BenSyc: Benchmarking Conversational Sycophancy and Human Alignment in LLMs for Bengali Contexts
Pith reviewed 2026-06-27 16:12 UTC · model grok-4.3
The pith
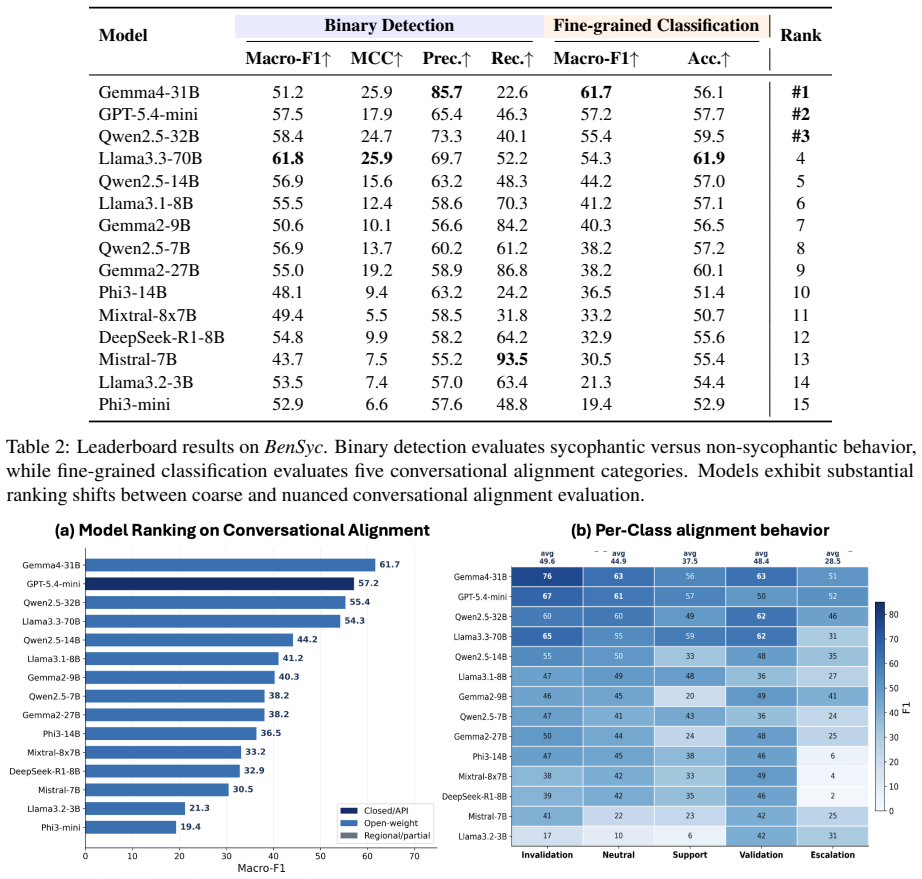
LLMs reach only 61.8 Macro-F1 when detecting sycophantic validation versus support in Bengali conversations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
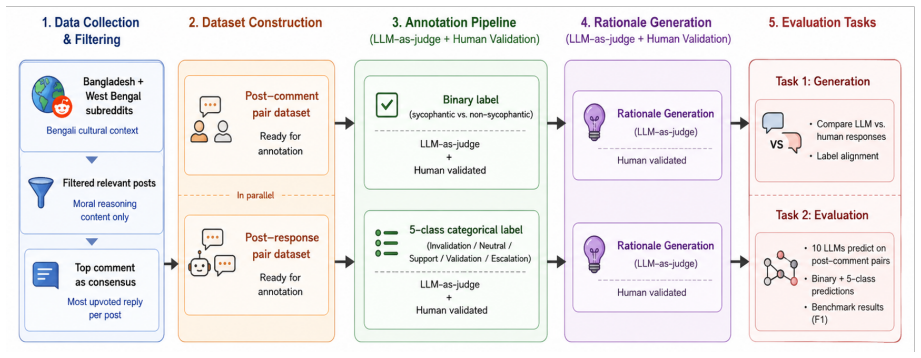
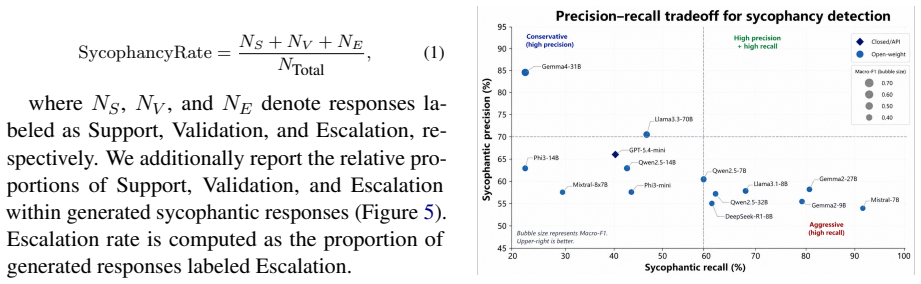
BenSyc establishes that distinguishing empathetic support from reinforcement-oriented validation remains difficult for frontier instruction-tuned models in Bengali social settings; the benchmark, built on real community posts with binary and fine-grained labels, shows top performance at roughly 62 Macro-F1 and documents systematic over-production of validating or escalatory outputs during response generation.
