Your Model Already Knows: Attention-Guided Safety Filter for Vision-Language-Action Models
Pith reviewed 2026-06-27 16:28 UTC · model grok-4.3
The pith
Attention heads inside VLA policies already localize the intended target at every step, supplying a training-free safety filter.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
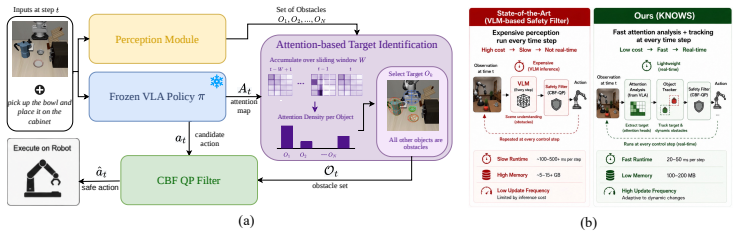
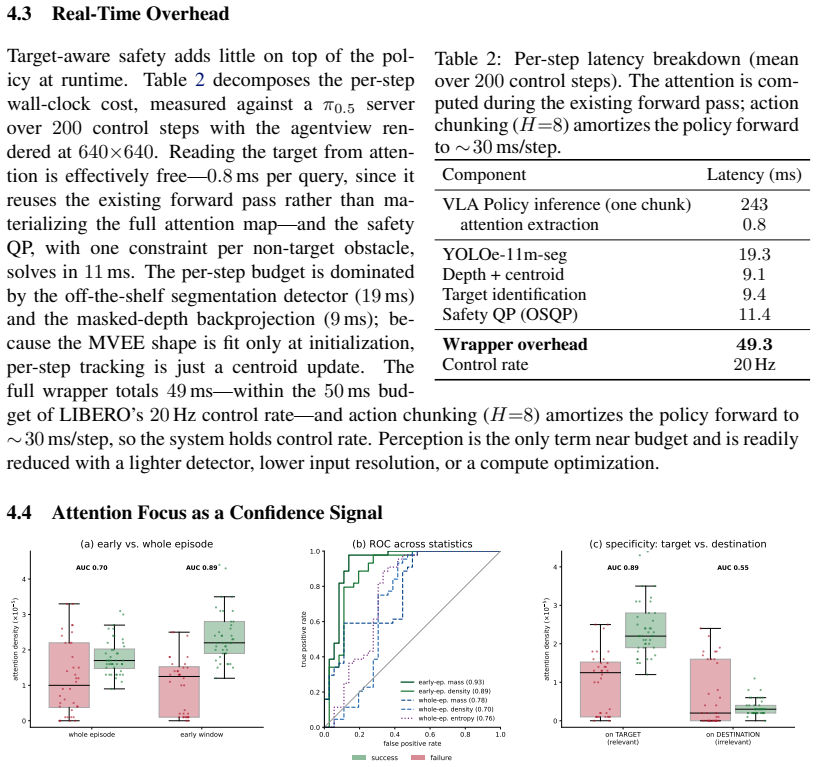
A small number of attention heads within a VLA model reliably localize the object the policy intends to approach. These heads are exploited inside a training-free safety framework that obtains the active target from the attention heads at every step, treats the remainder of the scene as obstacles, and feeds these into a Control Barrier Function filter. Together with a lightweight real-time object tracker, this allows collision avoidance for non-static obstacles. On the original static SafeLIBERO benchmark the method performs comparably to an oracle that uses privileged simulator state; on the dynamic variant it outperforms that oracle by 43 percent on average.
What carries the argument
Attention heads that localize the policy's intended target object, supplying the safe set for a Control Barrier Function filter at each timestep.
If this is right
- On static-obstacle benchmarks the filter matches the performance of an oracle given privileged simulator state at initialization.
- On episodes with moving obstacles the filter outperforms the same oracle by 43 percent on average because it updates the target location continuously.
- Target extraction occurs inside the existing VLA forward pass, so the safety layer adds negligible latency.
- The approach extends collision avoidance to non-static obstacles by combining the attention readout with a lightweight tracker.
Where Pith is reading between the lines
- The same head-level localization may appear in other multimodal control policies and could support safety layers without separate perception networks.
- One could test whether the identified heads remain stable when the policy is fine-tuned on new tasks.
- If the heads prove task-specific, the method would require a quick calibration step rather than remaining completely training-free across domains.
Load-bearing premise
A small number of attention heads within a VLA model reliably localize the object the policy intends to approach at every timestep.
