LexRubric: A Rubric-Guided Diagnostic Benchmark for Open-Ended Legal Tasks
Pith reviewed 2026-06-27 16:20 UTC · model grok-4.3
The pith
LexRubric supplies 12,337 expert atomic criteria in a six-dimensional framework to evaluate and diagnose LLM answers on open-ended Chinese legal tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
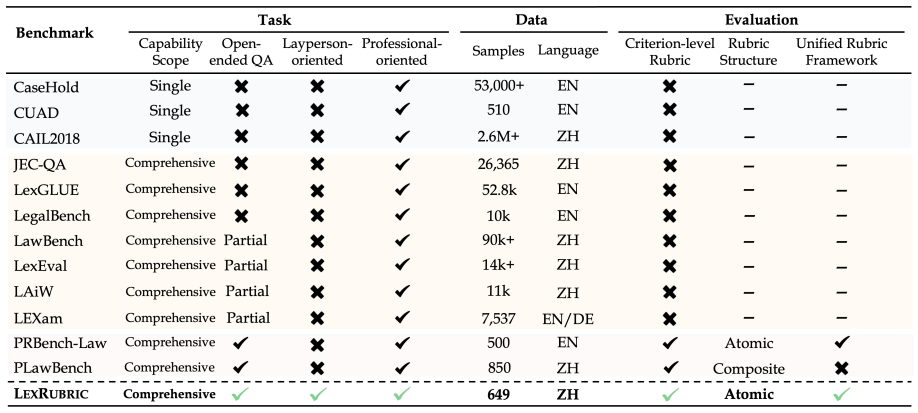
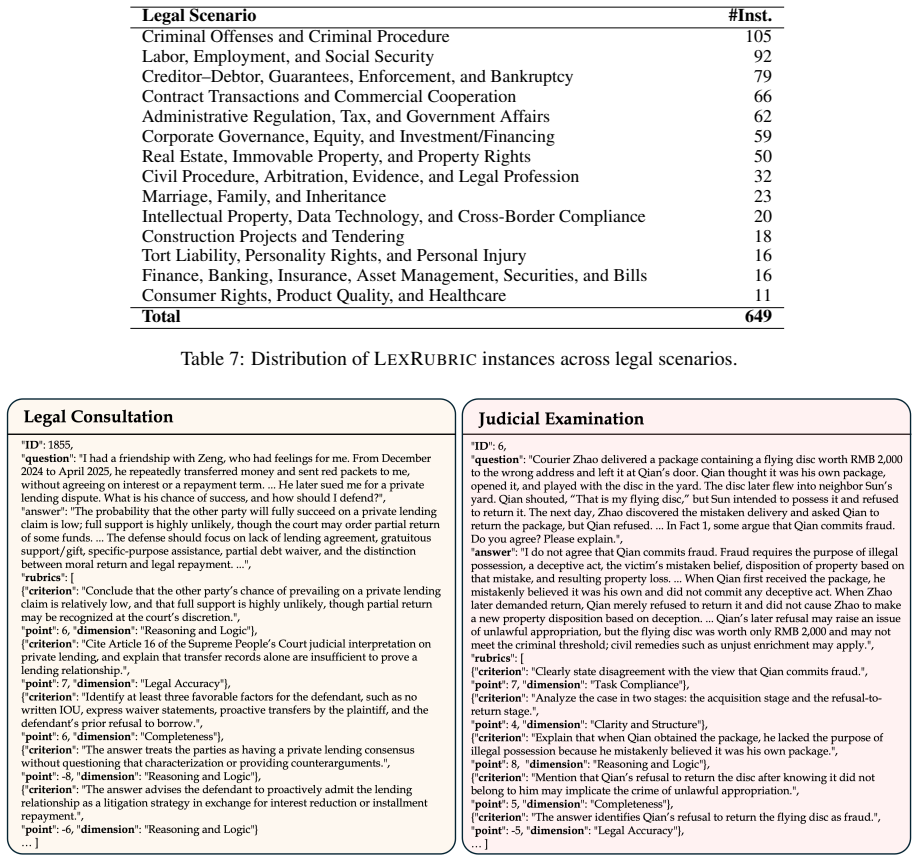
LexRubric is a rubric-guided benchmark that contains 649 instances from Chinese legal consultation and judicial examination tasks across 14 scenarios together with 12,337 expert-written atomic scoring criteria organized under a single six-dimensional framework, which supports both precise overall evaluation and detailed diagnostic analysis of open-ended model responses.
What carries the argument
The unified six-dimensional framework of expert-written atomic scoring criteria that decomposes response quality into discrete, checkable elements for each legal task instance.
