025
-
[8]
Q. Gu, Y . Ju, S. Sun, I. Gilitschenski, H. Nishimura, M. Itkina, and F. Shkurti. Safe: Mul- titask failure detection for vision-language-action models.Advances in Neural Information Processing Systems, 38:40041–40076, 2025
2025
-
[9]
Z. Lin, J. Duan, H. Fang, D. Fox, R. Krishna, C. Tan, and B. Wen. Failsafe: Reasoning and recovery from failures in vision-language-action models.arXiv preprint arXiv:2510.01642, 2025
arXiv 2025
-
[10]
Y . Dai, J. Lee, N. Fazeli, and J. Chai. Racer: Rich language-guided failure recovery policies for imitation learning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 15657–15664. IEEE, 2025
2025
-
[11]
W. Xia, R. Feng, D. Wang, and D. Hu. Phoenix: A motion-based self-reflection framework for fine-grained robotic action correction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6981–6990, 2025
2025
-
[12]
D. Li, J. Lei, H. Wang, L. Liu, Y . Yang, Z. Wang, B. Liu, M. Zheng, and Z. Fan. Learn- ing actionable manipulation recovery via counterfactual failure synthesis.arXiv preprint arXiv:2603.13528, 2026
arXiv 2026
-
[13]
P. Wu, P. Zhang, Z. Wang, D. Wang, B. Zhao, and X. Li. Closed-loop action chunks with dynamic corrections for training-free diffusion policy.arXiv preprint arXiv:2603.01953, 2026. 9
arXiv 2026
-
[14]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[15]
Y . Du, S. Yang, P. Florence, F. Xia, A. Wahid, P. Sermanet, T. Yu, P. Abbeel, J. B. Tenen- baum, L. Kaelbling, et al. Video language planning. InInternational Conference on Learning Representations, volume 2024, pages 31138–31155, 2024
2024
-
[16]
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172, 2023
2023
-
[17]
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finn, et al. Cot- vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1702–1713, 2025
2025
-
[18]
Zhang, H
W. Zhang, H. Liu, Z. Qi, Y . Wang, X. Yu, J. Zhang, R. Dong, J. He, H. Wang, Z. Zhang, et al. Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge. Advances in Neural Information Processing Systems, 38:24195–24228, 2025
2025
- [19]
-
[20]
J. Chen, W. Song, P. Ding, Z. Zhou, H. Zhao, F. Tang, D. Wang, and H. Li. Unified diffu- sion vla: Vision-language-action model via joint discrete denoising diffusion process.arXiv preprint arXiv:2511.01718, 2025
arXiv 2025
-
[21]
H. Chen, Y . Yao, R. Liu, C. Liu, and J. Ichnowski. Automating robot failure recovery using vision-language models with optimized prompts.arXiv preprint arXiv:2409.03966, 2024
arXiv 2024
-
[22]
Kang and Y .-L
X. Kang and Y .-L. Kuo. Incorporating task progress knowledge for subgoal generation in robotic manipulation through image edits. In2025 IEEE/CVF Winter Conference on Applica- tions of Computer Vision (WACV), pages 7490–7499. IEEE, 2025
2025
-
[23]
D. Liu, H. Niu, Z. Wang, J. Zheng, Y . Zheng, Z. Ou, J. Hu, J. Li, and X. Zhan. Efficient robotic policy learning via latent space backward planning.arXiv preprint arXiv:2505.06861, 2025
arXiv 2025
-
[24]
H. Yan, Q. Li, J. Yang, and Y . Mu. Progressvla: Progress-guided diffusion policy for vision- language robotic manipulation.arXiv preprint arXiv:2603.27670, 2026
arXiv 2026
-
[25]
T. Dai, M. Han, T. Du, Z. Liu, Z. Li, S. Khan, J. Yu, and X. Chang. See, plan, rewind: Progress-aware vision-language-action models for robust robotic manipulation.arXiv preprint arXiv:2603.09292, 2026
Pith/arXiv arXiv 2026
-
[26]
Jaegle, F
A. Jaegle, F. Gimeno, A. Brock, O. Vinyals, A. Zisserman, and J. Carreira. Perceiver: General perception with iterative attention. InInternational conference on machine learning, pages 4651–4664. PMLR, 2021
2021
-
[27]
Sermanet, C
P. Sermanet, C. Lynch, Y . Chebotar, J. Hsu, E. Jang, S. Schaal, S. Levine, and G. Brain. Time-contrastive networks: Self-supervised learning from video. In2018 IEEE international conference on robotics and automation (ICRA), pages 1134–1141. IEEE, 2018
2018
-
[28]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018
2018
-
[29]
P. Christodoulou. Soft actor-critic for discrete action settings.arXiv preprint arXiv:1910.07207, 2019. 10
arXiv 1910
-
[30]
P. J. Huber. Robust estimation of a location parameter. InBreakthroughs in statistics: Method- ology and distribution, pages 492–518. Springer, 1992
1992
-
[31]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[32]
J. Lee, J. Duan, H. Fang, Y . Deng, S. Liu, B. Li, B. Fang, J. Zhang, Y . R. Wang, S. Lee, et al. Molmoact: Action reasoning models that can reason in space.arXiv preprint arXiv:2508.07917, 2025. 11 Appendix A B2FF Implementation Details Frozen inference interface.As described in the main text, B2FF uses the frozen foresight-driven VLA in two modes: joint...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.