iOSWorld: A Benchmark for Personally Intelligent Phone Agents
Pith reviewed 2026-06-27 17:21 UTC · model grok-4.3
The pith
iOSWorld benchmark shows frontier phone agents reach 52% overall but only 37% on multi-app personal tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
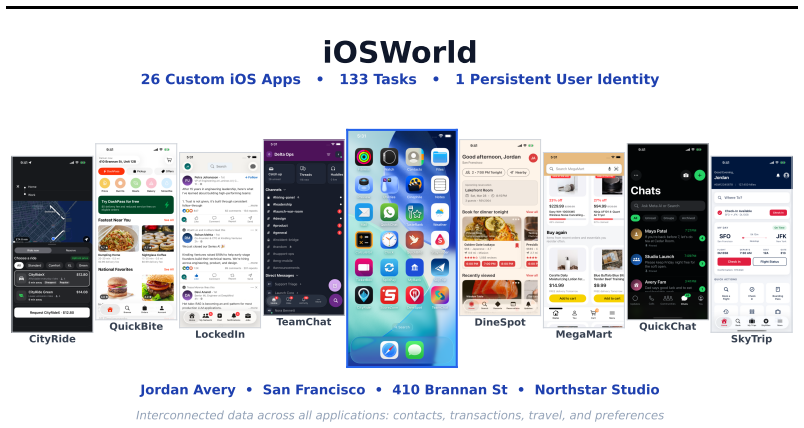
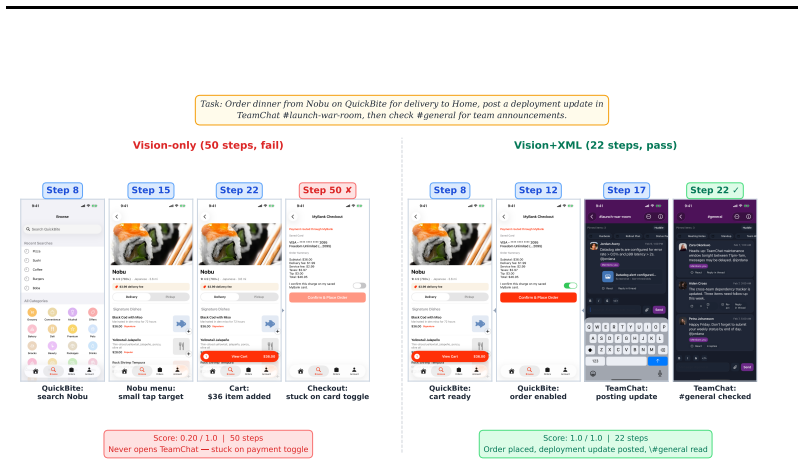
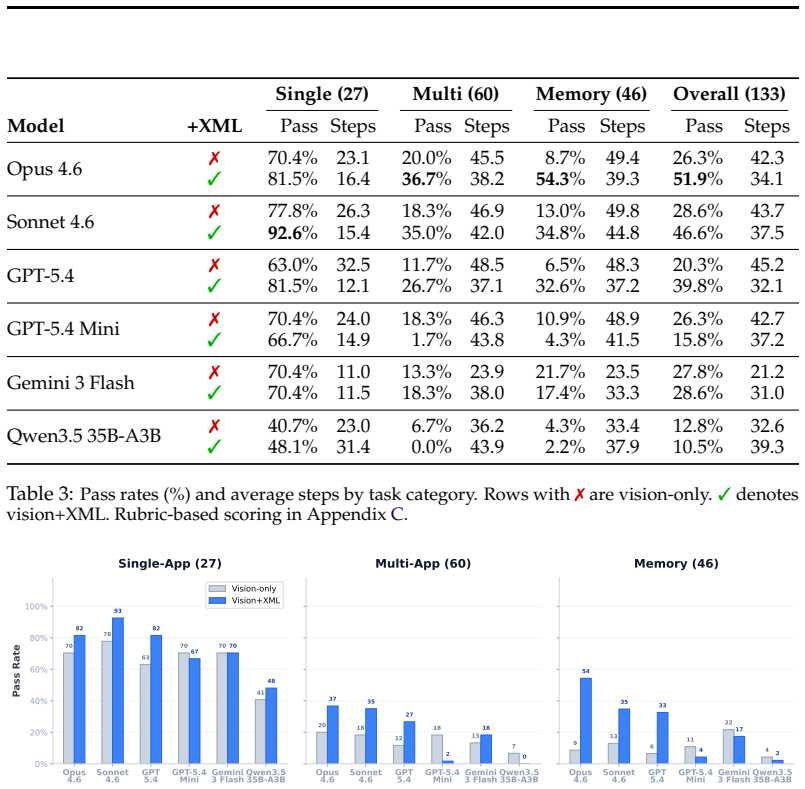
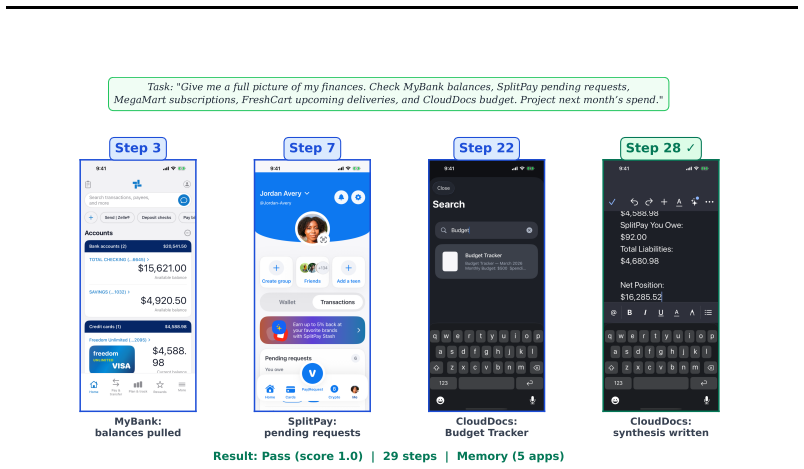
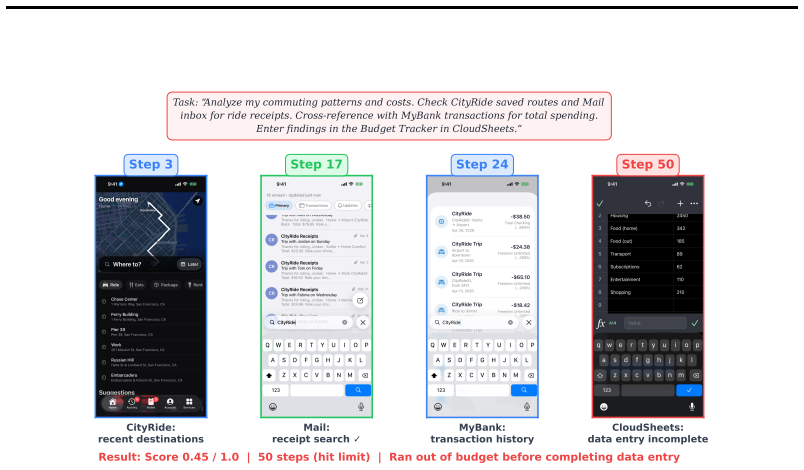
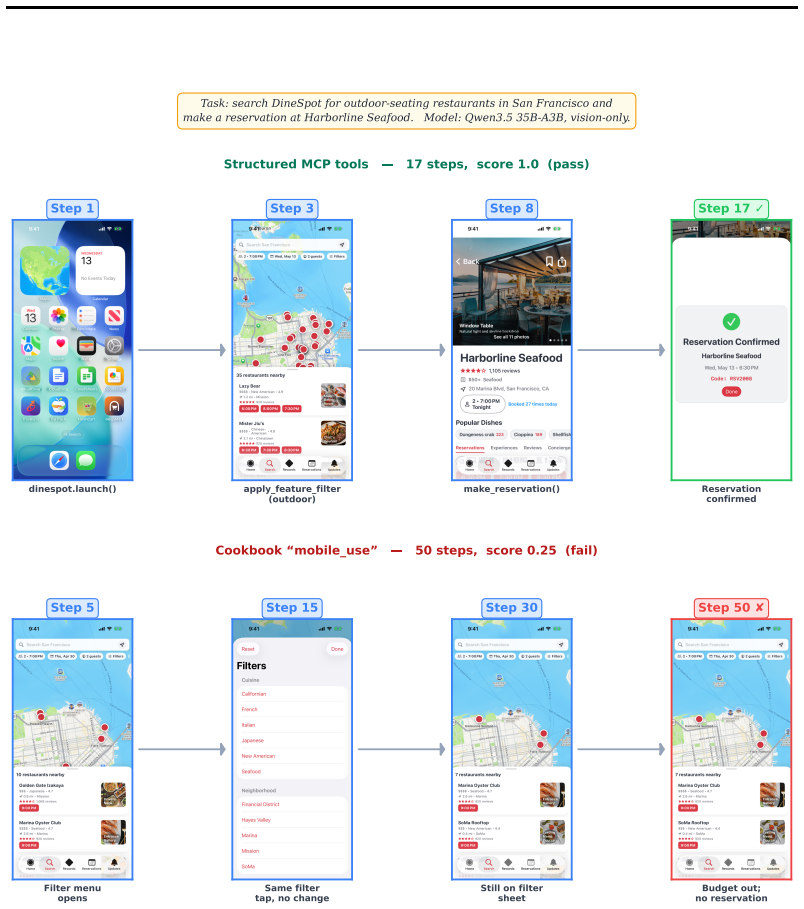
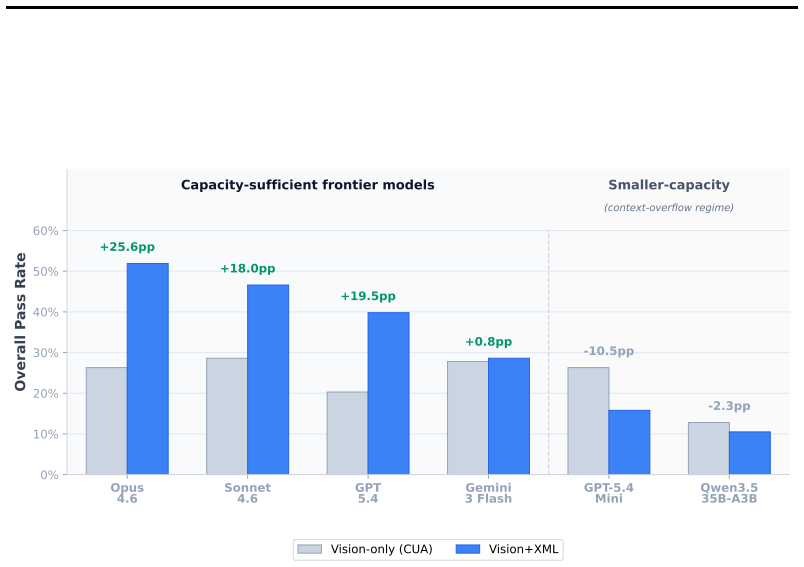
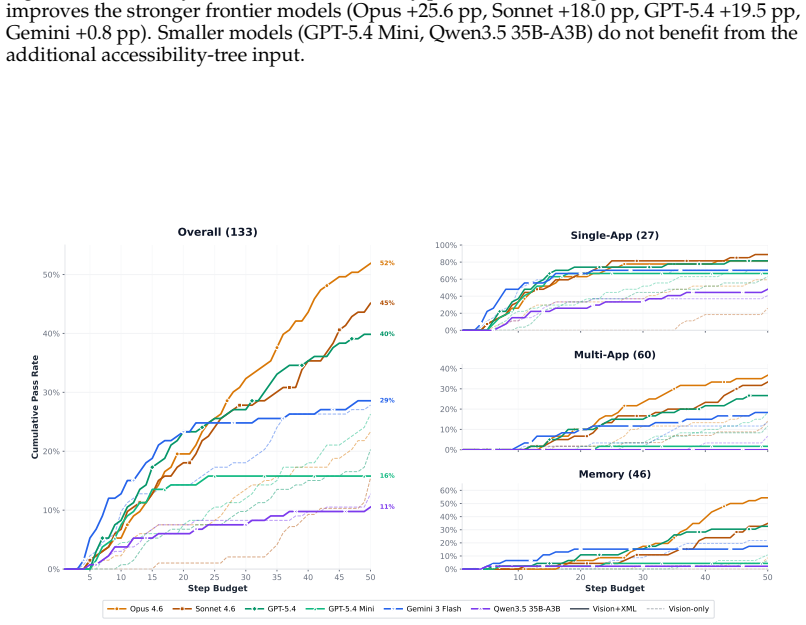
We introduce iOSWorld, the first interactive native iOS simulator benchmark built around a persistent user