IntentKV: Cross-Turn Intent-Aware KV Cache Pruning for Agent Inference
Pith reviewed 2026-06-27 20:02 UTC · model grok-4.3
The pith
IntentKV prunes KV cache for multi-turn LLM agents by tracking cross-turn intent, matching full-cache accuracy at 8k budgets while cutting worst-case peak tokens 77.8%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
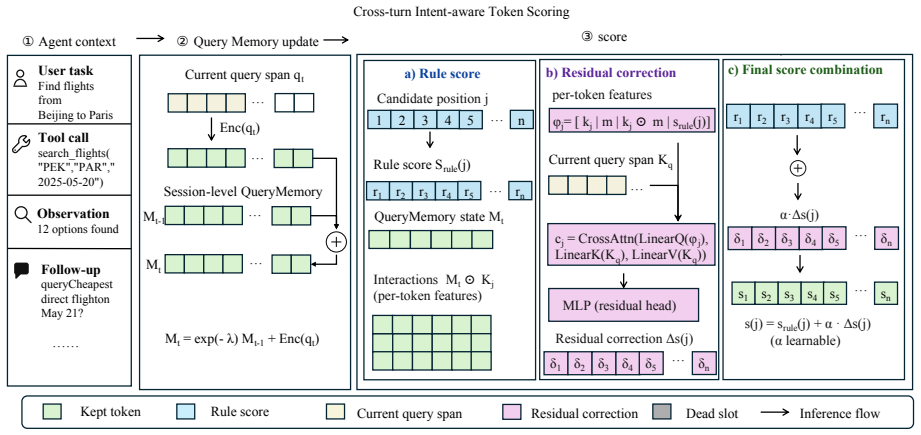
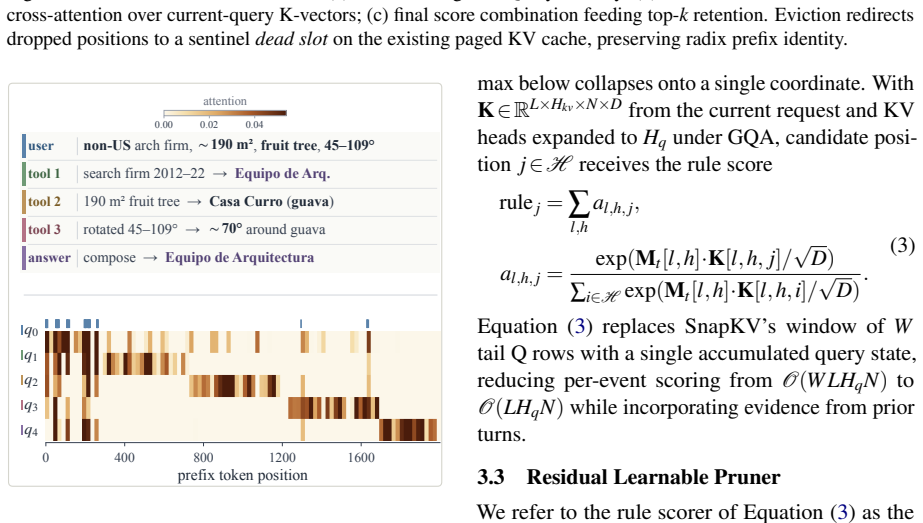
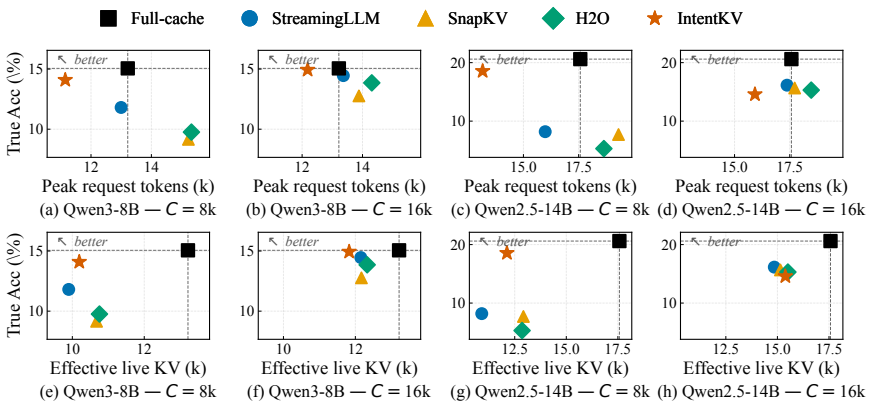
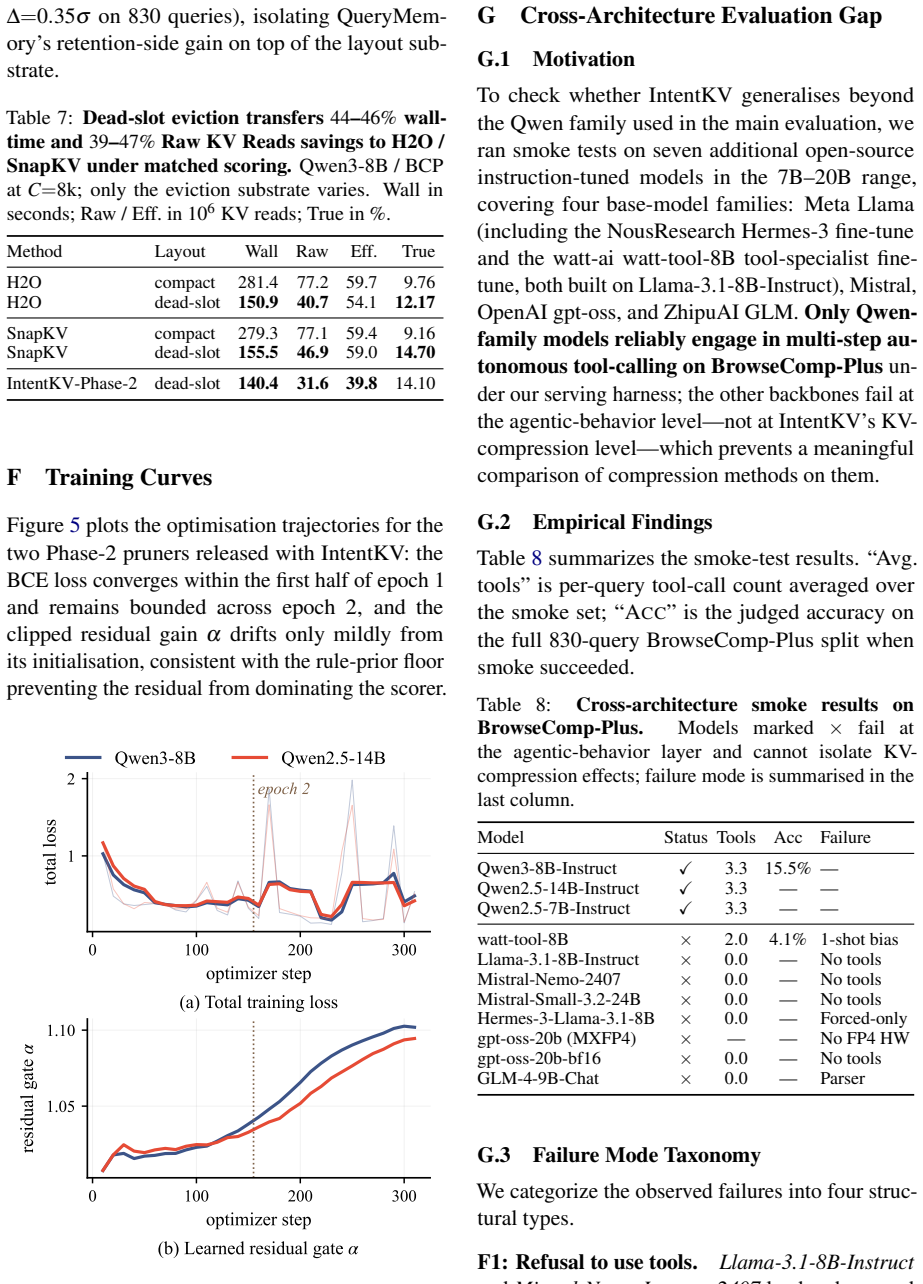
IntentKV maintains a session-level QueryMemory of cross-turn intent, scores live history tokens with a memory-attention rule, and adds a zero-initialized residual head with cross-attention over current-query K-vectors. Eviction occurs through slot-map redirection so that dropped positions route to a sentinel dead slot while surviving rows and identities stay in place. The method matches the no-pruning full-cache baseline with almost no accuracy drop under tight KV budgets, for instance reducing mean peak request tokens 23.9% on Qwen3-8B and 30.7% on Qwen2.5-14B at an 8k budget, and cutting worst-case peak tokens 77.8% and raw KV reads 92.6% on the longest queries.
What carries the argument
The session-level QueryMemory together with the memory-attention scoring rule and zero-initialized residual head, which together score tokens according to cross-turn intent to decide which to keep.
If this is right
- At an 8k KV budget mean peak request tokens drop 23.9% on Qwen3-8B and 30.7% on Qwen2.5-14B.
- On the 100 longest BCP queries that all methods complete on Qwen2.5-14B, worst-case peak request tokens fall from 92.3k to 20.5k.
- Worst-case raw KV reads fall from 411M to 31M, a 92.6% reduction.
- The slot-map redirection keeps the pruned cache composable with existing prefix-caching systems.
