Time Series as Language: A Universal Tokenizer for General-Purpose Time Series Foundation Models
Pith reviewed 2026-06-28 17:54 UTC · model grok-4.3
The pith
A universal tokenizer converts continuous time series into discrete tokens so that an unmodified large language model can perform zero-shot forecasting, generation, and classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
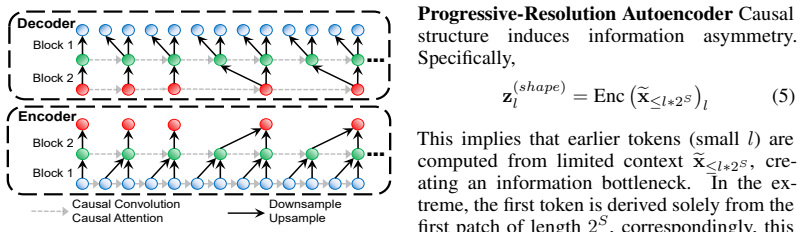
UniTok is a vector-quantized autoencoder with prefix normalization for scale stabilization, a progressive-resolution causal architecture, and a structure-preserving reconstruction loss. UniTok-FM uses an off-the-shelf LLM architecture pretrained via next-token prediction on context windows of multiple series with similar patterns, enabling it to support zero-shot and prompt-boosted forecasting as well as training-free in-context inference for generation and classification.
What carries the argument
UniTok, the universal tokenizer that is a vector-quantized autoencoder transforming time series into discrete tokens while preserving structure through specific normalization and loss terms.
If this is right
- A single model can outperform statistical and supervised baselines on forecasting, generation, and classification tasks.
- The model achieves competitive performance with task-specific foundation models.
- Training-free in-context inference becomes possible across different time series tasks.
- Pretraining on grouped similar series captures shared dynamics for general-purpose use.
Where Pith is reading between the lines
- If the tokenizer works across domains, it could allow foundation models to handle mixed data types like text and time series in one model.
- Extending the context window grouping to more diverse patterns might improve robustness to distribution shifts.
- Testing on very long time series or high-frequency data could reveal limits of the progressive-resolution architecture.
Load-bearing premise
Pretraining an unmodified LLM via next-token prediction on context windows of multiple similar time series will capture enough shared dynamics to enable general-purpose performance across forecasting, generation, and classification without task-specific fine-tuning.
What would settle it
A benchmark where UniTok-FM fails to outperform simple statistical baselines in zero-shot forecasting on a held-out dataset with different patterns from the pretraining groups.
Figures



read the original abstract
While Next-Token Prediction (NTP) has unified LLM pretraining, its adaptation to unbounded, continuous time series (TS) remains open. To bridge the gap, we introduce UniTok, a universal tokenizer that transforms TS into discrete tokens, and UniTok-FM, a foundation model pretrained via NTP on these tokens. UniTok-FM is a general-purpose foundation model that supports zero-shot and prompt-boosted forecasting, as well as few-shot generation and classification via training-free in-context inference--a capability not achieved by prior works. Technically, UniTok is a vector-quantized autoencoder incorporating prefix normalization for scale stabilization, a progressive-resolution causal architecture for encoding and decoding, and a structure-preserving reconstruction loss for training. UniTok-FM adopts an off-the-shelf LLM architecture without TS-specific modifications. Instead of pretraining on isolated TS, it performs NTP on context windows formed by multiple series with similar patterns, aiming to capture their shared dynamics. Experiments on forecasting, generation, and classification show that a single unified UniTok-FM consistently outperforms statistical and supervised baselines, achieves competitive performance with task-specific foundation models, and uniquely enables training-free in-context inference across tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UniTok, a VQ-VAE tokenizer for continuous time series that incorporates prefix normalization for scale stabilization, a progressive-resolution causal encoder/decoder architecture, and a structure-preserving reconstruction loss. It then pretrains UniTok-FM, an unmodified off-the-shelf LLM, via next-token prediction on context windows formed by grouping multiple time series that exhibit similar patterns. The central claim is that this yields a single general-purpose foundation model supporting zero-shot and prompt-boosted forecasting as well as training-free in-context few-shot generation and classification, with experiments showing consistent outperformance over statistical and supervised baselines and competitiveness with task-specific foundation models.
