iSAGE: A Human-in-the-Loop Framework for Remote Sensing Semantic Segmentation via Sparse Point Supervision
Pith reviewed 2026-06-27 16:47 UTC · model grok-4.3
The pith
Expert clicks targeting a model's confident errors suffice to match dense pixel supervision in remote sensing semantic segmentation with no auxiliary expansion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
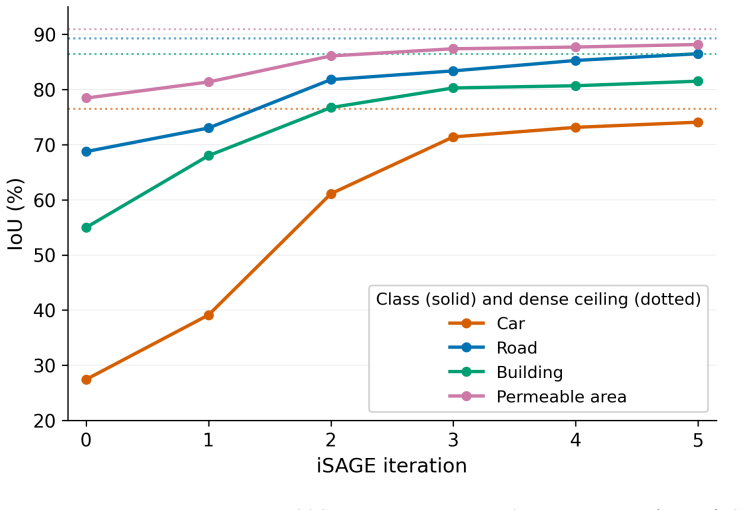
iSAGE demonstrates that iterative expert clicks on confident model errors, trained with an error-weighted loss and without any pseudo-labeling or propagation, achieve mIoU scores matching or exceeding dense supervision on remote sensing benchmarks, reaching 76.78% on ISPRS Vaihingen with only 0.011% of pixels labeled compared to 76.65% for the dense baseline.
What carries the argument
The error-weighted loss that amplifies gradients at expert-clicked error pixels, allowing training from sparse point supervision alone.
If this is right
- Matches dense baseline on ISPRS Vaihingen with 0.011% labeled pixels.
- Recovers 97.2% of dense performance on BsB Aerial with 0.040% pixels.
- Outperforms mechanisms like pseudo-labels and CRF propagation by 7 to 14 percentage points.
- Shows different annotation needs for amorphous versus small object classes across iterations.
Where Pith is reading between the lines
- The auditable annotation record could support dataset versioning and correction over time.
- Similar sparse supervision might apply to other pixel-level tasks like depth estimation or change detection.
- Reducing reliance on dense labels could accelerate model adaptation across different remote sensing platforms and geographies.
Load-bearing premise
That experts can reliably spot and click the pixels where the model is wrong rather than right, even when the model outputs high confidence.
What would settle it
Running the identical training loop but with clicks chosen by random selection or model entropy instead of expert error targeting, and observing whether mIoU still reaches the dense baseline.
Figures






read the original abstract
Semantic segmentation in remote sensing requires costly pixel-level annotations, and nearly every problem demands a new dataset since models rarely transfer across sensors, platforms, or geographies. Existing human-in-the-loop frameworks expand sparse clicks into dense supervision via auxiliary machinery (pseudo-labels, propagation, CRFs, foundation-model prompts, auxiliary heads), all operating on the model's predictive distribution. A confidently wrong pixel is indistinguishable from a confidently correct one in that distribution by construction, so no rule reading it can separate the two; the distinguishing signal is external to the model. This paper hypothesizes that expert clicks targeting confident model errors, not arbitrary pixels, suffice to match dense supervision, with no expansion machinery. iSAGE (Iterative Sparse Annotation Guided by Expert) realizes this hypothesis on an integrated open-source platform, where an error-weighted loss amplifies the gradient at each click and the annotation record itself is the dataset, extensible, correctable, and auditable. Experiments use a minimum-effort regime: at most one labeled pixel per class per frame. On BsB Aerial, iSAGE recovers 97.2% of dense supervision (74.79% mIoU on 0.040% of pixels) with contrasting class dynamics: amorphous classes (permeable areas) saturate from the seed, while small classes (cars) require late-iteration effort. On ISPRS Vaihingen (external benchmark), iSAGE reaches 76.78% mIoU with 0.011% of pixels, matching the dense baseline (76.65%) and exceeding all published methods. Under the same pipeline, four output-reading mechanisms (oracle entropy across budgets 1--100x, pseudo-labels across thresholds 0.90--0.99, CRF-based propagation, uniform random) plateau 7.4 to 14.5 pp below iSAGE. Across 31 surveyed methods, iSAGE is the only iterative human-in-the-loop framework operating without auxiliary machinery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces iSAGE, a human-in-the-loop framework for remote sensing semantic segmentation that relies on iterative sparse expert point annotations targeting confident model errors (at most one pixel per class per frame), combined with an error-weighted loss, to match dense-supervision performance without pseudo-labeling, propagation, CRFs, or other auxiliary machinery. On ISPRS Vaihingen it reports 76.78% mIoU at 0.011% labeled pixels (vs. 76.65% dense baseline) and on BsB Aerial 74.79% mIoU at 0.040% pixels (97.2% of dense); it also shows 7.4–14.5 pp gains over entropy, pseudo-label, CRF, and random baselines across budgets.
