Forward-Only Convolutional Neural Networks with Learnable Channel-Class Assignment
Pith reviewed 2026-06-27 18:42 UTC · model grok-4.3
The pith
Learnable channel-class assignment improves forward-forward CNNs on CIFAR-10, CIFAR-100 and Tiny-ImageNet.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The introduction of a learnable channel-class assignment mechanism, supported by entropy and orthogonality regularization, together with a loss-aware layer contribution strategy, allows residual forward-forward CNNs to achieve new state-of-the-art results among forward-forward models on CIFAR-10, CIFAR-100, and Tiny-ImageNet.
What carries the argument
Learnable channel-class assignment mechanism that enables adaptive, data-driven specialization of convolutional channels.
If this is right
- Consistently superior performance across CIFAR-10, CIFAR-100, and Tiny-ImageNet compared to existing forward-only methods.
- New state-of-the-art performance among FF-based models.
- Substantial narrowing of the gap with backpropagation-trained models.
Where Pith is reading between the lines
- Adaptive channel specialization may prove necessary for scaling forward-only algorithms to deeper vision networks.
- The loss-aware weighting idea could transfer to other local learning rules that combine multiple layer predictions.
- Applying the same learnable assignment to non-residual or non-convolutional forward-only models would test whether the benefit is architecture-specific.
Load-bearing premise
The reported performance gains arise specifically from the learnable channel-class assignment and loss-aware weighting rather than from differences in architecture details, hyperparameters, or training protocol.
What would settle it
Training identical residual CNN architectures on the same datasets with the same protocol but using fixed static channel-class partitions instead of the learnable assignment, then checking whether the accuracy advantage disappears.
Figures
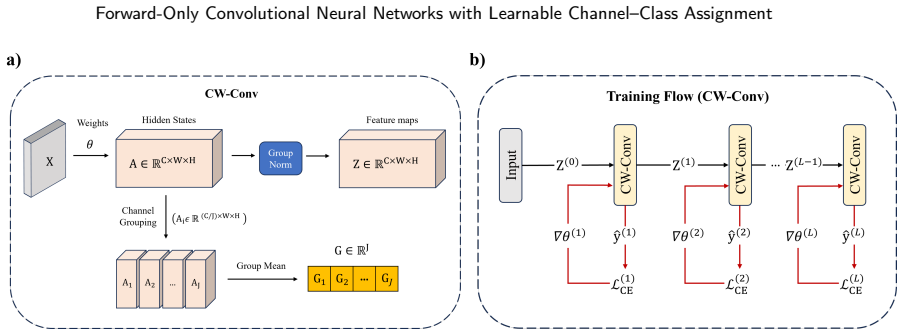
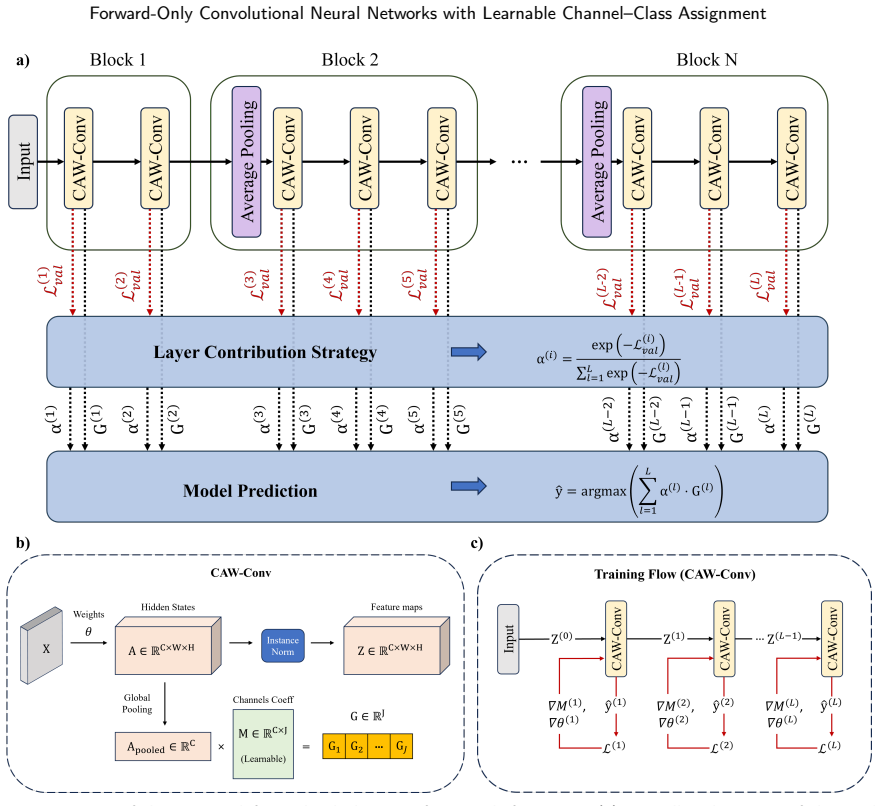
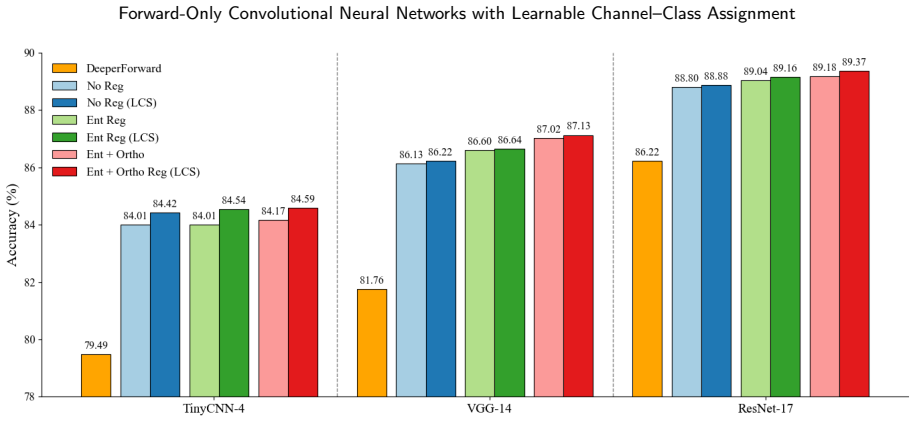
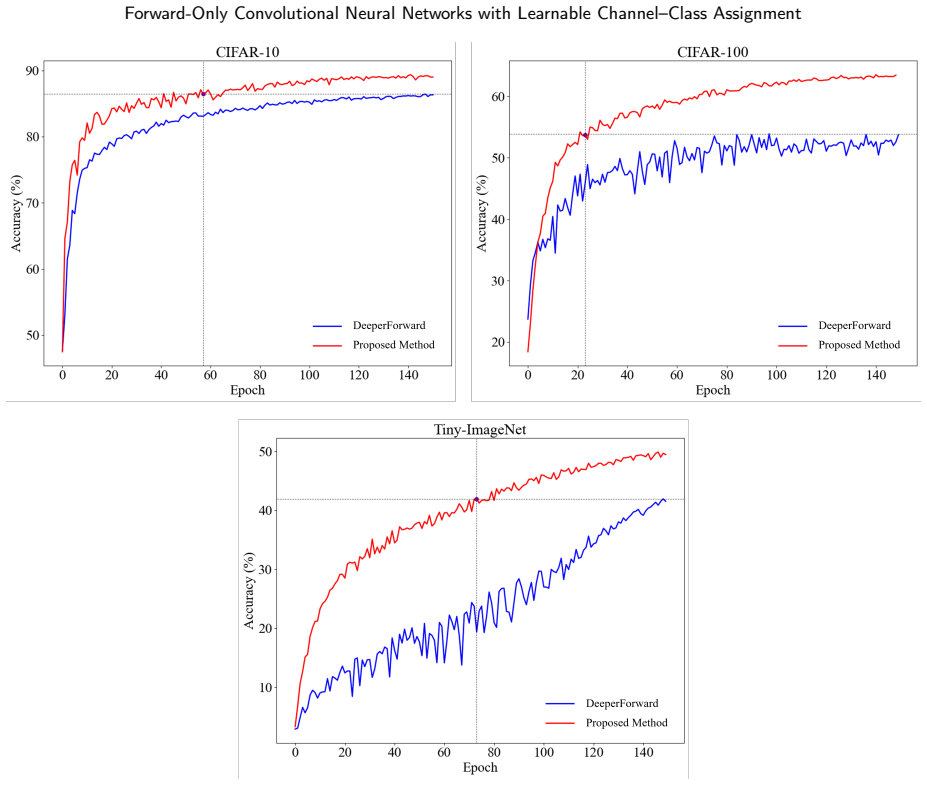
read the original abstract