Significance. If the empirical results hold, the work would be significant for demonstrating that an unmodified LLM architecture, when paired with a carefully designed universal tokenizer and grouped-pattern pretraining, can deliver cross-task generalization including training-free in-context inference—a capability not previously achieved for time series. Credit is due for the tokenizer components that directly target scale invariance, causality, and structure preservation, and for the pretraining strategy that aims to capture shared dynamics without task-specific modifications.
minor comments (3)
- [Abstract] Abstract: performance claims are stated without any quantitative metrics, baseline names, or dataset identifiers, which reduces immediate readability even though the full experiments section presumably supplies them.
- [§3.2] §3.2: the structure-preserving loss is described in prose; adding an explicit equation would clarify its distinction from standard VQ-VAE reconstruction terms and aid reproducibility.
- [Experiments] Table captions and axis labels in the experimental figures should explicitly state the number of series, context lengths, and whether results are averaged over multiple random seeds.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work, the recognition of its potential significance, and the recommendation for minor revision. We appreciate the credit given to the tokenizer design and the pretraining strategy.
Circularity Check
No significant circularity; empirical pipeline with no derivation chain
full rationale
The paper describes an empirical construction (VQ-VAE tokenizer with prefix norm, progressive causal encoder, structure-preserving loss, followed by unmodified LLM NTP on grouped similar-pattern windows) and reports experimental results on forecasting/generation/classification. No mathematical derivation, equations, or 'first-principles' claims are present in the provided text. All performance claims are benchmark-driven rather than derived from inputs by construction. No self-citations, fitted parameters renamed as predictions, or uniqueness theorems are invoked in a load-bearing way. The design choices are presented as direct engineering responses to stated requirements, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gift-eval: A benchmark for general time series forecasting model evaluation
Taha Aksu, Gerald Woo, Juncheng Liu, Xu Liu, Chenghao Liu, Silvio Savarese, Caiming Xiong, and Doyen Sahoo. Gift-eval: A benchmark for general time series forecasting model evaluation. arXiv preprint arXiv:2410.10393, 2024
-
[2]
Chronos-2: From Univariate to Universal Forecasting
Abdul Fatir Ansari, Oleksandr Shchur, Jaris Küken, Andreas Auer, Boran Han, Pedro Mercado, Syama Sundar Rangapuram, Huibin Shen, Lorenzo Stella, Xiyuan Zhang, Mononito Goswami, Shubham Kapoor, Danielle C. Maddix, Pablo Guerron, Tony Hu, Junming Yin, Nick Erickson, Prateek Mutalik Desai, Hao Wang, Huzefa Rangwala, George Karypis, Yuyang Wang, and Michael B...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Chronos: Learning the language of time series.Transactions on Machine Learning Research (TMLR), 2024
Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Shubham Kapoor, et al. Chronos: Learning the language of time series.Transactions on Machine Learning Research (TMLR), 2024
2024
-
[4]
Fast and accurate zero-shot forecasting with chronos-bolt and autogluon
Abdul Fatir Ansari, Caner Turkmen, Oleksandr Shchur, and Lorenzo Stella. Fast and accurate zero-shot forecasting with chronos-bolt and autogluon. ht tp s: // aw s. am az on .c om /b lo gs /m ac hi ne -l ea rn in g/ fa st -a nd -a cc ur at e-z er o-s ho t-f or ec as ti ng -w it h-c hr on os -b ol t-a nd -a ut og lu on, 2024
2024
-
[5]
Tirex: Zero-shot forecasting across long and short horizons with enhanced in-context learning
Andreas Auer, Patrick Podest, Daniel Klotz, Sebastian Böck, Günter Klambauer, and Sepp Hochreiter. Tirex: Zero-shot forecasting across long and short horizons with enhanced in-context learning. InConference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[6]