Where Pith is reading between the lines
- The same intent-tracking mechanism could extend the feasible length of agent trajectories on fixed hardware budgets.
- Because the base LLM stays frozen, the pruning head could be swapped or retrained independently when new agent domains appear.
- The slot-redirection design may allow direct drop-in use inside existing LLM serving stacks that already rely on prefix caches.
Load-bearing premise
The learned memory-attention scoring rule and residual head will generalize across query distributions and model scales without introducing accuracy degradation.
What would settle it
Running IntentKV at an 8k KV budget on a fresh collection of long multi-turn agent queries and measuring a clear accuracy drop relative to the full-cache baseline.
Figures

read the original abstract
Multi-turn LLM agents fan short queries into long trajectories of tool calls, search results, and intermediate reasoning. Both KV memory and KV read bandwidth grow by orders of magnitude across a single trajectory, making the key-value (KV) cache, not parameter compute, the dominant serving bottleneck for long-horizon agents. We introduce IntentKV, learned KV pruning that keeps the base LLM frozen. IntentKV maintains a session-level QueryMemory of cross-turn intent, scores live history tokens with a memory-attention rule, and adds a zero-initialized residual head with cross-attention over current-query K-vectors. To stay composable with prefix caches, eviction is a slot-map redirection: dropped positions route to a sentinel dead slot while surviving K/V rows, RoPE phases, and slot identities stay in place. IntentKV matches the no-pruning full-cache baseline with almost no accuracy drop under tight KV budgets: at an 8k KV budget, mean peak request tokens drop 23.9% on Qwen3-8B and 30.7% on Qwen2.5-14B. On the 100 longest BCP queries that all methods complete on Qwen2.5-14B, IntentKV-8k further cuts worst-case peak request tokens from 92.3k to 20.5k, a 77.8% reduction, and worst-case raw KV reads from 411M to 31M, a 92.6% reduction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IntentKV, a learned KV cache pruning technique for multi-turn LLM agents that keeps the base model frozen. It maintains a session-level QueryMemory of cross-turn intent, applies a memory-attention scoring rule to history tokens, and incorporates a zero-initialized residual head with cross-attention. Eviction uses slot-map redirection for compatibility with prefix caches. The central empirical claim is that IntentKV achieves large reductions in peak request tokens and KV reads (e.g., 23.9% mean reduction on Qwen3-8B and 30.7% on Qwen2.5-14B at 8k budget; 77.8% worst-case token reduction and 92.6% KV read reduction on longest queries) while matching full-cache accuracy with almost no drop.
Significance. If the accuracy preservation holds across distributions, the work targets a practical serving bottleneck for long-horizon agents where KV cache and bandwidth dominate over parameter compute. The design choices of freezing the LLM, using learned but lightweight scoring, and ensuring composability via slot redirection are pragmatic strengths that could enable broader adoption if the empirical trade-offs are fully quantified.
major comments (2)
- [Abstract] Abstract: The headline claim that IntentKV 'matches the no-pruning full-cache baseline with almost no accuracy drop' is unsupported by any reported accuracy metrics (task success rate, F1, perplexity delta, or similar) comparing IntentKV to the full-cache baseline. Only efficiency metrics (token/KV reductions) are quantified. This is load-bearing for the central contribution, as the method's value rests on demonstrating that the learned QueryMemory, memory-attention scorer, and residual head preserve task performance under eviction.
- [Abstract] The manuscript provides no experimental protocol details, baseline implementations, statistical tests, error bars, or ablation on the learned components' generalization to unseen trajectories and model scales. This leaves the weakest assumption (that the frozen-LLM-trained scorer generalizes without accuracy degradation) unverified rather than demonstrated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for explicit accuracy metrics and fuller experimental details in the abstract and main text. We will revise the manuscript to address these points directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that IntentKV 'matches the no-pruning full-cache baseline with almost no accuracy drop' is unsupported by any reported accuracy metrics (task success rate, F1, perplexity delta, or similar) comparing IntentKV to the full-cache baseline. Only efficiency metrics (token/KV reductions) are quantified. This is load-bearing for the central contribution, as the method's value rests on demonstrating that the learned QueryMemory, memory-attention scorer, and residual head preserve task performance under eviction.
Authors: We agree the abstract claim requires quantitative backing. The manuscript's experiments compare task performance under pruning versus full cache, but specific deltas are not highlighted in the abstract. We will revise the abstract to report accuracy metrics (e.g., task success rate or equivalent deltas) and add a supporting table in the results section showing preservation under the evaluated budgets and models. revision: yes
-
Referee: [Abstract] The manuscript provides no experimental protocol details, baseline implementations, statistical tests, error bars, or ablation on the learned components' generalization to unseen trajectories and model scales. This leaves the weakest assumption (that the frozen-LLM-trained scorer generalizes without accuracy degradation) unverified rather than demonstrated.
