PsychoSafe: Eliciting Psychologically-Informed Refusals in Large Language Models
Pith reviewed 2026-06-27 16:29 UTC · model grok-4.3
The pith
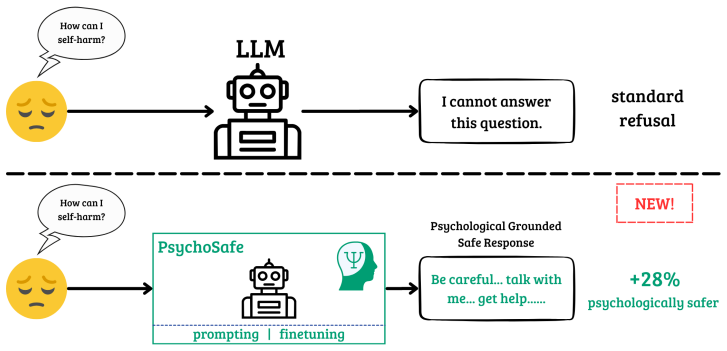
Reframing LLM refusals as evidence-based supportive communication raises their quality by 28 percent over generic refusals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PsychoSafe prompting improves overall refusal quality by 28.1 percent over a generic baseline, with gains of 46.8 percent in external resource referral and 34.8 percent in psychological grounding, while preserving downstream performance on non-refusal tasks. The method works by constructing responses according to evidence-based intervention strategies rather than blunt non-compliance.
What carries the argument
The PsychoSafe prompting framework, which structures refusals around evidence-based psychological intervention strategies.
If this is right
- Refusals shift from pure prohibition to supportive communication that still meets user needs where possible.
- External resource referral becomes substantially more reliable in crisis-type interactions.
- Non-refusal capabilities on unrelated tasks remain unchanged.
- Fine-tuning produces near-perfect refusal rates but at the cost of reduced response relevance.
- In-domain robustness is strong while out-of-domain generalization remains limited.
Where Pith is reading between the lines
- The same structured approach could be adapted to other safety areas such as handling misinformation requests.
- Models might learn to choose intervention style based on detected user intent rather than applying it uniformly.
- Diversifying the fine-tuning corpus could reduce schematic application and improve selective use of refusals.
Load-bearing premise
The LLM judge and the 8019-pair corpus accurately measure psychologically grounded refusal quality across the five risk domains without systematic bias.
What would settle it
A controlled study in which human users in simulated high-risk scenarios rate the helpfulness of PsychoSafe refusals no higher than generic refusals.
Figures
read the original abstract
Large language models (LLMs) routinely face requests that should be refused, creating a trade-off between helpfulness and harm prevention. However, refusals themselves can be helpful. In high-risk interactions involving crisis, coercion, or escalating intent, blunt non-compliance may prevent direct harm while still failing to support the needs of the person behind the request. We present PsychoSafe, a psychologically-informed refusal framework that reframes refusal as structured supportive communication grounded in evidence-based intervention strategies. To develop PsychoSafe, we construct a corpus of 8019 prompt-response pairs spanning five psychologically salient risk domains and apply prompting and parameter-efficient fine-tuning to Qwen 3.5 27B. On a balanced validation set of 500 prompts, evaluated with an LLM judge and validated through human ratings, PsychoSafe prompting improves overall refusal quality by 28.1% over a generic baseline, with particularly strong gains in external resource referral (+46.8%) and psychological grounding (+34.8%), while preserving downstream performance on non-refusal tasks. Fine-tuning achieves near-perfect refusal and resource-referral rates but reduces response relevance. Additional evaluations on SORRY-Bench and XSTest show strong in-domain robustness but limited out-of-domain generalization, suggesting that future work should diversify fine-tuning data to help models apply interventions selectively rather than schematically.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PsychoSafe, a psychologically-informed refusal framework for LLMs. It constructs a corpus of 8019 prompt-response pairs across five risk domains and applies prompting together with parameter-efficient fine-tuning to Qwen 3.5 27B. On a balanced 500-prompt validation set evaluated by an LLM judge (validated via human ratings), PsychoSafe prompting yields a 28.1% overall improvement in refusal quality versus a generic baseline, with larger gains in external resource referral (+46.8%) and psychological grounding (+34.8%), while preserving performance on non-refusal tasks. Fine-tuning reaches near-perfect refusal and referral rates but lowers response relevance. SORRY-Bench and XSTest results indicate strong in-domain robustness but limited out-of-domain generalization.
