Efficient-WAM: A 1B-Parameter World-Action Model with Low-Cost Future Imagination
Pith reviewed 2026-06-27 16:02 UTC · model grok-4.3
The pith
Efficient-WAM shows a 1B-parameter world-action model can reach 100 ms latency and 30x speedup by treating coarse video predictions as action guidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
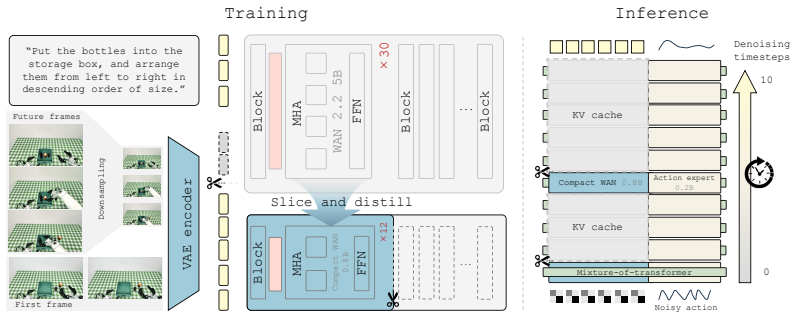
Efficient-WAM reduces the cost of future imagination while preserving its control benefit. It improves inference efficiency via a compact video expert transferred from WAN-2.2-5B, token-sparse video latents, and asymmetric video-action denoising that allocates fewer sampling steps to video than to actions. Instead of optimizing the future branch for visual fidelity, Efficient-WAM treats future video prediction as a compact guidance signal for action generation. Comprehensive experiments on RoboTwin 2.0 and real-world manipulation tasks show that Efficient-WAM maintains strong action performance despite visibly coarse future predictions. While maintaining competitive control capabilities, the
What carries the argument
Asymmetric video-action denoising that allocates fewer sampling steps to video than to actions, combined with token-sparse latents and a compact transferred video expert, to produce low-cost future predictions used only as guidance for actions.
If this is right
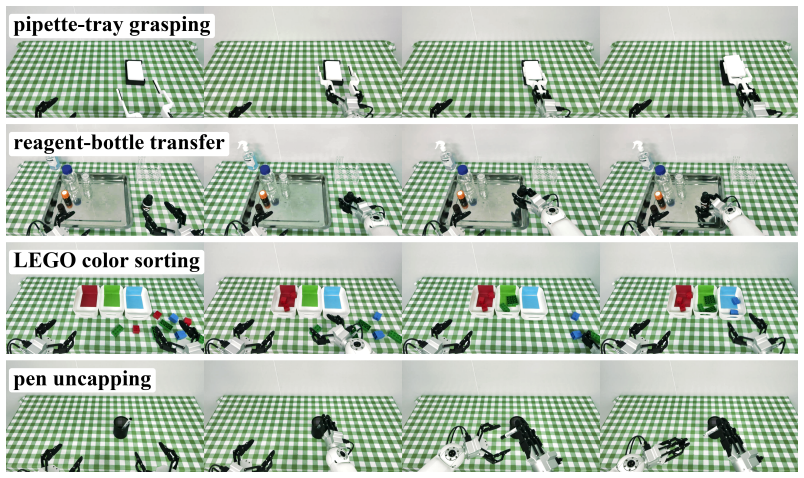
- The model sustains competitive control performance on RoboTwin 2.0 simulation and real manipulation tasks.
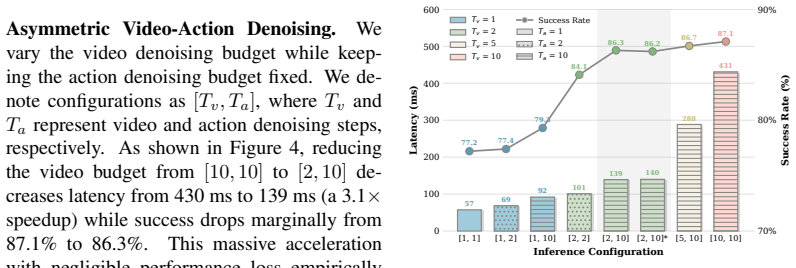
- Per-chunk latency drops to around 100 ms in physical robot deployment.
