Echo-DM: Ultrasound Marker Removal via Conditional Latent Diffusion and Region-Aware Fusion
Pith reviewed 2026-06-27 17:27 UTC · model grok-4.3
The pith
Echo-DM removes ultrasound markers via conditional latent diffusion and region-aware fusion without requiring masks at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
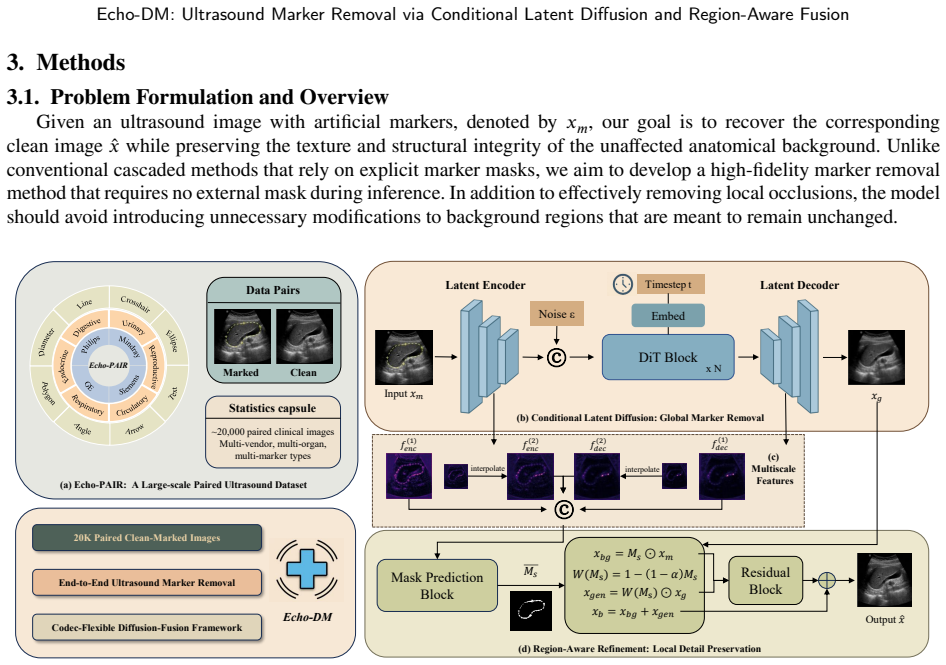
Echo-DM follows an encoder-diffusion-decoder design in which a conditional latent diffusion network performs global marker removal and a region-aware fusion module enforces preservation-aware refinement in image space, enabling mask-free inference that avoids both error propagation from explicit masks and over-smoothing from deterministic restorers.
What carries the argument
The region-aware fusion module, which performs preservation-aware image-space refinement after latent diffusion to maintain background consistency under mask-free operation.
If this is right
- Downstream diagnostic models trained on cleaned images should rely less on marker shortcuts and more on anatomical features.
- The architecture works with both VAE-based and RAE-based latent modules, indicating flexibility across encoder choices.
- The method supplies favorable quality-efficiency operating points for different clinical deployment constraints.
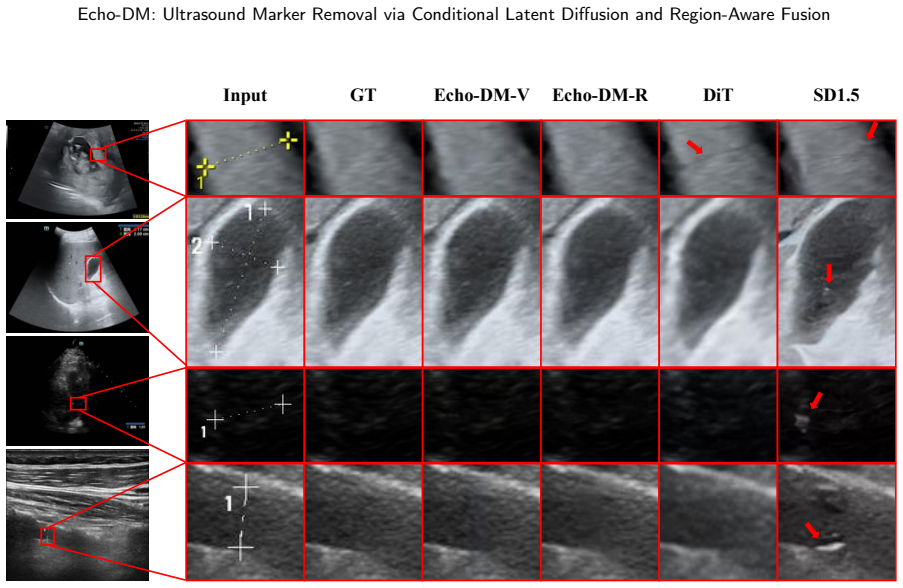
- Marker removal quality exceeds that of representative two-stage baselines on the Echo-PAIR dataset.
