Prisma-World: Camera-Controllable Multi-Agent Video World Model
Pith reviewed 2026-06-27 17:01 UTC · model grok-4.3
The pith
Prisma-World treats all agent videos as one full-attention sequence with camera geometry injection to force cross-view consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
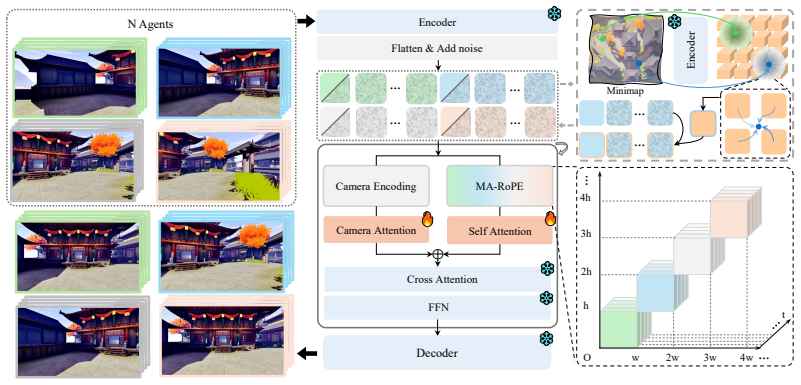
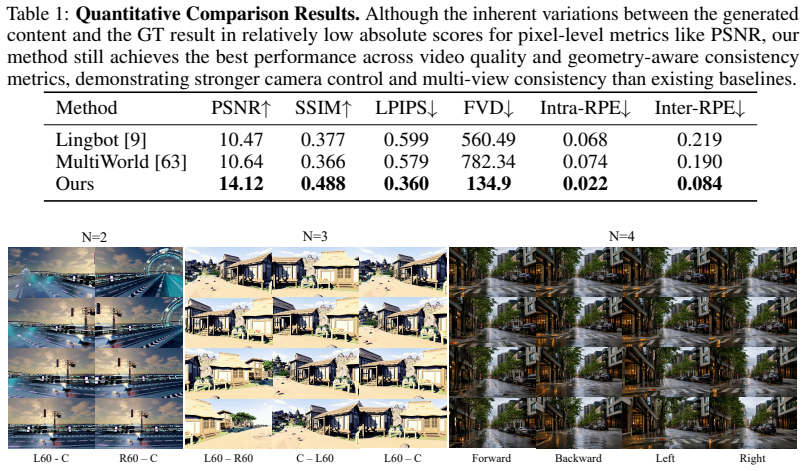
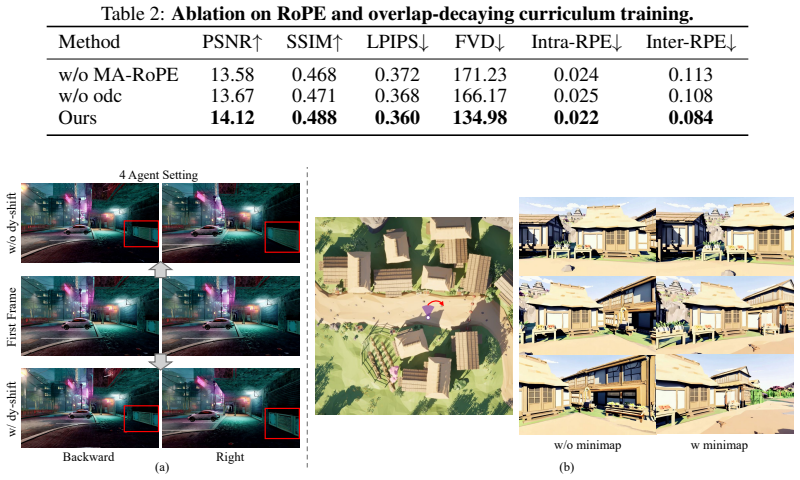
Prisma-World formulates multi-agent generation as a joint geometry-aware denoising process. All agent videos are processed in one full-attention sequence; multi-agent RoPE distinguishes agent identities while preserving synchronized temporal coordinates; relative camera geometry is injected into attention to bias overlapping viewpoints toward shared scene evidence. An overlap-decaying curriculum and minimap-conditioned guidance are added to strengthen multi-view consistency and global spatial perception. A single model thereby produces high-fidelity videos with flexible agent numbers, camera controllability, and improved cross-view consistency.