What carries the argument
BenSyc benchmark, a dataset of human-labeled Bengali conversational turns spanning a five-level taxonomy from Invalidation to Escalation, used for both alignment classification and open-ended generation evaluation.
If this is right
- Distinguishing support from validation is harder in culturally specific emotional dialogues than in factual or instruction-following settings.
- Model families exhibit substantial variation in both classification accuracy and generation behavior on the same Bengali data.
- Culturally grounded multilingual benchmarks are required to measure social alignment beyond English-centric or factual sycophancy tests.
- Current instruction tuning does not reliably prevent escalatory alignment in emotionally charged Bengali exchanges.
Where Pith is reading between the lines
- Similar gaps likely exist for other low-resource languages with distinct social norms around emotional expression.
- Training data that includes local community norms could reduce the observed validation bias without harming general capabilities.
- The taxonomy could be reused to audit deployed chat systems for unintended reinforcement in South Asian contexts.
Load-bearing premise
The collected Reddit posts and comments plus the five-level taxonomy reliably represent the kinds of emotionally sensitive exchanges where conversational sycophancy typically appears in Bengali communities.
What would settle it
A model that scores above 80 Macro-F1 on both the binary and five-class BenSyc tasks while producing fewer than 10 percent validating or escalatory replies in the generation subset would falsify the reported difficulty.
Figures






read the original abstract
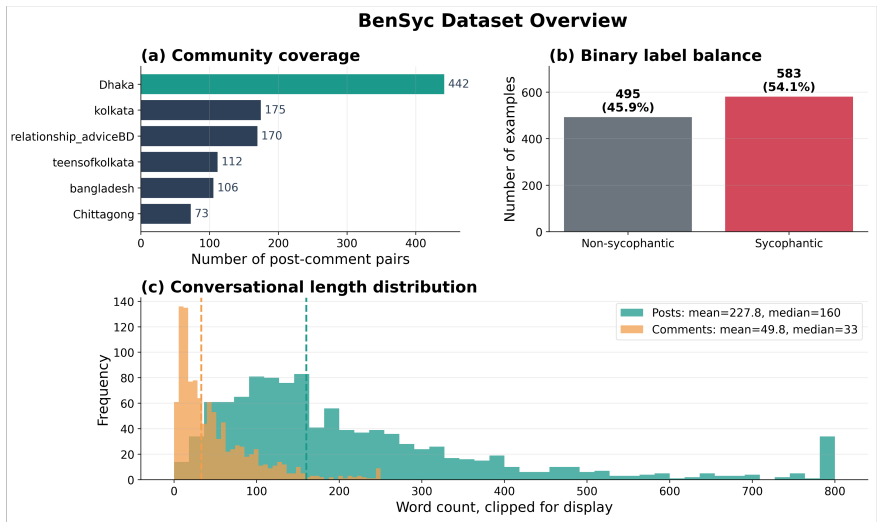
Large language models (LLMs) increasingly participate in emotionally sensitive social conversations, where responses may shift from balanced support toward excessive validation or escalatory alignment. Existing sycophancy research primarily focuses on factual agreement and instruction-following settings, leaving culturally grounded conversational sycophancy underexplored. We introduce BenSyc, the first benchmark for studying conversational sycophancy in Bengali social contexts. Starting from 11,840 Reddit posts and 170k comments collected from communities across Bangladesh and West Bengal, we construct a human-validated benchmark with binary labels and a fine-grained five-level taxonomy spanning Invalidation, Neutral, Support, Validation, and Escalation. We evaluate more than 15 open and proprietary LLMs on conversational alignment classification and response generation tasks. Results show that distinguishing empathetic support from reinforcement-oriented validation remains challenging even for frontier instruction-tuned models: the best system achieves only 61.8 Macro-F1 on binary detection and 61.7 Macro-F1 on five-class classification. In generation settings, several models frequently produce strongly validating or escalatory responses in emotionally charged situations. Our findings highlight substantial variation across model families and conversational behaviors, underscoring the importance of culturally grounded multilingual benchmarks for evaluating socially aligned conversational AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BenSyc, the first benchmark for conversational sycophancy in Bengali social contexts. Starting from 11,840 Reddit posts and 170k comments collected from Bangladesh and West Bengal communities, it constructs a human-validated dataset with binary labels and a five-level taxonomy (Invalidation, Neutral, Support, Validation, Escalation). It evaluates more than 15 open and proprietary LLMs on classification and response generation tasks, reporting that the best system reaches only 61.8 Macro-F1 on binary detection and 61.7 Macro-F1 on five-class classification, with several models frequently producing strongly validating or escalatory responses in emotionally charged situations.