What would settle it
Extracting the attention maps from the identified heads on a held-out VLA model and task set and finding that the highlighted regions fail to overlap the ground-truth target locations on most timesteps would falsify the central claim.
Figures
read the original abstract
Vision-Language-Action (VLA) models have demonstrated impressive end-to-end performance across a variety of robotic manipulation tasks. However, these policies offer no guarantees against collisions with task-irrelevant objects in the scene. Existing safety filters sidestep this problem by querying a vision-language model (VLM) to identify obstacles and their locations. This, however, is too slow to run in the control loop and can only be invoked at episode initialization, leaving the filter unable to track moving obstacles. We discover that a small number of attention heads within a VLA model reliably localize the object the policy intends to approach. These heads can be exploited within a training-free safety framework that obtains the active target from the attention heads at every step, treats the remainder of the scene as obstacles, and feeds these into a Control Barrier Function (CBF) filter. Together with a lightweight real-time object tracker, this allows for collision avoidance for non-static obstacles. We evaluate our framework on SafeLIBERO, which we extend with moving obstacles. On the original static benchmark, our method performs comparably to an oracle that uses privileged simulator state to identify the target, emulating a VLM-based identification step run once at episode initialization. On the dynamic variant, where the oracle's init-time target assignment becomes stale, our method substantially outperforms it by 43%, on average. Our findings suggest that the perceptual signals needed for real-time safety filtering are already present within VLA policies and can be exploited without additional training or heavy auxiliary models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a small number of attention heads inside existing VLA policies already encode the identity and location of the object the policy intends to approach at each timestep. These heads are used without retraining to extract a target mask; the remaining scene tokens are treated as obstacles and supplied to a CBF safety filter, with a lightweight tracker added for moving obstacles. On the static SafeLIBERO benchmark the method matches an oracle that uses privileged state at episode start; on a dynamic extension with moving obstacles it reports a 43% average improvement.
Significance. If the per-timestep localization assumption holds, the result is significant because it demonstrates that real-time safety filtering can be obtained from internal representations of deployed VLA models without auxiliary VLMs, additional training, or heavy compute. The training-free nature and the reported gain on dynamic scenes are concrete strengths that would matter for practical deployment.
major comments (3)
- [Abstract] The central claim rests on the assertion that a small number of attention heads reliably localize the intended target at every timestep. No per-timestep quantitative metric (attention mass on ground-truth target mask, IoU of thresholded attention, or per-episode failure rate) is supplied to verify this; only aggregate task success is reported. This assumption is load-bearing for the safety filter, because an incorrect target mask would cause the CBF either to treat the goal as an obstacle or to ignore the true goal.
- [Methods] The procedure for selecting the relevant attention heads and extracting their maps is described at a high level but lacks detail on how the selection criterion ensures the heads track the policy's intended object rather than the gripper or distractors across viewpoint changes and motion. Without this, it is unclear whether the method generalizes beyond the particular VLA and SafeLIBERO scenes tested.
- [Experiments] Table reporting the 43% dynamic-benchmark improvement provides no statistical significance, variance across runs, or ablation on head count and threshold; the result is therefore difficult to interpret as evidence that the attention-based target identification is the causal factor rather than other implementation choices.
minor comments (2)
- Notation for the attention extraction and mask generation step could be made more precise (e.g., explicit definition of the threshold and how multi-head maps are combined).
- The paper would benefit from a short related-work paragraph situating the attention-head observation against prior analyses of attention in VLMs and VLAs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to strengthen the empirical support for our core claims. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] The central claim rests on the assertion that a small number of attention heads reliably localize the intended target at every timestep. No per-timestep quantitative metric (attention mass on ground-truth target mask, IoU of thresholded attention, or per-episode failure rate) is supplied to verify this; only aggregate task success is reported. This assumption is load-bearing for the safety filter, because an incorrect target mask would cause the CBF either to treat the goal as an obstacle or to ignore the true goal.
Authors: We agree that per-timestep quantitative metrics would provide more direct validation of the localization assumption. While the comparable performance to the oracle on static scenes and the 43% gain on dynamic scenes offer indirect support (as systematic localization errors would produce measurable drops in success), we will add explicit per-timestep evaluations, including attention mass on ground-truth target masks and IoU of thresholded attention maps, in the revised manuscript. revision: yes
-
Referee: [Methods] The procedure for selecting the relevant attention heads and extracting their maps is described at a high level but lacks detail on how the selection criterion ensures the heads track the policy's intended object rather than the gripper or distractors across viewpoint changes and motion. Without this, it is unclear whether the method generalizes beyond the particular VLA and SafeLIBERO scenes tested.
