A Theory on Flow Matching with Neural Networks
Pith reviewed 2026-06-27 16:57 UTC · model grok-4.3
The pith
Overparameterized two-layer ReLU networks converge under gradient descent when trained to match conditional velocity fields, yielding Wasserstein guarantees on generated samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We establish convergence guarantees for gradient descent in the over-parameterized 2-layered ReLU neural network regime. We derive generalization bounds for the conditional velocity-field matching objective. Building on these results, we provide Wasserstein-distance guarantees for the samples generated by the induced flow. Our analysis is based on a generalization bound for multi-task representation learning with unbounded losses.
What carries the argument
The conditional velocity-field matching objective, which trains the network to approximate the time-dependent velocity that maps noise distributions to data distributions under the flow.
If this is right
- Gradient descent reaches a solution with controlled error for the velocity field approximation.
- The generated flow produces samples with provably bounded Wasserstein distance to the data distribution.
- The same multi-task bound yields generalization results for the flow matching loss.
- The guarantees extend to both synthetic distributions and real image datasets under the stated conditions.
Where Pith is reading between the lines
- Similar analysis could apply to other continuous normalizing flow variants if their objectives admit comparable multi-task reductions.
- The Wasserstein guarantees suggest that early stopping or regularization choices can be guided by the derived rates rather than cross-validation alone.
- Extensions to deeper or wider networks would require checking whether the overparameterization assumptions scale without introducing new error terms.