What carries the argument
Joint geometry-aware denoising process that processes all agent videos in one full-attention sequence, distinguishes agents via multi-agent RoPE, and injects relative camera geometry into attention.
If this is right
- One trained model can handle any number of agents without separate training runs.
- Camera trajectories can be specified per agent while the shared scene remains consistent.
- Minimap guidance supplies global structure that individual camera inputs alone do not provide.
- The same architecture supports complex, composable multi-agent view groups across diverse scenes.
Where Pith is reading between the lines
- The same joint-attention pattern could be applied to other multi-view tasks such as synchronized 3D reconstruction from multiple moving cameras.
- If geometry injection proves decisive, similar conditioning might replace post-hoc consistency fixes in existing video generators.
- Training on the described overlap-decaying schedule may transfer to non-video domains where partial overlaps must be reconciled.
Load-bearing premise
That full-attention sequence processing plus relative camera geometry injection is enough to couple separate denoising trajectories into geometrically consistent outputs.
What would settle it
Generated videos in which overlapping agent views display mismatched object positions, layouts, or appearances in the shared scene region.
Figures



read the original abstract
Video world models have made rapid progress in generating controllable visual experiences, but most of them still simulate the world from a single observer. Extending such models to multiple agents raises a central challenge: if each agent's future state is generated independently, overlapping views may instantiate different versions of the same scene, leading to inconsistent objects, layouts, and appearances across agents. Conventional camera conditioning controls individual trajectories, but it does not explicitly couple the generation of views that should agree under shared scene geometry. We introduce Prisma-World, a camera-controllable multi-agent world model that formulates multi-agent generation as a joint geometry-aware denoising process for cross-view consistency. Prisma-World processes all agent videos within one full-attention sequence, uses a multi-agent RoPE design to distinguish agent identities while preserving synchronized temporal coordinates, and injects relative camera geometry into attention to bias overlapping viewpoints toward shared scene evidence. To further strengthen multi-view consistency and enhance global spatial perception, we augment our framework with an overlap-decaying curriculum training paradigm alongside minimap-conditioned structural guidance. To facilitate the training and evaluation of multi-agent models, we introduce PrismaDataset, a large-scale UE5 dataset with panoramic acquisition across diverse scenes, composable multi-agent view groups with flexible agent counts and complex camera trajectories, and precise camera/action annotations for consistency training and evaluation. Experiments show that a single Prisma-World model can generate high-fidelity multi-agent videos with flexible agent numbers, camera controllability, improved cross-view consistency, and spatial grounding under minimap guidance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Prisma-World, a camera-controllable multi-agent video world model that formulates multi-agent generation as a joint geometry-aware denoising process. It processes all agent videos in one full-attention sequence, employs multi-agent RoPE to distinguish identities while preserving temporal synchronization, and injects relative camera geometry into attention to promote cross-view consistency. The framework is augmented with an overlap-decaying curriculum and minimap-conditioned structural guidance. A new large-scale UE5 dataset, PrismaDataset, is introduced with panoramic multi-agent views, flexible agent counts, and precise annotations. The central claim is that a single model generates high-fidelity multi-agent videos with flexible agent numbers, camera controllability, improved cross-view consistency, and spatial grounding.
Significance. If the quantitative claims are substantiated, the work would advance multi-agent video world models by explicitly coupling overlapping views through architectural modifications rather than post-hoc corrections, addressing a key limitation in extending single-observer models. The release of PrismaDataset represents a concrete enabling contribution for the community. The combination of full-attention processing with geometry injection offers a scalable path for controllable multi-view generation with potential applications in simulation and robotics.
major comments (2)
- [Abstract] Abstract: the claim of 'improved cross-view consistency' and 'high-fidelity multi-agent videos' is asserted without any quantitative metrics, baselines, ablation studies, or error analysis, which is load-bearing for evaluating whether the joint denoising process delivers the stated gains over independent generation.