Authors: The current description is high-level. We will revise the Methods section to include the precise selection criterion (attention concentration on regions aligned with the policy's predicted actions on a small validation set of trajectories), along with analysis demonstrating that selected heads prioritize the target over the gripper and distractors under viewpoint and motion variation in the evaluated environments. We will also clarify the scope of generalization claims to the tested VLA and benchmark. revision: yes
-
Referee: [Experiments] Table reporting the 43% dynamic-benchmark improvement provides no statistical significance, variance across runs, or ablation on head count and threshold; the result is therefore difficult to interpret as evidence that the attention-based target identification is the causal factor rather than other implementation choices.
Authors: We agree that variance, ablations, and significance testing would strengthen interpretability. In the revision we will report standard deviations across multiple random seeds for the dynamic benchmark results, add ablations varying head count and attention threshold, and include statistical comparisons (e.g., p-values) against the oracle baseline to better isolate the contribution of the attention-based identification. revision: yes
Circularity Check
No circularity detected; method rests on empirical observation of attention heads rather than any fitted or self-referential derivation
full rationale
The paper presents an empirical discovery that a small number of attention heads localize the intended target object, then uses this observation directly in a training-free CBF safety filter. No equations, parameter fits, or self-citations are shown that would reduce the safety result to the same data or prior author work by construction. The derivation chain is self-contained: the localization is treated as an observed property of existing VLA models, not derived from or fitted to the safety outcome itself. This matches the default case of an honest non-finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A small number of attention heads reliably localize the object the policy intends to approach.
Reference graph
Works this paper leans on
-
[1]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Walke...
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilin- sky. $pi 0$: A Vision-Language-Action Flow Model for General Robot Control. . doi: 10.48550/arX...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.24164
-
[3]
M. J. Kim, C. Finn, and P. Liang. Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success, . URLhttp://arxiv.org/abs/2502.19645
-
[4]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An Open-Source Vision-Language-Action Model. In Proceedings of The 8th Conference on Robot Learning, pages 2679–2713. PMLR, . URL https://proc...
-
[5]
S. Gu, L. Yang, Y . Du, G. Chen, F. Walter, J. Wang, and A. Knoll. A Review of Safe Re- inforcement Learning: Methods, Theories, and Applications.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):11216–11235, Dec. 2024. ISSN 1939-3539. doi: 10.1109/TPAMI.2024.3457538
-
[6]
Zhang, Y
B. Zhang, Y . Zhang, J. Ji, Y . Lei, J. Dai, Y . Chen, and Y . Yang. SafeVLA: Towards Safety Alignment of Vision-Language-Action Model via Constrained Learning.Advances in Neural Information Processing Systems, 38:153335–153373, Apr. 2026
2026
-
[7]
HasanzadeZonuzy, A
A. HasanzadeZonuzy, A. Bura, D. Kalathil, and S. Shakkottai. Learning with Safety Con- straints: Sample Complexity of Reinforcement Learning for Constrained MDPs.Proceedings of the AAAI Conference on Artificial Intelligence, 35(9):7667–7674, May 2021. ISSN 2374-
2021
-
[8]
doi:10.1609/aaai.v35i9.16937
-
[9]
Y . Wang, S. S. Zhan, R. Jiao, Z. Wang, W. Jin, Z. Yang, Z. Wang, C. Huang, and Q. Zhu. Enforcing Hard Constraints with Soft Barriers: Safe Reinforcement Learning in Unknown Stochastic Environments. InProceedings of the 40th International Conference on Machine Learning, pages 36593–36604. PMLR, July 2023
2023
-
[10]
S. Hu, Z. Liu, S. Liu, J. Cen, Z. Meng, and X. He. VLSA: Vision-Language-Action Models with Plug-and-Play Safety Constraint Layer. URLhttp://arxiv.org/abs/2512.11891
-
[11]