- Inference achieves a 30x speedup relative to existing world-action models.
- Visible coarseness in predicted futures does not prevent retention of control capability.
Where Pith is reading between the lines
- The guidance-signal treatment of video prediction may extend to other sensor streams where utility for control matters more than reconstruction quality.
- Further reductions in video fidelity could enable still smaller models or higher control frequencies on the same hardware.
- Testing on tasks with greater dynamics or longer horizons would check whether the coarse-prediction assumption continues to hold.
Load-bearing premise
Coarse low-fidelity future video predictions remain sufficient to preserve control benefits on the tested tasks.
What would settle it
Ablating or further degrading the video prediction branch on the real-world manipulation tasks and measuring whether action success rates fall below those of non-WAM baselines.
Figures




read the original abstract
World-Action Models (WAMs) have emerged as a promising paradigm for embodied control by coupling future visual prediction with action generation. However, most existing WAMs rely on photorealistic future prediction, which incurs high inference latency and makes real-time robot deployment difficult. This motivates a more efficient WAM design that preserves the control benefits of future visual prediction while reducing its inference cost. We introduce Efficient-WAM, a World-Action Model that reduces the cost of future imagination while preserving its control benefit. Efficient-WAM improves inference efficiency via a compact video expert transferred from WAN-2.2-5B, token-sparse video latents, and asymmetric video-action denoising that allocates fewer sampling steps to video than to actions. Instead of optimizing the future branch for visual fidelity, Efficient-WAM treats future video prediction as a compact guidance signal for action generation. Comprehensive experiments on RoboTwin 2.0 and real-world manipulation tasks show that Efficient-WAM maintains strong action performance despite visibly coarse future predictions. While maintaining competitive control capabilities, our 1B-parameter model can reduce per-chunk latency to around 100 ms during physical deployment, achieving a 30x speedup over existing WAMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Efficient-WAM, a 1B-parameter World-Action Model for embodied robot control. It reduces inference cost of future visual prediction via a compact expert transferred from WAN-2.2-5B, token-sparse video latents, and asymmetric denoising (fewer steps for video than actions), treating predictions as compact guidance signals rather than high-fidelity outputs. Experiments on RoboTwin 2.0 and real-world manipulation tasks are claimed to show maintained competitive control performance despite visibly coarse predictions, with per-chunk latency reduced to ~100 ms (30x speedup over prior WAMs).
Significance. If the empirical claims hold with proper validation, the result would be significant for robotics: it directly addresses the deployment barrier of high-latency WAMs by showing that low-fidelity future prediction can still deliver control benefits at real-time speeds. The approach of asymmetric compute allocation and guidance-only video modeling is a practical contribution to efficient embodied models.
major comments (2)
- [Abstract / Experiments] Abstract and experimental results section: the claim that 'experiments on RoboTwin 2.0 and real-world manipulation tasks show that Efficient-WAM maintains strong action performance despite visibly coarse future predictions' is unsupported by any reported baselines, metrics (e.g., success rate, trajectory error), statistical significance, error bars, or number of trials. This renders the central efficiency claim (30x speedup while preserving control) unverifiable from the provided information.
- [Experiments] Experiments / ablation studies: no ablations are described that disable the video prediction branch or replace it with null/constant input to test whether the coarse future predictions contribute measurable guidance signal to action generation versus the action-denoising pathway alone. Given the design choice to deliberately de-emphasize visual fidelity (compact expert, token-sparse latents, fewer denoising steps), this test is load-bearing for the claim that control benefits of future visual prediction are preserved.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important gaps in experimental reporting that we will address in revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental results section: the claim that 'experiments on RoboTwin 2.0 and real-world manipulation tasks show that Efficient-WAM maintains strong action performance despite visibly coarse future predictions' is unsupported by any reported baselines, metrics (e.g., success rate, trajectory error), statistical significance, error bars, or number of trials. This renders the central efficiency claim (30x speedup while preserving control) unverifiable from the provided information.