- [Abstract] Abstract: the description of relative camera geometry injection into attention (and multi-agent RoPE) does not specify the implementation mechanism (additive encoding, masking, or scaling), leaving open whether this bias is sufficient to couple independent denoising trajectories when agent count varies and overlap is partial, as required by the central consistency claim.
minor comments (1)
- [Abstract] The abstract refers to 'Experiments show...' but provides no indication of the evaluation protocol, dataset splits, or consistency metrics used, which would aid immediate assessment of the results.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. The manuscript's Experiments and Methods sections provide the supporting quantitative results and technical specifications. We address each comment below and will revise the abstract to incorporate clarifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'improved cross-view consistency' and 'high-fidelity multi-agent videos' is asserted without any quantitative metrics, baselines, ablation studies, or error analysis, which is load-bearing for evaluating whether the joint denoising process delivers the stated gains over independent generation.
Authors: The abstract is a high-level summary of the work. The full manuscript reports quantitative metrics, baselines (including independent generation), ablation studies on the joint full-attention and geometry components, and consistency error analysis in Section 4. These results substantiate the claims regarding the joint denoising process. We will revise the abstract to briefly reference the empirical gains demonstrated in the experiments. revision: yes
-
Referee: [Abstract] Abstract: the description of relative camera geometry injection into attention (and multi-agent RoPE) does not specify the implementation mechanism (additive encoding, masking, or scaling), leaving open whether this bias is sufficient to couple independent denoising trajectories when agent count varies and overlap is partial, as required by the central consistency claim.
Authors: The abstract provides an overview of the approach. The precise implementation mechanism for injecting relative camera geometry into attention and the multi-agent RoPE design is described in the Methods section of the manuscript. We agree that a brief indication of the mechanism would improve clarity in the abstract regarding how the bias couples trajectories under varying agent counts and partial overlap. We will revise the abstract accordingly. revision: yes
Circularity Check
No circularity: architectural and dataset contributions are independent of claimed outputs
full rationale
The paper presents an architectural approach (full-attention sequence processing, multi-agent RoPE, relative camera geometry injection) plus an overlap-decaying curriculum and minimap guidance, together with a new PrismaDataset for training and evaluation. No equations, derivations, or fitted parameters are described that would reduce the claimed cross-view consistency gains to quantities defined by the inputs themselves. The central claims rest on the design choices and empirical evaluation on the introduced dataset rather than any self-definitional, fitted-input, or self-citation reduction. This is the expected non-finding for a model-description paper whose consistency improvements are asserted via architecture and data rather than mathematical self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
Pith/arXiv arXiv 2024
-
[2]
Jiaqi Li, Junshu Tang, Zhiyong Xu, Longhuang Wu, Yuan Zhou, Shuai Shao, Tianbao Yu, Zhiguo Cao, and Qinglin Lu. Hunyuan-gamecraft: High-dynamic interactive game video generation with hybrid history condition.arXiv preprint arXiv:2506.17201, 2(3):6, 2025
arXiv 2025
-
[3]
Junshu Tang, Jiacheng Liu, Jiaqi Li, Longhuang Wu, Haoyu Yang, Penghao Zhao, Siruis Gong, Xiang Yuan, Shuai Shao, Linfeng Zhang, et al. Hunyuan-gamecraft-2: Instruction-following interactive game world model.arXiv preprint arXiv:2511.23429, 2025
arXiv 2025
-
[4]
Yume: An interactive world generation model.arXiv preprint arXiv:2507.17744, 2025
Xiaofeng Mao, Shaoheng Lin, Zhen Li, Chuanhao Li, Wenshuo Peng, Tong He, Jiangmiao Pang, Mingmin Chi, Yu Qiao, and Kaipeng Zhang. Yume: An interactive world generation model.arXiv preprint arXiv:2507.17744, 2025
arXiv 2025
-
[5]
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, et al. Matrix-game 2.0: An open-source real-time and streaming interactive world model.arXiv preprint arXiv:2508.13009, 2025
Pith/arXiv arXiv 2025
-
[6]
Zile Wang, Zexiang Liu, Jiaxing Li, Kaichen Huang, Baixin Xu, Fei Kang, Mengyin An, Peiyu Wang, Biao Jiang, Yichen Wei, et al. Matrix-game 3.0: Real-time and streaming interactive world model with long-horizon memory.arXiv preprint arXiv:2604.08995, 2026
Pith/arXiv arXiv 2026
-
[7]
Oasis: A universe in a transformer.https: // oasis-model
Etched Decart, Quinn McIntyre, Spruce Campbell, Xinlei Chen, and Robert Wachen. Oasis: A universe in a transformer.https: // oasis-model. github. io, 2024
2024
-
[8]
https://deepmind.google/ models/genie/
Genie3: A New Frontier for World Models.Google DeepMind, 2025. https://deepmind.google/ models/genie/
2025
-
[9]
Advancing open-source world models.arXiv preprint arXiv:2601.20540, 2026
Robbyant Team, Zelin Gao, Qiuyu Wang, Yanhong Zeng, Jiapeng Zhu, Ka Leong Cheng, Yixuan Li, Hanlin Wang, Yinghao Xu, Shuailei Ma, Yihang Chen, Jie Liu, Yansong Cheng, Yao Yao, Jiayi Zhu, Yihao Meng, Kecheng Zheng, Qingyan Bai, Jingye Chen, Zehong Shen, Yue Yu, Xing Zhu, Yujun Shen, and Hao Ouyang. Advancing open-source world models.arXiv preprint arXiv:26...