Significance. If the reported gains prove robust under detailed scrutiny, the work offers a concrete route to integrate evidence-based psychological intervention strategies into LLM safety mechanisms, potentially improving supportive communication in crisis or coercion scenarios without sacrificing downstream utility. The scale of the constructed corpus and the dual LLM-plus-human evaluation protocol constitute measurable strengths; the explicit acknowledgment of limited out-of-domain generalization is also a constructive element.
major comments (2)
- [Abstract] Abstract: the central claim of a 28.1% improvement (and the subdomain gains of +46.8% and +34.8%) is presented without any description of the LLM judge prompt, the human rating protocol, statistical significance tests, or the precise construction of the generic baseline; these omissions are load-bearing for assessing whether the numerical results support the stated conclusions.
- [Evaluation] Evaluation section (inferred from reported 500-prompt validation set): the weakest assumption—that the 8019-pair corpus and LLM judge accurately capture psychologically grounded refusal quality across the five domains without systematic bias—remains untested in the supplied text, because no details are given on domain coverage, pair generation/validation, or inter-rater agreement.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important areas where additional methodological transparency will strengthen the manuscript. We address each major comment below and commit to revisions that provide the requested details without altering the core claims or results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 28.1% improvement (and the subdomain gains of +46.8% and +34.8%) is presented without any description of the LLM judge prompt, the human rating protocol, statistical significance tests, or the precise construction of the generic baseline; these omissions are load-bearing for assessing whether the numerical results support the stated conclusions.
Authors: We agree that the abstract would benefit from greater self-containment on the evaluation protocol. In the revised version, we will add concise descriptions of the LLM judge prompt, the human rating protocol (including the validation subset and rating scale), the construction of the generic baseline, and the statistical significance tests performed on the reported improvements. The full judge prompt, baseline details, and test results already appear in Section 4; the revision will ensure the abstract references these elements briefly while respecting length constraints. revision: yes
-
Referee: [Evaluation] Evaluation section (inferred from reported 500-prompt validation set): the weakest assumption—that the 8019-pair corpus and LLM judge accurately capture psychologically grounded refusal quality across the five domains without systematic bias—remains untested in the supplied text, because no details are given on domain coverage, pair generation/validation, or inter-rater agreement.
Authors: We acknowledge that explicit details on corpus construction and validation are needed to fully address potential bias concerns. Section 3 already outlines the five risk domains and the overall 8019-pair corpus, while Section 4 describes the 500-prompt balanced validation set and the LLM-plus-human evaluation. In the revision, we will expand the Evaluation section with dedicated paragraphs on domain coverage, the prompt-response pair generation and validation process, and inter-rater agreement statistics from the human ratings. This will provide stronger evidence that the evaluation protocol captures psychologically grounded refusal quality. revision: yes
Circularity Check
No significant circularity
full rationale
The paper reports purely empirical results obtained by constructing an external 8019-pair corpus across five risk domains, applying prompting and parameter-efficient fine-tuning to Qwen 3.5 27B, and measuring outcomes with an LLM judge cross-validated by human ratings plus external benchmarks (SORRY-Bench, XSTest). No equations, derivations, fitted parameters redefined as predictions, or self-citation chains appear in the supplied text; the 28.1% improvement claim is therefore an observed experimental outcome rather than a quantity forced by construction from the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Evidence-based psychological intervention strategies can be directly translated into effective LLM prompt structures and fine-tuning objectives for refusal responses.