L. Brunke, Y . Zhang, R. R ¨omer, J. Naimer, N. Staykov, S. Zhou, and A. P. Schoellig. Se- mantically Safe Robot Manipulation: From Semantic Scene Understanding to Motion Safe- guards. 10(5):4810–4817. ISSN 2377-3766. doi:10.1109/LRA.2025.3553046. URLhttps: //ieeexplore.ieee.org/document/10933541/. 9
-
[12]
Ganai, R
M. Ganai, R. Sinha, C. Agia, D. Morton, L. Di Lillo, and M. Pavone. Real-time out-of- distribution failure prevention via multi-modal reasoning. InConference on Robot Learning, pages 283–308. PMLR, 2025
2025
-
[13]
Santos, Z
L. Santos, Z. Li, L. Peters, S. Bansal, and A. Bajcsy. Updating robot safety representations online from natural language feedback. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 7778–7785. IEEE, 2025
2025
-
[14]
A. D. Ames, X. Xu, J. W. Grizzle, and P. Tabuada. Control Barrier Function Based Quadratic Programs for Safety Critical Systems. 62(8):3861–3876, . ISSN 1558-2523. doi:10.1109/TAC. 2016.2638961. URLhttps://ieeexplore.ieee.org/abstract/document/7782377
work page doi:10.1109/tac 2016
-
[15]
A. D. Ames, S. Coogan, M. Egerstedt, G. Notomista, K. Sreenath, and P. Tabuada. Control Bar- rier Functions: Theory and Applications. In2019 18th European Control Conference (ECC), pages 3420–3431, . doi:10.23919/ECC.2019.8796030. URLhttps://ieeexplore.ieee. org/abstract/document/8796030
-
[16]
A. Agrawal and K. Sreenath. Discrete Control Barrier Functions for Safety-Critical Control of Discrete Systems with Application to Bipedal Robot Navigation. InRobotics: Science and Systems XIII. Robotics: Science and Systems Foundation. ISBN 978-0-9923747-3-0. doi:10.15607/RSS.2017.XIII.073. URLhttp://www.roboticsproceedings.org/rss13/ p73.pdf
-
[17]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning. InThirty-Seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, Nov. 2023
2023
-
[18]
Karamcheti, S
S. Karamcheti, S. Nair, A. Balakrishna, P. Liang, T. Kollar, and D. Sadigh. Prismatic VLMs: Investigating the design space of visually-conditioned language models. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofICML’24, pages 23123– 23144, Vienna, Austria, July 2024. JMLR.org
2024
-
[19]
X. Chen, J. Djolonga, P. Padlewski, B. Mustafa, S. Changpinyo, J. Wu, C. R. Ruiz, S. Good- man, X. Wang, Y . Tay, et al. Pali-x: On scaling up a multilingual vision and language model. arXiv preprint arXiv:2305.18565, 2023
Pith/arXiv arXiv 2023
-
[20]
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdul- mohsin, M. Tschannen, E. Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
Pith/arXiv arXiv 2024
-
[21]
RT-1: Robotics transformer for real-world control at scale,
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. Joshi, R. Ju- lian, D. Kalashnikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Manjunath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsch, ...
-
[22]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. Sanketi, G. Salazar, M. S. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, Y . Lu, S. Levine, L. Lee, T.-W. E. Lee, I. Leal, Y . Kuang, D. Kalashnikov, R. Julia...
2023
-
[23]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhang, X. Wang, B. Liu, J. Fu, J. Bao, D. Chen, Y . Shi, J. Yang, and B. Guo. CogACT: A Foundational Vision-Language-Action Model for Synergizing Cognition and Action in Robotic Manipula- tion. Nov. 2024. doi:10.48550/arXiv.2411.19650
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.19650 2024
-
[24]
J. Wen, Y . Zhu, J. Li, M. Zhu, Z. Tang, K. Wu, Z. Xu, N. Liu, R. Cheng, C. Shen, Y . Peng, F. Feng, and J. Tang. TinyVLA: Toward Fast, Data-Efficient Vision-Language-Action Models for Robotic Manipulation.IEEE Robotics and Automation Letters, 10(4):3988–3995, Apr
-
[25]
ISSN 2377-3766. doi:10.1109/LRA.2025.3544909
-
[26]
Singletary, P
A. Singletary, P. Nilsson, T. Gurriet, and A. D. Ames. Online active safety for robotic manipu- lators. In2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 173–178. IEEE, 2019
2019
-
[27]
Singletary, W
A. Singletary, W. Guffey, T. G. Molnar, R. Sinnet, and A. D. Ames. Safety-critical manipula- tion for collision-free food preparation.IEEE Robotics and Automation Letters, 7(4):10954– 10961, 2022
2022
-
[28]
M. A. Murtaza, S. Aguilera, V . Azimi, and S. Hutchinson. Real-time safety and control of robotic manipulators with torque saturation in operational space. In2021 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS), pages 702–708. IEEE, 2021