The Forward-Forward (FF) algorithm offers a biologically inspired alternative to backpropagation by replacing gradient-based credit assignment with local, forward-only objectives. While recent extensions have adapted FF to convolutional neural networks (CNNs), existing formulations rely on static channel-class partitions and struggle to perform effectively in complex tasks. In this work, we introduce a learnable channel-class assignment mechanism that enables adaptive, data-driven specialization of convolutional channels, supported by entropy and orthogonality regularization to promote learning performance. We further propose a loss-aware layer contribution strategy that adaptively weights intermediate-layer predictions based on their validation performance, enhancing the effectiveness of forward-only inference. Integrated into residual CNNs, the proposed method achieves consistently superior performance across CIFAR-10, CIFAR-100, and Tiny-ImageNet compared to existing similar forward-only methods. Notably, it establishes new state-of-the-art performance among FF-based models, substantially narrowing the gap with backpropagation. These findings demonstrate that introducing learnable channel specialization and layer contribution weighting significantly enhances the representational capacity of forward-only learning in deep CNNs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a learnable channel-class assignment mechanism for Forward-Forward (FF) convolutional networks, augmented by entropy/orthogonality regularization and a loss-aware weighting of layer contributions. It integrates these into residual CNNs and reports consistent gains over prior FF-CNN baselines on CIFAR-10, CIFAR-100, and Tiny-ImageNet, establishing new state-of-the-art results among FF-based models while narrowing the gap to backpropagation.
Significance. If the performance improvements can be rigorously attributed to the learnable assignment and weighting rather than protocol differences, the work would meaningfully extend the applicability of local, forward-only objectives to deeper CNN architectures and reduce reliance on static partitions that limit prior FF-CNNs.
major comments (2)
- [Experiments] Experiments section: the central claim that gains arise specifically from learnable channel-class assignment (rather than residual integration, hyperparameter choices, or training-protocol differences) is not supported by ablations that freeze the assignment mechanism while retaining all other proposed components; without such controls the attribution to the new mechanisms remains insecure.