Where Pith is reading between the lines
- The same diffusion-plus-fusion pattern could be tested on other imaging modalities that carry similar overlay artifacts.
- Releasing the paired dataset would allow direct measurement of how much marker bias affects current ultrasound analysis models.
- End-to-end mask-free operation removes a source of annotation cost that mask-dependent methods incur at scale.
Load-bearing premise
The region-aware fusion module can enforce preservation of unaffected regions during end-to-end mask-free inference without introducing artifacts or inconsistencies that affect anatomical fidelity.
What would settle it
A side-by-side comparison on Echo-PAIR test pairs in which the output differs visibly from the clean ground-truth image in any region outside the original marker locations would falsify the preservation claim.
Figures

read the original abstract
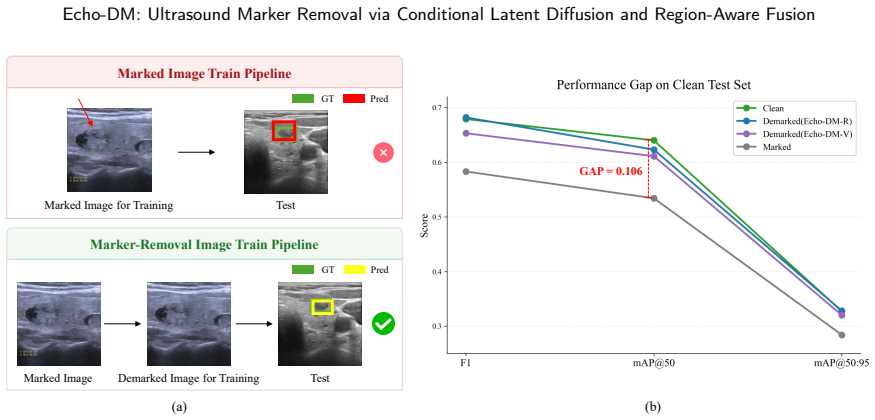
Clinical ultrasound images often contain artificial markers, such as measurement calipers and text, to assist diagnostic interpretation and comparison. However, these markers can introduce shortcut bias in downstream automated analysis, encouraging deep learning models to rely on marker-related cues rather than clinically meaningful anatomy. Existing marker removal methods are either mask-dependent and vulnerable to error propagation, or mask-free deterministic restorers that may over-smooth ultrasound texture and perturb unaffected background regions. To address these challenges, we present Echo-DM, a framework for ultrasound marker removal via conditional latent diffusion and region-aware fusion. Echo-DM follows a common encoder-diffusion-decoder pipeline, where a DiT-based conditional latent diffusion network performs global restoration and a region-aware fusion module enforces preservation-aware image-space refinement under end-to-end mask-free inference. Building on this fixed core design, we further instantiate Echo-DM-V and Echo-DM-R with VAE-based and RAE-based latent modules, respectively, which demonstrates that the Echo-DM architecture is compatible with diverse latent-module instantiations. Extensive experiments on Echo-PAIR, a large-scale paired clinical ultrasound dataset, demonstrate superior marker removal and strong anatomical fidelity compared with representative two-stage baselines, while providing favorable quality--efficiency trade-offs across deployment settings. Data, code and models will be released at https://github.com/MiliLab/Echo-DM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Echo-DM, a conditional latent diffusion framework for removing artificial markers (e.g., calipers, text) from clinical ultrasound images. It uses a DiT-based diffusion network for global restoration followed by a region-aware fusion module for image-space refinement in an end-to-end mask-free setting. Two latent-module variants (VAE-based Echo-DM-V and RAE-based Echo-DM-R) are instantiated, and experiments on the Echo-PAIR paired dataset claim superior marker removal, anatomical fidelity, and quality-efficiency trade-offs versus two-stage baselines, with public release of data, code, and models planned.
Significance. If the central empirical claims hold under verification, the work offers a practical mask-free alternative to existing marker-removal pipelines that could reduce shortcut bias in downstream ultrasound analysis models. The planned artifact release is a clear strength that supports reproducibility and extension by the community.
major comments (2)
- [§3.2] §3.2 (region-aware fusion module): The description of how region awareness is implemented during mask-free inference (e.g., via learned attention, implicit masking, or auxiliary preservation losses) is insufficiently detailed to evaluate whether unaffected background regions are reliably protected from perturbation. This mechanism is load-bearing for the superiority claim over mask-dependent baselines and the assertion of strong anatomical fidelity.