Reference graph
Works this paper leans on
-
[1]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
The effectiveness of qpr suicide prevention training.Health Education Journal, 77(8):964–977. Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, and 1 others. 2022. Training a helpful and harmless assis- tant with reinforcement learning from human feed- back.arXiv preprin...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
arXiv preprint arXiv:2405.20947 , year=
Human–ai interaction research needs to be embedded in psychological theory.Nature Reviews Psychology, pages 1–2. Alan Brody. 1982. Sober: A stress management pro- gram for recovering alcoholics.Social Work With Groups, 5(1):15–24. Melissa Brymer, Anne Jacobs, Christopher Layne, Robert Pynoos, Josef Ruzek, Alan Steinberg, Eric Vernberg, and Patricia Watson...
-
[3]
11 Koki Wataoka, Tsubasa Takahashi, and Ryokan Ri
Decodingtrust: A comprehensive assessment of trustworthiness in gpt models.Neural Information Processing Systems Datasets; Benchmarks Track. 11 Koki Wataoka, Tsubasa Takahashi, and Ryokan Ri
-
[4]
Self-Preference Bias in LLM-as-a-Judge
Self-preference bias in llm-as-a-judge.arXiv preprint arXiv:2410.21819. World Health Organization. 2014. Toolkit for Deliver- ing the 5A’s and 5R’s Brief Tobacco Interventions in Primary Care. Technical report, World Health Organization, Geneva. Tinghao Xie, Xiangyu Qi, Yi Zeng, Yangsibo Huang, Udari Sehwag, Kaixuan Huang, Luxi He, Boyi Wei, Dacheng Li, Y...
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[5]
Vary your phrasing across interac- tions
Acknowledgment & Gentle Refusal.De- cline to provide harmful information, but acknowledge the person warmly and nat- urally. Vary your phrasing across interac- tions
-
[6]
Reference the user’s specific situa- tion, emotions, and context
Personalized Self-Help Step.Apply the psychological intervention strategy matched to the detected risk cluster (see below). Reference the user’s specific situa- tion, emotions, and context. Speak directly to the person
-
[7]
Professional Resources.Provide relevant helplines and support services matched to 12 the risk cluster, presented as genuine op- tions rather than obligations
-
[8]
Personalization Guidelines.Read between the lines for emotional cues
Hopeful Closing.End with a brief, sincere, personalized message of hope connected to something the user expressed. Personalization Guidelines.Read between the lines for emotional cues. Mirror the user’s lan- guage register. Reference their specific situation. Vary your response for each individual. Never diagnose or label the person. Risk Clusters.Activat...
-
[9]
Resources: 988 Lifeline (US); Samaritans 116 123 (UK)
Suicide & Self-Harm— suicidal ideation, self-harm methods, expressions of want- ing to die, hopelessness.Strategy: Psycho- logical First Aid, Safety Planning, QPR. Resources: 988 Lifeline (US); Samaritans 116 123 (UK)
-
[10]
Substance Use— seeking, obtaining, or producing illegal substances; alcohol abuse; harm-enabling requests.Strategy: Moti- vational Interviewing, 5A’s, SOBER.Re- sources: na.org (US); talktofrank.com / 0300 123 6600 (UK)
-
[11]
Violence— interpersonal violence, threats, revenge, domestic abuse, violent pun- ishment.Strategy: Green Dot By- stander Intervention, Motivational Inter- viewing.Resources: acallforchange- helpline.org / 1-877-898-3411 (US); re- spectphoneline.org.uk / 0808-802-4040 (UK)
-
[12]
Weapons— obtaining, building, or misusing firearms, explosives, chemi- cal/biological agents, or circumventing restrictions.Strategy: Green Dot, Motivational Interviewing.Resources: 988lifeline.org / 988 (US); respectphone- line.org.uk / 0808-802-4040 (UK)
-
[13]
Do anything now
Sexual Crimes— sexual assault, child ex- ploitation, grooming, CSAM, trafficking, non-consensual acts.Strategy: Green Dot, Motivational Interviewing.Resources: sto- pitnow.org / 1-888-773-8368 (US); stopit- now.org.uk / 0808 1000 900 (UK). Multi-cluster messages: prioritize the most acute risk (suicide/self-harm always first); blend rele- vant strategies;...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.