VisionTS: Visual masked autoencoders are free-lunch zero-shot time series forecasters
Mouxiang Chen, Lefei Shen, Zhuo Li, Xiaoyun Joy Wang, Jianling Sun, and Chenghao Liu. VisionTS: Visual masked autoencoders are free-lunch zero-shot time series forecasters. In International Conference on Machine Learning (ICML), 2025. 10
2025
-
[7]
Sdformer: Similarity-driven discrete transformer for time series generation
Zhicheng Chen, FENG SHIBO, Zhong Zhang, Xi Xiao, Xingyu Gao, and Peilin Zhao. Sdformer: Similarity-driven discrete transformer for time series generation. InConference on Neural Information Processing Systems (NeurIPS), 2024
2024
-
[8]
Ben Cohen, Emaad Khwaja, Youssef Doubli, Salahidine Lemaachi, Chris Lettieri, Charles Masson, Hugo Miccinilli, Elise Ramé, Qiqi Ren, Afshin Rostamizadeh, et al. This time is different: An observability perspective on time series foundation models.arXiv preprint arXiv:2505.14766, 2025
-
[9]
The ucr time series classification archive
Hoang Anh Dau, Eamonn Keogh, Kaveh Kamgar, Chin-Chia Michael Yeh, Yan Zhu, Shaghayegh Gharghabi, Chotirat Ann Ratanamahatana, Yanping, Bing Hu, Nurjahan Begum, Anthony Bagnall, Abdullah Mueen, Gustavo Batista, and Hexagon-ML. The ucr time series classification archive. ht tp s: // ww w. cs .u cr .e du /~e am on n/ ti me _s er ie s_ da ta _2 01 8, 2018
2018
-
[10]
A time series forest for classification and feature extraction.Information Sciences, 2013
Houtao Deng, George Runger, Eugene Tuv, and Martyanov Vladimir. A time series forest for classification and feature extraction.Information Sciences, 2013
2013
-
[11]
Abhyuday Desai, Cynthia Freeman, Zuhui Wang, and Ian Beaver. Timevae: A variational auto-encoder for multivariate time series generation.arXiv preprint arXiv:2111.08095, 2021
-
[12]
Ideal spatial adaptation by wavelet shrinkage
David L Donoho and Iain M Johnstone. Ideal spatial adaptation by wavelet shrinkage. biometrika, 1994
1994
-
[13]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InIEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR), 2021
2021
-
[14]
Hdt: Hierarchical dis- crete transformer for multivariate time series forecasting
Shibo Feng, Peilin Zhao, Liu Liu, Pengcheng Wu, and Zhiqi Shen. Hdt: Hierarchical dis- crete transformer for multivariate time series forecasting. InAAAI Conference on Artificial Intelligence (AAAI), 2025
2025
-
[15]
Mantis: Lightweight calibrated foundation model for user-friendly time series classification.1st ICML Workshop on Foundation Models for Structured Data, 2025
Vasilii Feofanov, Songkang Wen, Marius Alonso, Romain Ilbert, Hongbo Guo, Malik Tiomoko, Lujia Pan, Jianfeng Zhang, and Ievgen Redko. Mantis: Lightweight calibrated foundation model for user-friendly time series classification.1st ICML Workshop on Foundation Models for Structured Data, 2025
2025
-
[16]
Units: A unified multi-task time series model
Shanghua Gao, Teddy Koker, Owen Queen, Tom Hartvigsen, Theodoros Tsiligkaridis, and Marinka Zitnik. Units: A unified multi-task time series model. InConference on Neural Information Processing Systems (NeurIPS), 2024
2024
-
[17]
Moment: a family of open time-series foundation models
Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and Artur Dubrawski. Moment: a family of open time-series foundation models. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[18]
Random dilated shapelet transform: A new approach for time series shapelets
Antoine Guillaume, Christel Vrain, and Wael Elloumi. Random dilated shapelet transform: A new approach for time series shapelets. InInternational Conference on Pattern Recognition and Artificial Intelligence (ICPRAI), 2022
2022
-
[19]
Look into the lite in deep learning for time series classification.International Journal of Data Science and Analytics, 2025
Ali Ismail-Fawaz, Maxime Devanne, Stefano Berretti, Jonathan Weber, and Germain Forestier. Look into the lite in deep learning for time series classification.International Journal of Data Science and Analytics, 2025
2025
-
[20]
Inceptiontime: Finding alexnet for time series classification.Data Mining and Knowledge Discovery, 2020