- [§4] §4 (experiments on Echo-PAIR): The abstract asserts quantitative superiority in marker removal and fidelity, yet the manuscript provides no error bars, statistical significance tests, or per-region breakdown (marker vs. background) that would confirm the fusion module avoids introducing inconsistencies in unaffected areas. Without these, the cross-method comparison cannot be fully assessed.
minor comments (2)
- [Abstract, §1] The acronyms Echo-DM-V and Echo-DM-R are introduced without immediate expansion on first use in the abstract and §1.
- [Figures 2-3] Figure captions and method diagrams should explicitly label the region-aware fusion block to clarify its placement relative to the diffusion decoder.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the region-aware fusion module and experimental reporting. We address each major comment below.
read point-by-point responses
-
Referee: [§3.2] §3.2 (region-aware fusion module): The description of how region awareness is implemented during mask-free inference (e.g., via learned attention, implicit masking, or auxiliary preservation losses) is insufficiently detailed to evaluate whether unaffected background regions are reliably protected from perturbation. This mechanism is load-bearing for the superiority claim over mask-dependent baselines and the assertion of strong anatomical fidelity.
Authors: We agree that §3.2 requires additional detail on the implementation of region awareness under mask-free inference. In the revised manuscript we will expand this section to specify the learned attention formulation, the implicit protection of background regions, and the role of any auxiliary preservation losses, thereby clarifying how the fusion module safeguards unaffected areas. revision: yes
-
Referee: [§4] §4 (experiments on Echo-PAIR): The abstract asserts quantitative superiority in marker removal and fidelity, yet the manuscript provides no error bars, statistical significance tests, or per-region breakdown (marker vs. background) that would confirm the fusion module avoids introducing inconsistencies in unaffected areas. Without these, the cross-method comparison cannot be fully assessed.
Authors: We acknowledge that the current experimental section lacks error bars, statistical significance testing, and per-region (marker vs. background) breakdowns. We will revise §4 to report standard deviations across runs, include appropriate statistical tests, and add separate quantitative results for marker and background regions to strengthen the evaluation of the fusion module. revision: yes
Circularity Check
No circularity; empirical engineering contribution
full rationale
The paper presents Echo-DM as an encoder-diffusion-decoder architecture with a region-aware fusion module, instantiated in variants (Echo-DM-V, Echo-DM-R) and validated empirically on the Echo-PAIR paired dataset. No equations, derivations, or claims reduce by construction to fitted inputs or self-citations; performance claims rest on external experimental comparisons rather than internal redefinitions or load-bearing self-references. The central differentiator (mask-free inference with region preservation) is asserted via design and results, not via any tautological step.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mededit: Counterfactual diffusion-based image editing on brain mri, in: International Workshop on Simulation and Synthesis in Medical Imaging, Springer
Alaya, M.B., Lang, D.M., Wiestler, B., Schnabel, J.A., Bercea, C.I., 2024. Mededit: Counterfactual diffusion-based image editing on brain mri, in: International Workshop on Simulation and Synthesis in Medical Imaging, Springer. pp. 167–176
2024
-
[2]
Pet image denoising based on denoising diffusion probabilistic model
Gong, K., Johnson, K., El Fakhri, G., Li, Q., Pan, T., 2024. Pet image denoising based on denoising diffusion probabilistic model. European Journal of Nuclear Medicine and Molecular Imaging 51, 358–368
2024
-
[3]
Blindinpaintingwithobject-awarediscriminationforartificialmarkerremoval,in: ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE
Guo,X.,Hu,W.,Ni,C.,Chai,W.,Li,S.,Wang,G.,2024. Blindinpaintingwithobject-awarediscriminationforartificialmarkerremoval,in: ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE. pp. 1516–1520
2024
-
[4]
Inpainting pathology in lumbar spine mri with latent diffusion