- [Method] § on loss-aware layer contribution: the validation-based weighting is presented as enhancing forward-only inference, yet no quantitative comparison is shown isolating its effect from the channel-assignment module, leaving unclear whether both innovations are load-bearing for the reported SOTA numbers.
minor comments (1)
- [Abstract] Abstract supplies no error bars, dataset splits, or implementation specifics; these should be summarized even at high level to allow readers to assess the strength of the empirical claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight the need for stronger controls to attribute performance gains, and we will revise the manuscript accordingly to address both points.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that gains arise specifically from learnable channel-class assignment (rather than residual integration, hyperparameter choices, or training-protocol differences) is not supported by ablations that freeze the assignment mechanism while retaining all other proposed components; without such controls the attribution to the new mechanisms remains insecure.
Authors: We agree that the current experiments do not include ablations that freeze the learnable channel-class assignment while retaining residuals, regularization, and loss-aware weighting. In the revision we will add these controls (e.g., random or static partitions) to isolate the contribution of the learnable assignment and thereby strengthen the attribution of the reported gains. revision: yes
-
Referee: [Method] § on loss-aware layer contribution: the validation-based weighting is presented as enhancing forward-only inference, yet no quantitative comparison is shown isolating its effect from the channel-assignment module, leaving unclear whether both innovations are load-bearing for the reported SOTA numbers.
Authors: We acknowledge that an isolated ablation of the loss-aware weighting is missing. The revised manuscript will include a direct comparison (uniform/fixed weights versus the proposed adaptive weighting) while keeping the learnable assignment fixed, to quantify the individual contribution of each component to the final results. revision: yes
Circularity Check
No circularity; empirical proposal of mechanisms with reported performance gains.
