Escaping the KL Agreement Trap in On-Policy Distillation
Pith reviewed 2026-06-27 16:57 UTC · model grok-4.3
The pith
Detecting and terminating low-KL agreement traps in on-policy distillation filters weak supervision and raises student accuracy on math tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
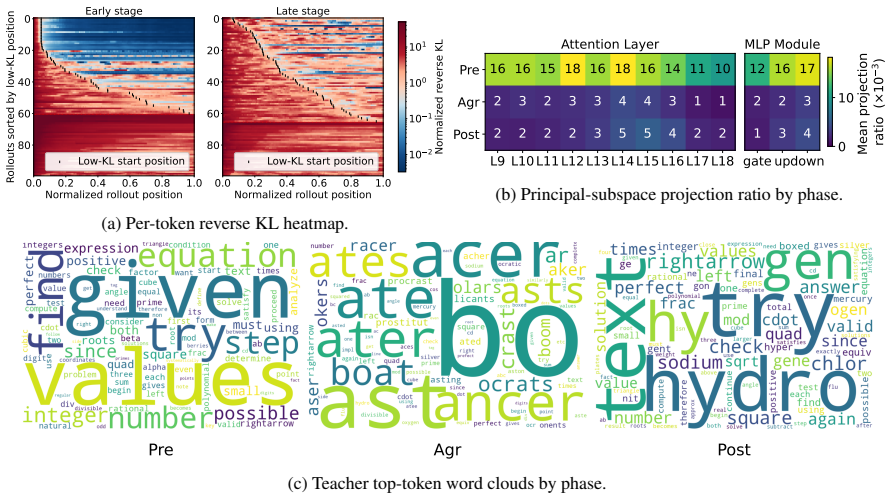
In on-policy distillation, when the student drifts into an unrecoverable prefix, the teacher may produce low reverse KL but little corrective signal, defining a low-KL agreement trap. Tokens during and after these traps yield less useful supervision. KAT detects persistent low-KL agreement with a dynamic training-adaptive threshold to terminate the rollout, filtering weak supervision from degenerate agreement.
What carries the argument
KAT (KL Agreement Trap Termination), an online termination rule that detects persistent low-KL agreement using a dynamic training-adaptive threshold to end rollouts early.
If this is right
- Improves average accuracy at k by 2.66% across four mathematical benchmarks.
- Improves pass rate at k by 3.43% on the same benchmarks.
- Reduces average rollout length by 59.73% during training.
- The method applies to on-policy distillation setups where teacher scores student rollouts.
Where Pith is reading between the lines
- Similar trap detection could apply to other teacher-student setups beyond math, such as code generation.
- If the dynamic threshold adapts well, it might generalize to non-on-policy methods.
- Shorter rollouts could reduce computational cost in large-scale distillation training.
- Testing KAT on non-math domains would reveal if the trap phenomenon is domain-specific.
Load-bearing premise
Persistent low-KL agreement reliably marks unrecoverable prefixes that give less useful supervision signals, and a dynamic threshold can spot these without losing good corrective signals.
What would settle it
Train two identical student models on the same data, one using KAT termination and one without, then compare if the accuracy and length benefits disappear when traps are allowed to continue.