If this is right
- Model-based judges can be validated against human judgments on the same rubric items.
- Different LLMs display distinct capability profiles when scored across the six dimensions.
- Open-ended legal questions remain challenging for current general and legal-domain models.
- The atomic criteria enable identification of specific sources of response quality failures.
Where Pith is reading between the lines
- The same atomic-criteria approach could be extended to legal tasks in languages other than Chinese.
- Repeated use of the benchmark across model versions might track whether improvements occur in particular dimensions over time.
- The framework could serve as a template for creating diagnostic rubrics in other high-stakes professional domains such as medicine or finance.
Load-bearing premise
Expert-written atomic scoring criteria and the six-dimensional framework accurately and comprehensively capture response quality for open-ended legal tasks without systematic bias or gaps in coverage.
What would settle it
A side-by-side comparison in which independent legal experts apply the published atomic criteria to the same set of model responses and produce scores or coverage gaps that differ substantially from the benchmark's intended judgments.
Figures


read the original abstract
As large language models (LLMs) are increasingly applied to real-world legal tasks, evaluating the reliability of their open-ended legal responses has become essential. These tasks require context-sensitive answers and allow little room for error, motivating fine-grained and diagnostic evaluation that can identify specific sources of response quality failures. We introduce LexRubric, a rubric-based benchmark for evaluating open-ended Chinese legal tasks. LexRubric contains 649 instances from legal consultation and judicial examination, which reflect both everyday legal needs and professional legal reasoning and cover 14 legal scenarios. It further includes 12,337 expert-written atomic scoring criteria organized under a unified six-dimensional framework, enabling accurate evaluation and diagnostic analysis across tasks and evaluation dimensions. To validate the reliability of the evaluation, we test multiple judge models and compare model-based judgments with human judgments. We further evaluate 18 recent general and legal-domain LLMs on LexRubric. Results show that different models exhibit distinct capability profiles, and that open-ended legal question remains challenging for current LLMs. Data is available at: https://github.com/foggpoy/LexRubric.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LexRubric, a benchmark for open-ended Chinese legal tasks consisting of 649 instances drawn from legal consultation and judicial examination across 14 scenarios. It supplies 12,337 expert-written atomic scoring criteria organized under a single six-dimensional framework to support fine-grained, diagnostic evaluation. The authors validate the rubric by comparing multiple judge models against human judgments on final scores and then evaluate 18 general and legal-domain LLMs, reporting distinct capability profiles and persistent difficulty on these tasks.
Significance. If the expert-derived atomic criteria and six-dimensional framework deliver reliable, unbiased coverage, LexRubric supplies a much-needed diagnostic instrument for high-stakes legal LLM evaluation that goes beyond aggregate accuracy. The public release of the 12,337 criteria and the 649 instances supports reproducibility and future extension.
major comments (2)
- [Abstract / validation description] The central claim that the 12,337 expert-written atomic criteria enable 'accurate evaluation and diagnostic analysis' (abstract) rests on the untested assumption that these criteria comprehensively capture response quality without systematic gaps or bias; the manuscript provides no inter-annotator agreement statistics for criterion creation, no coverage audit against legal task taxonomies, and no error analysis of missed failure modes.
- [Validation paragraph] The reliability validation compares judge-model scores to human judgments but reports neither the size of the held-out test set, the exact agreement metric (e.g., Cohen’s κ, Pearson r), nor per-dimension breakdowns; without these numbers it is impossible to assess whether the claimed reliability of model-based judgments holds for the diagnostic use case.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the validation of LexRubric. We address the two major comments point by point below and will revise the manuscript to improve transparency on the evaluation methodology.
read point-by-point responses
-
Referee: [Abstract / validation description] The central claim that the 12,337 expert-written atomic criteria enable 'accurate evaluation and diagnostic analysis' (abstract) rests on the untested assumption that these criteria comprehensively capture response quality without systematic gaps or bias; the manuscript provides no inter-annotator agreement statistics for criterion creation, no coverage audit against legal task taxonomies, and no error analysis of missed failure modes.
Authors: We agree that the manuscript would benefit from greater detail on criterion creation. The 12,337 atomic criteria were authored by legal-domain experts using the six-dimensional framework, but inter-annotator agreement was not computed. We will expand the methods section to describe the creation workflow and explicitly note the absence of IAA as a limitation. The 14 scenarios were chosen by experts to reflect representative legal consultation and judicial examination tasks; we will add a short mapping to standard legal task categories. We will also include an error analysis of instances where judge-model scores diverged from human scores to surface potential gaps in coverage. revision: partial
-
Referee: [Validation paragraph] The reliability validation compares judge-model scores to human judgments but reports neither the size of the held-out test set, the exact agreement metric (e.g., Cohen’s κ, Pearson r), nor per-dimension breakdowns; without these numbers it is impossible to assess whether the claimed reliability of model-based judgments holds for the diagnostic use case.