Authors: We agree that the current manuscript version does not report explicit numerical metrics, baselines, success rates, trajectory errors, trial counts, or statistical details to support the performance claim. The abstract and experiments section rely on qualitative statements and the latency figure without accompanying quantitative tables. To make the central claim verifiable, we will add a results table in the revised manuscript that includes success rates on RoboTwin 2.0, real-world task success percentages, trajectory error metrics, number of trials, error bars, and direct comparisons to prior WAM baselines. This will directly substantiate the statement that competitive control performance is maintained at ~100 ms latency. revision: yes
-
Referee: [Experiments] Experiments / ablation studies: no ablations are described that disable the video prediction branch or replace it with null/constant input to test whether the coarse future predictions contribute measurable guidance signal to action generation versus the action-denoising pathway alone. Given the design choice to deliberately de-emphasize visual fidelity (compact expert, token-sparse latents, fewer denoising steps), this test is load-bearing for the claim that control benefits of future visual prediction are preserved.
Authors: We acknowledge that the manuscript does not contain an ablation that isolates the video prediction branch (e.g., by disabling it or replacing predictions with constant/null input). Such an experiment would directly test whether the coarse video guidance provides measurable benefit beyond the action-denoising pathway alone. We will add this ablation study to the revised experiments section, reporting action performance with and without the video branch on the same tasks to quantify its contribution. revision: yes
Circularity Check
No significant circularity; empirical claims rest on experiments, not self-referential derivations
full rationale
The paper introduces Efficient-WAM via architectural choices (compact expert from WAN-2.2-5B, token-sparse latents, asymmetric denoising) and reports empirical results on latency (~100 ms, 30x speedup) and control performance on RoboTwin 2.0 and real tasks. No equations, first-principles derivations, or 'predictions' are presented that reduce by construction to fitted parameters or prior outputs. The central claim that coarse video predictions preserve control benefits is supported by direct experimental comparison rather than any self-definitional or fitted-input mechanism. No load-bearing self-citations or uniqueness theorems appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Future visual prediction provides control benefits in embodied tasks even when predictions are coarse
Reference graph
Works this paper leans on
-
[1]
S. Wang, J. Shi, Z. Fu, X. He, F. Liu, C. Yang, Y . Zhou, Z. Fei, J. Gong, J. Fu, M. Z. Shou, X. Huang, X. Qiu, and Y .-G. Jiang. World action models: The next frontier in embodied ai. arXiv preprint arXiv:2605.12090, 2026
Pith/arXiv arXiv 2026
-
[2]
B. Hou, G. Li, J. Jia, T. An, X. Guo, S. Leng, H. Geng, Y . Ze, T. Harada, P. Torr, O. Mees, M. Pollefeys, Z. Liu, J. Wu, P. Abbeel, J. Malik, Y . Du, and J. Yang. World model for robot learning: A comprehensive survey.arXiv preprint arXiv:2605.00080, 2026
Pith/arXiv arXiv 2026
-
[3]
Finn and S
C. Finn and S. Levine. Deep visual foresight for planning robot motion. InProceedings of the IEEE International Conference on Robotics and Automation, 2017
2017
-
[4]
Y . Hu, Y . Guo, P. Wang, X. Chen, Y .-J. Wang, J. Zhang, K. Sreenath, C. Lu, and J. Chen. Video prediction policy: A generalist robot policy with predictive visual representations. In Proceedings of the International Conference on Machine Learning, 2025