Significance. If the human-identification premise holds, the result is significant: it supplies direct empirical evidence that external expert signal on model errors can replace expansion machinery, with an open-source extensible platform whose annotation record is the dataset. The controlled comparisons to four alternative output-reading mechanisms and the class-specific dynamics (amorphous vs. small objects) strengthen the contribution.
major comments (2)
- [Experimental protocol] Experimental protocol (implicit in §4 and results): the paper does not specify whether the 'expert clicks targeting confident model errors' are obtained by human annotators viewing only the image and predictive map or by oracle access to ground truth to locate errors. This is load-bearing for the central claim that expert identification from the predictive distribution suffices; oracle selection would make the large gap over entropy/pseudo-label/CRF baselines unsurprising and would undermine the human-in-the-loop premise. No inter-annotator agreement, human-study protocol, or visual-only annotation interface description is provided.
- [Vaihingen results] Vaihingen results paragraph and comparison table: the claim that iSAGE matches the dense baseline at 0.011% pixels requires explicit confirmation that click selection and model updates are performed iteratively without any GT leakage at selection time; otherwise the 'minimum-effort regime' numbers cannot be interpreted as evidence for the no-expansion hypothesis.
minor comments (2)
- [Abstract] Abstract: the four output-reading mechanisms are named only later; a parenthetical list (entropy, pseudo-label thresholds, CRF, random) would improve immediate readability.
- [Method] Notation: the error-weighted loss is described qualitatively; an explicit equation showing how the per-click weight is computed from the annotation record would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments on experimental protocol are well-taken and we will revise the manuscript to address them explicitly.
read point-by-point responses
-
Referee: [Experimental protocol] Experimental protocol (implicit in §4 and results): the paper does not specify whether the 'expert clicks targeting confident model errors' are obtained by human annotators viewing only the image and predictive map or by oracle access to ground truth to locate errors. This is load-bearing for the central claim that expert identification from the predictive distribution suffices; oracle selection would make the large gap over entropy/pseudo-label/CRF baselines unsurprising and would undermine the human-in-the-loop premise. No inter-annotator agreement, human-study protocol, or visual-only annotation interface description is provided.
Authors: We agree the protocol must be stated clearly. The reported experiments simulate expert clicks via oracle access to ground truth solely to identify confident model errors; this isolates the contribution of error-targeted sparse points without auxiliary expansion. The framework itself is designed for human annotators who would view only the image and current prediction map. We will revise §4 and the experimental setup to describe the simulation, note that it provides an upper-bound reference for human performance, and add a limitations paragraph discussing the absence of a full human-subject study together with plans for future interface-based validation. revision: yes
-
Referee: [Vaihingen results] Vaihingen results paragraph and comparison table: the claim that iSAGE matches the dense baseline at 0.011% pixels requires explicit confirmation that click selection and model updates are performed iteratively without any GT leakage at selection time; otherwise the 'minimum-effort regime' numbers cannot be interpreted as evidence for the no-expansion hypothesis.