full rationale
The paper proposes learnable channel-class assignment with regularization and loss-aware weighting for forward-forward CNNs, then reports superior empirical results on CIFAR-10/100 and Tiny-ImageNet versus prior FF methods. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims rest on experimental comparisons rather than any reduction of outputs to inputs by construction, so the work is self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep learning without weight transport, in: Advances in Neural Information Processing Systems (NeurIPS)
Akrout, M., Wilson, C., Humphreys, P., Lillicrap, T., Tweed, D., 2019. Deep learning without weight transport, in: Advances in Neural Information Processing Systems (NeurIPS)
2019
-
[2]
Assessing the scalability of biologically motivated deep learning algorithms, in: Advances in Neural Information Processing Systems (NeurIPS)
Bartunov, S., Santoro, A., Richards, B., Marris, L., Hinton, G.E., Lillicrap, T., 2018. Assessing the scalability of biologically motivated deep learning algorithms, in: Advances in Neural Information Processing Systems (NeurIPS)
2018
-
[3]
Decoupled greedy learning of cnns, in: International Conference on Machine Learning (ICML)
Belilovsky, E., Eickenberg, M., Oyallon, E., 2020. Decoupled greedy learning of cnns, in: International Conference on Machine Learning (ICML)
2020
-
[4]
Bengio,Y.,2014.Howauto-encoderscouldprovidecreditassignmentindeepnetworksviatargetpropagation.arXivpreprintarXiv:1407.7906
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[5]
Learning long-term dependencies with gradient descent is difficult
Bengio, Y., Simard, P., Frasconi, P., 1994. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks 5, 157–166
1994
-
[6]
Self-contrastive forward-forward algorithm
Chen, X., Liu, D., Laydevant, J., Grollier, J., 2025. Self-contrastive forward-forward algorithm. Nature Communications 16, 5978
2025
-
[7]
Unlockingdeeplearning:Abp-freeapproachfor parallelblock-wisetrainingofneuralnetworks,in:ICASSP2024-IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing, pp
Cheng,A.,Ping,H.,Wang,Z.,Xiao,X.,Yin,C.,Nazarian,S.,Cheng,M.,Bogdan,P.,2024. Unlockingdeeplearning:Abp-freeapproachfor parallelblock-wisetrainingofneuralnetworks,in:ICASSP2024-IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing, pp. 4235–4239
2024
-
[8]
Understanding synthetic gradients and decoupled neural interfaces, in: International Conference on Machine Learning (ICML)
Czarnecki, W.M., Świrszcz, G., Jaderberg, M., Osindero, S., Vinyals, O., Kavukcuoglu, K., 2017. Understanding synthetic gradients and decoupled neural interfaces, in: International Conference on Machine Learning (ICML)
2017
-
[9]
Error-driven input modulation: Solving the credit assignment problem without a backward pass, in: Proceedings of the 39th International Conference on Machine Learning, PMLR
Dellaferrera, G., Kreiman, G., 2022. Error-driven input modulation: Solving the credit assignment problem without a backward pass, in: Proceedings of the 39th International Conference on Machine Learning, PMLR. pp. 4937–4955
2022
-
[10]
The trifecta: Three simple techniques for training deeper forward-forward networks
Dooms, T., Tsang, I.J., Oramas, J., 2023. The trifecta: Three simple techniques for training deeper forward-forward networks. arXiv preprint arXiv:2311.18130
-
[11]
Towards scaling difference target propagation, in: International Conference on Machine Learning (ICML)
Ernoult, M., Normandin, F., Moudgil, A., Spinney, S., Belilovsky, E., Rish, I., Richards, B., Bengio, Y., 2022. Towards scaling difference target propagation, in: International Conference on Machine Learning (ICML)
2022
-
[12]
Feed-forwardoptimizationwithdelayedfeedbackforneuralnetwork training, in: Neural Information Processing – ICONIP 2024
Flügel,K.,Coquelin,D.,Weiel,M.,Debus,C.,Streit,A.,Götz,M.,2025. Feed-forwardoptimizationwithdelayedfeedbackforneuralnetwork training, in: Neural Information Processing – ICONIP 2024. Springer, Singapore. volume 15289, pp. 67–78
2025
-
[13]
Ghader, M., Kheradpisheh, S.R., Farahani, B., Fazlali, M., 2024. Enabling privacy-preserving edge ai: Federated learning enhanced with forward-forward algorithm, in: 2024 IEEE International Conference on Omni-layer Intelligent Systems (COINS), pp. 1–7. doi:10.1109/ COINS61597.2024.10622150
-
[14]
Backpropagation-free spiking neural networks with the forward–forward algorithm