Hansen, C., Glinskis, S., Raju, A., Kornreich, M., Park, J., Pawar, J., Herzog, R., Zhang, L., Odry, B., 2024. Inpainting pathology in lumbar spine mri with latent diffusion. arXiv preprint arXiv:2406.02477
-
[5]
Masked autoencoders are scalable vision learners, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R., 2022. Masked autoencoders are scalable vision learners, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 16000–16009
2022
-
[6]
Ho,J.,Jain,A.,Abbeel,P.,2020.Denoisingdiffusionprobabilisticmodels.Advancesinneuralinformationprocessingsystems33,6840–6851
2020
-
[7]
Scope of validity of psnr in image/video quality assessment
Huynh-Thu, Q., Ghanbari, M., 2008. Scope of validity of psnr in image/video quality assessment. Electronics letters 44, 800–801
2008
-
[8]
nnu-net: a self-configuring method for deep learning-based biomedical image segmentation
Isensee, F., Jaeger, P.F., Kohl, S.A., Petersen, J., Maier-Hein, K.H., 2021. nnu-net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods 18, 203–211
2021
-
[9]
Denoising diffusion restoration models
Kawar, B., Elad, M., Ermon, S., Song, J., 2022. Denoising diffusion restoration models. Advances in neural information processing systems 35, 23593–23606
2022
-
[10]
Auto-encoding variational bayes
Kingma, D.P., Welling, M., 2014. Auto-encoding variational bayes. stat 1050, 1
2014
-
[11]
4681–4690
Ledig,C.,Theis,L.,Huszár,F.,Caballero,J.,Cunningham,A.,Acosta,A.,Aitken,A.,Tejani,A.,Totz,J.,Wang,Z.,etal.,2017.Photo-realistic single image super-resolution using a generative adversarial network, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4681–4690
2017
-
[12]
Noise2noise: Learning image restoration without clean data, in: International Conference on Machine Learning, PMLR
Lehtinen, J., Munkberg, J., Hasselgren, J., Laine, S., Karras, T., Aittala, M., Aila, T., 2018. Noise2noise: Learning image restoration without clean data, in: International Conference on Machine Learning, PMLR. pp. 2965–2974
2018
-
[13]
Mat: Mask-aware transformer for large hole image inpainting, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp
Li, W., Lin, Z., Zhou, K., Qi, L., Wang, Y., Jia, J., 2022. Mat: Mask-aware transformer for large hole image inpainting, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10758–10768
2022
-
[14]
Ultrasound in Medicine & Biology 50, 509–519
Li,X.,Fu,C.,Xu,S.,Sham,C.W.,2024.Thyroidultrasoundimagedatabaseandmarkermaskinpaintingmethodforresearchanddevelopment. Ultrasound in Medicine & Biology 50, 509–519
2024
-
[15]
Image inpainting for irregular holes using partial convolutions, in: Proceedings of the European conference on computer vision (ECCV), pp
Liu, G., Reda, F.A., Shih, K.J., Wang, T.C., Tao, A., Catanzaro, B., 2018. Image inpainting for irregular holes using partial convolutions, in: Proceedings of the European conference on computer vision (ECCV), pp. 85–100
2018
-
[16]
Liu, H., Wang, Y., Qian, B., Wang, M., Rui, Y., 2024. Structure matters: Tackling the semantic discrepancy in diffusion models for image inpainting, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8038–8047
2024
-
[17]
Repaint: Inpainting using denoising diffusion probabilistic models, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp
Lugmayr, A., Danelljan, M., Romero, A., Yu, F., Timofte, R., Van Gool, L., 2022. Repaint: Inpainting using denoising diffusion probabilistic models, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11461–11471
2022
-
[18]
Dfcl: Dual-pathway fusion contrastive learning for blind single-image visible watermark removal
Meng, B., Zhou, J., Yang, H., Liu, J., Pu, Y., 2025. Dfcl: Dual-pathway fusion contrastive learning for blind single-image visible watermark removal. Neural Networks 184, 107077
2025
-
[19]
4195–4205
Peebles,W.,Xie,S.,2023.Scalablediffusionmodelswithtransformers,in:ProceedingsoftheIEEE/CVFinternationalconferenceoncomputer vision, pp. 4195–4205
2023
-
[20]
Domain adaptation of stable diffusion for ultrasound inpainting: a synthetic data approach for enhanced thyroid nodule segmentation
Prochazka, A., Zeman, J., 2025. Domain adaptation of stable diffusion for ultrasound inpainting: a synthetic data approach for enhanced thyroid nodule segmentation. Journal of Biomedical Informatics , 104963
2025
-
[21]
High-resolution image synthesis with latent diffusion models, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B., 2022. High-resolution image synthesis with latent diffusion models, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10684–10695
2022
-