Authors: We will add an explicit statement in the Vaihingen results section confirming the iterative protocol: after each model update on the accumulated sparse points, the next click is chosen from the current prediction map (via the oracle simulation of error identification). No ground-truth information enters the loss or model parameters except through the selected points themselves. This preserves the no-expansion hypothesis while making the simulation transparent. revision: yes
Circularity Check
No circularity: empirical validation against external benchmarks
full rationale
The paper advances an empirical hypothesis tested via direct mIoU comparisons on ISPRS Vaihingen and BsB Aerial against dense supervision and multiple alternative mechanisms (entropy, pseudo-labels, CRF, random). No mathematical derivation chain exists that reduces a claimed result to its inputs by construction. The error-weighted loss is applied to externally supplied clicks; performance is measured, not derived. No self-citations, fitted parameters renamed as predictions, or ansatzes are load-bearing. The result is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert humans can reliably identify confident model errors from the predictive distribution.
Reference graph
Works this paper leans on
-
[1]
Computer Vision – ECCV 2014
Microsoft COCO: Common Objects in Context , author=. Computer Vision – ECCV 2014. Lecture Notes in Computer Science, vol 8693 , doi=
2014
-
[2]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
The cityscapes dataset for semantic urban scene understanding , author=. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=. doi:10.1109/CVPR.2016.350 , url=
-
[3]
ImageNet: A large-scale hierarchical image database
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Kai Li and Li Fei-Fei , booktitle=. ImageNet: A large-scale hierarchical image database , year=. doi:10.1109/CVPR.2009.5206848 , url=
-
[4]
The VLDB Journal , pages=
Data collection and quality challenges in deep learning: A data-centric AI perspective , author=. The VLDB Journal , pages=. 2023 , doi=
2023
-
[5]
arXiv preprint arXiv:2303.10158 , eprint=
Data-centric artificial intelligence: A survey , author=. arXiv preprint arXiv:2303.10158 , eprint=
-
[6]
Revisiting Unreasonable Effectiveness of Data in Deep Learning Era , year=
Sun, Chen and Shrivastava, Abhinav and Singh, Saurabh and Gupta, Abhinav , booktitle=. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era , year=. doi:10.1109/ICCV.2017.97 , url=
-
[7]
ISPRS Journal of Photogrammetry and Remote Sensing , keywords =
Rottensteiner, Franz and Sohn, Gunho and Gerke, Markus and Wegner, Jan Dirk and Breitkopf, Uwe and Jung, Jaewook , doi =. ISPRS Journal of Photogrammetry and Remote Sensing , keywords =
-
[8]
2022 , eprint=
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation , author=. 2022 , eprint=
2022
-
[9]
Remote Sensing , volume=
Panoptic Segmentation Meets Remote Sensing , author=. Remote Sensing , volume=. 2022 , doi=
2022
-
[10]
Scientific Data , month =
Rahnemoonfar, Maryam and Chowdhury, Tashnim and Murphy, Robin , doi =. Scientific Data , month =
-
[11]
Bearman, Amy and Russakovsky, Olga and Ferrari, Vittorio and Fei-Fei, Li , doi =. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) , keywords =. 2016 , url=. arXiv , arxivId =:1506.02106 , isbn =
Pith/arXiv arXiv 2016
-
[12]
IEEE Geoscience and Remote Sensing Letters , volume=
Semantic segmentation of remote sensing images with sparse annotations , author=. IEEE Geoscience and Remote Sensing Letters , volume=. 2021 , doi=
2021
-
[13]
International Conference on Learning Representations (ICLR) , year=
Active learning for convolutional neural networks: A core-set approach , author=. International Conference on Learning Representations (ICLR) , year=. 1708.00489 , archivePrefix=
-
[14]
Workshop on challenges in representation learning, ICML , volume=
Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks , author=. Workshop on challenges in representation learning, ICML , volume=. 2013 , organization=
2013
-
[15]
and Lo, Wan-Yen and Dollár, Piotr and Girshick, Ross , booktitle=
Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Dollár, Piotr and Girshick, Ross , booktitle=. Segment Anything , year=
-
[16]
ScribbleSup: Scribble-Supervised Convolutional Networks for Semantic Segmentation , year=
Lin, Di and Dai, Jifeng and Jia, Jiaya and He, Kaiming and Sun, Jian , booktitle=. ScribbleSup: Scribble-Supervised Convolutional Networks for Semantic Segmentation , year=
-
[17]
Medical Image Computing and Computer-Assisted Intervention – MICCAI 2016 , doi =
2016
-
[18]
Segmentation only uses sparse annotations: Unified weakly and semi-supervised learning in medical images , volume =
Feng Gao and Minhao Hu and Min Er Zhong and Shixiang Feng and Xuwei Tian and Xiaochun Meng and Ma yi di li Ni-jia-ti and Zeping Huang and Minyi Lv and Tao Song and Xiaofan Zhang and Xiaoguang Zou and Xiaojian Wu , doi =. Segmentation only uses sparse annotations: Unified weakly and semi-supervised learning in medical images , volume =. Medical Image Analy...