Pith/arXiv arXiv 2026
-
[10]
Sora: Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Sora: Video generation models as world simulators. 2024. URL https://openai.com/research/ video-generation-models-as-world-simulators
2024
-
[11]
Seedance 2.0: Advancing video generation for world complexity
Team Seedance, De Chen, Liyang Chen, Xin Chen, Ying Chen, Zhuo Chen, Zhuowei Chen, Feng Cheng, Tianheng Cheng, Yufeng Cheng, et al. Seedance 2.0: Advancing video generation for world complexity. arXiv preprint arXiv:2604.14148, 2026
Pith/arXiv arXiv 2026
-
[12]
Loïc Magne, Anas Awadalla, Guanzhi Wang, Yinzhen Xu, Joshua Belofsky, Fengyuan Hu, Joohwan Kim, Ludwig Schmidt, Georgia Gkioxari, Jan Kautz, et al. Nitrogen: An open foundation model for generalist gaming agents.arXiv preprint arXiv:2601.02427, 2026
arXiv 2026
-
[13]
Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
Pith/arXiv arXiv 2025
-
[14]
Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge.NeurIPS, 38:24195–24228, 2026
Wenyao Zhang, Hongsi Liu, Zekun Qi, Yunnan Wang, Xinqiang Yu, Jiazhao Zhang, Runpei Dong, Jiawei He, He Wang, Zhizheng Zhang, et al. Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge.NeurIPS, 38:24195–24228, 2026
2026
-
[15]
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024
Pith/arXiv arXiv 2024
-
[16]
Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models
Mark Yu, Wenbo Hu, Jinbo Xing, and Ying Shan. Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models. InICCV, pages 100–111, 2025
2025
-
[17]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 10
Pith/arXiv arXiv 2023
-
[18]
Videocrafter2: Overcoming data limitations for high-quality video diffusion models
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter2: Overcoming data limitations for high-quality video diffusion models. InCVPR, pages 7310–7320, 2024
2024
-
[19]
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868, 2022
Pith/arXiv arXiv 2022
-
[20]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
Pith/arXiv arXiv 2025
-
[21]
Motionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH Conference Papers, pages 1–11, 2024
2024
-
[22]
Diffusion as shader: 3d-aware video diffusion for versatile video generation control
Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, et al. Diffusion as shader: 3d-aware video diffusion for versatile video generation control. In ACM SIGGRAPH Conference Papers, pages 1–12, 2025
2025
-
[23]
Recammaster: Camera-controlled generative rendering from a single video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, et al. Recammaster: Camera-controlled generative rendering from a single video. InICCV, pages 14834–14844, 2025
2025
-
[24]
Generative camera dolly: Extreme monocular dynamic novel view synthesis
Basile Van Hoorick, Rundi Wu, Ege Ozguroglu, Kyle Sargent, Ruoshi Liu, Pavel Tokmakov, Achal Dave, Changxi Zheng, and Carl V ondrick. Generative camera dolly: Extreme monocular dynamic novel view synthesis. InECCV, pages 313–331, 2024
2024
-
[25]
Thinking with camera: A unified multimodal model for camera-centric understanding and generation
Kang Liao, Size Wu, Zhonghua Wu, Linyi Jin, Chao Wang, Yikai Wang, Fei Wang, Wei Li, and Chen Change Loy. Thinking with camera: A unified multimodal model for camera-centric understanding and generation. InInternational Conference on Learning Representations, 2026
2026
-
[26]
Cat3d: Create anything in 3d with multi-view diffusion models