2025
-
[5]
H. Wu, Y . Jing, C. Cheang, G. Chen, J. Xu, X. Li, M. Liu, H. Li, and T. Kong. Unleashing large-scale video generative pre-training for visual robot manipulation. InProceedings of the International Conference on Learning Representations, 2024
2024
-
[6]
Y . Du, M. Yang, B. Dai, H. Dai, O. Nachum, J. B. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation. InAdvances in Neural Informa- tion Processing Systems, 2023
2023
-
[7]
S. Li, Y . Gao, D. Sadigh, and S. Song. Unified video action model. InProceedings of Robotics: Science and Systems, 2025
2025
-
[8]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, and J. Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning. arXiv preprint arXiv:2601.16163, 2026
Pith/arXiv arXiv 2026
-
[9]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
Pith/arXiv arXiv 2026
-
[10]
T. Yuan, Z. Dong, Y . Liu, and H. Zhao. Fast-W AM: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
Pith/arXiv arXiv 2026
-
[11]
H. Bi, H. Tan, S. Xie, Z. Wang, S. Huang, H. Liu, R. Zhao, Y . Feng, C. Xiang, Y . Rong, H. Zhao, H. Liu, Z. Su, L. Ma, H. Su, and J. Zhu. Motus: A unified latent action world model. arXiv preprint arXiv:2512.13030, 2025
Pith/arXiv arXiv 2025
-
[12]
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, Y . Shen, and Y . Xu. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
Pith/arXiv arXiv 2026
-
[13]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Wan Team. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[14]
Y . Yue, Y . Wang, B. Kang, Y . Han, S. Wang, S. Song, J. Feng, and G. Huang. DeeR-VLA: Dynamic inference of multimodal large language models for efficient robot execution. In Advances in Neural Information Processing Systems, volume 37, 2024
2024
-
[15]
Z. Yang, Y . Qi, T. Xie, B. Yu, S. Liu, and M. Li. DySL-VLA: Efficient vision-language-action model inference via dynamic-static layer-skipping for robot manipulation.arXiv preprint arXiv:2602.22896, 2026. 9
arXiv 2026
-
[16]
Y . Song, P. Dhariwal, M. Chen, and I. Sutskever. Consistency models. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 32211–32252, 2023
2023
- [17]
-
[18]
Z. Wang, Z. Li, A. Mandlekar, Z. Xu, J. Fan, Y . Narang, L. Fan, Y . Zhu, Y . Balaji, M. Zhou, M.-Y . Liu, and Y . Zeng. One-step diffusion policy: Fast visuomotor policies via diffusion dis- tillation. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 59770–59791, 2025
2025
-
[19]
C. Zhu, R. Yu, S. Feng, B. Burchfiel, P. Shah, and A. Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets. InProceedings of Robotics: Science and Systems, 2025. arXiv:2504.02792
Pith/arXiv arXiv 2025
-
[20]
H. Luo, W. Zhang, Y . Feng, S. Zheng, H. Xu, C. Xu, Z. Xi, Y . Fu, and Z. Lu. Being-H0.7: A latent World-Action model from egocentric videos.arXiv preprint arXiv:2605.00078, 2026
Pith/arXiv arXiv 2026
-
[21]
A. Ye, B. Wang, C. Ni, G. Huang, G. Zhao, H. Li, H. Li, J. Li, J. Lv, J. Liu, M. Cao, P. Li, Q. Deng, W. Mei, X. Wang, X. Chen, X. Zhou, Y . Wang, Y . Chang, Y . Li, Y . Zhou, Y . Ye, Z. Liu, and Z. Zhu. GigaWorld-Policy: An efficient action-centered world–action model.arXiv preprint arXiv:2603.17240, 2026
arXiv 2026
-
[22]
J. Guo, Q. Li, P. Li, Z. Chen, N. Sun, Y . Su, H. Wang, Y . Zhang, X. Li, and H. Liu. Unified 4D world action modeling from video priors with asynchronous denoising.arXiv preprint arXiv:2604.26694, 2026
Pith/arXiv arXiv 2026
-
[23]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. InProceedings of the 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learni...