2022
-
[19]
Medical Image Analysis , month =
Kervadec, Hoel and Dolz, Jose and Tang, Meng and Granger, Eric and Boykov, Yuri and. Medical Image Analysis , month =. doi:10.1016/j.media.2019.02.009 , issn =
-
[20]
BMC Medical Imaging , month =
Yang, Guanyu and Wang, Chuanxia and Yang, Jian and Chen, Yang and Tang, Lijun and Shao, Pengfei and Dillenseger, Jean-Louis and Shu, Huazhong and Luo, Limin , doi =. BMC Medical Imaging , month =
-
[21]
Computers in Biology and Medicine , month =
Liu, Xiaoming and Liu, Qi and Zhang, Ying and Wang, Man and Tang, Jinshan , doi =. Computers in Biology and Medicine , month =
-
[22]
and Tuia, Devis , doi =
Maggiolo, Luca and Marcos, Diego and Moser, Gabriele and Serpico, Sebastiano B. and Tuia, Devis , doi =. IEEE Transactions on Geoscience and Remote Sensing , keywords =. 2022 , url =
2022
-
[23]
Remote Sensing , keywords =
Mazhar, Sarah and Sun, Guangmin and Bilal, Anas and Hassan, Bilal and Li, Yu and Zhang, Junjie and Lin, Yinyi and Khan, Ali and Ahmed, Ramsha and Hassan, Taimur , doi =. Remote Sensing , keywords =. 2022 , url =
2022
-
[24]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , keywords =
Gbodjo, Yawogan Jean Eudes and Montet, Olivier and Ienco, Dino and Gaetano, Raffaele and Dupuy, Stephane , doi =. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , keywords =
-
[25]
Tree Energy Loss: Towards Sparsely Annotated Semantic Segmentation , url =
Zhiyuan Liang and Tiancai Wang and Xiangyu Zhang and Jian Sun and Jianbing Shen , doi =. Tree Energy Loss: Towards Sparsely Annotated Semantic Segmentation , url =. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
2022
-
[26]
One Thing One Click: A Self-Training Approach for Weakly Supervised 3D Semantic Segmentation , url =
Zhengzhe Liu and Xiaojuan Qi and Chi-Wing Fu , doi =. One Thing One Click: A Self-Training Approach for Weakly Supervised 3D Semantic Segmentation , url =. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
2021
-
[27]
2017 , eprint=
Rethinking Atrous Convolution for Semantic Image Segmentation , author=. 2017 , eprint=
2017
-
[28]
Learning to Segment Medical Images with Scribble-Supervision Alone
Can, Yigit B. and Chaitanya, Krishna and Mustafa, Basil and Koch, Lisa M. and Konukoglu, Ender and Baumgartner, Christian F. , booktitle =. Learning to Segment Medical Images with Scribble-Supervision Alone , url =. doi:10.1007/978-3-030-00889-5_27 , editor =. arXiv , arxivId =:1807.04668 , isbn =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/978-3-030-00889-5_27
-
[29]
Arnab, Anurag and Zheng, Shuai and Jayasumana, Sadeep and Romera-Paredes, Bernardino and Larsson, Mans and Kirillov, Alexander and Savchynskyy, Bogdan and Rother, Carsten and Kahl, Fredrik and Torr, Philip H.S. , doi =. IEEE Signal Processing Magazine , month =
-
[30]
PyMIC: A deep learning toolkit for annotation-efficient medical image segmentation , journal =
Guotai Wang and Xiangde Luo and Ran Gu and Shuojue Yang and Yijie Qu and Shuwei Zhai and Qianfei Zhao and Kang Li and Shaoting Zhang , keywords =. PyMIC: A deep learning toolkit for annotation-efficient medical image segmentation , journal =. 2023 , issn =. doi:10.1016/j.cmpb.2023.107398 , url =
-
[31]
Deep Active Learning for Joint Classification & Segmentation with Weak Annotator , url =
Soufiane Belharbi and Ismail Ben Ayed and Luke McCaffrey and Eric Granger , doi =. Deep Active Learning for Joint Classification & Segmentation with Weak Annotator , url =. 2021 IEEE Winter Conference on Applications of Computer Vision (WACV) , month =
2021
-
[32]
A framework of active learning and semi-supervised learning for lithology identification based on improved naive Bayes , volume =