Ghader, M., Kheradpisheh, S.R., Farahani, B., Fazlali, M., 2026. Backpropagation-free spiking neural networks with the forward–forward algorithm. Scientific Reports 16, 14294. doi:10.1038/s41598-026-41671-4
-
[15]
Understanding the difficulty of training deep feedforward neural networks, in: Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS)
Glorot, X., Bengio, Y., 2010. Understanding the difficulty of training deep feedforward neural networks, in: Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS)
2010
-
[16]
Noise-contrastive estimation, in: Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS)
Gutmann, M., Hyvärinen, A., 2010. Noise-contrastive estimation, in: Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS). M. Ghader et al.:Preprint submitted to ElsevierPage 14 of 15 Forward-Only Convolutional Neural Networks with Learnable Channel–Class Assignment
2010
-
[17]
The forward-forward algorithm: Some preliminary investigations
Hinton, G.E., 2022. The forward-forward algorithm: Some preliminary investigations. arXiv preprint arXiv:2212.13345
-
[18]
Learning and relearning in boltzmann machines, in: Parallel Distributed Processing
Hinton, G.E., Sejnowski, T.J., 1986. Learning and relearning in boltzmann machines, in: Parallel Distributed Processing. MIT Press
1986
-
[19]
Decoupled parallel backpropagation with convergence guarantee, in: Advances in Neural Information Processing Systems (NeurIPS)
Huo, Z., Gu, B., Yang, Q., Huang, H., 2018. Decoupled parallel backpropagation with convergence guarantee, in: Advances in Neural Information Processing Systems (NeurIPS)
2018
-
[20]
Decoupled neural interfaces using synthetic gradients, in: International Conference on Machine Learning (ICML)
Jaderberg, M., Czarnecki, W.M., Osindero, S., Vinyals, O., Graves, A., Silver, D., Kavukcuoglu, K., 2017. Decoupled neural interfaces using synthetic gradients, in: International Conference on Machine Learning (ICML)
2017
-
[21]
Hebbian deep learning without feedback, in: International Conference on Learning Representations (ICLR)
Journe, A., Rodriguez, H.G., Guo, Q., Moraitis, T., 2023. Hebbian deep learning without feedback, in: International Conference on Learning Representations (ICLR)
2023
-
[22]
Learning multiple layers of features from tiny images
Krizhevsky, A., 2009. Learning multiple layers of features from tiny images. URL:https://api.semanticscholar.org/CorpusID: 18268744
2009
-
[23]
Imagenet classification with deep convolutional neural networks, in: Advances in Neural Information Processing Systems (NeurIPS)
Krizhevsky, A., Sutskever, I., Hinton, G.E., 2012. Imagenet classification with deep convolutional neural networks, in: Advances in Neural Information Processing Systems (NeurIPS)
2012
-
[24]
Tinyimagenetvisualrecognitionchallenge
Le,Y.,Yang,X.S.,2015. Tinyimagenetvisualrecognitionchallenge. URL:https://api.semanticscholar.org/CorpusID:16664790
2015
-
[25]
The mnist database of handwritten digits
LeCun, Y., Cortes, C., Burges, C.J.C., 1998. The mnist database of handwritten digits. URL:http://yann.lecun.com/exdb/mnist/
1998
-
[26]
Difference target propagation, in: European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD)
Lee, D.H., Zhang, S., Fischer, A., Bengio, Y., 2015. Difference target propagation, in: European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD)
2015
-
[27]
Lee, H.C., Song, J., 2023. Symba: Symmetric backpropagation-free contrastive learning with forward-forward algorithm for optimizing convergence. arXiv preprint arXiv:2303.08418
-
[28]
Random synaptic feedback weights support error backpropagation for deep learning
Lillicrap, T.P., Cownden, D., Tweed, D.B., Akerman, C.J., 2016. Random synaptic feedback weights support error backpropagation for deep learning. Nature Communications 7, 13276
2016
-
[29]
Direct feedback alignment provides learning in deep neural networks, in: Advances in Neural Information Processing Systems (NeurIPS)
Nøkland, A., 2016. Direct feedback alignment provides learning in deep neural networks, in: Advances in Neural Information Processing Systems (NeurIPS)
2016
-
[30]
The predictive forward-forward algorithm
Ororbia, A., Mali, A.A., 2023. The predictive forward-forward algorithm. arXiv preprint arXiv:2301.01452
-
[31]
Contrastive signal–dependent plasticity: Self-supervised learning in spiking neural circuits
Ororbia, A.G., 2024. Contrastive signal–dependent plasticity: Self-supervised learning in spiking neural circuits. Science Advances 10, eadn6076
2024
-
[32]