Figures




read the original abstract
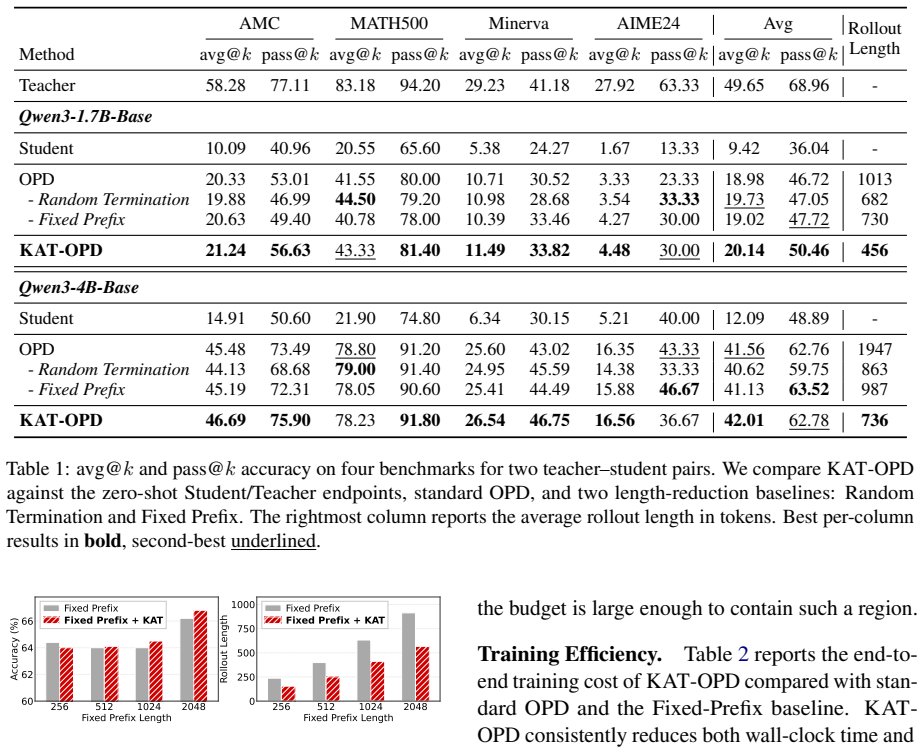
On-policy distillation (OPD) provides dense token-level supervision by asking a teacher to score student-generated rollouts. However, when the student drifts into an unrecoverable prefix, the teacher may locally agree with the degraded state, producing low reverse KL but little corrective training signal. We identify this persistent regime as a low-KL agreement trap. Further analyses show that tokens during and after such traps produce less useful supervision signals. We propose KAT (KL Agreement Trap Termination), an online OPD termination rule that detects persistent low-KL agreement with a dynamic training-adaptive threshold. By filtering weak supervision from degenerate agreement, KAT improves avg@k accuracy by 2.66% and pass@k by 3.43% across four mathematical benchmarks, while reducing average rollout length by 59.73%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies a 'low-KL agreement trap' in on-policy distillation (OPD) where the teacher locally agrees with a degraded student prefix (low reverse KL) yet supplies little corrective signal. It proposes KAT, an online termination rule that detects persistent low-KL agreement via a dynamic training-adaptive threshold, terminating such rollouts to filter weak supervision. Empirical results on four mathematical benchmarks report gains of +2.66% avg@k accuracy and +3.43% pass@k, accompanied by a 59.73% reduction in average rollout length.
Significance. If the dynamic threshold reliably isolates unrecoverable low-KL prefixes from recoverable ones that still carry corrective signal, KAT could improve both sample efficiency and final performance in OPD pipelines for reasoning tasks. The reported length reduction would additionally lower compute cost. However, the absence of independent supervision-quality metrics or length-controlled ablations leaves open whether the accuracy gains are causal or a side-effect of shorter trajectories.
major comments (2)
- [Abstract] Abstract: the headline improvements (+2.66% avg@k, +3.43% pass@k) are attributed to 'filtering weak supervision from degenerate agreement,' yet no token-level metric (gradient contribution, held-out prefix loss) or ablation against length-matched random termination is described. Without such controls, the claimed separation of useful vs. weak signals cannot be isolated from the 59.73% rollout-length reduction.
- [Abstract] Abstract: the central assumption that 'persistent low-KL agreement reliably indicates unrecoverable prefixes' is load-bearing for the termination rule, but the dynamic threshold definition, its adaptation schedule, and any sensitivity analysis are not provided, preventing verification that recoverable low-KL states are not prematurely terminated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying the supporting analyses already present in the manuscript while acknowledging where additional controls would strengthen the claims. We propose targeted revisions accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline improvements (+2.66% avg@k, +3.43% pass@k) are attributed to 'filtering weak supervision from degenerate agreement,' yet no token-level metric (gradient contribution, held-out prefix loss) or ablation against length-matched random termination is described. Without such controls, the claimed separation of useful vs. weak signals cannot be isolated from the 59.73% rollout-length reduction.