2025
-
[24]
Y . Ye, J. Ma, J. Cen, and Z. Lu. Token expand-merge: Training-free token compression for vision-language-action models.arXiv preprint arXiv:2512.09927, 2025
arXiv 2025
-
[25]
W. Guan, Q. Hu, A. Li, and J. Cheng. Efficient vision-language-action models for embodied manipulation: A systematic survey.arXiv preprint arXiv:2510.17111, 2025
Pith/arXiv arXiv 2025
-
[26]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InProceedings of Robotics: Science and Systems, 2023. arXiv:2303.04137
Pith/arXiv arXiv 2023
-
[27]
G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
Pith/arXiv arXiv 2015
-
[28]
X. Jiao, Y . Yin, L. Shang, X. Jiang, X. Chen, L. Li, F. Wang, and Q. Liu. TinyBERT: Distilling BERT for natural language understanding. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 4163–4174, 2020
2020
-
[29]
A. Fan, E. Grave, and A. Joulin. Reducing transformer depth on demand with structured dropout. InProceedings of the International Conference on Learning Representations, 2020
2020
-
[30]
Molchanov, S
P. Molchanov, S. Tyree, T. Karras, T. Aila, and J. Kautz. Pruning convolutional neural networks for resource efficient inference. InProceedings of the International Conference on Learning Representations, 2017. 10
2017
-
[31]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InProceedings of the International Conference on Learning Representations, 2023
2023
-
[32]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InProceedings of the International Conference on Learning Representations, 2023
2023
-
[33]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InProceedings of Robotics: Science and Systems, 2023
2023
-
[34]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, W. Deng, Y . Guo, T. Nian, X. Xie, Q. Chen, K. Su, T. Xu, G. Liu, M. Hu, H.-a. Gao, K. Wang, Z. Liang, Y . Qin, X. Yang, P. Luo, and Y . Mu. RoboTwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXi...
Pith/arXiv arXiv 2025
-
[35]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control. InProceedings of Robotics...
2025
-
[36]
J. Ye, N. Gao, S. Yang, J. Zheng, Z. Wang, Y . Chen, P. Chen, Y . Chen, S. Liu, and J. Jia. StarVLA-α: Reducing complexity in vision-language-action systems.arXiv preprint arXiv:2604.11757, 2026
Pith/arXiv arXiv 2026
-
[37]
Black, N
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner...
2025
-
[38]
Y . Yang, S. Zeng, T. Lin, X. Chang, D. Qi, J. Xiao, H. Liu, R. Chen, Y . Chen, D. Huo, F. Xiong, X. Wei, Z. Ma, and M. Xu. ABot-M0: VLA foundation model for robotic manipulation with action manifold learning.arXiv preprint arXiv:2602.11236, 2026
Pith/arXiv arXiv 2026
-
[39]
W. Wu, F. Lu, Y . Wang, S. Yang, S. Liu, F. Wang, Q. Zhu, H. Sun, Y . Wang, S. Ma, Y . Ren, K. Zhang, H. Yu, J. Zhao, S. Zhou, Z. Qiu, H. Xiong, Z. Wang, Z. Wang, R. Cheng, Y .-L. Li, Y . Huang, X. Zhu, Y . Shen, and K. Zheng. A pragmatic VLA foundation model.arXiv preprint arXiv:2601.18692, 2026
Pith/arXiv arXiv 2026
-
[40]
Q. Sun, X. Chi, Y . Rui, Y . Li, K. Ge, J. Li, S. Han, and S. Zhang. Labshield: A multimodal benchmark for safety-critical reasoning and planning in scientific laboratories.arXiv preprint arXiv:2603.11987, 2026. 11 Appendix A Training Details Table 4: Training stages and main optimization settings. Stage Trainable Batch Size LR Video Loss Wt. Action Loss ...
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.