Authors: We thank the referee for pointing out this omission. The held-out set contained 100 instances. Agreement was measured with both Pearson correlation and Cohen’s κ, and we computed per-dimension scores across the six rubric dimensions. We will insert a dedicated validation subsection (with table) reporting the exact sample size, metrics, and per-dimension results so that readers can directly evaluate reliability for diagnostic use. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper constructs a benchmark dataset and rubric from externally sourced expert annotations (12,337 atomic criteria across 649 instances) under a six-dimensional framework, then validates scoring reliability via separate human-model agreement tests and evaluates 18 LLMs. No equations, fitted parameters, self-citations, or derivations are present that reduce any claimed result to the paper's own inputs by construction. The central claims rest on independent expert input and external validation steps rather than self-referential logic.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human expert judgments constitute reliable ground truth for scoring open-ended legal responses
Reference graph
Works this paper leans on
-
[1]
Brown, Tom B. and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel M. and Wu, Jeffrey and W...
2020
-
[2]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[3]
AI Open , volume =
Large language models in law: A survey , author =. AI Open , volume =. 2024 , doi =
2024
-
[4]
Humanities and Social Sciences Communications , volume =
Large Language Models in Legal Systems: A Survey , author =. Humanities and Social Sciences Communications , volume =. 2025 , doi =
2025
-
[5]
2026 , eprint=
Evaluation of Large Language Models in Legal Applications: Challenges, Methods, and Future Directions , author=. 2026 , eprint=
2026
-
[6]
2026 , eprint=
LegalOne: A Family of Foundation Models for Reliable Legal Reasoning , author=. 2026 , eprint=
2026
-
[7]
Magesh, Varun and Surani, Faiz and Dahl, Matthew and Suzgun, Mirac and Manning, Christopher D. and Ho, Daniel E. , title =. Journal of Empirical Legal Studies , volume =. doi:https://doi.org/10.1111/jels.12413 , url =
-
[8]
Chalkidis, Ilias and Jana, Abhik and Hartung, Dirk and Bommarito, Michael and Androutsopoulos, Ion and Katz, Daniel and Aletras, Nikolaos. L ex GLUE : A Benchmark Dataset for Legal Language Understanding in E nglish. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022....
-
[9]
JEC-QA: A Legal-Domain Question Answering Dataset , volume =
Zhong, Haoxi and Xiao, Chaojun and Tu, Cunchao and Zhang, Tianyang and Liu, Zhiyuan and Sun, Maosong , year =. JEC-QA: A Legal-Domain Question Answering Dataset , volume =. Proceedings of the AAAI Conference on Artificial Intelligence , doi =
-
[10]
2018 , eprint=
CAIL2018: A Large-Scale Legal Dataset for Judgment Prediction , author=. 2018 , eprint=
2018
-
[11]
Guha, Neel and Nyarko, Julian and Ho, Daniel E. and R\'. LEGALBENCH: a collaboratively built benchmark for measuring legal reasoning in large language models , year =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
-
[12]
L aw B ench: Benchmarking Legal Knowledge of Large Language Models
Fei, Zhiwei and Shen, Xiaoyu and Zhu, Dawei and Zhou, Fengzhe and Han, Zhuo and Huang, Alan and Zhang, Songyang and Chen, Kai and Yin, Zhixin and Shen, Zongwen and Ge, Jidong and Ng, Vincent. L aw B ench: Benchmarking Legal Knowledge of Large Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi...
-
[13]
LA i W : A C hinese Legal Large Language Models Benchmark
Dai, Yongfu and Feng, Duanyu and Huang, Jimin and Jia, Haochen and Xie, Qianqian and Zhang, Yifang and Han, Weiguang and Tian, Wei and Wang, Hao. LA i W : A C hinese Legal Large Language Models Benchmark. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[14]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Li, Haitao and Chen, You and Ai, Qingyao and Wu, Yueyue and Zhang, Ruizhe and Liu, Yiqun , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[15]
UCL -Bench: A C hinese User-Centric Legal Benchmark for Large Language Models
Gan, Ruoli and Feng, Duanyu and Zhang, Chen and Lin, Zhihang and Jia, Haochen and Wang, Hao and Cai, Zhenyang and Cui, Lei and Xie, Qianqian and Huang, Jimin and Wang, Benyou. UCL -Bench: A C hinese User-Centric Legal Benchmark for Large Language Models. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.find...
