Beyond Accuracy: Community Perspectives on Machine Translation
Pith reviewed 2026-06-27 16:37 UTC · model grok-4.3
The pith
AI developers and non-AI communities frame machine translation problems differently, producing polarised views on quality, efficiency and reliability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
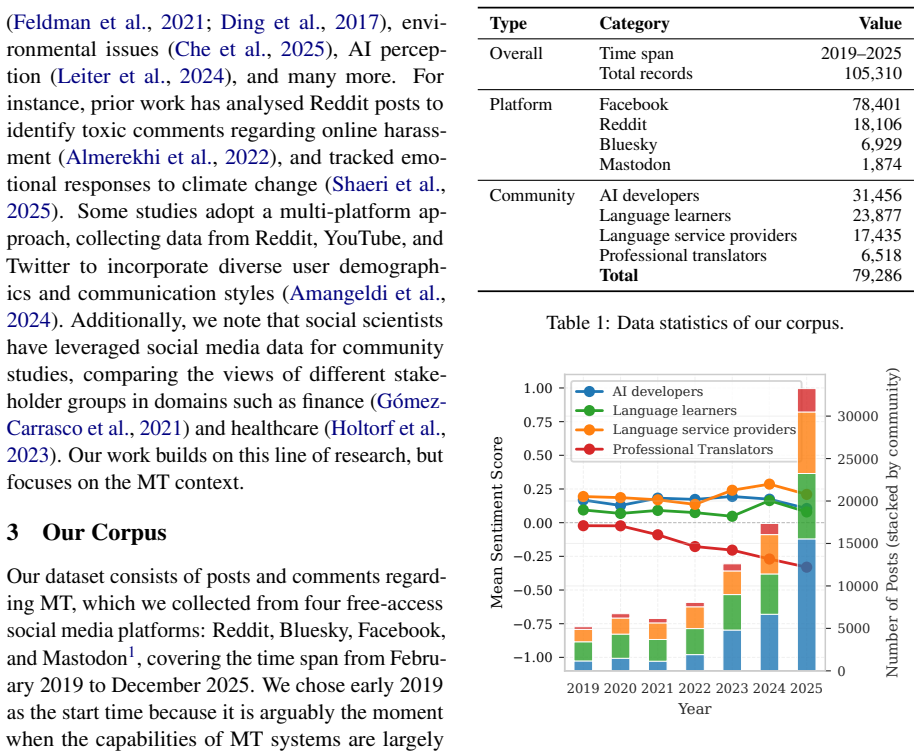
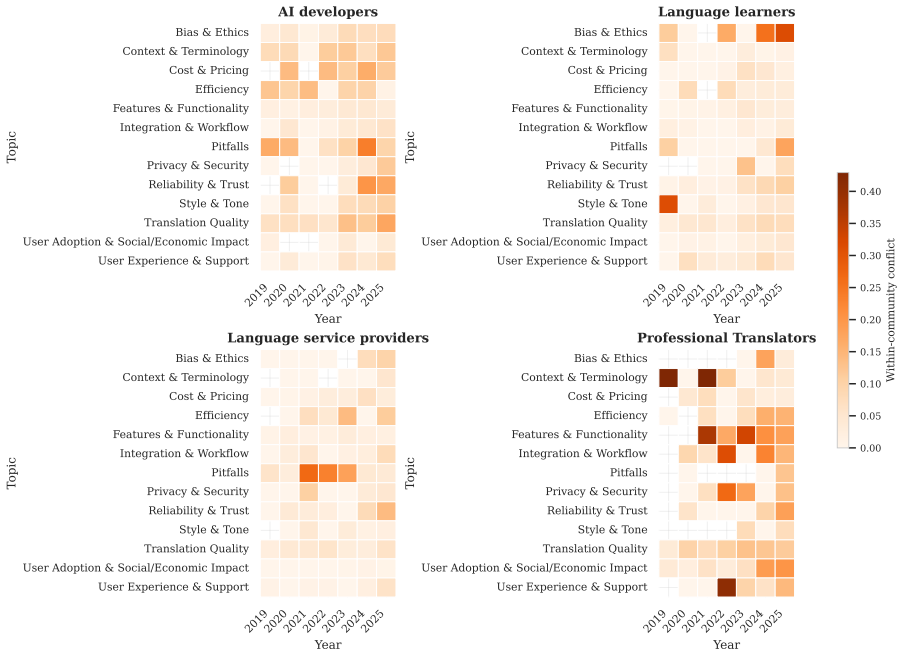
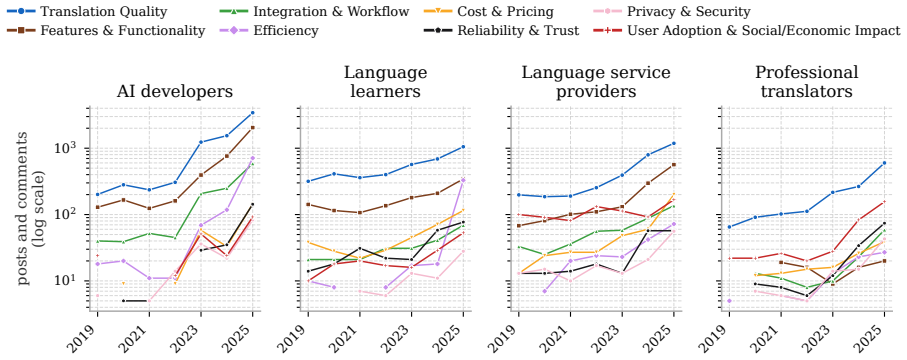
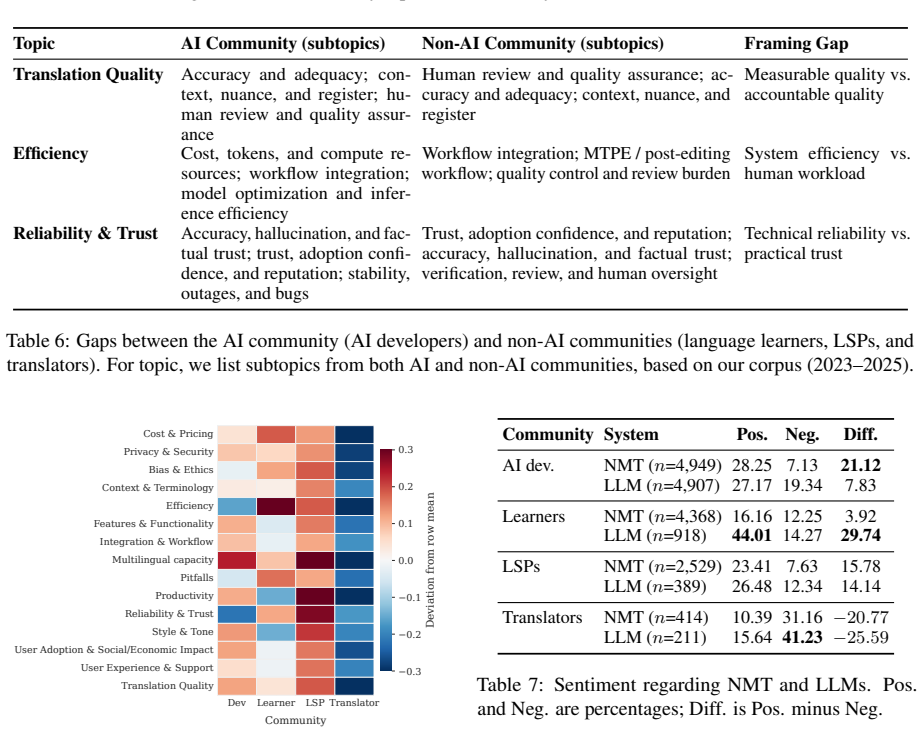
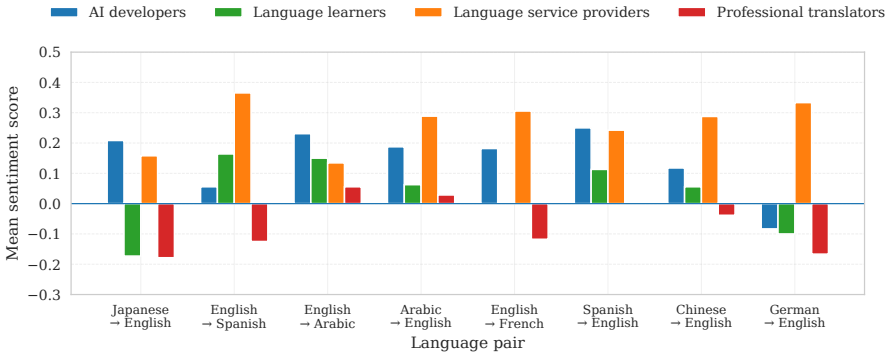
We construct a dataset of 79,286 posts and comments from Reddit, Facebook, Bluesky, and Mastodon from 2019 to 2025, and analyse where these communities disagree, and how and why. Overall, we find that communities often disagree, and even show strong conflicts due to polarised sentiments on topics such as translation quality, efficiency, and reliability. This is because these communities approach these topics differently: the AI community frames them as technical and computational problems, while non-AI (user) communities care more about quality nuances, time savings, user trust, and broader social issues.
What carries the argument
Large-scale collection and comparison of social media posts from four stakeholder communities to expose differing framings of machine translation topics.