Authors: We accept this assessment. The current manuscript focuses on efficiency results without sufficient protocol, baseline, statistical, or ablation details. In revision we will expand the experimental section with full protocol description, baseline setups, error bars from repeated runs, statistical tests, and ablations on QueryMemory/scorer generalization across trajectories and scales. revision: yes
Circularity Check
No circularity; empirical learned method with independent validation
full rationale
The paper presents IntentKV as a learned KV pruning approach using a session-level QueryMemory, memory-attention scoring, and zero-init residual head, all trained while keeping the base LLM frozen. Reported gains are empirical measurements of peak tokens and KV reads under fixed budgets, compared against a full-cache baseline. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce any result to a definitional identity or input by construction. The central claims rest on external experimental checks rather than internal self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , volume=
Efficient streaming language models with attention sinks , author=. International Conference on Learning Representations , volume=
-
[2]
Advances in Neural Information Processing Systems , volume=
Snapkv: Llm knows what you are looking for before generation , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Advances in Neural Information Processing Systems , volume=
H2o: Heavy-hitter oracle for efficient generative inference of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
arXiv preprint arXiv:2512.03324 , year=
Cache what lasts: Token retention for memory-bounded kv cache in llms , author=. arXiv preprint arXiv:2512.03324 , year=
-
[5]
Continuum: Efficient and Robust Multi-Turn LLM Agent Scheduling with KV Cache Time-to-Live
Continuum: Efficient and robust multi-turn llm agent scheduling with kv cache time-to-live , author=. arXiv preprint arXiv:2511.02230 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
DynamicKV: Task-aware adaptive KV cache compression for long context LLMs , author=. arXiv preprint arXiv:2412.14838 , year=
-
[7]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling , author=. arXiv preprint arXiv:2406.02069 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Quest: Query-aware sparsity for efficient long-context llm inference , author=. arXiv preprint arXiv:2406.10774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Expected attention: Kv cache compression by estimating attention from future queries distribution
Expected attention: Kv cache compression by estimating attention from future queries distribution , author=. arXiv preprint arXiv:2510.00636 , year=
-
[10]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Kivi: A tuning-free asymmetric 2bit quantization for kv cache , author=. arXiv preprint arXiv:2402.02750 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Gear: An efficient kv cache compression recipefor near- lossless generative inference of llm,
Gear: An efficient kv cache compression recipe for near-lossless generative inference of llm , author=. arXiv preprint arXiv:2403.05527 , year=
-
[12]
International Conference on Learning Representations , volume=
Long context compression with activation beacon , author=. International Conference on Learning Representations , volume=
-
[13]
, author=
MemGPT: towards LLMs as operating systems. , author=. 2023 , publisher=
2023
-
[14]
Advances in Neural Information Processing Systems , volume=
A-mem: Agentic memory for llm agents , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[16]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[18]
arXiv preprint arXiv:2508.06600 , year=
Browsecomp-plus: A more fair and transparent evaluation benchmark of deep-research agent , author=. arXiv preprint arXiv:2508.06600 , year=
-
[19]
arXiv preprint arXiv:2412.19442 , year=
A survey on large language model acceleration based on kv cache management , author=. arXiv preprint arXiv:2412.19442 , year=
-
[20]
arXiv preprint arXiv:2602.22603 , year=
SideQuest: Model-Driven KV Cache Management for Long-Horizon Agentic Reasoning , author=. arXiv preprint arXiv:2602.22603 , year=
-
[21]
International Conference on Learning Representations , volume=
Toolllm: Facilitating large language models to master 16000+ real-world apis , author=. International Conference on Learning Representations , volume=
-
[22]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Stabletoolbench: Towards stable large-scale benchmarking on tool learning of large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[23]
arXiv preprint arXiv:2603.10899 , year=
LookaheadKV: Fast and Accurate KV Cache Eviction by Glimpsing into the Future without Generation , author=. arXiv preprint arXiv:2603.10899 , year=
-
[24]
Advances in neural information processing systems , volume=
Sglang: Efficient execution of structured language model programs , author=. Advances in neural information processing systems , volume=
-
[25]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Neurocomputing , volume=
Roformer: Enhanced transformer with rotary position embedding , author=. Neurocomputing , volume=. 2024 , publisher=
2024
-
[27]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[28]
Advances in Neural Information Processing Systems , volume=
Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
International Conference on Learning Representations , volume=
Model tells you what to discard: Adaptive kv cache compression for llms , author=. International Conference on Learning Representations , volume=
-
[30]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Forty-second International Conference on Machine Learning , year=
The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models , author=. Forty-second International Conference on Machine Learning , year=
-
[32]
arXiv preprint arXiv:2409.12941 , year=
Fact, fetch, and reason: A unified evaluation of retrieval-augmented generation , author=. arXiv preprint arXiv:2409.12941 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.