VArify: A Visual Analytics System for Verifying Knowledge Enhanced Large Language Model Responses in Food Science
Pith reviewed 2026-06-27 14:42 UTC · model grok-4.3
The pith
VArify's tree visualization lets users separate an LLM's internal knowledge from external graph evidence in food science responses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
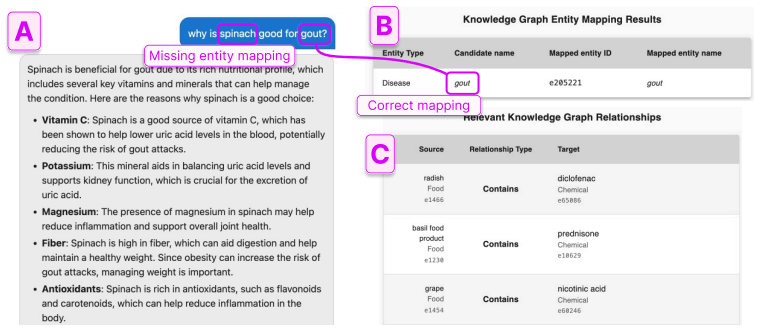
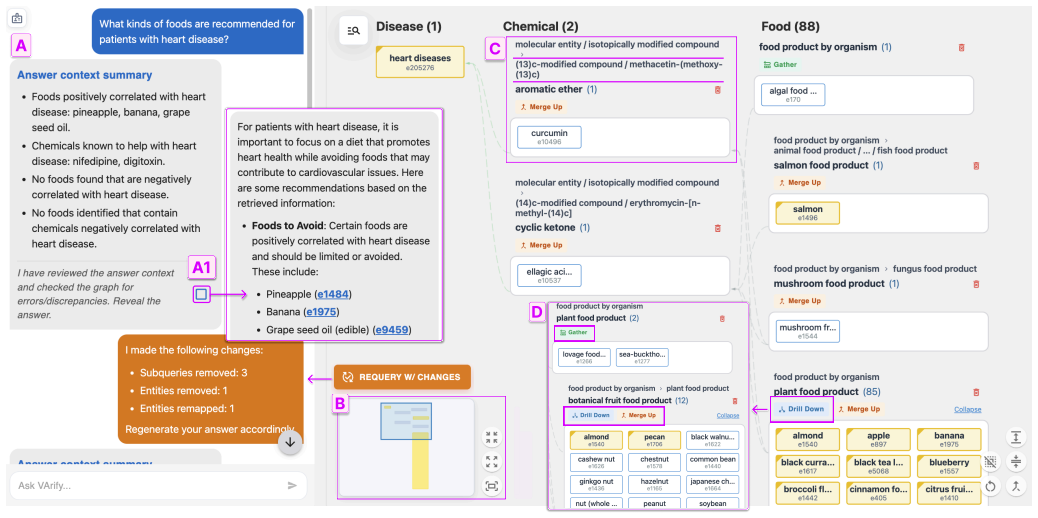
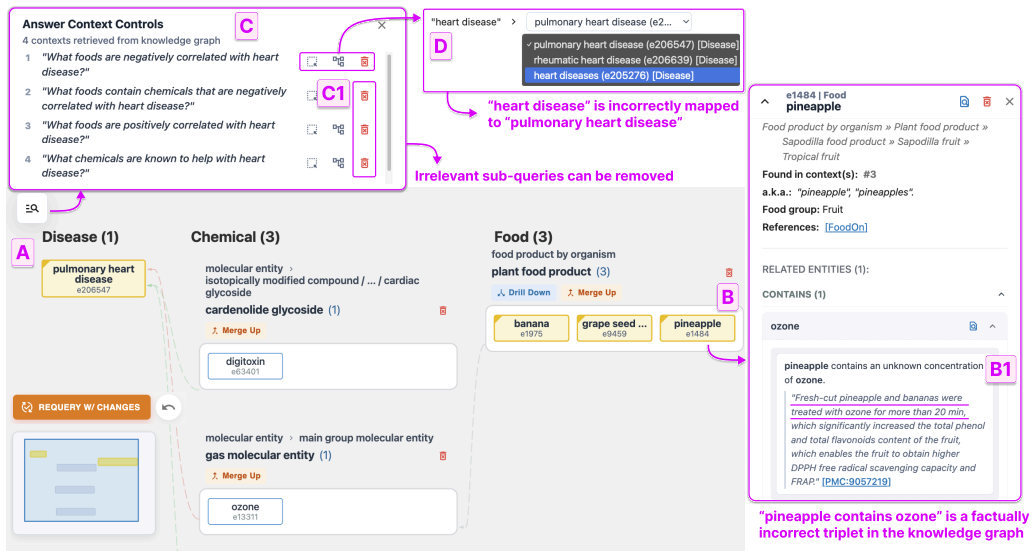
VArify provides a tree visualization that enables simultaneous exploration of inter-group relationships and intra-group hierarchies in retrieved evidence, allowing users to distinguish an LLM's internal parametric knowledge from external graph-sourced evidence and to identify inaccuracies within the underlying knowledge graph itself.