Quan Ren and Hongbing Zhang and Dailu Zhang and Xiang Zhao and Lizhi Yan and Jianwen Rui and Fanxin Zeng and Xinyi Zhu , doi =. A framework of active learning and semi-supervised learning for lithology identification based on improved naive Bayes , volume =. Expert Systems with Applications , keywords =. 2022 , url=
2022
-
[33]
Active Learning for Improved Semi-Supervised Semantic Segmentation in Satellite Images , url =
Shasvat Desai and Debasmita Ghose , doi =. Active Learning for Improved Semi-Supervised Semantic Segmentation in Satellite Images , url =. 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , month =
2022
-
[34]
Journal of Field Robotics , keywords =
Alonso, I. Journal of Field Robotics , keywords =. 2019 , url=. doi:10.1002/rob.21915 , issn =
-
[35]
doi:10.1007/978-3-030-59710-8_2 , editor =
Lee, Hyeonsoo and Jeong, Won-Ki , booktitle =. doi:10.1007/978-3-030-59710-8_2 , editor =. arXiv , arxivId =:2006.12890 , isbn =
-
[36]
IEEE Transactions on Geoscience and Remote Sensing , volume=
Half a percent of labels is enough: Efficient animal detection in UAV imagery using deep CNNs and active learning , author=. IEEE Transactions on Geoscience and Remote Sensing , volume=. 2019 , doi=
2019
-
[37]
Learning Loss for Active Learning , url =
Donggeun Yoo and In So Kweon , doi =. Learning Loss for Active Learning , url =. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
2019
-
[38]
Dugger and Sen-Ching Cheung and Chen-Nee Chuah , doi =
Zhengfeng Lai and Chao Wang and Luca Cerny Oliveira and Brittany N. Dugger and Sen-Ching Cheung and Chen-Nee Chuah , doi =. Joint Semi-supervised and Active Learning for Segmentation of Gigapixel Pathology Images with Cost-Effective Labeling , url =. 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW) , month =
2021
-
[39]
Multiple Instance Active Learning for Object Detection , url =
Tianning Yuan and Fang Wan and Mengying Fu and Jianzhuang Liu and Songcen Xu and Xiangyang Ji and Qixiang Ye , doi =. Multiple Instance Active Learning for Object Detection , url =. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
2021
-
[40]
Integrating active learning and semi-supervised learning for improved data-driven HVAC fault diagnosis performance , volume =
Cheng Fan and Qiuting Wu and Yang Zhao and Like Mo , doi =. Integrating active learning and semi-supervised learning for improved data-driven HVAC fault diagnosis performance , volume =. Applied Energy , keywords =. 2024 , url=
2024
-
[41]
Think Twice Before Selection: Federated Evidential Active Learning for Medical Image Analysis with Domain Shifts , url =
Jiayi Chen and Benteng Ma and Hengfei Cui and Yong Xia , doi =. Think Twice Before Selection: Federated Evidential Active Learning for Medical Image Analysis with Domain Shifts , url =. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
2024
-
[42]
Active Learning for Single-Stage Object Detection in UAV Images , url =
Asma Yamani and Albandari Alyami and Hamzah Luqman and Bernard Ghanem and Silvio Giancola , doi =. Active Learning for Single-Stage Object Detection in UAV Images , url =. 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , month =
2024
-
[43]
2024 , eprint=
ESA: Annotation-Efficient Active Learning for Semantic Segmentation , author=. 2024 , eprint=
2024
-
[44]
EasySeg: An Error-Aware Domain Adaptation Framework for Remote Sensing Imagery Semantic Segmentation via Interactive Learning and Active Learning , volume =
Liangzhe Yang and Hao Chen and Anran Yang and Jun Li , doi =. EasySeg: An Error-Aware Domain Adaptation Framework for Remote Sensing Imagery Semantic Segmentation via Interactive Learning and Active Learning , volume =. IEEE Transactions on Geoscience and Remote Sensing , keywords =. 2024 , url=
2024
-
[45]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=