Load-bearing premise
The multi-task representation learning bound for unbounded losses applies directly to the conditional velocity-field matching objective.
What would settle it
Training runs where the empirical Wasserstein distance between generated and target samples remains larger than the paper's derived bound after convergence in the stated overparameterized regime.
Figures
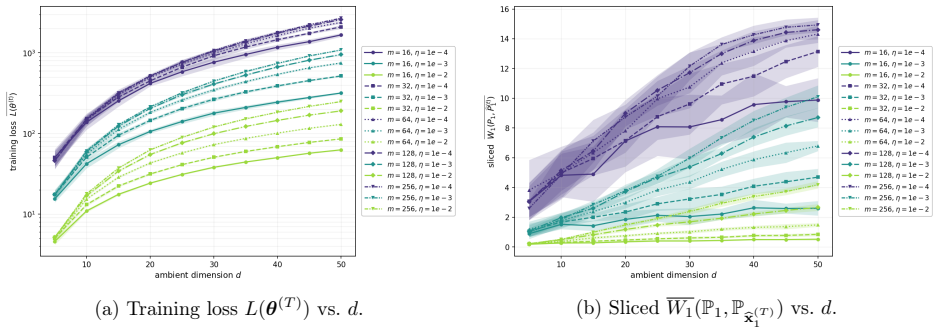

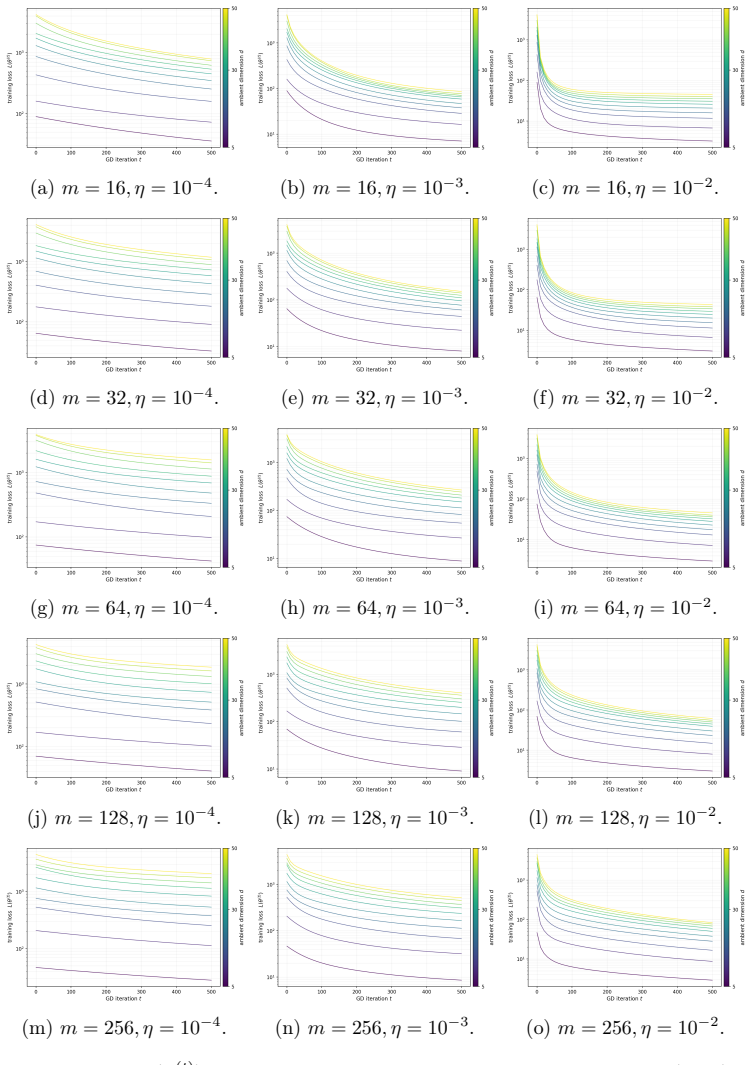

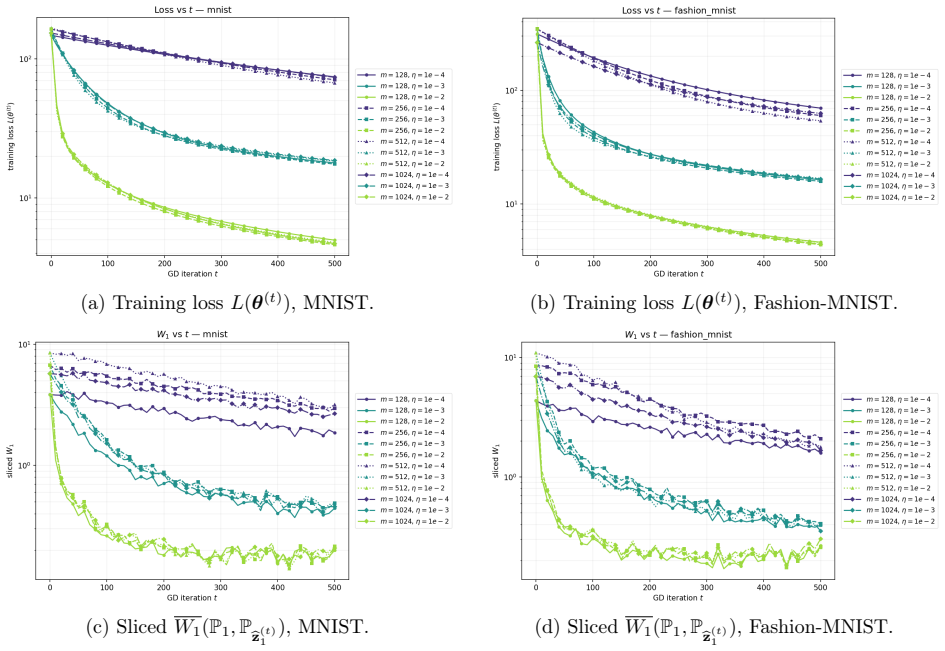


read the original abstract
In this work, we develop theoretical foundation for flow matching with neural-network-parameterized conditional velocity fields. We establish convergence guarantees for gradient descent in the over-parameterized 2-layered ReLU neural network regime. We derive generalization bounds for the conditional velocity-field matching objective. Building on these results, we provide Wasserstein-distance guarantees for the samples generated by the induced flow. Our analysis is based on generalization bound for multi-task representation learning with unbounded losses, which may be of independent interest beyond flow-based generative modeling. These theoretical results are validated through extensive experiments on both synthetic and real-world image benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops theoretical foundations for flow matching with neural-network-parameterized conditional velocity fields. It claims convergence guarantees for gradient descent in the over-parameterized 2-layer ReLU regime, generalization bounds for the conditional velocity-field matching objective derived from a multi-task representation learning bound with unbounded losses, and resulting Wasserstein-distance guarantees for samples from the induced flow. Results are supported by experiments on synthetic and real-world image benchmarks.