What carries the argument
The file directory-inspired tree visualization that supports simultaneous exploration of inter-group relationships and intra-group hierarchies within the retrieved evidence.
If this is right
- Users gain the ability to distinguish an LLM's internal parametric knowledge from external graph-sourced evidence.
- The visualization enables experts to identify inaccuracies inside the knowledge graph.
- Trust in the model's output becomes more calibrated after verification.
- Visualizations can be extended to address verification of unknown unknowns and knowledge-graph limitations.
Where Pith is reading between the lines
- The same tree structure could be tested in other evidence-heavy fields such as medicine or law to check GraphRAG outputs.
- Direct editing of flagged graph errors from within the interface would turn verification into a feedback loop for improving the source graph.
- The approach may reduce over-trust in LLM answers when the underlying knowledge graph contains domain-specific gaps.
Load-bearing premise
Insights from an unspecified pilot study and a user study with only six experts are representative enough to show that the tree visualization solves verification challenges for GraphRAG systems in general.
What would settle it
A follow-up study in which experts using VArify still cannot reliably separate model knowledge from graph evidence or fail to detect known graph inaccuracies would show the visualization does not deliver the claimed benefits.
Figures


read the original abstract
Graph Retrieval-Augmented Generation (GraphRAG) enables Large Language Models (LLMs) to leverage structured, domain-specific knowledge graph databases for factually grounded responses. However, the retrieval of irrelevant or conflicting data can still result in erroneous responses. In knowledge-intensive and evidence-focused domains, human verification of the supporting evidence for an LLM response is still necessary. We conducted a formative pilot study to characterize the challenges of verifying complex, multi-layered data retrieved by GraphRAG systems. Based on these insights, we present VArify, a visual analytics system that leverages a file directory-inspired tree visualization to support simultaneous exploration of inter-group relationships and intra-group hierarchies within the retrieved evidence. We evaluate VArify through a user study with six food science experts and students. Our results indicate that the system effectively helps users distinguish between an LLM's internal parametric knowledge and external graph-sourced evidence. Furthermore, the visualization helped experts identify inaccuracies within the underlying knowledge graph itself, leading to more calibrated trust in the model's output. We conclude by discussing opportunities to leverage visualizations to further support verification regarding unknown unknowns, personalization, and limitations of knowledge graphs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VArify, a visual analytics system for verifying GraphRAG-augmented LLM responses in food science. It describes a formative pilot study to identify verification challenges with complex retrieved evidence, presents a file directory-inspired tree visualization to support exploration of inter-group relationships and intra-group hierarchies, and reports results from a user study with six food science experts and students. The central claims are that the system helps users distinguish LLM parametric knowledge from external graph-sourced evidence, enables identification of inaccuracies in the underlying knowledge graph, and leads to more calibrated trust in model outputs.