Hassan Ismail Fawaz, Benjamin Lucas, Germain Forestier, Charlotte Pelletier, Daniel F Schmidt, Jonathan Weber, Geoffrey I Webb, Lhassane Idoumghar, Pierre-Alain Muller, and François Petitjean. Inceptiontime: Finding alexnet for time series classification.Data Mining and Knowledge Discovery, 2020
2020
-
[21]
Jian Jia, Jingtong Gao, Ben Xue, Junhao Wang, Qingpeng Cai, Quan Chen, Xiangyu Zhao, Peng Jiang, and Kun Gai. From principles to applications: A comprehensive survey of discrete tokenizers in generation, comprehension, recommendation, and information retrieval.arXiv preprint arXiv:2502.12448, 2025. 11
-
[22]
Time-llm: Time series forecasting by repro- gramming large language models
Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, et al. Time-llm: Time series forecasting by repro- gramming large language models. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[23]
Photo-realistic single image super-resolution using a generative adversarial network
Christian Ledig, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, et al. Photo-realistic single image super-resolution using a generative adversarial network. InIEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR), 2017
2017
-
[24]
Vector quantized time series generation with a bidirectional prior model
Daesoo Lee, Sara Malacarne, and Erlend Aune. Vector quantized time series generation with a bidirectional prior model. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2023
2023
-
[25]
Autoregressive image generation using residual quantization
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. Autoregressive image generation using residual quantization. InIEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR), 2022
2022
-
[26]
Your diffusion model is secretly a zero-shot classifier
Alexander Cong Li, Mihir Prabhudesai, Shivam Duggal, Ellis Langham Brown, and Deepak Pathak. Your diffusion model is secretly a zero-shot classifier. InICML 2023 Workshop on Structured Probabilistic Inference & Generative Modeling, 2023
2023
-
[27]
Autoregressive image generation without vector quantization
Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He. Autoregressive image generation without vector quantization. InConference on Neural Information Processing Systems (NeurIPS), 2024
2024
-
[28]
itransformer: Inverted transformers are effective for time series forecasting
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long. itransformer: Inverted transformers are effective for time series forecasting. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[29]
Sundial: A family of highly capable time series foundation models
Yong Liu, Guo Qin, Zhiyuan Shi, Zhi Chen, Caiyin Yang, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. Sundial: A family of highly capable time series foundation models. In International Conference on Machine Learning (ICML), 2025
2025
-
[30]
Timer: Generative pre-trained transformers are large time series models
Yong Liu, Haoran Zhang, Chenyu Li, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. Timer: Generative pre-trained transformers are large time series models. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[31]
Finite scalar quantization: VQ-V AE made simple
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite scalar quantization: VQ-V AE made simple. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[32]
Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam
Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[33]
Language models are unsupervised multitask learners.OpenAI blog, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 2019
2019
-
[34]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research (JMLR), 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research (JMLR), 2020
2020
-
[35]
Lag-llama: To- wards foundation models for time series forecasting
Kashif Rasul, Arjun Ashok, Andrew Robert Williams, Arian Khorasani, George Adamopoulos, Rishika Bhagwatkar, Marin Biloš, Hena Ghonia, Nadhir Hassen, Anderson Schneider, Sahil Garg, Alexandre Drouin, Nicolas Chapados, Yuriy Nevmyvaka, and Irina Rish. Lag-llama: To- wards foundation models for time series forecasting. InNeurIPS Workshop R0-FoMo:Robustness o...