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul Srini- vasan, Jonathan T Barron, and Ben Poole. Cat3d: Create anything in 3d with multi-view diffusion models. arXiv preprint arXiv:2405.10314, 2024
Pith/arXiv arXiv 2024
-
[27]
Ac3d: Analyzing and improving 3d camera control in video diffusion transformers
Sherwin Bahmani, Ivan Skorokhodov, Guocheng Qian, Aliaksandr Siarohin, Willi Menapace, Andrea Tagliasacchi, David B Lindell, and Sergey Tulyakov. Ac3d: Analyzing and improving 3d camera control in video diffusion transformers. InCVPR, pages 22875–22889, 2025
2025
-
[28]
Wonderland: Navigating 3d scenes from a single image
Hanwen Liang, Junli Cao, Vidit Goel, Guocheng Qian, Sergei Korolev, Demetri Terzopoulos, Konstanti- nos N Plataniotis, Sergey Tulyakov, and Jian Ren. Wonderland: Navigating 3d scenes from a single image. InCVPR, pages 798–810, 2025
2025
-
[29]
Cameras as relative positional encoding.NeurIPS, 38:15984–16009, 2026
Ruilong Li, Brent Yi, Junchen Liu, Hang Gao, Yi Ma, and Angjoo Kanazawa. Cameras as relative positional encoding.NeurIPS, 38:15984–16009, 2026
2026
-
[30]
Gta: A geometry-aware attention mechanism for multi-view transformers
Takeru Miyato, Bernhard Jaeger, Max Welling, and Andreas Geiger. Gta: A geometry-aware attention mechanism for multi-view transformers. InICLR, volume 2024, pages 8172–8208, 2024
2024
-
[31]
Cheng Zhang, Boying Li, Meng Wei, Yan-Pei Cao, Camilo Cruz Gambardella, Dinh Phung, and Jianfei Cai. Unified camera positional encoding for controlled video generation.arXiv preprint arXiv:2512.07237, 2025
arXiv 2025
-
[32]
Jiannan Xiang, Guangyi Liu, Yi Gu, Qiyue Gao, Yuting Ning, Yuheng Zha, Zeyu Feng, Tianhua Tao, Shibo Hao, Yemin Shi, et al. Pandora: Towards general world model with natural language actions and video states.arXiv preprint arXiv:2406.09455, 2024
arXiv 2024
-
[33]
World models.arXiv preprint arXiv:1803.10122, 2018
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2018
Pith/arXiv arXiv 2018
-
[34]
Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023. 11
Pith/arXiv arXiv 2023
-
[35]
The matrix: Infinite-horizon world generation with real-time moving control.NeurIPS, 38:87318–87344, 2026
Ruili Feng, Han Zhang, Zhilei Shu, Zhantao Yang, Longxiang Tang, Zhicai Wang, Andy Zheng, Jie Xiao, Zhiheng Liu, Ruihang Chu, et al. The matrix: Infinite-horizon world generation with real-time moving control.NeurIPS, 38:87318–87344, 2026
2026
-
[36]
Diffusion models are real-time game engines
Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter. Diffusion models are real-time game engines. InICLR, volume 2025, pages 73754–73776, 2025
2025
-
[37]
Avid: Adapting video diffusion models to world models.arXiv preprint arXiv:2410.12822, 2024
Marc Rigter, Tarun Gupta, Agrin Hilmkil, and Chao Ma. Avid: Adapting video diffusion models to world models.arXiv preprint arXiv:2410.12822, 2024
arXiv 2024
-
[38]
Diffusion for world modeling: Visual details matter in atari.NeurIPS, 37:58757–58791, 2024
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, and François Fleuret. Diffusion for world modeling: Visual details matter in atari.NeurIPS, 37:58757–58791, 2024
2024
-
[39]
Zijian Song, Sihan Qin, Tianshui Chen, Liang Lin, and Guangrun Wang. Physical autoregressive model for robotic manipulation without action pretraining.arXiv preprint arXiv:2508.09822, 2025
arXiv 2025
-
[40]
Enhancing physical consistency in lightweight world models.arXiv preprint arXiv:2509.12437, 2025