Significance. If the results hold, the work could advance visual analytics approaches for human verification of knowledge-enhanced LLM outputs in evidence-focused domains. The tree visualization for handling hierarchical and relational evidence from graphs represents a targeted interface contribution. The paper does not ship machine-checked proofs or reproducible code, but the domain-expert qualitative insights provide a starting point for interface design in this area.
major comments (2)
- [User Study] User Study section (and abstract): The claims that the system 'effectively helps users distinguish between an LLM's internal parametric knowledge and external graph-sourced evidence' and leads to 'more calibrated trust' rest on qualitative feedback from only six participants. No quantitative metrics, statistical tests, error bars, or baseline comparisons are described, rendering the evidence for effectiveness anecdotal and insufficient to support the strength of the conclusions.
- [Formative Pilot Study] Formative Pilot Study (abstract and introduction): The pilot study that drove the design requirements is described only as having been conducted, with no details on participant count, protocol, or how its insights were validated as representative. This makes it difficult to assess whether the tree visualization directly addresses general verification challenges rather than study-specific observations.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on our manuscript. We address each major comment below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [User Study] User Study section (and abstract): The claims that the system 'effectively helps users distinguish between an LLM's internal parametric knowledge and external graph-sourced evidence' and leads to 'more calibrated trust' rest on qualitative feedback from only six participants. No quantitative metrics, statistical tests, error bars, or baseline comparisons are described, rendering the evidence for effectiveness anecdotal and insufficient to support the strength of the conclusions.
Authors: We agree that the evaluation is based on a small qualitative user study with six domain experts, which is typical for initial visual analytics systems in HCI to gain rich insights rather than generalizable quantitative results. The study aimed to gather expert feedback on the system's utility rather than measure performance metrics. However, we recognize that the claims in the abstract and conclusion could be strengthened by more cautious language. We will revise the abstract, results, and discussion sections to explicitly state that the findings are qualitative and exploratory, add a dedicated limitations section discussing the small sample size and lack of quantitative measures, and avoid overgeneralizing the effectiveness. revision: partial
-
Referee: [Formative Pilot Study] Formative Pilot Study (abstract and introduction): The pilot study that drove the design requirements is described only as having been conducted, with no details on participant count, protocol, or how its insights were validated as representative. This makes it difficult to assess whether the tree visualization directly addresses general verification challenges rather than study-specific observations.
Authors: We will provide additional details on the formative pilot study, including the number of participants, their backgrounds, the study protocol, and how the insights were analyzed and used to derive the design requirements. This will be added to the introduction and a new methods subsection. revision: yes
Circularity Check
No circularity: systems paper with user-study evaluation contains no derivations or fitted predictions
full rationale
The paper is a visual analytics systems description whose central claims rest on a formative pilot and a qualitative user study with six participants. No equations, parameters, first-principles derivations, or statistical predictions appear in the provided text. The evaluation results are presented as direct observations from participant feedback rather than outputs that reduce to the design inputs by construction. Self-citations are absent from the load-bearing sections, and the methodology does not invoke uniqueness theorems or ansatzes from prior author work. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. Beigi, S. Wang, Y . Shen, Z. Lin, A. Kulkarni, J. He et al. Rethinking the uncertainty: A critical review and analysis in the era of Large Language Models, 2024. doi: 10.48550/arXiv.2410.20199 8
-
[2]
S. Bjork, L. Holmquist, and J. Redstrom. A framework for focus+context visualization. InProceedings 1999 IEEE Symposium on Information Visualization (InfoVis’99), pp. 53–56, 1999. doi: 10.1109/INFVIS.1999. 801857 5
-
[3]
Z. Buçinca, M. B. Malaya, and K. Z. Gajos. To trust or to think: Cog- nitive forcing functions can reduce overreliance on AI in AI-assisted decision-making.Proceedings of the ACM on Human-Computer Interac- tion, 5(CSCW1):1–21, Apr. 2021. doi: 10.1145/3449287 2, 4, 8
work page internal anchor Pith review doi:10.1145/3449287 2021
-
[4]
V . Danry, P. Pataranutaporn, M. Groh, and Z. Epstein. Deceptive Expla- nations by Large Language Models Lead People to Change their Beliefs About Misinformation More Often than Honest Explanations. InPro- ceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI ’25, pp. 1–31. Association for Computing Machinery, New York, NY , USA, ...