identity spanning 26 newly built iOS apps. These apps contain connected data such as transactions, messages, travel records, social relationships, and financial activity. iOSWorld includes 133 tasks across three increasingly difficult categories. Single-app tasks test one app, multi-app tasks span 2 to 8 apps, and memory and personalization tasks require agents to infer patterns from personal data. The best configuration reaches 52% overall but only 37% on multi-app tasks. Privileged vision+XML access improves frontier models by up to 26 percentage points, while smaller models do not be
What carries the argument
iOSWorld, the interactive native iOS simulator with 26 apps seeded with connected personal data and 133 tasks that require single-app execution, multi-app coordination, or inference from user history.
If this is right
- Current agents still lack reliable multi-app coordination even when given privileged access.
- Frontier models gain substantial performance from accessibility-tree input while smaller models do not.
- Personalization tasks expose the gap between following isolated instructions and maintaining user-specific memory.
- The benchmark supplies a concrete, reproducible testbed for measuring progress on device-native agent intelligence.
Where Pith is reading between the lines
- Similar simulators could be built for Android or other platforms to check whether the observed limits are platform-specific.
- Agents may need explicit long-term memory architectures beyond what current vision-language models provide.
- If seeded data patterns prove too regular, real-user variability could lower observed success rates further.
- The results suggest prioritizing cross-app data sharing mechanisms in future agent designs.
Load-bearing premise
The seeded personal data and task rubrics across the 26 apps accurately represent the kinds of personalization and memory demands that would appear in real user phone usage.
What would settle it
Testing the same agent configurations on actual iOS devices using real user data and observing whether success rates remain near 52% overall and 37% on multi-app tasks.