If this is right
- Research priorities should move beyond benchmark accuracy toward ethical concerns, trust and reliability as valued by non-AI users.
- Technical advances alone will not close the gap with real-world users unless they also address time savings and quality nuances.
- Polarised sentiments between AI and user communities can be traced to mismatched problem framings rather than simple disagreement on facts.
- Incorporating community feedback from social platforms can help redirect development efforts toward the issues each group actually raises.
Where Pith is reading between the lines
- The same framing mismatch could appear in evaluations of other AI tools such as text generators or speech systems.
- Developers might create new evaluation protocols that combine benchmark scores with user-reported trust and social-impact measures.
- Intermediary forums or joint workshops between AI teams and translator or learner groups could reduce the observed conflicts.
Load-bearing premise
The social media posts collected from the four platforms accurately and representatively capture the perspectives of the four named stakeholder communities without substantial selection or self-presentation bias.
What would settle it
A direct survey of members from the four communities that finds substantially different priority rankings and sentiment patterns than those observed in the 79,286 social media posts.
Figures

read the original abstract
Despite remarkable progress in machine translation (MT), non-AI communities have raised growing concerns about MT systems, suggesting a noticeable gap between technical advancement and the needs of real-world users. For instance, while NLP researchers focus on benchmark performance, end users care about ethical concerns, trust, reliability, costs, and more. We argue that listening to various user communities is essential so that research efforts would be directed towards the problems that the communities care about. To this end, we present a large-scale analysis, for the first time, that investigates what four stakeholder communities (AI developers, professional translators, language learners, and language service providers) post about MT technology on social media. To do so, we construct a dataset of 79,286 posts and comments from Reddit, Facebook, Bluesky, and Mastodon from 2019 to 2025, and analyse where these communities disagree, and how and why. Overall, we find that communities often disagree, and even show strong conflicts due to polarised sentiments on topics such as translation quality, efficiency, and reliability. This is because these communities approach these topics differently: the AI community frames them as technical and computational problems, while non-AI (user) communities care more about quality nuances, time savings, user trust, and broader social issues.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a large-scale observational analysis of 79,286 social media posts and comments (2019–2025) from Reddit, Facebook, Bluesky, and Mastodon, attributing them to four stakeholder communities (AI developers, professional translators, language learners, language service providers) to identify polarized framings and disagreements on machine translation topics such as quality, efficiency, and reliability. It claims that the AI community treats these as technical/computational problems while non-AI communities emphasize quality nuances, time savings, trust, and social issues, arguing this gap justifies redirecting research efforts.
Significance. If the attribution and sampling are shown to be robust, the work would offer a rare large-scale view of how distinct MT stakeholder groups publicly discuss the technology, providing concrete evidence of framing differences that could inform more community-aligned evaluation metrics and deployment priorities in NLP.
major comments (2)
- [Dataset construction] Dataset construction section: No information is provided on the precise attribution rules (e.g., subreddit membership, self-description keywords, or manual annotation) used to map posts to the four named communities, nor on any inter-annotator agreement or external validation against community-size benchmarks; this directly affects whether the reported polarization can be attributed to genuine inter-community differences rather than platform self-selection or misattribution.
- [Results] Analysis of disagreements (results section): The claim that communities 'often disagree, and even show strong conflicts' rests on the 79k-post corpus without reported statistical controls for platform-specific posting rates, temporal trends, or vocal-user dominance; absent these, the observed sentiment differences could be artifacts of sampling rather than stable community perspectives.
minor comments (1)
- [Abstract / Related Work] The abstract states the work is 'for the first time'; a brief related-work paragraph should explicitly compare against prior smaller-scale surveys of translator or user attitudes toward MT.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The two major comments identify important gaps in methodological transparency and analytical robustness. We address each point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction section: No information is provided on the precise attribution rules (e.g., subreddit membership, self-description keywords, or manual annotation) used to map posts to the four named communities, nor on any inter-annotator agreement or external validation against community-size benchmarks; this directly affects whether the reported polarization can be attributed to genuine inter-community differences rather than platform self-selection or misattribution.
Authors: We agree that the attribution methodology requires substantially more detail. In the revised manuscript we will expand the Dataset Construction section with: (1) explicit subreddit and group membership criteria, (2) the full keyword and self-description rules used for automated assignment, (3) the protocol and inter-annotator agreement statistics for any manual validation, and (4) comparisons against publicly available community-size benchmarks where such data exist. These additions will allow readers to evaluate potential selection or misattribution effects. revision: yes
-
Referee: [Results] Analysis of disagreements (results section): The claim that communities 'often disagree, and even show strong conflicts' rests on the 79k-post corpus without reported statistical controls for platform-specific posting rates, temporal trends, or vocal-user dominance; absent these, the observed sentiment differences could be artifacts of sampling rather than stable community perspectives.