Bounding box-free instance segmentation using semi-supervised iterative learning for vehicle detection , author=. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=. 2022 , doi=
2022
-
[46]
de Carvalho, Osmar L. F. and de Carvalho Júnior, Osmar A. and de Albuquerque, Anesmar O. and Santana, Nickolas C. and Borges, Díbio L. , journal=. Rethinking Panoptic Segmentation in Remote Sensing: A Hybrid Approach Using Semantic Segmentation and Non-Learning Methods , year=. doi:10.1109/LGRS.2022.3172207 , url=
-
[47]
PANet: Few-Shot Image Semantic Segmentation With Prototype Alignment , year=
Wang, Kaixin and Liew, Jun Hao and Zou, Yingtian and Zhou, Daquan and Feng, Jiashi , booktitle=. PANet: Few-Shot Image Semantic Segmentation With Prototype Alignment , year=. doi:10.1109/ICCV.2019.00929 , url=
-
[48]
2021 , eprint=
Few-Shot Segmentation Without Meta-Learning: A Good Transductive Inference Is All You Need? , author=. 2021 , eprint=
2021
-
[49]
Lüddecke, Timo and Ecker, Alexander , booktitle=. Image Segmentation Using Text and Image Prompts , year=. doi:10.1109/CVPR52688.2022.00695 , url=
-
[50]
2023 , eprint=
Segment Everything Everywhere All at Once , author=. 2023 , eprint=
2023
-
[51]
2017 , eprint=
One-Shot Learning for Semantic Segmentation , author=. 2017 , eprint=
2017
-
[52]
HAL-IA: A Hybrid Active Learning framework using Interactive Annotation for medical image segmentation , volume =
Xiaokang Li and Menghua Xia and Jing Jiao and Shichong Zhou and Cai Chang and Yuanyuan Wang and Yi Guo , doi =. HAL-IA: A Hybrid Active Learning framework using Interactive Annotation for medical image segmentation , volume =. Medical Image Analysis , keywords =. 2023 , url=
2023
-
[53]
Cold-start active learning for image classification , volume =
Qiuye Jin and Mingzhi Yuan and Shiman Li and Haoran Wang and Manning Wang and Zhijian Song , doi =. Cold-start active learning for image classification , volume =. Information Sciences , keywords =. 2022 , url=
2022
-
[54]
Structured Sparse R-CNN for Direct Scene Graph Generation , year =
Teng, Yao and Wang, Limin , doi =. Structured Sparse R-CNN for Direct Scene Graph Generation , year =. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
2022
-
[55]
Semantic Segmentation with Active Semi-Supervised Learning , year =
Aneesh Rangnekar and Christopher Kanan and Matthew Hoffman , doi =. Semantic Segmentation with Active Semi-Supervised Learning , year =. 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , month =
2023
-
[56]
GitHub repository , Howpublished =
Pavel Iakubovskii , Title =. GitHub repository , Howpublished =. 2019 , Publisher =
2019
-
[57]
International Conference on Medical Image Computing and Computer-assisted Intervention , pages=
U-net: Convolutional networks for biomedical image segmentation , author=. International Conference on Medical Image Computing and Computer-assisted Intervention , pages=. 2015 , doi=
2015
-
[58]
Tan, Mingxing and Le, Quoc , booktitle =. 2019 , editor =. 1905.11946 , archivePrefix=
Pith/arXiv arXiv 2019
-
[59]
Tailornet: Predict- ing clothing in 3d as a function of human pose, shape and garment style
Siddiqui, Yawar and Valentin, Julien and Niessner, Matthias , booktitle=. ViewAL: Active Learning With Viewpoint Entropy for Semantic Segmentation , year=. doi:10.1109/CVPR42600.2020.00945 , url=
-
[60]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=
DIAL: Deep interactive and active learning for semantic segmentation in remote sensing , author=. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=. 2022 , doi=
2022
-
[61]
Simple Does It: Weakly Supervised Instance and Semantic Segmentation , year=
Khoreva, Anna and Benenson, Rodrigo and Hosang, Jan and Hein, Matthias and Schiele, Bernt , booktitle=. Simple Does It: Weakly Supervised Instance and Semantic Segmentation , year=