-
[5]
M. E. Deagen, J. P. McCusker, T. Fateye, S. C. Rashid, S. Stingel, R. Yan et al. FAIR and interactive data graphics from a scientific knowledge graph.Scientific Data, 9(1):239, 2022. doi: 10.1038/s41597-022-01352-z 2
-
[6]
Digital education council AI literacy frame- work
Digital Education Council. Digital education council AI literacy frame- work. Online, 2025. 1, 2
2025
-
[7]
It makes you think
I. Drosos, A. Sarkar, Xiaotong, Xu, and N. Toronto. "It makes you think": Provocations help restore critical thinking to AI-assisted knowledge work,
-
[8]
doi: 10.48550/arXiv.2501.17247 2
-
[9]
D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody et al. From local to global: A graph RAG approach to query-focused summarization,
-
[10]
doi: 10.48550/arXiv.2404.16130 1
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.16130
-
[11]
Regulation (eu) 2024/1689 of the european parliament and of the council laying down harmonised rules on artificial intelligence (Artificial Intelligence Act)
European Union. Regulation (eu) 2024/1689 of the european parliament and of the council laying down harmonised rules on artificial intelligence (Artificial Intelligence Act). https: //op.europa.eu/en/publication-detail/-/publication/ d79f3e5d-41bc-11f0-b9f2-01aa75ed71a1 , 2024. Published in the Official Journal of the European Union, 12 July 2024. doi: 10...
2024
-
[12]
W. Fan, Y . Ding, L. Ning, S. Wang, H. Li, D. Yin et al. A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’24, pp. 6491–6501. Association for Computing Machinery, New York, NY , USA, Aug. 2024. doi: 10.1145/ 3637528.3671470 1
arXiv 2024
-
[13]
J. Heer. Agency plus automation: Designing artificial intelligence into interactive systems.Proceedings of the National Academy of Sciences, 116(6):1844–1850, 2019. doi: 10.1073/pnas.1807184115 2
-
[14]
C.-W. Hsuan Yuan, T.-W. Yu, J.-Y . Pan, and W.-C. Lin. KGScope: In- teractive visual exploration of knowledge graphs with embedding-based guidance.IEEE Transactions on Visualization and Computer Graphics, 30(12):7702–7716, 2024. doi: 10.1109/TVCG.2024.3360690 2
-
[15]
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang et al. A survey on hallucination in Large Language Models: Principles, taxonomy, chal- lenges, and open questions.ACM Trans. Inf. Syst., 43(2), art. no. 42, 55 pages, 2025. doi: 10.1145/3703155 1
-
[16]
S. Ji, S. Pan, E. Cambria, P. Marttinen, and P. S. Yu. A survey on knowl- edge graphs: Representation, acquisition, and applications.IEEE Trans- actions on Neural Networks and Learning Systems, 33(2):494–514, 2022. doi: 10.1109/TNNLS.2021.3070843 1
-
[17]
H. Jiang, S. Shi, Y . Yao, C. Jiang, and Q. Li. HypoChainer: A collaborative system combining LLMs and knowledge graphs for hypothesis-driven scientific discovery.IEEE Transactions on Visualization and Computer Graphics, 32(1):298–308, 2026. doi: 10.1109/TVCG.2025.3633887 2
-
[18]
Kahneman.Thinking, Fast and Slow
D. Kahneman.Thinking, Fast and Slow. Farrar, Straus and Giroux, New York, 2011. 8
2011
-
[19]
Karpukhin, B
V . Karpukhin, B. O˘guz, S. Min, P. Lewis, L. Wu, S. Edunov et al. Dense passage retrieval for open-domain question answering, 2020. 1
2020
-
[20]
S. S. Y . Kim, Q. V . Liao, M. V orvoreanu, S. Ballard, and J. W. Vaughan. "I’m not sure, but...": Examining the impact of large language models’ uncertainty expression on user reliance and trust. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’24), pp. 822–835, 2024. doi: 10.1145/3630106.3658941 2
-
[21]
S. S. Y . Kim, J. W. Vaughan, Q. V . Liao, T. Lombrozo, and O. Russakovsky. Fostering appropriate reliance on large language models: The role of explanations, sources, and inconsistencies. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25), art. no. 420, 19 pages, 2025. doi: 10.1145/3706598.3714020 1, 2
-
[22]
T. S. Kim, Y . Lee, J. Shin, Y .-H. Kim, and J. Kim. EvalLM: Interactive evaluation of large language model prompts on user-defined criteria. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI’24), art. no. 306, 21 pages, 2024. doi: 10.1145/3613904. 3642216 2
-
[23]
LangGraph
LangChain-AI. LangGraph. Accessed: 2026-03-31. 3
2026
-
[24]
H.-P. H. Lee, A. Sarkar, L. Tankelevitch, I. Drosos, S. Rintel, R. Banks et al. The impact of generative AI on critical thinking: Self-reported reductions in cognitive effort and confidence effects from a survey of knowledge workers. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25), CHI ’25, art. no. 1121, 22 pages,...