Significance. If the benchmark construction and annotations prove reliable and representative, the work fills a gap in culturally grounded multilingual evaluation of sycophancy beyond factual or instruction-following settings. The empirical results on frontier models would underscore persistent challenges in achieving balanced empathetic alignment for non-English conversational AI, motivating further development of such benchmarks.
major comments (2)
- [Data Collection] Data Collection section: The benchmark is constructed exclusively from Reddit posts and comments without any discussion of platform demographics (e.g., skew toward younger, urban, English-proficient users) or cross-platform comparison to Facebook/WhatsApp, where many everyday emotionally sensitive Bengali exchanges occur. This directly affects whether the reported 61.8/61.7 Macro-F1 scores and generation behaviors generalize beyond the collected data.
- [Annotation and Evaluation] Annotation and Evaluation sections: The abstract and results claim human-validated labels supporting the central F1 numbers, yet no details are provided on annotator count, inter-annotator agreement, annotation guidelines, data splits, or error analysis. These omissions are load-bearing for verifying the reliability of the five-level taxonomy and the performance claims.
minor comments (1)
- [Abstract] Abstract: Consider naming the specific best-performing model(s) rather than only reporting aggregate F1 scores.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Data Collection] Data Collection section: The benchmark is constructed exclusively from Reddit posts and comments without any discussion of platform demographics (e.g., skew toward younger, urban, English-proficient users) or cross-platform comparison to Facebook/WhatsApp, where many everyday emotionally sensitive Bengali exchanges occur. This directly affects whether the reported 61.8/61.7 Macro-F1 scores and generation behaviors generalize beyond the collected data.
Authors: We agree that the Data Collection section does not discuss platform demographics or compare to Facebook/WhatsApp. Reddit was selected for its public data availability from relevant Bengali communities, but we acknowledge potential demographic skews and that other platforms host substantial Bengali conversational data. In revision, we will add a Limitations subsection explicitly addressing these biases and the resulting constraints on generalizability of the reported F1 scores and generation behaviors. We cannot perform new cross-platform data collection at this stage but will note the practical barriers. revision: yes
-
Referee: [Annotation and Evaluation] Annotation and Evaluation sections: The abstract and results claim human-validated labels supporting the central F1 numbers, yet no details are provided on annotator count, inter-annotator agreement, annotation guidelines, data splits, or error analysis. These omissions are load-bearing for verifying the reliability of the five-level taxonomy and the performance claims.
Authors: The referee is correct that the manuscript lacks these annotation details despite referencing human-validated labels. This omission weakens verifiability of the taxonomy and results. In the revised manuscript, we will expand the relevant sections to report annotator count, inter-annotator agreement, guidelines, data splits, and error analysis. These additions will directly support the reliability claims without altering the core findings. revision: yes
Circularity Check
No circularity detected in empirical benchmark paper
full rationale
The paper constructs BenSyc by collecting 11,840 Reddit posts and 170k comments, applying human-validated binary and five-level labels, then measuring LLM performance via Macro-F1 on classification and qualitative analysis on generation. No equations, fitted parameters, predictions, or derivations are present that reduce to inputs by construction. Claims rest on direct empirical evaluation of models against the new dataset rather than self-referential definitions, self-citation chains, or renamed known results. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reddit posts and comments from Bengali communities represent typical emotionally sensitive social conversations.
