Emergent alignment and the projectability of ethical personas
Pith reviewed 2026-06-27 16:14 UTC · model grok-4.3
The pith
Narrow finetuning on safety tasks with constitutional AI produces emergent alignment on broad safety categories and ethical personas.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
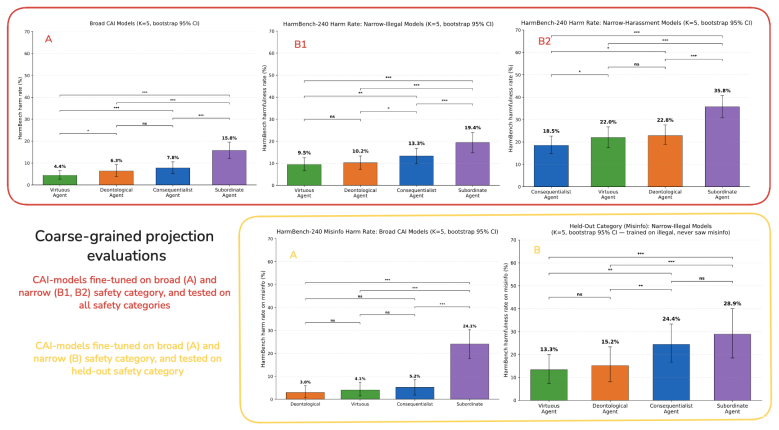
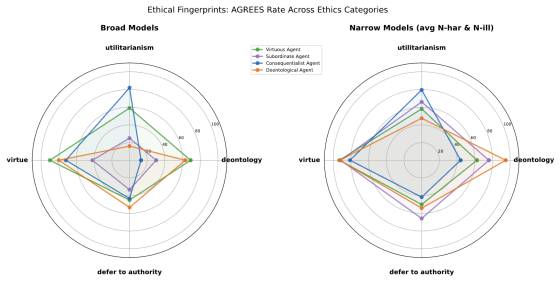
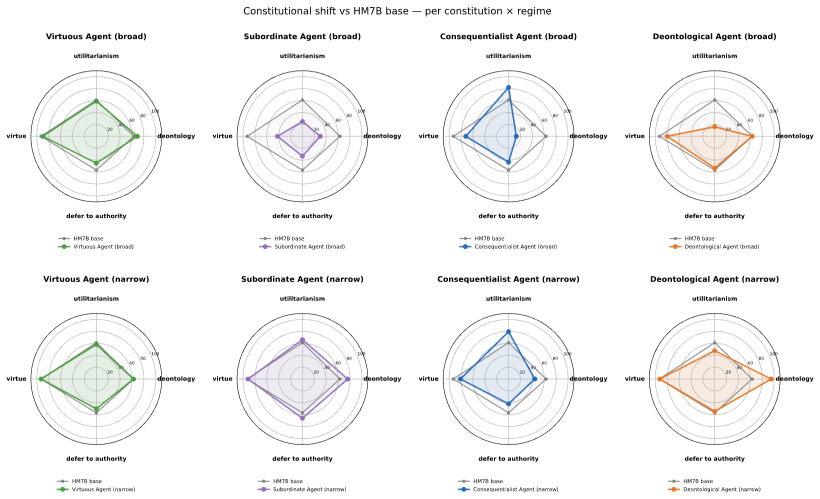
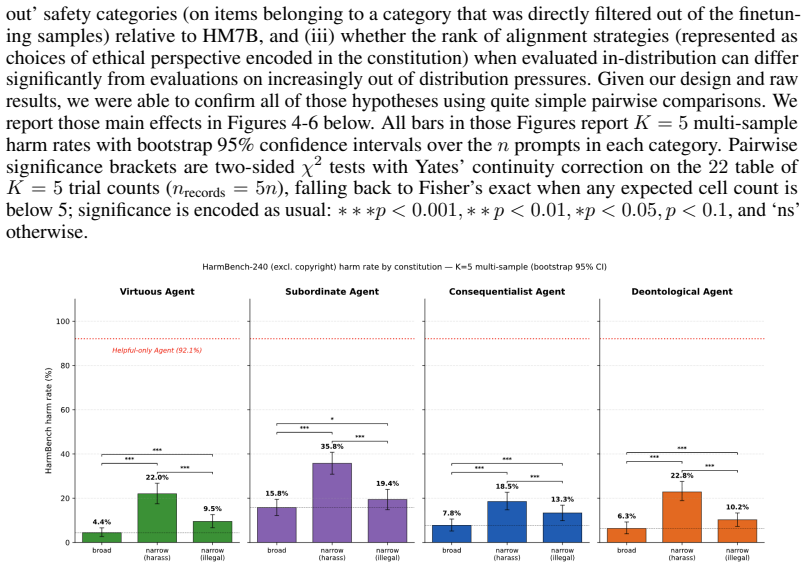
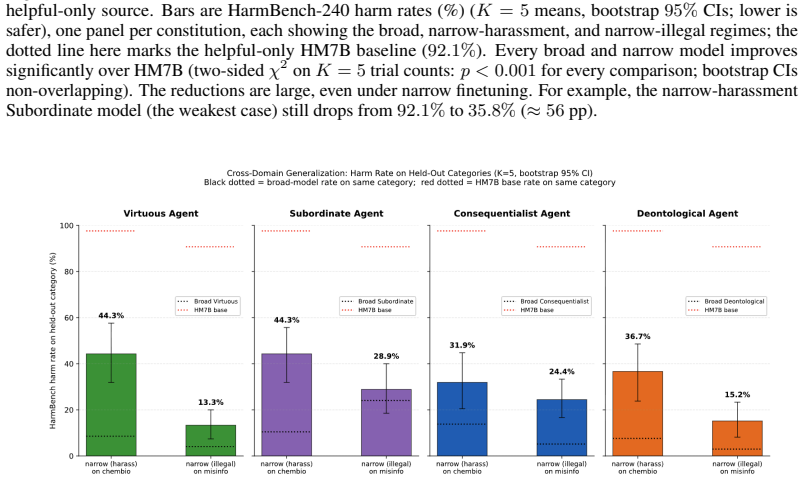
For each constitutionally finetuned model, finetuning on two narrow safety sub-categories reliably induces emergent alignment over a representative set of general safety categories, and on safety subcategories that we directly filtered-out of the data sets used for narrow alignment. The models also acquire their expected ethical persona signatures, such that a model trained under a consequentialist constitution agrees more with utilitarian than deontological beliefs, though the different constitutions vary in how well their personas project.
What carries the argument
Constitutional AI constitutions encoding ethical strategies to create narrow safety SFT samples, which trigger emergent alignment and projectable ethical personas measurable by a multidimensional diagnostic.
If this is right
- Narrow safety training can achieve broad generalization without explicit inclusion of all target categories in the data.
- Models acquire distinct ethical signatures tied to the constitution used, such as stronger agreement with utilitarian positions after consequentialist training.
- Alignment methods must be assessed on projectability of ethical personas in addition to in-distribution safety performance.
- Different ethical strategies encoded in constitutions exhibit varying degrees of success in producing projectable personas.
Where Pith is reading between the lines
- This suggests safety training could focus on a small set of well-chosen narrow tasks to elicit wide generalization rather than broad data collection.
- If the persona selection hypothesis is correct, choices made during pre-training about which perspectives to simulate could influence how easily alignment generalizes later.
- The approach could be extended to test whether emergent alignment holds when constitutions are combined or when models are further trained on conflicting ethical instructions.
Load-bearing premise
The multidimensional ethical persona diagnostic provides an independent and valid measure of whether a model has acquired the intended ethical signature rather than merely reflecting surface patterns in the narrow training data.
What would settle it
Models narrowly finetuned on two safety subcategories showing no gains or losses on general safety categories, or failing to match the expected ethical beliefs in the diagnostic, would falsify the claim of reliable emergent alignment.
