Bittensor Agent Arenas as a Trajectory Primitive: Distilling a Shopping Agent from ShoppingBench Subnet Traces
Pith reviewed 2026-06-27 17:05 UTC · model grok-4.3
The pith
Bittensor subnet traces, after a structural filter, train a 4B shopping agent from 18 percent to 42.7 percent success on held-out tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
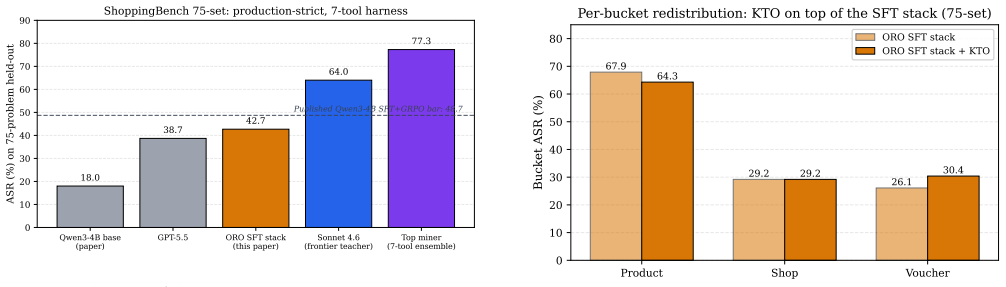
An incentive-aligned agent arena manufactures multi-turn trajectories that carry per-trajectory supervision. The structural-quality filter converts raw subnet output into a corpus consisting only of agentic traces. Post-training Qwen3-4B with the SFT-then-GRPO pipeline matched to the published ShoppingBench recipe lifts ASR on a leak-cluster-guarded held-out partition scored production-strict from the base 18.0 percent to 42.7 percent, within single-problem noise of the 43.6 percent synthetic SFT baseline, while training on a fraction of a single day of subnet output.
What carries the argument
The structural-quality filter that keeps trajectories in which the model emits tool calls and rejects trajectories in which the model only classifies or narrates over a deterministic search loop.
If this is right
- The filtered corpus enables SFT-then-GRPO training that reaches within noise of the synthetic-data SFT baseline.
- A per-step teacher-grounded Dr. GRPO reward converts the observed pass@8 to pass@1 gap into process improvement.
- The sub-task firehose from the arena is the primary remaining lever for closing the gap to the full 48.7 percent SFT-plus-GRPO level.
- The arena's race mechanism, LLM judge, and leak-cluster guard together deliver incentive-aligned diversity and anti-memorized held-out evaluation.
Where Pith is reading between the lines
- The same arena construction could be applied to agent benchmarks in domains other than commerce to generate comparable corpora.
- Continuous operation of such subnets could provide an ongoing stream of fresh trajectories for repeated post-training cycles.
- Combining arena traces with other data sources might narrow the remaining gap between the distilled model and the full synthetic-plus-GRPO result.
- The filter logic could be ported to other agent environments to extract usable training signals from raw production logs.
Load-bearing premise
The structural-quality filter accurately retains only agentic trajectories while rejecting sub-task trajectories and the resulting corpus supplies effective per-trajectory supervision for the SFT-then-GRPO recipe.
What would settle it
Retraining the identical base model on the unfiltered subnet traces or on a corpus produced without the structural filter and measuring whether the ASR lift to 42.7 percent on the same leak-cluster-guarded held-out partition disappears.