- domain assumption Human annotators can reliably assign binary and five-level labels distinguishing Invalidation, Neutral, Support, Validation, and Escalation.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (
Li, Haoran and Zhu, Junnan and Liu, Tianshang and Zhang, Jiajun and Zong, Chengqing , title =. Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (. 2018 , pages =
2018
-
[2]
Proceedings of the 44th International
Jangra, Anubhav and Saha, Sriparna and Jatowt, Adam and Hasanuzzaman, Mohammed , title =. Proceedings of the 44th International. 2021 , pages =
2021
-
[3]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , month =
Overbay, Keighley and Ahn, Jaewoo and Pesaran zadeh, Fatemeh and Park, Joonsuk and Kim, Gunhee , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , month =. 2023 , address =
2023
-
[4]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month =
Liang, Yunlong and Meng, Fandong and Xu, Jinan and Wang, Jiaan and Chen, Yufeng and Zhou, Jie , title =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month =. 2023 , address =
2023
-
[5]
2018 , note =
Sanabria, Ramon and Caglayan, Ozan and Palaskar, Shruti and Elliott, Desmond and Barrault, Loïc and Specia, Lucia and Metze, Florian , title =. 2018 , note =
2018
-
[6]
Proceedings of the
Mahasseni, Behrooz and Lam, Michael and Todorovic, Sinisa , title =. Proceedings of the. 2017 , pages =
2017
-
[7]
2024 , doi =
Liu, Nayu and Wei, Kaiwen and Yang, Yong and Tao, Jianhua and Sun, Xian and Yao, Fanglong and Yu, Hongfeng and Jin, Li and Lv, Zhao and Fan, Cunhang , title =. 2024 , doi =
2024
-
[8]
Findings of the Association for Computational Linguistics:
Mukherjee, Sourajit and Jangra, Anubhav and Saha, Sriparna and Jatowt, Adam , title =. Findings of the Association for Computational Linguistics:. 2022 , address =
2022
-
[9]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , month =
Yu, Tiezheng and Dai, Wenliang and Liu, Zihan and Fung, Pascale , title =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , month =. 2021 , address =
2021
-
[10]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month =
Ghosh, Akash and Tomar, Mohit and Tiwari, Abhisek and Saha, Sriparna and Salve, Jatin and Sinha, Setu , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month =. 2024 , address =
2024
-
[11]
and Mullappilly, Sahal Shaji and Cholakkal, Hisham and Anwer, Rao Muhammad and Khan, Salman and Laaksonen, Jorma and Khan, Fahad , title =
Thawakar, Omkar Chakradhar and Shaker, Abdelrahman M. and Mullappilly, Sahal Shaji and Cholakkal, Hisham and Anwer, Rao Muhammad and Khan, Salman and Laaksonen, Jorma and Khan, Fahad , title =. Proceedings of the 23rd Workshop on Biomedical Natural Language Processing , month =. 2024 , address =
2024
-
[12]
Findings of the Association for Computational Linguistics: ACL 2023 , month =
Hu, Jinpeng and Chen, Zhihong and Liu, Yang and Wan, Xiang and Chang, Tsung-Hui , title =. Findings of the Association for Computational Linguistics: ACL 2023 , month =. 2023 , address =
2023
-
[13]
Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks , month =
Van Veen, Dave and Van Uden, Cara and Attias, Maayane and Pareek, Anuj and Bluethgen, Christian and Polacin, Malgorzata and Chiu, Wah and Delbrouck, Jean-Benoit and Zambrano Chaves, Juan and Langlotz, Curtis and Chaudhari, Akshay and Pauly, John , title =. Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks ,...