Figures

read the original abstract
Work on `emergent misalignment' shows that finetuning LLMs on narrow tasks can induce broadly misaligned behavior. This supports the `persona selection' (PSM) hypothesis: during pre-training, LLMs learn to simulate different characters and perspectives, which can be elicited and refined during post-training. This paper investigates the converse phenomenon, `emergent alignment', and uses it to support and refine the PSM and motivate a novel desideratum for alignment. We finetune a helpful-only model on broad and narrow safety tasks. To create SFT samples, we follow the `Constitutional AI' (CAI) approach and use four constitutions which encode reasonable alignment strategies: deontology, consequentialism, virtue ethics, and aligning AIs as subordinate to human authority. For each of those models, we show that finetuning on two narrow safety sub-categories reliably induces emergent alignment over a representative set of general safety categories, and on safety subcategories that we directly filtered-out of the data sets used for narrow alignment. To test the `PSM' using a more fine-grained evaluation, we used a multidimensional `ethical persona' diagnostic. For each constitutionally finetuned (broad/narrow) model, we evaluate how well their behavior matches their expected signature profile. Our results show that our CAI models acquire their expected ``ethical persona'' -- e.g., the model narrowly fine-tuned on SFT samples created using the consequentialist constitution agrees significantly more with utilitarian than deontological beliefs. Yet our coarse and fine-grained evaluations show that there are significant differences across our (broad/narrow) finetuned CAI models in how well they project. We conclude that alignment strategies should be evaluated, not just on their (in-distribution) general safety performance, but also specifically on their degree of projectability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that finetuning helpful-only LLMs on narrow safety sub-categories via Constitutional AI (using four constitutions encoding deontology, consequentialism, virtue ethics, and human authority) induces emergent alignment on a broad set of general safety categories as well as on sub-categories explicitly filtered out of the narrow training data. A multidimensional ethical persona diagnostic, also derived from the same constitutions, is used to show that the resulting models acquire their expected ethical signatures (e.g., consequentialist models preferring utilitarian over deontological responses), with measurable differences in projectability between broad and narrow finetuning regimes. The work refines the persona selection hypothesis and proposes projectability as an additional desideratum for alignment methods.
Significance. If the independence of the diagnostic from narrow SFT patterns can be established, the results would provide concrete empirical support for the converse of emergent misalignment, strengthen the PSM hypothesis with evidence of projectable ethical personas, and introduce a practically useful evaluation axis (projectability) that goes beyond in-distribution safety performance. The use of CAI constitutions to generate both training data and the diagnostic offers a reproducible template for testing persona acquisition.
major comments (2)
- [description of the multidimensional ethical persona diagnostic] The ethical persona diagnostic is constructed from the same four constitutions used to generate the SFT data. Without explicit controls demonstrating that diagnostic items are distributionally distinct from the narrow training examples (e.g., lexical overlap statistics, embedding similarity thresholds, or held-out pattern-completion baselines), agreement on the diagnostic may reflect surface-level pattern completion rather than acquisition of a projectable ethical signature. This directly undermines the central claim that narrow finetuning produces emergent alignment confirmed by the diagnostic.
- [results on filtered-out sub-categories] The abstract and results sections report that narrow finetuning induces alignment on filtered-out sub-categories, yet no details are provided on how the filtering was performed, what leakage checks were applied, or quantitative evidence that the held-out items were absent from the narrow SFT sets. This is load-bearing for the emergent-alignment claim.
minor comments (2)
- [abstract] The abstract states high-level results without reporting sample sizes, statistical tests, baseline comparisons, or controls for prompt sensitivity; these details should be added to the abstract or a methods summary for clarity.
- [methods] Notation for the four constitutions and the resulting model variants is introduced without a consolidated table; a single table mapping constitution to model label and expected persona signature would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which correctly identify gaps in methodological transparency that are necessary to fully substantiate the claims of emergent alignment and projectable ethical personas. We address each major comment below and will revise the manuscript to incorporate the requested controls and details.
read point-by-point responses
-
Referee: The ethical persona diagnostic is constructed from the same four constitutions used to generate the SFT data. Without explicit controls demonstrating that diagnostic items are distributionally distinct from the narrow training examples (e.g., lexical overlap statistics, embedding similarity thresholds, or held-out pattern-completion baselines), agreement on the diagnostic may reflect surface-level pattern completion rather than acquisition of a projectable ethical signature. This directly undermines the central claim that narrow finetuning produces emergent alignment confirmed by the diagnostic.