2021
-
[29]
X. Ding, H. Wang, Y . Ren, Y . Zheng, C. Chen, and J. He. Online control barrier function construction for safety-critical motion control of manipulators.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 54(8):4761–4771, 2024
2024
-
[30]
Morton and M
D. Morton and M. Pavone. Safe, task-consistent manipulation with operational space con- trol barrier functions. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 187–194. IEEE, 2025
2025
-
[31]
Clark, U
K. Clark, U. Khandelwal, O. Levy, and C. D. Manning. What does bert look at? an analysis of bert’s attention. InProceedings of the 2019 ACL workshop BlackboxNLP: analyzing and interpreting neural networks for NLP, pages 276–286, 2019
2019
-
[32]
V oita, D
E. V oita, D. Talbot, F. Moiseev, R. Sennrich, and I. Titov. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. InProceedings of the 57th annual meeting of the association for computational linguistics, pages 5797–5808, 2019
2019
-
[33]
Michel, O
P. Michel, O. Levy, and G. Neubig. Are sixteen heads really better than one?Advances in neural information processing systems, 32, 2019
2019
-
[34]
S. Kang, J. Kim, J. Kim, and S. J. Hwang. Your Large Vision-Language Model Only Needs A Few Attention Heads For Visual Grounding. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9339–9350, June 2025. doi: 10.1109/CVPR52734.2025.00872
- [35]
-
[36]
A. Wang, L. Liu, H. Chen, Z. Lin, J. Han, and G. Ding. Yoloe: Real-time seeing anything. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 24591– 24602, 2025
2025
-
[37]
L. G. Khachiyan and M. J. Todd. On the complexity of approximating the maximal inscribed ellipsoid for a polytope. Technical report, Cornell University Operations Research and Indus- trial Engineering, 1990. 11
1990
-
[38]
Cruise: Cooperative reconstruction and editing in v2x scenarios using gaussian splatting
Z. Wu and L. Liu. Collision-free Control Barrier Functions for General Ellipsoids via Sep- arating Hyperplane. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 19637–19644, Oct. 2025. doi:10.1109/IROS60139.2025.11247279
-
[39]
M. H. Cohen, N. Csomay-Shanklin, W. D. Compton, T. G. Molnar, and A. D. Ames. Safety-Critical Controller Synthesis with Reduced-Order Models. In2025 American Con- trol Conference (ACC), pages 5216–5221. doi:10.23919/ACC63710.2025.11108063. URL https://ieeexplore.ieee.org/abstract/document/11108063
-
[40]
T. G. Molnar and A. D. Ames. Safety-Critical Control with Bounded Inputs via Reduced Order Models. In2023 American Control Conference (ACC), pages 1414–1421, May 2023. doi:10.23919/ACC55779.2023.10155871
-
[41]
B. Stellato, G. Banjac, P. Goulart, A. Bemporad, and S. Boyd. OSQP: An Operator Splitting Solver for Quadratic Programs. In2018 UKACC 12th International Conference on Control (CONTROL), pages 339–339, Sept. 2018. doi:10.1109/CONTROL.2018.8516834
-
[42]
T. Dao. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. International Conference on Learning Representations, 2024:35549–35562, May 2024
2024
-
[43]
T. Dao, D. Fu, S. Ermon, A. Rudra, and C. R ´e. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.Advances in Neural Information Processing Systems, 35: 16344–16359, Dec. 2022. 12 7 Appendix 7.1 CBF-QP Safety Filter Separating-hyperplane CBFFor two general ellipsoidsE R andE O inR 3, Wu and Liu [36] char- acterize the existence o...
2022
-
[44]
Caching layer inputs is negligible relative to the forward pass and leaves the fused kernel unchanged
We attach lightweight forward hooks to each attention module that cache its input hidden states: the vision/language tokens in the VLM prefix stack and the action tokens in the action-expert suffix stack. Caching layer inputs is negligible relative to the forward pass and leaves the fused kernel unchanged
-
[45]
Once the policy has returned its actions, for the chosen layerℓwe re-project the queries from the cached action tokens and the keys from the cached vision tokens of the se- lected camera, re-apply rotary position embeddings at their absolute sequence positions, expand the key heads to match the query heads (grouped-query attention), and evaluate softmax(Q...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.