Significance. If the mapping of the conditional velocity-field objective to the multi-task bound is valid and the derivations hold, the work would supply useful convergence and generalization theory for flow matching, a prominent class of generative models. The multi-task bound with unbounded losses is presented as potentially of independent interest.
major comments (2)
- [Abstract and theoretical analysis] The central claims (GD convergence, generalization of the matching objective, and Wasserstein guarantees) rest on applying the multi-task representation learning bound with unbounded losses to the conditional velocity-field matching objective, yet the manuscript supplies no explicit verification that the objective satisfies the bound's assumptions on loss structure, unboundedness handling, task decomposition, or representation-learning setup (see abstract and the theoretical analysis sections).
- [Theoretical analysis] The conditional nature of the velocity field (conditioned on data or time) must map onto the multi-task framework for the bound to apply directly; without a concrete check of this mapping or the over-parameterized ReLU regime, the applicability of the bound remains unestablished and undermines the downstream Wasserstein guarantees.
minor comments (2)
- [Abstract] The abstract asserts the existence of proofs and bounds but provides no derivation steps, assumption lists, or error-bar details, making it difficult to assess the mathematics even at a high level.
- [Experiments] Experiment section should include specific metrics, baselines, and quantitative results to support the validation claims on image benchmarks.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback on our manuscript. We address the major comments point by point below and will revise the manuscript to improve clarity on the mapping to the multi-task bound.
read point-by-point responses
-
Referee: [Abstract and theoretical analysis] The central claims (GD convergence, generalization of the matching objective, and Wasserstein guarantees) rest on applying the multi-task representation learning bound with unbounded losses to the conditional velocity-field matching objective, yet the manuscript supplies no explicit verification that the objective satisfies the bound's assumptions on loss structure, unboundedness handling, task decomposition, or representation-learning setup (see abstract and the theoretical analysis sections).
Authors: We agree that an explicit, systematic verification of the assumptions would strengthen the presentation and make the applicability clearer. While the theoretical analysis sections frame the conditional velocity-field objective within the multi-task representation learning setup (with tasks corresponding to conditioning on time and data), we acknowledge that a dedicated check listing each assumption (loss structure, unboundedness handling via truncation or moment conditions, task decomposition, and the 2-layer ReLU overparameterized regime) is not presented as a single consolidated verification. In the revision we will add a new subsection that performs this explicit mapping and assumption check. revision: yes
-
Referee: [Theoretical analysis] The conditional nature of the velocity field (conditioned on data or time) must map onto the multi-task framework for the bound to apply directly; without a concrete check of this mapping or the over-parameterized ReLU regime, the applicability of the bound remains unestablished and undermines the downstream Wasserstein guarantees.
Authors: We concur that the conditional structure requires an explicit mapping to justify direct application of the bound. In the revised manuscript we will add a concrete construction: we define tasks as pairs (t, x_0) where t is discretized time and x_0 indexes data samples, with the shared representation learned by the 2-layer ReLU network satisfying the overparameterization conditions of the bound. This explicit mapping will be inserted prior to the generalization and Wasserstein results to ensure the chain of implications is fully justified. revision: yes
Circularity Check
No circularity: analysis applies external multi-task generalization bound to flow-matching objective
full rationale
The paper states that its convergence guarantees, generalization bounds for the conditional velocity-field matching objective, and Wasserstein guarantees build on a generalization bound for multi-task representation learning with unbounded losses. This bound is described as potentially of independent interest beyond the present work. No quoted equation or derivation in the provided abstract reduces any claimed result to a fitted parameter, self-definition, or self-citation chain internal to the flow-matching analysis. The central claims therefore rest on an externally applicable bound rather than on quantities defined or fitted inside the paper itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A generalization bound for multi-task representation learning with unbounded losses holds and transfers to the flow-matching velocity-field objective