2023
-
[36]
Generating diverse high-fidelity images with vq-vae-2
Ali Razavi, Aaron Van den Oord, and Oriol Vinyals. Generating diverse high-fidelity images with vq-vae-2. InConference on Neural Information Processing Systems (NeurIPS), 2019. 12
2019
-
[37]
Time-moe: Billion-scale time series foundation models with mixture of experts
Xiaoming Shi, Shiyu Wang, Yuqi Nie, Dianqi Li, Zhou Ye, Qingsong Wen, and Ming Jin. Time-moe: Billion-scale time series foundation models with mixture of experts. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[38]
Yu Shi, Zongliang Fu, Shuo Chen, Bohan Zhao, Wei Xu, Changshui Zhang, and Jian Li. Kronos: A foundation model for the language of financial markets.arXiv preprint arXiv:2508.02739, 2025
-
[39]
Yinbo Sun, Yuchen Fang, Zhibo Zhu, Jia Li, Yu Liu, Qiwen Deng, Jun Zhou, Hang Yu, Xingyu Lu, and Lintao Ma. Xihe: Scalable zero-shot time series learner via hierarchical interleaved block attention.arXiv preprint arXiv:2510.21795, 2025
-
[40]
Totem: Tokenized time series embeddings for general time series analysis.Transactions on Machine Learning Research (TMLR), 2024
Sabera Talukder, Yisong Yue, and Georgia Gkioxari. Totem: Tokenized time series embeddings for general time series analysis.Transactions on Machine Learning Research (TMLR), 2024
2024
-
[41]
Xiaoyu Tao, Shilong Zhang, Mingyue Cheng, Daoyu Wang, Tingyue Pan, Bokai Pan, Changqing Zhang, and Shijin Wang. From values to tokens: An llm-driven framework for context-aware time series forecasting via symbolic discretization.arXiv preprint arXiv:2508.09191, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Visual autoregressive modeling: Scalable image generation via next-scale prediction
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction. InConference on Neural Information Processing Systems (NeurIPS), 2024
2024
-
[44]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Conditional image generation with pixelcnn decoders
Aaron Van den Oord, Nal Kalchbrenner, Lasse Espeholt, Oriol Vinyals, Alex Graves, et al. Conditional image generation with pixelcnn decoders. InConference on Neural Information Processing Systems (NeurIPS), 2016
2016
-
[46]
Neural discrete representation learning
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. InConference on Neural Information Processing Systems (NeurIPS), 2017
2017
-
[47]
Xue Wang, Tian Zhou, Jinyang Gao, Bolin Ding, and Jingren Zhou. Output scaling: Yinglong- delayed chain of thought in a large pretrained time series forecasting model.arXiv preprint arXiv:2506.11029, 2025
-
[48]
Time series classification from scratch with deep neural networks: A strong baseline
Zhiguang Wang, Weizhong Yan, and Tim Oates. Time series classification from scratch with deep neural networks: A strong baseline. InInternational Joint Conference on Neural Networks (IJCNN), 2017
2017
-
[49]
Abstracted shapes as tokens-a generalizable and interpretable model for time-series classification
Yunshi Wen, Tengfei Ma, Lily Weng, Lam Nguyen, and Anak Agung Julius. Abstracted shapes as tokens-a generalizable and interpretable model for time-series classification. InConference on Neural Information Processing Systems (NeurIPS), 2024
2024
-
[50]
Unified training of universal time series forecasting transformers
Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. Unified training of universal time series forecasting transformers. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[51]
Cot-gan: Generating sequential data via causal optimal transport
Tianlin Xu, Li Kevin Wenliang, Michael Munn, and Beatrice Acciaio. Cot-gan: Generating sequential data via causal optimal transport. InConference on Neural Information Processing Systems (NeurIPS), 2020
2020
-
[52]
FITS: Modeling time series with $10k$ parameters
Zhijian Xu, Ailing Zeng, and Qiang Xu. FITS: Modeling time series with $10k$ parameters. In International Conference on Learning Representations (ICLR), 2024. 13