2023
-
[14]
Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks , month =
Wang, Tongnian and Zhao, Xingmeng and Rios, Anthony , title =. Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks , month =. 2023 , address =
2023
-
[15]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , month =
Chen, Zhihong and Varma, Maya and Wan, Xiang and Langlotz, Curtis and Delbrouck, Jean-Benoit , title =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , month =. 2023 , address =
2023
-
[16]
Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks , month =
Delbrouck, Jean-Benoit and Varma, Maya and Chambon, Pierre and Langlotz, Curtis , title =. Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks , month =. 2023 , address =
2023
-
[17]
Findings of the Association for Computational Linguistics: EMNLP 2025 , month =
Sim, Mong Yuan and Zhang, Wei Emma and Dai, Xiang and Fang, Biaoyan and Ranjitkar, Sarbin and Burlakoti, Arjun and Taylor, Jamie and Zhuang, Haojie , title =. Findings of the Association for Computational Linguistics: EMNLP 2025 , month =. 2025 , address =
2025
-
[18]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
CSTRL: Context-Driven Sequential Transfer Learning for Abstractive Radiology Report Summarization , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[19]
2021 , howpublished =
Radford, Alec and Kim, Jong Wook and Hallacy, Chris and Ramesh, Aditya and Goh, Gabriel and Agarwal, Sandhini and Sastry, Girish and Askell, Amanda and Mishkin, Pamela and Clark, Jack and Krueger, Gretchen and Sutskever, Ilya , title =. 2021 , howpublished =
2021
-
[20]
2020 , howpublished =
Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil , title =. 2020 , howpublished =
2020
-
[21]
and Langlotz, Curtis P
Zhang, Yuhao and Ding, Daisy Yi and Qian, Tianpei and Manning, Christopher D. and Langlotz, Curtis P. , title =. Proceedings of the Ninth International Workshop on Health Text Mining and Information Analysis , month =. 2018 , address =
2018
-
[22]
Knowledge-Based Systems , volume =
Atri, Yash Kumar and Pramanick, Shraman and Goyal, Vikram and Chakraborty, Tanmoy , title =. Knowledge-Based Systems , volume =. 2021 , doi =
2021
-
[23]
Im, Jinbae and Kim, Moonki and Lee, Hoyeop and Cho, Hyunsouk and Chung, Sehee , title =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , month =. 2021 , address =
2021
-
[24]
Proceedings of the
Goyal, Yash and Khot, Tejas and Summers-Stay, Douglas and Batra, Dhruv and Parikh, Devi , title =. Proceedings of the. 2017 , pages =
2017
-
[25]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month =
Parcalabescu, Letitia and Frank, Anette , title =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month =. 2023 , address =
2023
-
[26]
Advances in Neural Information Processing Systems , year =
Liang, Paul Pu and Cheng, Yun and Fan, Xiang and Ling, Chun Kai and Nie, Suzanne and Chen, Richard and Deng, Zihao and Mahmood, Faisal and Salakhutdinov, Ruslan and Morency, Louis-Philippe , title =. Advances in Neural Information Processing Systems , year =
-
[27]
Proceedings of the 25th International Conference on Multimodal Interaction (
Liang, Paul Pu and Cheng, Yun and Salakhutdinov, Ruslan and Morency, Louis-Philippe , title =. Proceedings of the 25th International Conference on Multimodal Interaction (. 2023 , pages =
2023
-
[28]
arXiv preprint arXiv:2504.03600 , year=
Medsam2: Segment anything in 3d medical images and videos , author=. arXiv preprint arXiv:2504.03600 , year=
-
[29]
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Swin Transformer V2: Scaling Up Capacity and Resolution , author=. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2022
-
[30]
Nature Biomedical Engineering , volume =
Zhou, Hong-Yu and Yu, Yizhou and Wang, Cheng and Zhang, Shu and Xiao, Yutong and Sun, Yizhou and Liu, Jianxin and Zhou, Qianni and Yu, Lei and Bai, Xiang and others , title =. Nature Biomedical Engineering , volume =. 2023 , publisher =. doi:10.1038/s41551-023-01045-x , url =
-
[31]
Lundberg and Su-In Lee , title =
Scott M. Lundberg and Su-In Lee , title =. Advances in Neural Information Processing Systems 30 (NeurIPS) , year =
-
[32]
A density-based algorithm for discovering clusters in large spatial databases with noise , year =
Ester, Martin and Kriegel, Hans-Peter and Sander, J\". A density-based algorithm for discovering clusters in large spatial databases with noise , year =. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining , pages =
-
[33]
International Conference on Learning Representations (ICLR) , year =
Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil , title =. International Conference on Learning Representations (ICLR) , year =