Backpropagation-free deep learning with recursive local representation alignment, in: Proceedings of the AAAI Conference on Artificial Intelligence, pp
Ororbia, A.G., Mali, A., Kifer, D., Giles, C.L., 2023. Backpropagation-free deep learning with recursive local representation alignment, in: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 9327–9335
2023
-
[33]
Convolutionalchannel-wisecompetitivelearningfortheforward- forward algorithm, in: AAAI Conference on Artificial Intelligence
Papachristodoulou,A.,Kyrkou,C.,Timotheou,S.,Theocharides,T.,2023. Convolutionalchannel-wisecompetitivelearningfortheforward- forward algorithm, in: AAAI Conference on Artificial Intelligence
2023
-
[34]
Sedona: Search for decoupled neural networks toward greedy block-wise learning, in: International Conference on Learning Representations (ICLR)
Pyeon, M., Moon, J., Hahn, T., Kim, G., 2021. Sedona: Search for decoupled neural networks toward greedy block-wise learning, in: International Conference on Learning Representations (ICLR)
2021
-
[35]
Learning representations by back-propagating errors
Rumelhart, D.E., Hinton, G.E., Williams, R.J., 1986. Learning representations by back-propagating errors. Nature 323, 533–536
1986
-
[36]
Hpff:Hierarchicallocallysupervisedlearningwithpatchfeaturefusion
Su,J.,He,C.,Zhu,F.,Xu,X.,Guan,D.,Si,C.,2024. Hpff:Hierarchicallocallysupervisedlearningwithpatchfeaturefusion. arXivpreprint arXiv:2407.05638
-
[37]
Deeperforward: Enhanced forward-forward training for deeper and better performance, in: International Conference on Learning Representations (ICLR)
Sun, L., Zhang, Y., He, W., Wen, J., Shen, L., Xie, W., 2025. Deeperforward: Enhanced forward-forward training for deeper and better performance, in: International Conference on Learning Representations (ICLR)
2025
-
[38]
Terres-Escudero, E.B., Del Ser, J., Martínez-Seras, A., Garcia-Bringas, P., 2025. Forward-forward learning achieves highly selective latent representations for out-of-distribution detection in fully spiking neural networks. arXiv preprint arXiv:2407.14097
-
[39]
Emerging neohebbian dynamics in forward-forward learning: Implications for neuromorphic computing
Terres-Escudero, E.B., Ser, J.D., Garcia-Bringas, P., 2024. Emerging neohebbian dynamics in forward-forward learning: Implications for neuromorphic computing. arXiv preprint arXiv:2406.16479
-
[40]
Instance Normalization: The Missing Ingredient for Fast Stylization
Ulyanov, D., Vedaldi, A., Lempitsky, V.S., 2016. Instance normalization: The missing ingredient for fast stylization. arXiv preprint arXiv:1607.08022
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[41]
Attention is all you need, in: Advances in Neural Information Processing Systems (NeurIPS)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I., 2017. Attention is all you need, in: Advances in Neural Information Processing Systems (NeurIPS)
2017
-
[42]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Xiao, H., Rasul, K., Vollgraf, R., 2017. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. ArXiv abs/1708.07747. URL:https://api.semanticscholar.org/CorpusID:702279
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Advancing the forward-forward algorithm towards high-performance deep local learning
Xu, S., Wu, Y., Wu, J., Deng, L., Xu, M., Wen, Q., Li, G., 2026. Advancing the forward-forward algorithm towards high-performance deep local learning. Neural Networks 200, 108765. doi:10.1016/j.neunet.2026.108765
-
[44]
A theory for the sparsity emerged in the forward forward algorithm
Yang, Y., 2023. A theory for the sparsity emerged in the forward forward algorithm. arXiv preprint arXiv:2311.05667
-
[45]
Thecascadedforwardalgorithmforneuralnetworktraining
Zhao,G.,Wang,T.,Jin,Y.,Lang,C.,Li,Y.,Ling,H.,2025. Thecascadedforwardalgorithmforneuralnetworktraining. PatternRecognition 161, 111292
2025
-
[46]
Understanding why vit trains badly on small datasets: An intuitive perspective
Zhu, H., Chen, B., Yang, C., 2023. Understanding why vit trains badly on small datasets: An intuitive perspective. arXiv preprint arXiv:2302.03751
-
[47]
Deep companion learning: Enhancing generalization through historical consistency, in: European Conference on Computer Vision (ECCV)
Zhu, R., Saligrama, V., 2024. Deep companion learning: Enhancing generalization through historical consistency, in: European Conference on Computer Vision (ECCV). M. Ghader et al.:Preprint submitted to ElsevierPage 15 of 15
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.