Figures







read the original abstract
A useful phone agent needs to be personally intelligent. It should reason over a user's identity, history, and preferences as they exist on the device, not just follow isolated instructions in an impersonal sandbox. Existing mobile agent benchmarks lack this kind of personalization. We introduce iOSWorld, the first interactive native iOS simulator benchmark built around a persistent user identity spanning 26 newly built iOS apps. These apps contain connected data such as transactions, messages, travel records, social relationships, and financial activity. iOSWorld includes 133 tasks across three increasingly difficult categories. Single-app tasks (27) test one app, multi-app tasks (60) span 2 to 8 apps, and memory and personalization tasks (46) require agents to infer patterns from personal data. We evaluate frontier and open-source computer-use models in both vision-only and privileged vision+XML settings. The best configuration reaches 52\% overall but only 37\% on multi-app tasks. Privileged vision+XML access improves frontier models by up to 26 percentage points, while smaller models do not benefit from added accessibility-tree input. We release iOSWorld as an open-source benchmark with all apps, seeded data, tasks, rubrics, and evaluation code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces iOSWorld, the first interactive native iOS simulator benchmark for personally intelligent phone agents. It features 26 newly built apps containing connected personal data (transactions, messages, travel records, etc.) and 133 tasks divided into single-app (27), multi-app (60), and memory/personalization (46) categories. Frontier and open-source computer-use models are evaluated in vision-only and privileged vision+XML settings, with the best configuration achieving 52% overall success (37% on multi-app tasks) and privileged access improving frontier models by up to 26 percentage points. The benchmark, including all apps, seeded data, tasks, rubrics, and evaluation code, is released open-source.
Significance. If the seeded data and rubrics validly exercise personalization and memory demands, iOSWorld would be a valuable open benchmark addressing a clear gap in existing mobile-agent evaluations. The reported performance gaps (especially multi-app and the differential benefit of XML access) provide concrete, falsifiable baselines for future work. The full release of apps, data, tasks, rubrics, and code is a notable strength for reproducibility.
major comments (3)
- [Task construction and validation sections] Task construction and validation (likely §3–4): the manuscript provides no details on how the 133 tasks or rubrics were validated, inter-rater reliability of scoring, or whether data seeding avoids leakage between training corpora and the benchmark; without this, the headline claim that the 46 memory/personalization tasks test inference over personal history remains unanchored.
- [Data seeding and task design] Ecological validity of seeded data (§3): the central interpretation that privileged XML access advances 'personally intelligent' agents rests on the assumption that the synthetic connected data (transactions, messages, etc.) across 26 apps matches the frequency, noise, and inference difficulty of real device usage; the paper should include a concrete comparison or user study to support this.
- [Task categories] Category definitions and scoring (Table 1 or equivalent): the distinction between multi-app and memory/personalization tasks is load-bearing for the 37% multi-app result; the manuscript should clarify overlap and whether any memory tasks can be solved without cross-app reasoning.
minor comments (2)
- [Evaluation setup] Figure clarity: screenshots of the simulator and XML structure would help readers understand the privileged vs. vision-only conditions.
- [Introduction] Missing reference: cite prior mobile-agent benchmarks (e.g., AndroidWorld or similar) when claiming novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We respond to each major comment below and note planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Task construction and validation sections] Task construction and validation (likely §3–4): the manuscript provides no details on how the 133 tasks or rubrics were validated, inter-rater reliability of scoring, or whether data seeding avoids leakage between training corpora and the benchmark; without this, the headline claim that the 46 memory/personalization tasks test inference over personal history remains unanchored.
Authors: We agree that the original manuscript lacks sufficient detail on task and rubric construction. In the revision we will add an expanded subsection in §3 describing the iterative design process for the 133 tasks, the criteria used to ensure memory/personalization tasks require inference over seeded personal history, and the rubric development workflow. We did not conduct formal inter-rater reliability measurements or explicit training-corpus leakage audits; these will be noted as limitations. revision: partial
-
Referee: [Data seeding and task design] Ecological validity of seeded data (§3): the central interpretation that privileged XML access advances 'personally intelligent' agents rests on the assumption that the synthetic connected data (transactions, messages, etc.) across 26 apps matches the frequency, noise, and inference difficulty of real device usage; the paper should include a concrete comparison or user study to support this.