-
[25]
In: Advances in Neural Information Processing Systems
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NIPS ’20), art. no. 793, 16 pages. Curran Associates Inc., 2020. doi: doi/abs/10.5555/3495724.3496517 1
-
[26]
H. Li, G. Appleby, K. Alperin, S. R. Gomez, and A. Suh. The Role of Visualization in LLM-Assisted Knowledge Graph Systems: Effects on User Trust, Exploration, and Workflows, May 2025. doi: 10.48550/arXiv. 2505.21512 2, 3, 4
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[27]
H. Li, G. Appleby, C. D. Brumar, R. Chang, and A. Suh. Knowledge Graphs in Practice: Characterizing their Users, Challenges, and Visual- ization Opportunities.IEEE Transactions on Visualization and Computer Graphics, 30(1):584–594, Jan. 2024. doi: 10.1109/TVCG.2023.3326904 4
-
[28]
H. Li, G. Appleby, and A. Suh. LinkQ: An LLM-assisted visual interface for knowledge graph question-answering. In2024 IEEE Visualization and Visual Analytics (VIS), pp. 116–120, 2024. doi: 10.1109/VIS55277.2024. 00031 2
-
[29]
H. Li, G. Appleby, and A. Suh. A Preliminary Roadmap for LLMs as Assistants in Exploring, Analyzing, and Visualizing Knowledge Graphs, Apr. 2024. doi: 10.48550/arXiv.2404.01425 2
-
[30]
Lissandrini, D
M. Lissandrini, D. Mottin, K. Hose, and T. Pedersen. Knowledge graph exploration systems: Are we lost? InProceedings of the 12th Conference on Innovative Data Systems Research, Jan. 2022. 2, 9
2022
-
[31]
L. Mei, J. Yao, Y . Ge, Y . Wang, B. Bi, Y . Cai et al. A survey of context engineering for Large Language Models, 2025. doi: 10.48550/arXiv.2507 .13334 1, 2
-
[32]
A. Mertsiotaki, S. Hofmann, S. Keck, E. Kratsch, A. Daum, and B. Popp. Designing usable interfaces for human evaluation of LLM-generated texts: UX challenges and solutions. InInternational Joint Conference on Artifi- cial Intelligence 2025, 2025. doi: 10.24406/publica-4219 2
-
[33]
Y . Mou, L. Liu, S. Sowe, D. Collarana, and S. Decker. Leveraging LLMs few-shot learning to improve instruction-driven knowledge graph construction.Proceedings of the VLDB Endowment, 2024. 9
2024
-
[34]
R. Nararatwong, N. Kertkeidkachorn, and R. Ichise. Knowledge graph visualization: Challenges, framework, and implementation. In2020 IEEE Third International Conference on Artificial Intelligence and Knowledge Engineering (AIKE), pp. 174–178, 2020. doi: 10.1109/AIKE48582.2020. 00034 2
-
[35]
OpenAI API
OpenAI. OpenAI API. https://platform.openai.com, 2024. Ac- cessed: 2026-03-31. 3
2024
-
[36]
S. Ott, P. Betz, D. Stepanova, M. H. Gad-Elrab, C. Meilicke, and H. Stuck- enschmidt. Rule-based knowledge graph completion with canonical mod- els. InProceedings of the 32nd ACM International Conference on Infor- mation and Knowledge Management (CIKM ’23), pp. 1971–1981, 2023. doi: 10.1145/3583780.3615042 9
-
[37]