Dingrui Wang, Zhexiao Sun, Zhouheng Li, Cheng Wang, Youlun Peng, Hongyuan Ye, Baha Zarrouki, Wei Li, Mattia Piccinini, Lei Xie, et al. Enhancing physical consistency in lightweight world models.arXiv preprint arXiv:2509.12437, 2025
arXiv 2025
-
[41]
Jianhao Yuan, Xiaofeng Zhang, Felix Friedrich, Nicolas Beltran-Velez, Melissa Hall, Reyhane Askari- Hemmat, Xiaochuang Han, Nicolas Ballas, Michal Drozdzal, and Adriana Romero-Soriano. Inference-time physics alignment of video generative models with latent world models.arXiv preprint arXiv:2601.10553, 2026
arXiv 2026
-
[42]
Aether: Geometric-aware unified world modeling
Haoyi Zhu, Yifan Wang, Jianjun Zhou, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Chunhua Shen, Jiangmiao Pang, and Tong He. Aether: Geometric-aware unified world modeling. InICCV, pages 8535–8546, 2025
2025
-
[43]
Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040, 2025
Yicong Hong, Yiqun Mei, Chongjian Ge, Yiran Xu, Yang Zhou, Sai Bi, Yannick Hold-Geoffroy, Mike Roberts, Matthew Fisher, Eli Shechtman, et al. Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040, 2025
arXiv 2025
-
[44]
Ruiqi Wu, Xuanhua He, Meng Cheng, Tianyu Yang, Yong Zhang, Zhuoliang Kang, Xunliang Cai, Xiaoming Wei, Chunle Guo, Chongyi Li, et al. Infinite-world: Scaling interactive world models to 1000-frame horizons via pose-free hierarchical memory.arXiv preprint arXiv:2602.02393, 2026
arXiv 2026
-
[45]
Context as memory: Scene-consistent interactive long video generation with memory retrieval
Jiwen Yu, Jianhong Bai, Yiran Qin, Quande Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Context as memory: Scene-consistent interactive long video generation with memory retrieval. In Proceedings of the SIGGRAPH Asia Conference Papers, pages 1–11, 2025
2025
-
[46]
Kaijin Chen, Dingkang Liang, Xin Zhou, Yikang Ding, Xiaoqiang Liu, Pengfei Wan, and Xiang Bai. Out of sight but not out of mind: Hybrid memory for dynamic video world models.arXiv preprint arXiv:2603.25716, 2026
arXiv 2026
-
[47]
Captain safari: A world engine.arXiv preprint arXiv:2511.22815, 2025
Yu-Cheng Chou, Xingrui Wang, Yitong Li, Jiahao Wang, Hanting Liu, Cihang Xie, Alan Yuille, and Junfei Xiao. Captain safari: A world engine.arXiv preprint arXiv:2511.22815, 2025
arXiv 2025
-
[48]
Video world models with long-term spatial memory.NeurIPS, 38:49371–49393, 2026
Tong Wu, Shuai Yang, Ryan Po, Yinghao Xu, Ziwei Liu, Dahua Lin, and Gordon Wetzstein. Video world models with long-term spatial memory.NeurIPS, 38:49371–49393, 2026
2026
-
[49]
Diffusion forcing: Next-token prediction meets full-sequence diffusion.NeurIPS, 37:24081–24125, 2024
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.NeurIPS, 37:24081–24125, 2024
2024
-
[50]
Self forcing: Bridging the train-test gap in autoregressive video diffusion.NeurIPS, 38:167283–167308, 2026
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.NeurIPS, 38:167283–167308, 2026
2026
-
[51]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. InCVPR, pages 22963–22974, 2025
2025
-
[52]
Xiaowei Chi, Peidong Jia, Chun-Kai Fan, Xiaozhu Ju, Weishi Mi, Kevin Zhang, Zhiyuan Qin, Wanxin Tian, Kuangzhi Ge, Hao Li, et al. Wow: Towards a world omniscient world model through embodied interaction.arXiv preprint arXiv:2509.22642, 2025
arXiv 2025
-
[53]
World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025
Arslan Ali, Junjie Bai, Maciej Bala, Yogesh Balaji, Aaron Blakeman, Tiffany Cai, Jiaxin Cao, Tianshi Cao, Elizabeth Cha, Yu-Wei Chao, et al. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025. 12