-
[62]
2018 , eprint=
CEREALS - Cost-Effective REgion-based Active Learning for Semantic Segmentation , author=. 2018 , eprint=
2018
-
[63]
2020 , eprint=
Pseudo-Labeling and Confirmation Bias in Deep Semi-Supervised Learning , author=. 2020 , eprint=
2020
-
[64]
2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , title=
Vu, Tuan-Hung and Jain, Himalaya and Bucher, Maxime and Cord, Matthieu and P. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , title=. 2019 , pages=. doi:10.1109/CVPR.2019.00262 , url=
-
[65]
Luo, Yawei and Zheng, Liang and Guan, Tao and Yu, Junqing and Yang, Yi , booktitle=. Taking a Closer Look at Domain Shift: Category-Level Adversaries for Semantics Consistent Domain Adaptation , year=. doi:10.1109/CVPR.2019.00261 , url=
-
[66]
2023 , eprint=
Iterative Loop Method Combining Active and Semi-supervised Learning for Domain Adaptive Semantic Segmentation , author=. 2023 , eprint=
2023
-
[67]
Wu, Tsung-Han and Liou, Yi-Syuan and Yuan, Shao-Ji and Lee, Hsin-Ying and Chen, Tung-I and Huang, Kuan-Chih and Hsu, Winston H. , booktitle=. 2022 , pages=. doi:10.1007/978-3-031-19818-2_26 , eprint=
-
[68]
Xie, Binhui and Yuan, Longhui and Li, Shuang and Liu, Chi Harold and Cheng, Xinjing , booktitle=. Towards Fewer Annotations: Active Learning via Region Impurity and Prediction Uncertainty for Domain Adaptive Semantic Segmentation , year=. doi:10.1109/CVPR52688.2022.00790 , url=
-
[69]
Ning, Munan and Lu, Donghuan and Xie, Yujia and Chen, Dongdong and Wei, Dong and Zheng, Yefeng and Tian, Yonghong and Yan, Shuicheng and Yuan, Li , journal=. 2023 , volume=. doi:10.1109/TPAMI.2023.3293893 , url=
-
[70]
de Carvalho, Osmar Luiz Ferreira and de Carvalho J. 2026 , publisher =. doi:10.5281/zenodo.20635237 , url =
-
[71]
de Carvalho, Osmar Luiz Ferreira , title =. 2026 , publisher =. doi:10.5281/zenodo.20596185 , url =
-
[72]
and Chen, Xiaojiang and Wang, Xin , title =
Ren, Pengzhen and Xiao, Yun and Chang, Xiaojun and Huang, Po-Yao and Li, Zhihui and Gupta, Brij B. and Chen, Xiaojiang and Wang, Xin , title =. 2021 , issue_date =. doi:10.1145/3472291 , journal =
-
[73]
International Journal of Applied Earth Observation and Geoinformation , volume=
The segment anything model (sam) for remote sensing applications: From zero to one shot , author=. International Journal of Applied Earth Observation and Geoinformation , volume=. 2023 , doi=
2023
-
[74]
ISPRS Journal of Photogrammetry and Remote Sensing , volume=
One class one click: Quasi scene-level weakly supervised point cloud semantic segmentation with active learning , author=. ISPRS Journal of Photogrammetry and Remote Sensing , volume=. 2023 , publisher=
2023
-
[75]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
Adaptive Superpixel for Active Learning in Semantic Segmentation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=. 2023 , eprint=
2023
-
[76]
2024 , publisher=
Li, Zihan and Zheng, Yuan and Shan, Dandan and Yang, Shuzhou and Li, Qingde and Wang, Beizhan and Zhang, Yuanting and Hong, Qingqi and Shen, Dinggang , journal=. 2024 , publisher=
2024
-
[77]
2025 , publisher=
Yang, Lihe and Zhao, Zhen and Zhao, Hengshuang , journal=. 2025 , publisher=
2025
-
[78]
AI Magazine , volume=
Power to the People: The Role of Humans in Interactive Machine Learning , author=. AI Magazine , volume=. 2014 , doi=
2014
-
[79]
Artificial Intelligence Review , volume=
Human-in-the-loop machine learning: a state of the art , author=. Artificial Intelligence Review , volume=. 2023 , publisher=
2023
-
[80]
Future Generation Computer Systems , volume=
A Survey of Human-in-the-loop for Machine Learning , author=. Future Generation Computer Systems , volume=. 2022 , publisher=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.