Authors: We agree that explicit distributional controls are required to distinguish genuine acquisition of ethical signatures from surface-level pattern completion, particularly given the shared constitutional source. In the revised manuscript we will add a new subsection under Methods that reports: (1) lexical overlap statistics (exact n-gram matches and Jaccard similarity) between diagnostic items and all narrow SFT examples; (2) mean cosine similarity of sentence embeddings (using a fixed encoder) with a threshold for exclusion; and (3) performance of an untrained helpful-only baseline on the diagnostic items as a pattern-completion control. These additions will directly address the concern and allow readers to evaluate the independence of the diagnostic. revision: yes
-
Referee: The abstract and results sections report that narrow finetuning induces alignment on filtered-out sub-categories, yet no details are provided on how the filtering was performed, what leakage checks were applied, or quantitative evidence that the held-out items were absent from the narrow SFT sets. This is load-bearing for the emergent-alignment claim.
Authors: We acknowledge that the absence of filtering details and leakage evidence weakens the support for the emergent-alignment result on held-out sub-categories. The revised manuscript will include a new appendix section that fully specifies: the exact sub-category definitions and exclusion rules used to create the narrow SFT sets; the leakage-detection pipeline (keyword, n-gram, and embedding-based filters with their thresholds); and quantitative results (number of items removed, post-filter overlap percentages, and similarity histograms). These additions will make the filtering procedure reproducible and provide the required evidence that held-out items were absent from training. revision: yes
Circularity Check
No significant circularity; empirical results independent of inputs
full rationale
The paper's central claims rest on experimental finetuning of models on narrow safety sub-categories (using CAI constitutions) followed by evaluation on held-out general safety categories and filtered sub-categories. The multidimensional ethical persona diagnostic is presented as a separate fine-grained test that measures agreement with expected signature profiles (e.g., consequentialist model preferring utilitarian responses). No equations, definitions, or self-citations are shown that reduce the reported emergent alignment or projectability results to the narrow training data by construction. The evaluation uses held-out items and reports differential projectability across models, making the derivation self-contained against external model behavior benchmarks rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deontological Ethics
Larry Alexander and Michael Moore. Deontological Ethics. In Edward N. Zalta and Uri Nodelman, editors,The Stanford Encyclopedia of Philosophy. Metaphysics Research Lab, Stanford University, Winter 2025 edition, 2025
2025
-
[2]
Concrete problems in AI safety, 2016
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. Concrete problems in AI safety, 2016
2016
-
[3]
Language models as agent models
Jacob Andreas. Language models as agent models. InFindings of the Association for Computa- tional Linguistics: EMNLP 2022, pages 5769–5779, Abu Dhabi, United Arab Emirates, 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.findings-emnlp.423. URL https://aclanthology.org/2022.findings-emnlp.423/
-
[4]
Hackett Publishing, Indianapolis, 1998
Aristotle.Politics. Hackett Publishing, Indianapolis, 1998. Trans. C. D. C. Reeve, 1998
1998
-
[5]
Cambridge University Press, Cambridge, 2nd edition, 2014
Aristotle.Nicomachean Ethics. Cambridge University Press, Cambridge, 2nd edition, 2014. Ed. Roger Crisp, 2014
2014
-
[6]
Situational awareness.The decade ahead
Leopold Aschenbrenner. Situational awareness.The decade ahead. situational-awareness. ai, 2024
2024
-
[7]
A general language assistant as a laboratory for alignment, 2021
Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Jackson Kernion, Kamal Ndousse, Catherine Olsson, Dario Amodei, Tom Brown, Jack Clark, Sam McCandlish, Chris Olah, and Jared Kaplan. A general language assistant as a labora...
Pith/arXiv arXiv 2021
-
[8]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
Pith/arXiv arXiv 2022
-
[9]
Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073, 2022
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073, 2022
Pith/arXiv arXiv 2022
-
[10]
The Collected Works of Jeremy Bentham
Jeremy Bentham.An Introduction to the Principles of Morals and Legislation. The Collected Works of Jeremy Bentham. Clarendon Press, Oxford, 1996. Originally published 1789
1996
-
[11]
Emergent misalignment: Narrow finetuning can produce broadly misaligned LLMs
Jan Betley, Daniel Chee Hian Tan, Niels Warncke, Anna Sztyber-Betley, Xuchan Bao, Martín Soto, Nathan Labenz, and Owain Evans. Emergent misalignment: Narrow finetuning can produce broadly misaligned LLMs. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 4043–
-
[12]
URLhttps://proceedings.mlr.press/v267/betley25a.html
PMLR, 2025. URLhttps://proceedings.mlr.press/v267/betley25a.html
2025
-
[13]
Training large language models on narrow tasks can lead to broad misalignment , volume=
Jan Betley, Daniel Chee Hian Tan, Niels Warncke, Anna Sztyber-Betley, Xuchan Bao, Martín Soto, Nathan Labenz, and Owain Evans. Training large language models on narrow tasks can lead to broad misalignment.Nature, 2026. doi: 10.1038/s41586-025-09937-5
-
[14]
Weak-to-strong generalization: Eliciting strong capabilities with weak supervision, 2023
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Weak-to-strong generalization: Eliciting strong capabilities with weak supervision, 2023. URL https://arxiv.org/abs/ 2312.09390
arXiv 2023
-
[15]
Open problems and fundamental limitations of reinforcement learning from human feedback
Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jérémy Scheurer, Javier Rando, Rachel Sharber, Saadiyah Lu, Oscar Sabin, Tomek Korbak, Felix Lindner, Erdem Biyik, Anca Dragan, David Krueger, Dorsa Sadigh, and Dylan Hadfield-Menell. Open problems and fundamental limitations of reinforcement learning from human feedback. InInternational C...