Pith/arXiv arXiv 2025
-
[54]
Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
Pith/arXiv arXiv 2026
-
[55]
Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
Pith/arXiv arXiv 2025
-
[56]
Lloyd Russell, Anthony Hu, Lorenzo Bertoni, George Fedoseev, Jamie Shotton, Elahe Arani, and Gianluca Corrado. Gaia-2: A controllable multi-view generative world model for autonomous driving.arXiv preprint arXiv:2503.20523, 2025
Pith/arXiv arXiv 2025
-
[57]
Syncammaster: Synchronizing multi-camera video generation from diverse viewpoints
Jianhong Bai, Menghan Xia, Xintao Wang, Ziyang Yuan, Zuozhu Liu, Haoji Hu, Pengfei Wan, and Di Zhang. Syncammaster: Synchronizing multi-camera video generation from diverse viewpoints. In ICLR, pages 58038–58060, 2025
2025
-
[58]
Collaborative video diffusion: Consistent multi-video generation with camera control.NeurIPS, 37:16240–16271, 2024
Zhengfei Kuang, Shengqu Cai, Hao He, Yinghao Xu, Hongsheng Li, Leonidas J Guibas, and Gordon Wetzstein. Collaborative video diffusion: Consistent multi-video generation with camera control.NeurIPS, 37:16240–16271, 2024
2024
-
[59]
Cavia: Camera-controllable multi-view video diffusion with view-integrated attention
Dejia Xu, Yifan Jiang, Chen Huang, Liangchen Song, Thorsten Gernoth, Liangliang Cao, Zhangyang Wang, and Hao Tang. Cavia: Camera-controllable multi-view video diffusion with view-integrated attention. arXiv preprint arXiv:2410.10774, 2024
arXiv 2024
-
[60]
Ic-world: In-context generation for shared world modeling.arXiv preprint arXiv:2512.02793, 2025
Fan Wu, Jiacheng Wei, Ruibo Li, Yi Xu, Junyou Li, Deheng Ye, and Guosheng Lin. Ic-world: In-context generation for shared world modeling.arXiv preprint arXiv:2512.02793, 2025
arXiv 2025
-
[61]
Introducing multiverse: The first ai multiplayer world model, 2025
Enigma team. Introducing multiverse: The first ai multiplayer world model, 2025. URLhttps://enigma. inc/blog
2025
-
[62]
Solaris: Building a multiplayer video world model in minecraft
Georgy Savva, Oscar Michel, Daohan Lu, Suppakit Waiwitlikhit, Timothy Meehan, Dhairya Mishra, Srivats Poddar, Jack Lu, and Saining Xie. Solaris: Building a multiplayer video world model in minecraft. arXiv preprint arXiv:2602.22208, 2026
arXiv 2026
-
[63]
Multiworld: Scalable multi-agent multi-view video world models.arXiv preprint arXiv:2604.18564, 2026
Haoyu Wu, Jiwen Yu, Yingtian Zou, and Xihui Liu. Multiworld: Scalable multi-agent multi-view video world models.arXiv preprint arXiv:2604.18564, 2026
Pith/arXiv arXiv 2026
-
[64]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[65]
Geocalib: Learning single-image calibration with geometric optimization
Alexander Veicht, Paul-Edouard Sarlin, Philipp Lindenberger, and Marc Pollefeys. Geocalib: Learning single-image calibration with geometric optimization. InEuropean Conference on Computer Vision, pages 1–20, 2024
2024
-
[66]
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018
Pith/arXiv arXiv 2018
-
[67]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
2004
-
[68]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, pages 586–595, 2018
2018
-
[69]
Haoyu Wu, Diankun Wu, Tianyu He, Junliang Guo, Yang Ye, Yueqi Duan, and Jiang Bian. Geometry forcing: Marrying video diffusion and 3d representation for consistent world modeling.arXiv preprint arXiv:2507.07982, 2025. 13
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.