Figures

read the original abstract
Small-model agentic post-training is bottlenecked less by the algorithm than by the trajectory substrate it consumes. Leading recipes (RLVR, group-relative RL, rejection-sampled re-SFT) all need multi-turn traces carrying per-trajectory supervision, and the two existing sources fall short: frontier-synthesised data inherits the synthesizer's biases and collapses the long tail, while unfiltered production logs are unjudged and contaminated by shortcut behaviour. We argue that an incentive-aligned agent arena can be engineered to manufacture such trajectories, and demonstrate this on ORO Subnet 15 (SN15), a Bittensor deployment of the ShoppingBench agentic-commerce benchmark. SN15's race mechanism, LLM reasoning judge, and rotating leak-cluster-guarded problem suite yield a corpus with three properties: incentive-aligned diversity, per-trajectory judging, and anti-memorised held-out evaluation. We introduce a structural-quality filter that converts the raw firehose into a trainable corpus by keeping agentic trajectories (the model itself emits the tool calls) and rejecting sub-task trajectories (the model only classifies or narrates over a deterministic search loop), then post-train Qwen3-4B with a recipe matched to the published ShoppingBench SFT-then-GRPO pipeline. On a leak-cluster-guarded held-out partition scored production-strict, the model lifts from the published Qwen3-4B base of 18.0% ASR to 42.7%, within single-problem noise of the synthetic-data SFT-only baseline (43.6%), while training on a fraction of a single day of subnet output. The supervised stack leaves a large pass@8 to pass@1 gap (53.3% vs 34.8%); a per-step teacher-grounded Dr. GRPO reward converts that headroom into process improvement, and we identify the sub-task firehose as the primary lever for closing the gap to the 48.7% SFT+GRPO bar. We release the filter, the corpus splits, and the arena mechanics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that incentive-aligned agent arenas such as Bittensor ORO Subnet 15 (SN15) on ShoppingBench can generate usable multi-turn agentic trajectories. A structural-quality filter retains traces in which the model itself emits tool calls (rejecting sub-task narration over deterministic loops); the resulting corpus is used to post-train Qwen3-4B via an SFT-then-GRPO recipe matched to the published ShoppingBench pipeline. On a leak-cluster-guarded held-out partition scored production-strict, ASR rises from the base 18.0% to 42.7% (within single-problem noise of the synthetic SFT-only baseline at 43.6%), using only a fraction of one day's subnet output. The work releases the filter, corpus splits, and arena mechanics.
Significance. If the filter demonstrably supplies effective per-trajectory supervision, the result supplies a new, scalable source of diverse, judged trajectories that avoids both frontier-synthesizer bias and unfiltered production contamination. The explicit release of code and splits, together with the use of an external leak-guarded benchmark, strengthens reproducibility and falsifiability.
major comments (2)
- [structural-quality filter (abstract and methods)] The structural-quality filter is load-bearing for the central claim yet receives no ablation or validation. No experiment compares SFT+GRPO performance on the filtered corpus versus the unfiltered SN15 firehose, nor are any quality metrics (human correctness of emitted calls, coverage of long-tail behaviors, or distributional difference from the synthetic baseline) reported on the retained trajectories. Without these checks the attribution of the 18.0%→42.7% lift specifically to arena-derived supervision remains unestablished.
- [results on held-out partition] Table or result section reporting the 42.7% ASR: the headline lift is stated to lie “within single-problem noise” of the 43.6% synthetic baseline, but no per-problem variance, confidence intervals, or statistical test is supplied. This weakens the claim that the arena corpus is competitive rather than merely non-inferior.
minor comments (1)
- [abstract] The abstract introduces “production-strict scoring” and “per-step teacher-grounded Dr. GRPO reward” without inline definitions or pointers to the exact equations; these should be expanded on first use for readers unfamiliar with the ShoppingBench pipeline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [structural-quality filter (abstract and methods)] The structural-quality filter is load-bearing for the central claim yet receives no ablation or validation. No experiment compares SFT+GRPO performance on the filtered corpus versus the unfiltered SN15 firehose, nor are any quality metrics (human correctness of emitted calls, coverage of long-tail behaviors, or distributional difference from the synthetic baseline) reported on the retained trajectories. Without these checks the attribution of the 18.0%→42.7% lift specifically to arena-derived supervision remains unestablished.
Authors: We agree that an ablation comparing the filtered versus unfiltered corpus would provide stronger causal evidence for the filter's contribution. The manuscript motivates the filter in the methods section by its explicit goal of retaining only trajectories in which the model itself emits tool calls. We did not include the requested ablation or additional quality metrics in the original submission. In the revised manuscript we will add (i) a direct SFT+GRPO comparison on a matched-size unfiltered subsample and (ii) basic distributional statistics on the retained trajectories (tool-call rate, average turns, and overlap with the synthetic baseline). The released filter code and corpus splits make these experiments feasible. revision: yes
-
Referee: [results on held-out partition] Table or result section reporting the 42.7% ASR: the headline lift is stated to lie “within single-problem noise” of the 43.6% synthetic baseline, but no per-problem variance, confidence intervals, or statistical test is supplied. This weakens the claim that the arena corpus is competitive rather than merely non-inferior.