Reference graph
Works this paper leans on
-
[1]
International Conference on Machine Learning , pages=
A mean field analysis of deep resnet and beyond: Towards provably optimization via overparameterization from depth , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[2]
2021 , eprint=
On the Global Convergence of Gradient Descent for multi-layer ResNets in the mean-field regime , author=. 2021 , eprint=
2021
-
[3]
Journal of Machine Learning Research , volume=
Overparameterization of deep resnet: Zero loss and mean-field analysis , author=. Journal of Machine Learning Research , volume=
-
[4]
Advances in Neural Information Processing Systems , volume=
Global convergence in training large-scale transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Conference on learning theory , pages=
Modeling from features: a mean-field framework for over-parameterized deep neural networks , author=. Conference on learning theory , pages=. 2021 , organization=
2021
-
[6]
their Induced Kernel , author=
Regularization Matters: Generalization and Optimization of Neural Nets v.s. their Induced Kernel , author=. Advances in Neural Information Processing Systems , year=
-
[7]
Proceedings of the National Academy of Sciences , volume=
A mean field view of the landscape of two-layer neural networks , author=. Proceedings of the National Academy of Sciences , volume=. 2018 , publisher=
2018
-
[8]
Advances in neural information processing systems , pages=
On the global convergence of gradient descent for over-parameterized models using optimal transport , author=. Advances in neural information processing systems , pages=
-
[9]
Advances in Neural Information Processing Systems , year=
On exact computation with an infinitely wide neural net , author=. Advances in Neural Information Processing Systems , year=
-
[10]
Advances in Neural Information Processing Systems , year=
On Lazy Training in Differentiable Programming , author=. Advances in Neural Information Processing Systems , year=
-
[11]
Advances in Neural Information Processing Systems , year=
Wide neural networks of any depth evolve as linear models under gradient descent , author=. Advances in Neural Information Processing Systems , year=
-
[12]
International Conference on Learning Representations , year=
Gradient Descent Provably Optimizes Over-parameterized Neural Networks , author=. International Conference on Learning Representations , year=
-
[13]
Advances in Neural Information Processing Systems , pages=
Learning overparameterized neural networks via stochastic gradient descent on structured data , author=. Advances in Neural Information Processing Systems , pages=
-
[14]
International Conference on Machine Learning , pages=
A Convergence Theory for Deep Learning via Over-Parameterization , author=. International Conference on Machine Learning , pages=
-
[15]
Gradient descent optimizes over-parameterized deep ReLU networks
Zou, Difan and Cao, Yuan and Zhou, Dongruo and Gu, Quanquan. Gradient descent optimizes over-parameterized deep ReLU networks. Machine Learning. 2019
2019
-
[16]
Advances in Neural Information Processing Systems , year=
Learning and Generalization in Overparameterized Neural Networks, Going Beyond Two Layers , author=. Advances in Neural Information Processing Systems , year=
-
[17]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[18]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[19]
M. J. Kearns , title =
-
[20]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[21]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[22]
Suppressed for Anonymity , author=
-
[23]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[24]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[25]
Advances in neural information processing systems , volume=
Understanding double descent requires a fine-grained bias-variance decomposition , author=. Advances in neural information processing systems , volume=
-
[26]
Advances in neural information processing systems , volume=
Nonlinear random matrix theory for deep learning , author=. Advances in neural information processing systems , volume=
-
[27]
Random Matrices: Theory and Applications , volume=
The spectrum of random inner-product kernel matrices , author=. Random Matrices: Theory and Applications , volume=. 2013 , publisher=
2013
-
[28]
2012 , publisher=
Topics in random matrix theory , author=. 2012 , publisher=
2012
-
[29]
The Annals of Statistics , volume=
Surprises in high-dimensional ridgeless least squares interpolation , author=. The Annals of Statistics , volume=. 2022 , publisher=