-
[16]
LegalAgentBench: Evaluating LLM agents in legal domain
Li, Haitao and Chen, Junjie and Yang, Jingli and Ai, Qingyao and Jia, Wei and Liu, Youfeng and Lin, Kai and Wu, Yueyue and Yuan, Guozhi and Hu, Yiran and Wang, Wuyue and Liu, Yiqun and Huang, Minlie. L egal A gent B ench: Evaluating LLM Agents in Legal Domain. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume ...
-
[17]
2026 , eprint=
PLawBench: A Rubric-Based Benchmark for Evaluating LLMs in Real-World Legal Practice , author=. 2026 , eprint=
2026
-
[18]
2025 , eprint=
HealthBench: Evaluating Large Language Models Towards Improved Human Health , author=. 2025 , eprint=
2025
-
[19]
2025 , eprint=
PRBench: Large-Scale Expert Rubrics for Evaluating High-Stakes Professional Reasoning , author=. 2025 , eprint=
2025
-
[20]
2025 , eprint=
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains , author=. 2025 , eprint=
2025
-
[21]
and Henderson, Peter and Ho, Daniel E
Zheng, Lucia and Guha, Neel and Anderson, Brandon R. and Henderson, Peter and Ho, Daniel E. , title =. 2021 , isbn =. doi:10.1145/3462757.3466088 , booktitle =
-
[22]
2021 , eprint=
CUAD: An Expert-Annotated NLP Dataset for Legal Contract Review , author=. 2021 , eprint=
2021
-
[23]
LEVEN : A Large-Scale C hinese Legal Event Detection Dataset
Yao, Feng and Xiao, Chaojun and Wang, Xiaozhi and Liu, Zhiyuan and Hou, Lei and Tu, Cunchao and Li, Juanzi and Liu, Yun and Shen, Weixing and Sun, Maosong. LEVEN : A Large-Scale C hinese Legal Event Detection Dataset. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.17
-
[24]
Li, Haitao and Shao, Yunqiu and Wu, Yueyue and Ai, Qingyao and Ma, Yixiao and Liu, Yiqun , title =. 2024 , isbn =. doi:10.1145/3626772.3657887 , booktitle =
-
[25]
2024 , eprint=
LegalBench-RAG: A Benchmark for Retrieval-Augmented Generation in the Legal Domain , author=. 2024 , eprint=
2024
-
[26]
Li, Haitao and Chen, Yifan and YiRan, Hu and Ai, Qingyao and Chen, Junjie and Yang, Xiaoyu and Yang, Jianhui and Wu, Yueyue and Liu, Zeyang and Liu, Yiqun , title =. 2025 , isbn =. doi:10.1145/3726302.3730340 , booktitle =
-
[27]
2025 , eprint=
CaseGen: A Benchmark for Multi-Stage Legal Case Documents Generation , author=. 2025 , eprint=
2025
-
[28]
2023 , eprint=
DISC-LawLLM: Fine-tuning Large Language Models for Intelligent Legal Services , author=. 2023 , eprint=
2023
-
[29]
2026 , eprint=
LEXam: Benchmarking Legal Reasoning on 340 Law Exams , author=. 2026 , eprint=
2026
-
[30]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[31]
2026 , eprint=
Kimi K2: Open Agentic Intelligence , author=. 2026 , eprint=
2026
-
[32]
2026 , eprint=
Kimi K2.5: Visual Agentic Intelligence , author=. 2026 , eprint=
2026
-
[33]
2026 , eprint=
GLM-5: from Vibe Coding to Agentic Engineering , author=. 2026 , eprint=
2026
-
[34]
2025 , eprint=
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models , author=. 2025 , eprint=
2025
-
[35]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[36]
LawLLM: Law Large Language Model for the US Legal System , url=
Shu, Dong and Zhao, Haoran and Liu, Xukun and Demeter, David and Du, Mengnan and Zhang, Yongfeng , year=. LawLLM: Law Large Language Model for the US Legal System , url=. doi:10.1145/3627673.3680020 , booktitle=
-
[37]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Colombo, Pierre and Pires, Telmo and Boudiaf, Malik and Melo, Rui and Culver, Dominic and Malaboeuf, Etienne and Hautreux, Gabriel and Charpentier, Johanne and Desa, Michael , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[38]
2024 , eprint=
SaulLM-7B: A pioneering Large Language Model for Law , author=. 2024 , eprint=
2024
-
[39]
2026 , eprint=
\ OneMillion-Bench: How Far are Language Agents from Human Experts? , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.