Authors: We acknowledge that a direct empirical comparison or user study would strengthen claims about ecological validity. The seeded data was constructed to reflect common real-world patterns (e.g., transaction frequencies, message threading, travel itineraries) drawn from public iOS app documentation and typical usage scenarios, with explicit cross-app linkages. A controlled user study or quantitative distributional comparison lies outside the scope of the current work; we will expand the data-seeding description in §3 and add an explicit limitations paragraph. revision: partial
-
Referee: [Task categories] Category definitions and scoring (Table 1 or equivalent): the distinction between multi-app and memory/personalization tasks is load-bearing for the 37% multi-app result; the manuscript should clarify overlap and whether any memory tasks can be solved without cross-app reasoning.
Authors: We will revise the category definitions and Table 1 to make the distinctions explicit. Memory/personalization tasks are defined by the requirement to perform inference over a user's personal history or preferences; multi-app tasks are defined by the number of distinct apps that must be accessed. We will add a paragraph clarifying potential overlap, provide examples of memory tasks that can be solved within a single app, and note that the 37% multi-app figure reflects tasks whose primary difficulty is cross-app coordination rather than memory inference. revision: yes
- Formal inter-rater reliability assessment for task scoring
- Empirical user study or quantitative comparison validating ecological validity of the synthetic seeded data
Circularity Check
No circularity: benchmark release with empirical evaluation only
full rationale
The paper introduces iOSWorld as a new benchmark consisting of 26 apps, seeded personal data, 133 tasks, and rubrics. It reports empirical model performance (e.g., 52% overall) on these tasks under vision-only vs. privileged settings. No equations, fitted parameters, predictions derived from inputs, or self-citation chains are present that reduce any claimed result to the inputs by construction. The contribution is the benchmark definition and initial scores; validity concerns about whether the seeded data matches real usage are separate from circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The seeded data in the 26 apps (transactions, messages, travel records, social relationships, financial activity) represents realistic user personal information patterns.
Forward citations
Cited by 1 Pith paper
-
OSWorld2.0: Benchmarking Computer Use Agents on Long-Horizon Real-World Tasks
OSWorld 2.0 is a benchmark of 108 realistic long-horizon computer-use tasks where current agents achieve only 20.6% binary completion, struggling with state inference and constraint tracking.
Reference graph
Works this paper leans on
-
[1]
ACL , year=
LaMP: When Large Language Models Meet Personalization , author=. ACL , year=
-
[2]
ACL , year=
Evaluating Very Long-Term Conversational Memory of LLM Agents , author=. ACL , year=
-
[3]
AAAI , year=
MemoryBank: Enhancing Large Language Models with Long-Term Memory , author=. AAAI , year=
-
[4]
UIST , year=
Generative Agents: Interactive Simulacra of Human Behavior , author=. UIST , year=
-
[5]
Artificial Intelligence , volume=
Planning and Acting in Partially Observable Stochastic Domains , author=. Artificial Intelligence , volume=
-
[6]
ICML , year=
World of Bits: An Open-Domain Platform for Web-Based Agents , author=. ICML , year=
-
[7]
ICLR , year=
Reinforcement Learning on Web Interfaces Using Workflow-Guided Exploration , author=. ICLR , year=
-
[8]
NeurIPS , year=
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , author=. NeurIPS , year=
-
[9]
NeurIPS , year=
Mind2Web: Towards a Generalist Agent for the Web , author=. NeurIPS , year=
-
[10]
ICLR , year=
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. ICLR , year=
-
[11]
ACL , year=
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks , author=. ACL , year=
-
[12]
ACL , year=