Authors: The manuscript already reports further analyses showing that tokens during and after low-KL agreement traps produce less useful supervision signals. We acknowledge, however, that an explicit ablation against length-matched random termination is absent, leaving open the possibility that some gains are attributable to shorter trajectories. We will add this ablation (comparing KAT termination to random early stopping at matched lengths) together with token-level metrics such as average gradient contribution and held-out prefix loss for trap versus non-trap states. These additions will be included in the revised version. revision: yes
-
Referee: [Abstract] Abstract: the central assumption that 'persistent low-KL agreement reliably indicates unrecoverable prefixes' is load-bearing for the termination rule, but the dynamic threshold definition, its adaptation schedule, and any sensitivity analysis are not provided, preventing verification that recoverable low-KL states are not prematurely terminated.
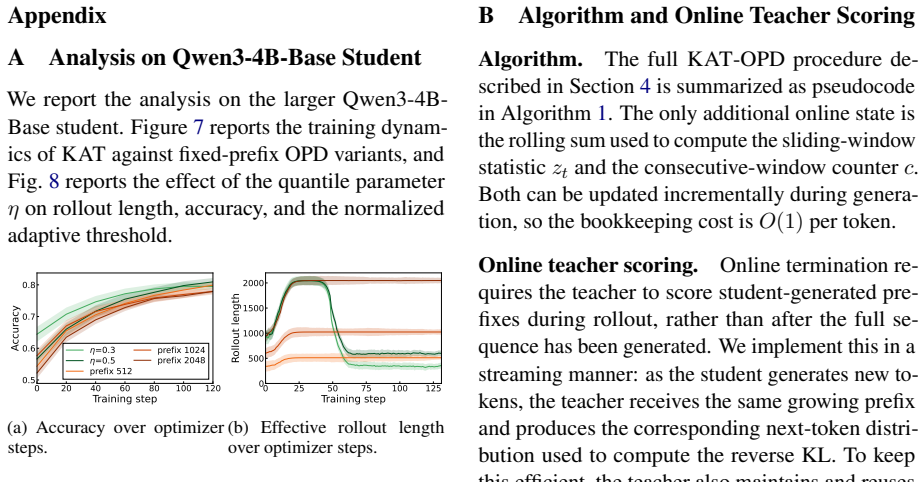
Authors: Section 3.2 defines the dynamic threshold as a training-adaptive quantity updated from the running mean and variance of observed reverse KL values, with termination triggered when the current KL remains below this threshold for a fixed number of consecutive tokens. The adaptation schedule is described in the same section. A sensitivity analysis over the adaptation window and persistence length appears in Appendix B, showing stable performance across reasonable hyper-parameter ranges. If the referee finds these descriptions insufficiently detailed, we will expand the main-text exposition and add further plots in the revision. revision: partial
Circularity Check
No significant circularity; empirical gains are self-contained experimental outcomes
full rationale
The paper identifies low-KL agreement traps and proposes KAT as a dynamic threshold-based termination rule for on-policy distillation. Reported improvements (2.66% avg@k, 3.43% pass@k, 59.73% shorter rollouts) are presented strictly as empirical results across four benchmarks. No equations, parameter fits, or self-citations appear in the abstract or described text that reduce any claimed prediction or result to its own inputs by construction. The derivation chain consists of an empirical observation followed by a practical filtering heuristic whose performance is measured externally; this is self-contained against benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2505.16782 , year=
Reasoning beyond language: A comprehensive survey on latent chain-of-thought reasoning , author=. arXiv preprint arXiv:2505.16782 , year=
-
[2]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[3]
arXiv preprint arXiv:2502.21321 , year=
Llm post-training: A deep dive into reasoning large language models , author=. arXiv preprint arXiv:2502.21321 , year=
-
[4]
International Conference on Learning Representations , volume=
Webrl: Training llm web agents via self-evolving online curriculum reinforcement learning , author=. International Conference on Learning Representations , volume=
-
[5]
arXiv preprint arXiv:2504.20073 , year=
Ragen: Understanding self-evolution in llm agents via multi-turn reinforcement learning , author=. arXiv preprint arXiv:2504.20073 , year=
-
[6]
arXiv preprint arXiv:2604.13016 , year=
Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe , author=. arXiv preprint arXiv:2604.13016 , year=
-
[7]
Thinking Machines Lab: Connectionism , year =
Kevin Lu and Thinking Machines Lab , title =. Thinking Machines Lab: Connectionism , year =
-
[8]
International Conference on Learning Representations , volume=
On-policy distillation of language models: Learning from self-generated mistakes , author=. International Conference on Learning Representations , volume=
-
[9]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
-
[10]
arXiv preprint arXiv:2601.02780 , year=
Mimo-v2-flash technical report , author=. arXiv preprint arXiv:2601.02780 , year=
-
[11]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[12]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[13]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[14]
arXiv preprint arXiv:2605.11739 , year=
Learning to Foresee: Unveiling the Unlocking Efficiency of On-Policy Distillation , author=. arXiv preprint arXiv:2605.11739 , year=
-
[15]
Computer , volume=
Matrix factorization techniques for recommender systems , author=. Computer , volume=. 2009 , publisher=
2009
-
[16]
arXiv preprint arXiv:2601.07155 , year=
Stable On-Policy Distillation through Adaptive Target Reformulation , author=. arXiv preprint arXiv:2601.07155 , year=
-
[17]
arXiv preprint arXiv:2603.07079 , year=
Entropy-Aware On-Policy Distillation of Language Models , author=. arXiv preprint arXiv:2603.07079 , year=
-
[18]
arXiv preprint arXiv:2603.11137 , year=
Scaling reasoning efficiently via relaxed on-policy distillation , author=. arXiv preprint arXiv:2603.11137 , year=
-
[19]
arXiv preprint arXiv:2602.12125 , year=
Learning beyond teacher: Generalized on-policy distillation with reward extrapolation , author=. arXiv preprint arXiv:2602.12125 , year=
-
[20]
arXiv preprint arXiv:2602.15260 , year=
Fast and effective on-policy distillation from reasoning prefixes , author=. arXiv preprint arXiv:2602.15260 , year=
-
[21]
Advances in Neural Information Processing Systems , volume=
Dapo: An open-source llm reinforcement learning system at scale , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
arXiv preprint arXiv:2504.13818 , year=
Not all rollouts are useful: Down-sampling rollouts in llm reinforcement learning , author=. arXiv preprint arXiv:2504.13818 , year=
-
[23]
Advances in Neural Information Processing Systems , volume=
Act only when it pays: Efficient reinforcement learning for llm reasoning via selective rollouts , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Online difficulty filtering for reasoning oriented reinforcement learning , author=. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[25]
arXiv preprint arXiv:2506.15050 , year=
Truncated proximal policy optimization , author=. arXiv preprint arXiv:2506.15050 , year=
-
[26]
arXiv preprint arXiv:2508.15260 , year=
Deep think with confidence , author=. arXiv preprint arXiv:2508.15260 , year=
-
[27]
Proceedings of the 2016 conference on empirical methods in natural language processing , pages=
Sequence-level knowledge distillation , author=. Proceedings of the 2016 conference on empirical methods in natural language processing , pages=
2016
-
[28]
arXiv preprint arXiv:2402.13116 , year=
A survey on knowledge distillation of large language models , author=. arXiv preprint arXiv:2402.13116 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.