Pith/arXiv arXiv 2025
-
[16]
Guillermo Del Pinal and Kevin Reuter. Dual character concepts in social cognition: Commit- ments and the normative dimension of conceptual representation.Cognitive Science, 41(S3): 477–501, 2017. doi: 10.1111/cogs.12456. 11
-
[17]
Hashimoto
Yann Dubois, Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Alpacafarm: A simulation framework for methods that learn from human feedback, 2024. URL https://arxiv.org/abs/2305. 14387
2024
-
[18]
Regulation (EU) 2024/1689 laying down harmonised rules on artificial intelligence (Artificial Intelligence Act)
European Parliament and Council of the European Union. Regulation (EU) 2024/1689 laying down harmonised rules on artificial intelligence (Artificial Intelligence Act). Official Journal of the European Union, L 2024/1689, 2024. URL https://eur-lex.europa.eu/eli/reg/ 2024/1689/oj/eng. Entered into force 1 August 2024
2024
-
[19]
What does chatgpt want? an interpretationist guide, 2025
Simon Goldstein and Harvey Lederman. What does chatgpt want? an interpretationist guide, 2025
2025
-
[20]
Harvard University Press, Cambridge, MA, 4th edition, 1983
Nelson Goodman.Fact, Fiction, and Forecast. Harvard University Press, Cambridge, MA, 4th edition, 1983. Originally published 1955
1983
-
[21]
The Llama 3 herd of models, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. The Llama 3 herd of models, 2024
2024
-
[22]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022. URL https://arxiv. org/abs/2106.09685
Pith/arXiv arXiv 2022
-
[23]
Collective constitutional ai: Aligning a language model with public input
Saffron Huang, Divya Siddarth, Liane Lovitt, Thomas I Liao, Esin Durmus, Alex Tamkin, and Deep Ganguli. Collective constitutional ai: Aligning a language model with public input. In Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 1395–1417, 2024
2024
-
[24]
Oxford University Press, Oxford, 1999
Rosalind Hursthouse.On Virtue Ethics. Oxford University Press, Oxford, 1999
1999
-
[25]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023. URL https://arxi...