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models , author=. ACL , year=
-
[13]
COLM , year=
An Illusion of Progress? Assessing the Current State of Web Agents , author=. COLM , year=
-
[14]
arXiv preprint arXiv:2504.12516 , year=
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents , author=. arXiv preprint arXiv:2504.12516 , year=
-
[15]
arXiv preprint arXiv:2310.11441 , year=
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V , author=. arXiv preprint arXiv:2310.11441 , year=
-
[16]
2025 , journal=
MobileWorld: Benchmarking Autonomous Mobile Agents in Agent-User Interactive and MCP-Augmented Environments , author=. 2025 , journal=
2025
-
[17]
NeurIPS , year=
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments , author=. NeurIPS , year=
-
[18]
ICML , year=
Windows Agent Arena: Evaluating Multi-Modal OS Agents at Scale , author=. ICML , year=
-
[19]
NeurIPS , year=
macOSWorld: A Multilingual Interactive Benchmark for GUI Agents , author=. NeurIPS , year=
-
[20]
ICML , year=
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks? , author=. ICML , year=
-
[21]
ICLR , year=
GAIA: A benchmark for General AI Assistants , author=. ICLR , year=
-
[22]
NeurIPS , year=
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks , author=. NeurIPS , year=
-
[23]
ICLR , year=
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author=. ICLR , year=
-
[24]
arXiv preprint arXiv:2105.13231 , year=
AndroidEnv: A Reinforcement Learning Platform for Android , author=. arXiv preprint arXiv:2105.13231 , year=
-
[25]
NeurIPS , year=
Android in the Wild: A Large-Scale Dataset for Android Device Control , author=. NeurIPS , year=
-
[26]
ICLR , year=
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents , author=. ICLR , year=
-
[27]
arXiv preprint arXiv:2305.08144 , year=
Mobile-Env: Building Qualified Evaluation Benchmarks for LLM-GUI Interaction , author=. arXiv preprint arXiv:2305.08144 , year=
-
[28]
CHI , year=
AppAgent: Multimodal Agents as Smartphone Users , author=. CHI , year=
-
[29]
CVPR , year=
CogAgent: A Visual Language Model for GUI Agents , author=. CVPR , year=
-
[30]
ICLR , year=
Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception , author=. ICLR , year=
-
[31]
ACL , year=
AndroidLab: Training and Systematic Benchmarking of Android Autonomous Agents , author=. ACL , year=
-
[32]
ICLR , year=
SPA-Bench: A Comprehensive Benchmark for SmartPhone Agent Evaluation , author=. ICLR , year=
-
[33]
CoLLAs , year=
B-MoCA: Benchmarking Mobile Device Control Agents across Diverse Configurations , author=. CoLLAs , year=
-
[34]
arXiv preprint arXiv:2501.12326 , year=
UI-TARS: Pioneering Automated GUI Interaction with Native Agents , author=. arXiv preprint arXiv:2501.12326 , year=
-
[35]
MobiCom , year=
AutoDroid: LLM-powered Task Automation in Android , author=. MobiCom , year=
-
[36]
NeurIPS , year=
DigiRL: Training In-The-Wild Device-Control Agents with Autonomous Reinforcement Learning , author=. NeurIPS , year=
-
[37]
ICLR , year=
Digi-Q: Learning VLM Q-Value Functions for Training Device-Control Agents , author=. ICLR , year=
-
[38]
ICCV , year=
GUIOdyssey: A Comprehensive Dataset for Cross-App GUI Navigation on Mobile Devices , author=. ICCV , year=
-
[39]
ECCV , year=
Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs , author=. ECCV , year=
-
[40]
2024 , journal=
SOTOPIA: Interactive Evaluation for Social Intelligence in Language Agents , author=. 2024 , journal=
2024
-
[41]
2023 , journal=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. 2023 , journal=
2023
-
[42]
2026 , howpublished=
Claude Opus 4.6 , author=. 2026 , howpublished=
2026
-
[43]
2026 , howpublished=
Claude Code , author=. 2026 , howpublished=
2026
-
[44]
2026 , howpublished=
GPT-5.4 , author=. 2026 , howpublished=
2026
-
[45]
2026 , howpublished=
Gemini 3 Flash , author=. 2026 , howpublished=
2026
-
[46]
2026 , howpublished=
Qwen3.5-35B-A3B , author=. 2026 , howpublished=
2026
-
[47]
ACL , year=
SkillBot: Towards Automatic Skill Development via User Demonstration , author=. ACL , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.