2022
-
[30]
Journal of Statistical Mechanics: Theory and Experiment , volume=
Scaling description of generalization with number of parameters in deep learning , author=. Journal of Statistical Mechanics: Theory and Experiment , volume=. 2020 , publisher=
2020
-
[31]
arXiv preprint arXiv:1912.07242 , year=
More data can hurt for linear regression: Sample-wise double descent , author=. arXiv preprint arXiv:1912.07242 , year=
arXiv 1912
-
[32]
International Conference on Machine Learning , pages=
Double trouble in double descent: Bias and variance (s) in the lazy regime , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[33]
Physical Review Letters , volume=
Eigenvalues of covariance matrices: Application to neural-network learning , author=. Physical Review Letters , volume=. 1991 , publisher=
1991
-
[34]
Journal of Physics A: Mathematical and General , volume=
Generalization in a linear perceptron in the presence of noise , author=. Journal of Physics A: Mathematical and General , volume=. 1992 , publisher=
1992
-
[35]
2001 , publisher=
Statistical mechanics of learning , author=. 2001 , publisher=
2001
-
[36]
arXiv preprint arXiv:2003.01897 , year=
Optimal regularization can mitigate double descent , author=. arXiv preprint arXiv:2003.01897 , year=
arXiv 2003
-
[37]
Advances in Neural Information Processing Systems , volume=
Triple descent and the two kinds of overfitting: Where & why do they appear? , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
Advances in Neural Information Processing Systems , volume=
Multiple descent: Design your own generalization curve , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
2011 , publisher=
Random fields on the sphere: representation, limit theorems and cosmological applications , author=. 2011 , publisher=
2011
-
[40]
, author=
Spherical-homoscedastic distributions: The equivalency of spherical and normal distributions in classification. , author=. Journal of Machine Learning Research , volume=
-
[41]
Journal of the American Statistical Association , volume=
Nonparametric regression for spherical data , author=. Journal of the American Statistical Association , volume=. 2014 , publisher=
2014
-
[42]
2009 , publisher=
The elements of statistical learning: data mining, inference, and prediction , author=. 2009 , publisher=
2009
-
[43]
Advances in Neural Information Processing Systems , pages=
Global convergence of langevin dynamics based algorithms for nonconvex optimization , author=. Advances in Neural Information Processing Systems , pages=
-
[44]
Proceedings of the 37th International Conference on Machine Learning , pages =
The Neural Tangent Kernel in High Dimensions: Triple Descent and a Multi-Scale Theory of Generalization , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
2020
-
[45]
Constructive Approximation , volume=
On Early Stopping in Gradient Descent Learning , author=. Constructive Approximation , volume=
-
[46]
Communications on Pure and Applied Mathematics , volume=
The generalization error of random features regression: Precise asymptotics and the double descent curve , author=. Communications on Pure and Applied Mathematics , volume=. 2022 , publisher=
2022
-
[47]
Advances in neural information processing systems , volume=
Random features for large-scale kernel machines , author=. Advances in neural information processing systems , volume=
-
[48]
Journal of Functional Analysis , volume=
Generalization of an inequality by Talagrand and links with the logarithmic Sobolev inequality , author=. Journal of Functional Analysis , volume=. 2000 , publisher=
2000
-
[49]
arXiv preprint arXiv:1910.11508 , year=
Over Parameterized Two-level Neural Networks Can Learn Near Optimal Feature Representations , author=. arXiv preprint arXiv:1910.11508 , year=
arXiv 1910
-
[50]
arXiv preprint arXiv:1904.04326 , year=
A Comparative Analysis of the Optimization and Generalization Property of Two-layer Neural Network and Random Feature Models Under Gradient Descent Dynamics , author=. arXiv preprint arXiv:1904.04326 , year=
arXiv 1904
-
[51]
the Thirty-Fourth AAAI Conference on Artificial Intelligence , year=
Generalization Error Bounds of Gradient Descent for Learning Over-parameterized Deep ReLU Networks , author=. the Thirty-Fourth AAAI Conference on Artificial Intelligence , year=
-
[52]
Proceedings of the 34th International Conference on Machine Learning-Volume 70 , pages=
Globally optimal gradient descent for a convnet with gaussian inputs , author=. Proceedings of the 34th International Conference on Machine Learning-Volume 70 , pages=. 2017 , organization=
2017
-
[53]
International Conference on Machine Learning , pages=
Overparameterized Nonlinear Learning: Gradient Descent Takes the Shortest Path? , author=. International Conference on Machine Learning , pages=