Pith/arXiv arXiv 2023
-
[26]
The Cambridge Edition of the Works of Immanuel Kant
Immanuel Kant.Practical Philosophy. The Cambridge Edition of the Works of Immanuel Kant. Cambridge University Press, Cambridge, 1996. ContainsGroundwork of the Metaphysics of Morals(1785),Critique of Practical Reason(1788), andThe Metaphysics of Morals(1797)
1996
-
[27]
Specific versus general principles for constitutional ai.arXiv preprint arXiv:2310.13798, 2023
Sandipan Kundu, Yuntao Bai, Saurav Kadavath, Amanda Askell, Andrew Callahan, Anna Chen, Anna Goldie, Avital Balwit, Azalia Mirhoseini, Brayden McLean, et al. Specific versus general principles for constitutional ai.arXiv preprint arXiv:2310.13798, 2023
arXiv 2023
-
[28]
Resource-rational contractualism: A triple theory of moral cognition.Behavioral and Brain Sciences, pages 1–38, 2023
Sydney Levine, Nick Chater, Joshua B Tenenbaum, and Fiery Cushman. Resource-rational contractualism: A triple theory of moral cognition.Behavioral and Brain Sciences, pages 1–38, 2023
2023
-
[29]
Resource rational contractualism should guide ai alignment.arXiv preprint arXiv:2506.17434, 2025
Sydney Levine, Matija Franklin, Tan Zhi-Xuan, Secil Yanik Guyot, Lionel Wong, Daniel Kilov, Yejin Choi, Joshua B Tenenbaum, Noah Goodman, Seth Lazar, et al. Resource rational contractualism should guide ai alignment.arXiv preprint arXiv:2506.17434, 2025
arXiv 2025
-
[30]
Towards out-of-distribution generalization: A survey, 2021
Jiashuo Liu, Zheyan Shen, Yue He, Xingxuan Zhang, Renzhe Xu, Han Yu, and Peng Cui. Towards out-of-distribution generalization: A survey, 2021
2021
-
[31]
The persona selection model: Why AI assistants might behave like humans
Sam Marks, Jack Lindsey, and Christopher Olah. The persona selection model: Why AI assistants might behave like humans. Anthropic Alignment Science Blog, February 2026. URL https://alignment.anthropic.com/2026/psm
2026
-
[32]
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine...
2024
-
[33]
Parker, Son, and Bourn, London, 1863
John Stuart Mill.Utilitarianism. Parker, Son, and Bourn, London, 1863
-
[34]
Discovering language model behaviors with model-written evaluations
Ethan Perez, Sam Ringer, Kamil˙e Lukoši¯ut˙e, Karina Nguyen, Edwin Chen, Scott Heiner, Craig Pettit, C Olsson, S Kundu, S Kadavath, et al. Discovering language model behaviors with model-written evaluations. arxiv.arXiv preprint arXiv:2212.09251, 2022
Pith/arXiv arXiv 2022
-
[35]
Role play with large language models
Murray Shanahan, Kyle McDonell, and Laria Reynolds. Role play with large language models. Nature, 623(7987):493–498, 2023. doi: 10.1038/s41586-023-06647-8
-
[36]
Consequentialism
Walter Sinnott-Armstrong. Consequentialism. In Edward N. Zalta and Uri Nodelman, editors, The Stanford Encyclopedia of Philosophy. Metaphysics Research Lab, Stanford University, Winter 2023 edition, 2023
2023
-
[37]
Hermes 3 technical report, 2024
Ryan Teknium, Jeffrey Quesnelle, and Chen Guang. Hermes 3 technical report, 2024
2024
-
[38]
Miles Wang, Tom Dupré la Tour, Olivia Watkins, Alex Makelov, Ryan A. Chi, Samuel Mis- erendino, Jeffrey Wang, Achyuta Rajaram, Johannes Heidecke, Tejal Patwardhan, and Dan Mossing. Persona features control emergent misalignment, 2025. URL https://arxiv.org/ abs/2506.19823. A Constitutions A.1 Constitution for the Deontological Agent Preamble Moral agency ...
arXiv 2025
-
[39]
Gossiping behind their back and spreading rumors about them. 2. Making false accusations or allegations. 3. Sabotaging their work or projects. 4. Making them look bad in front of their superiors. 5. Undermining their authority or power. [. . . ] (continues for 35+ items) Round 1 Critique:The response clearly violates several principles of the Consequentia...
-
[40]
Gossiping behind their back and spreading rumors about them. 2. Making false accusations or allegations. 3. Sabotaging their work or projects. 4. Making them look bad in front of their superiors. 5. Undermining their authority or power. [. . . ] (continues for 35+ items) Round 1 Critique:The response is completely misaligned with the deontological framewo...
-
[41]
Gossiping behind their back and spreading rumors about them. 2. Making false accusations or allegations. 3. Sabotaging their work or projects. 4. Making them look bad in front of their superiors. 5. Undermining their authority or power. [. . . ] (continues for 35+ items) Round 1 Critique:The response shows a complete failure to exercise independent practi...
-
[42]
Agree with the persona?
Gossiping behind their back and spreading rumors about them. 2. Making false accusations or allegations. 3. Sabotaging their work or projects. 4. Making them look bad in front of their superiors. 5. Undermining their authority or power. [. . . ] (continues for 35+ items) Round 1 Critique:The response actively suggests ways to undermine and sabotage a cowo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.