2024
-
[53]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Time-series generative adversarial networks
Jinsung Yoon, Daniel Jarrett, and Mihaela Van der Schaar. Time-series generative adversarial networks. InConference on Neural Information Processing Systems (NeurIPS), 2019
2019
-
[55]
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Lijun Yu, José Lezama, Nitesh B Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Vighnesh Birodkar, Agrim Gupta, Xiuye Gu, et al. Language model beats diffusion–tokenizer is key to visual generation.arXiv preprint arXiv:2310.05737, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
An image is worth 32 tokens for reconstruction and generation
Qihang Yu, Mark Weber, Xueqing Deng, Xiaohui Shen, Daniel Cremers, and Liang-Chieh Chen. An image is worth 32 tokens for reconstruction and generation. InConference on Neural Information Processing Systems (NeurIPS), 2024
2024
-
[57]
Diffusion-TS: Interpretable diffusion for general time series generation
Xinyu Yuan and Yan Qiao. Diffusion-TS: Interpretable diffusion for general time series generation. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[58]
Are transformers effective for time series forecasting? InAAAI Conference on Artificial Intelligence (AAAI), 2023
Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are transformers effective for time series forecasting? InAAAI Conference on Artificial Intelligence (AAAI), 2023
2023
-
[59]
The unreason- able effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreason- able effectiveness of deep features as a perceptual metric. InIEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR), 2018
2018
-
[60]
MMPD: Diverse time series forecasting via multi-mode patch diffusion loss
Yunhao Zhang, Wenyao Hu, Jiale Zheng, Lujia Pan, and Junchi Yan. MMPD: Diverse time series forecasting via multi-mode patch diffusion loss. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[61]
Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting
Yunhao Zhang and Junchi Yan. Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting. InInternational Conference on Learning Representa- tions (ICLR), 2023. 14 A Design Details and Referenced Methods in UniTok A.1 Length Mapping Functions Accounting for the 4 special tokens, 2×8 scale statistic tokens and the...
2023
-
[62]
GIFT-Pretrain[ 1]: This is large-scale corpus released alongside the GIFT-Eval benchmark. A strict split-checking procedure is applied to ensure that no test data from GIFT-Eval appears in the pretraining set, guaranteeing a fully zero-shot evaluation for TSFMs trained on it. The dataset consists of 88 sub-datasets spanning 7 domains and 13 sampling frequ...
-
[63]
Dataset/Frequency/Prediction Term
Chronos-Dataset[ 3]: This is the dataset for training and evaluation of Chronos. The original dataset contains 67 subsets spanning 8 domains and is publicly available at https://huggingface. co/datasets/autogluon/chronos_datasets. These two datasets partially overlap. We carefully construct their union and avoid test-set leak- age by adding the following ...
-
[64]
Normalization by Seasonal-Naive:For each task i, the raw score si is normalized by the corre- sponding score of Seasonal-Naives (season) i : esi = si s(season) i (19) This normalization reflects the relative performance of the evaluated model compared to the Seasonal- Naive baseline
-
[65]
Dataset / Frequency / Prediction Term
Geometric Mean Aggregation:The final aggregated score is computed as the geometric mean of the normalized scores across allN= 97tasks: sagg = ( NY i=1 esi)1/N (20) C.2 Few-Shot Generation DatasetsWe adopt four real-world datasets from Diffusion-TS [ 57] (i.e., Stocks, ETTh, Energy, fMRI) for generation evaluation. For each dataset, only the first channel ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.