-
[54]
Training Over-parameterized Deep
Zhang, Huishuai and Yu, Da and Chen, Wei and Liu, Tie-Yan , journal=. Training Over-parameterized Deep
-
[55]
arXiv preprint arXiv:1902.07111 , year=
Global Convergence of Adaptive Gradient Methods for An Over-parameterized Neural Network , author=. arXiv preprint arXiv:1902.07111 , year=
arXiv 1902
-
[56]
Advances in neural information processing systems , pages=
Better mini-batch algorithms via accelerated gradient methods , author=. Advances in neural information processing systems , pages=
-
[57]
Zhurnal Vychislitel'noi Matematiki i Matematicheskoi Fiziki , volume=
Gradient methods for minimizing functionals , author=. Zhurnal Vychislitel'noi Matematiki i Matematicheskoi Fiziki , volume=. 1963 , publisher=
1963
-
[58]
Journal of Machine Learning Research , volume=
Stochastic dual coordinate ascent methods for regularized loss minimization , author=. Journal of Machine Learning Research , volume=
-
[59]
Bell Labs Technical Journal , volume=
The one-sided barrier problem for Gaussian noise , author=. Bell Labs Technical Journal , volume=. 1962 , publisher=
1962
-
[60]
arXiv preprint arXiv:1312.6120 , year=
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks , author=. arXiv preprint arXiv:1312.6120 , year=
-
[61]
International Conference on Machine Learning , pages=
Gradient descent with identity initialization efficiently learns positive definite linear transformations , author=. International Conference on Machine Learning , pages=
-
[62]
Electronic Communications in Probability , volume=
A tail inequality for quadratic forms of subgaussian random vectors , author=. Electronic Communications in Probability , volume=. 2012 , publisher=
2012
-
[63]
NIPS Tutorial , year=
High-performance hardware for machine learning , author=. NIPS Tutorial , year=
-
[64]
Advances in neural information processing systems , pages=
Sequence to sequence learning with neural networks , author=. Advances in neural information processing systems , pages=
-
[65]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Going deeper with convolutions , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[66]
, author=
Fast and Robust Neural Network Joint Models for Statistical Machine Translation. , author=. ACL (1) , pages=
-
[67]
arXiv preprint arXiv:1409.0473 , year=
Neural machine translation by jointly learning to align and translate , author=. arXiv preprint arXiv:1409.0473 , year=
-
[68]
Neural networks , volume=
Approximation capabilities of multilayer feedforward networks , author=. Neural networks , volume=. 1991 , publisher=
1991
-
[69]
Advances In Neural Information Processing Systems , pages=
Toward deeper understanding of neural networks: The power of initialization and a dual view on expressivity , author=. Advances In Neural Information Processing Systems , pages=
-
[70]
Conference on Learning Theory , pages=
On the expressive power of deep learning: A tensor analysis , author=. Conference on Learning Theory , pages=
-
[71]
International Conference on Machine Learning , pages=
Convolutional rectifier networks as generalized tensor decompositions , author=. International Conference on Machine Learning , pages=
-
[72]
arXiv preprint arXiv:1606.05336 , year=
On the expressive power of deep neural networks , author=. arXiv preprint arXiv:1606.05336 , year=
-
[73]
Advances In Neural Information Processing Systems , pages=
Exponential expressivity in deep neural networks through transient chaos , author=. Advances In Neural Information Processing Systems , pages=
-
[74]
Advances in neural information processing systems , pages=
On the number of linear regions of deep neural networks , author=. Advances in neural information processing systems , pages=
-
[75]
Training , volume=
Training a single sigmoidal neuron is hard , author=. Training , volume=. 2006 , publisher=
2006
-
[76]
Advances in Neural Information Processing Systems , pages=
On the computational efficiency of training neural networks , author=. Advances in Neural Information Processing Systems , pages=
-
[77]
arXiv preprint arXiv:1609.01037 , year=
Distribution-specific hardness of learning neural networks , author=. arXiv preprint arXiv:1609.01037 , year=
-
[78]
International Conference on Machine Learning , pages=
Failures of gradient-based deep learning , author=. International Conference on Machine Learning , pages=
-
[79]
arXiv preprint arXiv:1706.00687 , year=
Weight Sharing is Crucial to Succesful Optimization , author=. arXiv preprint arXiv:1706.00687 , year=
-
[80]
Advances in neural information processing systems , pages=
Training a 3-node neural network is NP-complete , author=. Advances in neural information processing systems , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.