Authors: We accept that the current presentation of the 42.7% result would be strengthened by explicit variance measures. The phrase “within single-problem noise” reflects the small number of held-out problems and the observed per-problem variation we inspected during evaluation. In the revision we will expand the results section to report per-problem ASR values, standard error across problems, and a brief discussion of why formal hypothesis testing is under-powered given the problem count. This will make the competitiveness claim more precise. revision: yes
Circularity Check
No significant circularity detected.
full rationale
The paper reports an empirical result: post-training Qwen3-4B on a structurally filtered corpus from SN15 yields 42.7% ASR on a leak-cluster-guarded held-out partition of the external ShoppingBench benchmark, compared against previously published baselines (18.0% base, 43.6% synthetic SFT). The structural-quality filter is defined by explicit, non-fitted rules (retain traces where the model emits tool calls; reject those that only classify/narrate). No equations, fitted parameters, self-citations, or ansatzes are presented that reduce the reported lift or the filter's output to quantities defined inside this work by construction. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- structural-quality filter thresholds
axioms (2)
- domain assumption The LLM reasoning judge supplies reliable per-trajectory supervision
- domain assumption The rotating leak-cluster-guarded problem suite ensures generalization to held-out evaluation
Reference graph
Works this paper leans on
-
[1]
Shoppingbench: A multi- turn, tool-use benchmark for agentic commerce
ShoppingBench Authors. Shoppingbench: A multi- turn, tool-use benchmark for agentic commerce. arXiv preprint arXiv:2508.04266, 2025. URL https: //arxiv.org/abs/2508.04266
Pith/arXiv arXiv 2025
-
[2]
Introducing swe-1.5
Cognition. Introducing swe-1.5. Cognition Engi- neering Blog, 2025. URL https://cognition.ai/ blog/swe-1-5
2025
-
[3]
Introducing composer 2.5
Cursor. Introducing composer 2.5. Cursor Engineer- ing Blog, 2025. URL https://cursor.com/blog/ composer-2-5
2025
-
[4]
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. URL https:// arxiv.org/abs/2501.12948
Pith/arXiv arXiv 2025
-
[5]
Kto: Model align- ment as prospect theoretic optimization.arXiv preprint arXiv:2402.01306, 2024
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Kto: Model align- ment as prospect theoretic optimization.arXiv preprint arXiv:2402.01306, 2024. URL https: //arxiv.org/abs/2402.01306
Pith/arXiv arXiv 2024
-
[6]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models re- solve real-world github issues?International Con- ference on Learning Representations (ICLR), 2024. URLhttps://arxiv.org/abs/2310.06770
Pith/arXiv arXiv 2024
-
[7]
Nathan Lambert, Jacob Morrison, Valentina Py- atkin, et al. T¨ ulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124, 2024. URL https://arxiv.org/ abs/2411.15124
Pith/arXiv arXiv 2024
-
[8]
Toolace: Winning the points of llm function call- ing.arXiv preprint arXiv:2409.00920, 2024
Weiwen Liu, Xu Huang, Xingshan Zeng, et al. Toolace: Winning the points of llm function call- ing.arXiv preprint arXiv:2409.00920, 2024. URL https://arxiv.org/abs/2409.00920
arXiv 2024
-
[9]
Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
Zichen Liu et al. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025. URL https://arxiv.org/ abs/2503.20783
Pith/arXiv arXiv 2025
-
[11]
URLhttps://arxiv.org/abs/2307.16789
-
[12]
Bit- tensor: A peer-to-peer intelligence market
Yuma Rao, Jacob Steeves, and Ala Shaabana. Bit- tensor: A peer-to-peer intelligence market. Bittensor Foundation, 2024. URL https://docs.bittensor. com/
2024
-
[13]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseek- math: Pushing the limits of mathematical rea- soning in open language models.arXiv preprint arXiv:2402.03300, 2024. URL https://arxiv.org/ abs/2402.03300
Pith/arXiv arXiv 2024
-
[14]
Ai models collapse when trained on recur- sively generated data.Nature, 631(8022):755–759,
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson, and Yarin Gal. Ai models collapse when trained on recur- sively generated data.Nature, 631(8022):755–759,
-
[15]
URL https://www.nature.com/articles/ s41586-024-07566-y
-
[16]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. arXiv preprint arXiv:2404.07972, 2024. URL https: //arxiv.org/abs/2404.07972
Pith/arXiv arXiv 2024
-
[17]
Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yun- tian Deng, Radha Poovendran, Yejin Choi, and Bill Yuchen Lin. Magpie: Alignment data synthesis from scratch by prompting aligned llms with noth- ing.arXiv preprint arXiv:2406.08464, 2024. URL https://arxiv.org/abs/2406.08464
Pith/arXiv arXiv 2024
-
[19]
URLhttps://arxiv.org/abs/2403.04132
-
[20]
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for build- ing autonomous agents.International Conference on Learning Representations (ICLR), 2024. URL https://arxiv.org/abs/2307.13854. 12
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.