[22]
Imagesuper-resolutionviaiterativerefinement
Saharia,C.,Ho,J.,Chan,W.,Salimans,T.,Fleet,D.J.,Norouzi,M.,2022. Imagesuper-resolutionviaiterativerefinement. IEEEtransactions on pattern analysis and machine intelligence 45, 4713–4726. Wang et al.:Preprint submitted to ElsevierPage 17 of 18 Echo-DM: Ultrasound Marker Removal via Conditional Latent Diffusion and Region-Aware Fusion
2022
-
[23]
Removal of manually induced artifacts in ultrasound images of thyroid nodulesbasedonedge-connectionandcriminisiimagerestorationalgorithm
Sun, M., Meng, Q., Wang, T., Liu, T., Zhu, Y., Qiu, J., Lu, W., 2021. Removal of manually induced artifacts in ultrasound images of thyroid nodulesbasedonedge-connectionandcriminisiimagerestorationalgorithm. ComputerMethodsandProgramsinBiomedicine200,105868
2021
-
[24]
Narrowing the semantic gaps in u-net with learnable skip connections: The case of medical image segmentation
Wang, H., Cao, P., Yang, J., Zaiane, O., 2024. Narrowing the semantic gaps in u-net with learnable skip connections: The case of medical image segmentation. Neural Networks 178, 106546
2024
-
[25]
Vcnet: A robust approach to blind image inpainting, in: European Conference on Computer Vision, Springer
Wang, Y., Chen, Y.C., Tao, X., Jia, J., 2020. Vcnet: A robust approach to blind image inpainting, in: European Conference on Computer Vision, Springer. pp. 752–768
2020
-
[26]
Meansquarederror:Loveitorleaveit?anewlookatsignalfidelitymeasures
Wang,Z.,Bovik,A.C.,2009. Meansquarederror:Loveitorleaveit?anewlookatsignalfidelitymeasures. IEEEsignalprocessingmagazine 26, 98–117
2009
-
[27]
Image quality assessment: from error visibility to structural similarity
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P., 2004. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13, 600–612
2004
-
[28]
Diffcnn: A collaborative framework of diffusion model and cnn for semi-supervised medical image segmentation
Xu, S., Tian, L., 2025. Diffcnn: A collaborative framework of diffusion model and cnn for semi-supervised medical image segmentation. Neural Networks 191, 107813
2025
-
[29]
Frontiers in Bioengineering and Biotechnology 8, 599
Yao,S.,Yan,J.,Wu,M.,Yang,X.,Zhang,W.,Lu,H.,Qian,B.,2020.Texturesynthesisbasedthyroidnoduledetectionfrommedicalultrasound images: interpreting and suppressing the adversarial effect of in-place manual annotation. Frontiers in Bioengineering and Biotechnology 8, 599
2020
-
[30]
Cascademarkerremovalalgorithmfor thyroid ultrasound images
Ying,X.,Zhang,Y.,Yu,M.,Wei,X.,Zhu,J.,Gao,J.,Liu,Z.,Shen,H.,Zhang,R.,Li,X.,etal.,2020. Cascademarkerremovalalgorithmfor thyroid ultrasound images. Medical & Biological Engineering & Computing 58, 2641–2656
2020
-
[31]
Free-form image inpainting with gated convolution, in: Proceedings of the IEEE/CVF international conference on computer vision, pp
Yu, J., Lin, Z., Yang, J., Shen, X., Lu, X., Huang, T.S., 2019. Free-form image inpainting with gated convolution, in: Proceedings of the IEEE/CVF international conference on computer vision, pp. 4471–4480
2019
-
[32]
Medienet:medicalimageenhancementnetworkbasedonconditional latent diffusion model
Yuan,W.,Feng,Y.,Wen,T.,Luo,G.,Liang,J.,Sun,Q.,Liang,S.,2025. Medienet:medicalimageenhancementnetworkbasedonconditional latent diffusion model. BMC Medical Imaging 25, 372
2025
-
[33]
Adding conditional control to text-to-image diffusion models, in: Proceedings of the IEEE/CVF international conference on computer vision, pp
Zhang, L., Rao, A., Agrawala, M., 2023a. Adding conditional control to text-to-image diffusion models, in: Proceedings of the IEEE/CVF international conference on computer vision, pp. 3836–3847
-
[34]
The unreasonable effectiveness of deep features as a perceptual metric, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O., 2018. The unreasonable effectiveness of deep features as a perceptual metric, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 586–595
2018
-
[35]
Ultrasonicimage’sannotationremoval:Aself-supervisednoise2noiseapproach
Zhang,Y.,Jiang,N.,Xie,Z.,Cao,J.,Teng,Y.,2023b. Ultrasonicimage’sannotationremoval:Aself-supervisednoise2noiseapproach. arXiv preprint arXiv:2307.04133
-
[36]
Diffusion Transformers with Representation Autoencoders
Zheng, B., Ma, N., Tong, S., Xie, S., 2025. Diffusion transformers with representation autoencoders. arXiv preprint arXiv:2510.11690 . Wang et al.:Preprint submitted to ElsevierPage 18 of 18
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.