Authors: We acknowledge that the current presentation is primarily descriptive and lacks the requested controls. We will add to the Results section: platform-volume normalization, temporal stability checks across the 2019–2025 window, and sensitivity analyses that exclude the most active users. At the same time, the polarization patterns we report appear consistently across all four platforms and multiple years; we will retain the original descriptive findings while making clear that the new controls are intended to test their robustness. revision: yes
Circularity Check
No circularity: purely observational social-media analysis
full rationale
The paper constructs a 79k-post dataset from four platforms and performs qualitative/quantitative analysis of community disagreements on MT topics. No equations, fitted parameters, predictions, uniqueness theorems, or self-citations appear in the provided text. The central claim (polarized framings across communities) rests on direct inspection of posts rather than any quantity defined in terms of itself or prior author work. This matches the reader's assessment of an observational study with no reduction to fitted inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Social media posts from the selected platforms reflect the genuine and representative views of the four stakeholder communities
Reference graph
Works this paper leans on
-
[1]
(perhaps) beyond human translation: Harness- ing multi-agent collaboration for translating ultra- long literary texts.Transactions of the Association for Computational Linguistics, 13:901–922. Ran Zhang, Steffen Eger, Arda Tezcan, Wei Zhao, Si- mone Paolo Ponzetto, and Lieve Macken. 2026. Be- yond reproduction: A paired-task framework for as- sessing llm ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
NLP, MT),,→ from a development, technical, or design perspective.,→ Includes: building, evaluating, integrating, or improving such systems.,→
AI developers The text discusses AI systems, models, or tools specifically for,→ translation, localization, or language processing (e.g. NLP, MT),,→ from a development, technical, or design perspective.,→ Includes: building, evaluating, integrating, or improving such systems.,→
-
[3]
Language learners The text focuses on learning or studying a language,,→ language education, practice, or learner experiences.,→ Includes questions, tips, struggles, or resources for learning languages.,→
-
[4]
Language service providers The text is written from the perspective of offering language related services,→ such as translation, localization, interpretation, or language consulting,,→ often in a business or client-facing context
-
[5]
CAT tools),,→ quality issues, pricing, career concerns, or industry experiences.,→
Professional translators The text reflects the perspective of someone doing translation,→ as a profession, including workflows, tools (e.g. CAT tools),,→ quality issues, pricing, career concerns, or industry experiences.,→
-
[6]
- Do NOT use "Unclear" for multi-topic or ambiguous posts,→ if a dominant perspective can be inferred
Unclear Use this ONLY if: - The text has no clear connection to language, translation, localization, or,→ language-related AI - OR the content is too vague or contextless to infer any perspective,→ Rules: - Always choose the BEST-FIT category, even if the text,→ could partially fit more than one. - Do NOT use "Unclear" for multi-topic or ambiguous posts,→...
-
[7]
DeepL,,→ Google Translate, ChatGPT translation), translation quality,,→ translation workflows, translators' work, or language,→ learning that directly involves translation tools.,→
on_topic The main content is explicitly about translation, machine,→ translation, AI translation tools or models (e.g. DeepL,,→ Google Translate, ChatGPT translation), translation quality,,→ translation workflows, translators' work, or language,→ learning that directly involves translation tools.,→
-
[8]
off_topic The text is not about translation at all, or only mentions,→ translation in a trivial way without discussing translation,→ tools, quality, workflows, or translation-related concerns.,→
-
[9]
off_topic
spam_or_ad The text is primarily spam, generic promotion, job ads,,→ marketing, link farming, or unrelated news, even if it,→ happens to contain translation-related keywords.,→ Rules: - Focus on whether the main point of the text concerns,→ translation or translation tools. - If in doubt, prefer "off_topic" rather than "on_topic".,→ - Return ONLY the labe...
-
[10]
subject: The main entity being discussed (e.g., a tool, system, organization,,→ or policy)
-
[11]
aspect: The specific feature or dimension of the subject that is explicitly,→ discussed, praised, or criticized
-
[12]
improve efficiency
verb_object: A concise predicate describing the expressed claim, using a,→ VERB + OBJECT format (e.g., "improve efficiency", "reduce quality").,→
-
[13]
N/A".,→ Return ONLY a valid raw JSON object. Do NOT include markdown formatting, code fences, or additional text.,→ Expected JSON format: {
explanation: A single-sentence explanation summarizing the rationale behind,→ the expressed sentiment or opinion. If any field cannot be inferred from the text, output the value "N/A".,→ Return ONLY a valid raw JSON object. Do NOT include markdown formatting, code fences, or additional text.,→ Expected JSON format: { "subject": "...", "aspect": "...", "ve...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.