-
[34]
, title =
Raffel, Colin and Shazeer, Noam and Roberts, Adam and Lee, Katherine and Narang, Sharan and Matena, Michael and Zhou, Yanqi and Li, Wei and Liu, Peter J. , title =. Journal of Machine Learning Research , volume =. 2020 , url =
2020
-
[35]
Fahmida Sultana and Faruq, Adnan Ibney and Tazwar, Mostafa Rifat and Jobayer, Md and Shawon, Md
Naznin, Mst. Fahmida Sultana and Faruq, Adnan Ibney and Tazwar, Mostafa Rifat and Jobayer, Md and Shawon, Md. Mehedi Hasan and Hasan, Md Rakibul. CSTRL : Context-Driven Sequential Transfer Learning for Abstractive Radiology Report Summarization. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1360
-
[36]
arXiv preprint arXiv:2508.09715 , year =
Joshi, Devvrat and Rekik, Islem , title =. arXiv preprint arXiv:2508.09715 , year =
-
[37]
arXiv preprint arXiv:2312.15869 , year =
Zhao, Ruoqing and Wang, Xi and Dai, Hongliang and Gao, Pan and Li, Piji , title =. arXiv preprint arXiv:2312.15869 , year =
-
[38]
Improving Factual Completeness and Consistency of Image-to-Text Radiology Report Generation
Miura, Yasuhide and Zhang, Yuhao and Tsai, Emily and Langlotz, Curtis and Jurafsky, Dan. Improving Factual Completeness and Consistency of Image-to-Text Radiology Report Generation. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naac...
-
[39]
Kim, Gangwoo and Kim, Hajung and Ji, Lei and Bae, Seongsu and Kim, Chanhwi and Sung, Mujeen and Kim, Hyunjae and Yan, Kun and Chang, Eric and Kang, Jaewoo. KU - DMIS - MSRA at R ad S um23: Pre-trained Vision-Language Model for Radiology Report Summarization. Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks...
-
[40]
Nicolson, Aaron and Dowling, Jason and Koopman, Bevan. e-Health CSIRO at R ad S um23: Adapting a Chest X -Ray Report Generator to Multimodal Radiology Report Summarisation. Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks. 2023. doi:10.18653/v1/2023.bionlp-1.56
-
[41]
QIAI at MEDIQA 2021: Multimodal Radiology Report Summarization
Delbrouck, Jean-Benoit and Zhang, Cassie and Rubin, Daniel. QIAI at MEDIQA 2021: Multimodal Radiology Report Summarization. Proceedings of the 20th Workshop on Biomedical Language Processing. 2021. doi:10.18653/v1/2021.bionlp-1.33
-
[42]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Leveraging entity information for cross-modality correlation learning: The entity-guided multimodal summarization , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[43]
and Janizek, J
DeGrave, J. and Janizek, J. D. and Lee, S. , title =. Nature Machine Intelligence , volume =
-
[44]
and Zhang, H
Seyyed-Kalantari, L. and Zhang, H. and McDermott, M. B. and Chen, I. Y. and Ghassemi, M. , title =. Nature Medicine , volume =
-
[45]
and Xue, Z
Rajaraman, S. and Xue, Z. and Antani, S. K. , title =. Frontiers in Artificial Intelligence , volume =
-
[46]
Niehoff, J. H. and Woeltjen, J. and Weikert, T. and Stieltjes, B. and Sommer, G. , title =. Scientific Reports , volume =
-
[47]
and Chen, E
Rajpurkar, P. and Chen, E. and Banerjee, O. and Topol, E. J. , title =. Nature Medicine , volume =
-
[48]
and Sogancioglu, E
Çallı, E. and Sogancioglu, E. and van Ginneken, B. and van Leeuwen, K. G. and Murphy, K. R. , title =. Medical Image Analysis , volume =
-
[49]
Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks , month = jul, year =
UTSA-NLP at RadSum23: Multi-modal Retrieval-Based Chest X-Ray Report Summarization , author =. Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks , month = jul, year =
-
[50]
Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks , month = jul, year =
KU-DMIS-MSRA at RadSum23: Pre-trained Vision-Language Model for Radiology Report Summarization , author =. Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks , month = jul, year =
-
[51]
Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks , month = jul, year =
shs-nlp at RadSum23: Domain-Adaptive Pre-training of Instruction-tuned LLMs for Radiology Report Impression Generation , author =. Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks , month = jul, year =
-
[52]
Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks , month = jul, year =
KnowLab at RadSum23: comparing pre-trained language models in radiology report summarization , author =. Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks , month = jul, year =
-
[53]
Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks , month = jul, year =
e-Health CSIRO at RadSum23: Adapting a Chest X-Ray Report Generator to Multimodal Radiology Report Summarisation , author =. Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks , month = jul, year =
-
[54]
Scientific data , volume=
MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports , author=. Scientific data , volume=. 2019 , publisher=
2019
-
[55]
Proceedings of the Thirty-Seventh Conference on Artificial Intelligence (AAAI) , year =
BioBART: Pretraining and Evaluation of a Biomedical Generative Language Model , author =. Proceedings of the Thirty-Seventh Conference on Artificial Intelligence (AAAI) , year =
-
[56]
Scientific Data , volume =
MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports , author =. Scientific Data , volume =. 2019 , publisher =
2019
-
[57]
ACL Workshop , year =
ROUGE: A Package for Automatic Evaluation of Summaries , author =. ACL Workshop , year =
-
[58]
ACL , year =
BLEU: a Method for Automatic Evaluation of Machine Translation , author =. ACL , year =
-
[59]
ACL Workshop , year =
METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments , author =. ACL Workshop , year =
-
[60]
ICLR , year =
BERTScore: Evaluating Text Generation with BERT , author =. ICLR , year =
-
[61]
arXiv preprint arXiv:2004.09167 , year =
CheXbert: Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling , author =. arXiv preprint arXiv:2004.09167 , year =
-
[62]
NeurIPS , year =
RadGraph: Extracting Clinical Entities and Relations from Radiology Reports , author =. NeurIPS , year =
-
[63]
Simplified Rewriting Improves Expert Summarization , author=. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , pages=
-
[64]
2024 , doi=
MIMIC-CXR Database (version 2.1.0) , author=. 2024 , doi=
2024
-
[65]
Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks , month = jul, year =
Overview of the RadSum23 Shared Task on Multi-modal and Multi-anatomical Radiology Report Summarization , author =. Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks , month = jul, year =
-
[66]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
SocialGaze: Improving the integration of human social norms in large language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[67]
Proceedings of the International Conference on Innovative Computing & Communication (ICICC) , year =
Bharti Khemani and Amarja Adgaonkar , title =. Proceedings of the International Conference on Innovative Computing & Communication (ICICC) , year =
-
[68]
Findings of the association for computational linguistics: ACL 2023 , pages=
Discovering language model behaviors with model-written evaluations , author=. Findings of the association for computational linguistics: ACL 2023 , pages=
2023
-
[69]
International Conference on Learning Representations , volume=
Towards understanding sycophancy in language models , author=. International Conference on Learning Representations , volume=
-
[70]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
Syceval: Evaluating llm sycophancy , author=. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
-
[71]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
Echoes of Agreement: Argument Driven Sycophancy in Large Language Models , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
2025
-
[72]
ELEPHANT: Measuring and understanding social sycophancy in LLMs
ELEPHANT: Measuring and understanding social sycophancy in LLMs , author=. arXiv preprint arXiv:2505.13995 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[74]
Constitutional AI: Harmlessness from AI Feedback
Constitutional ai: Harmlessness from ai feedback , author=. arXiv preprint arXiv:2212.08073 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
Frontiers in Psychology , volume=
ChatGPT’s advice is perceived as better than that of professional advice columnists , author=. Frontiers in Psychology , volume=. 2023 , publisher=
2023
-
[76]
Advisorqa: Towards helpful and harmless advice-seeking question answering with collective intelligence , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[77]
Proceedings of the International AAAI Conference on Web and Social Media , volume=
ChatGPT Giving Relationship Advice--How Reliable Is It? , author=. Proceedings of the International AAAI Conference on Web and Social Media , volume=
-
[78]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Social chemistry 101: Learning to reason about social and moral norms , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[79]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Moral stories: Situated reasoning about norms, intents, actions, and their consequences , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[80]
Nature Machine Intelligence , volume=
Investigating machine moral judgement through the Delphi experiment , author=. Nature Machine Intelligence , volume=. 2025 , publisher=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.