L. Padilla, M. Kay, and J. Hullman.Uncertainty Visualization, pp. 1–18. John Wiley & Sons, Ltd, 2021. doi: 10.1002/9781118445112.stat08296 8
-
[38]
Passi, S
S. Passi, S. Dhanorkar, and M. V orvoreanu. Appropriate reliance on generative AI: Research synthesis. Technical Report MSR-TR-2024-7, Microsoft, March 2024. 2, 3
2024
-
[39]
Passi, S
S. Passi, S. Dhanorkar, and M. V orvoreanu.Addressing Overreliance on AI, pp. 1–34. Springer Nature Singapore, Singapore, 2025. doi: 10. 1007/978-981-97-8440-0_98-1 1, 2, 8
2025
-
[40]
B. Peng, Y . Zhu, Y . Liu, X. Bo, H. Shi, C. Hong et al. Graph Retrieval- Augmented Generation: A Survey, Sept. 2024. doi: 10.48550/arXiv.2408. 08921 1
-
[41]
R. Qiu, Y . Tu, P.-Y . Yen, and H.-W. Shen. V ADIS: A visual analytics pipeline for dynamic document representation and information-seeking. IEEE Transactions on Visualization and Computer Graphics, 31(1):1312– 1321, 2025. doi: 10.1109/TVCG.2024.3456339 9
-
[42]
A. Salemi and H. Zamani. Evaluating retrieval quality in retrieval- augmented generation, 2024. doi: arXiv:2404.13781 1
arXiv 2024
-
[43]
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
P. Sarthi, S. Abdullah, A. Tuli, S. Khanna, A. Goldie, and C. D. Manning. RAPTOR: Recursive abstractive processing for tree-organized retrieval. In The Twelfth International Conference on Learning Representations, 2024. doi: 10.48550/arXiv.2401.18059 9
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.18059 2024
-
[44]
A. Soylu, E. Kharlamov, D. Zheleznyakov, E. Jimenez-Ruiz, M. Giese, M. G. Skjæveland et al. OptiqueVQS: A visual query system over ontolo- gies for industry.Semantic Web, 9(5):627–660, 2018. doi: 10.3233/SW -180293 2
work page doi:10.3233/sw 2018
-
[45]
R. H. Thaler and C. R. Sunstein.Nudge: Improving Decisions About Health, Wealth, and Happiness. Yale University Press, New Haven, 2008. 8
2008
-
[46]
Y . Tu, R. Qiu, and H.-W. Shen. KG-PRE-view: Democratizing a TVCG knowledge graph through visual explorations. In2024 IEEE 17th Pacific Visualization Conference (PacificVis), pp. 162–171, 2024. doi: 10.1109/ PacificVis60374.2024.00026 2
arXiv 2024
-
[47]
Vargas, C
H. Vargas, C. Buil-Aranda, A. Hogan, and C. López. RDF explorer: A visual SPARQL query builder. InThe Semantic Web – ISWC 2019, pp. 647–663. Springer International Publishing, Cham, 2019. doi: 10. 1007/978-3-030-30793-6_37 2
2019
-
[48]
Z. Wang, Z. Wang, L. Le, S. Zheng, S. Mishra, V . Perot et al. Speculative RAG: Enhancing retrieval augmented generation through drafting. InThe Thirteenth International Conference on Learning Representations, 2025. doi: 10.48550/arXiv.2407.08223 9
-
[49]
J. Wei, S. Han, and L. Zou. VISION-KG: Topic-centric visualization system for summarizing knowledge graph. InProceedings of the 13th International Conference on Web Search and Data Mining (WSDM ’20), pp. 857–860. ACM, 2020. doi: 10.1145/3336191.3371863 2
-
[50]
T. L. Wingerter, T. Straub, and S. Schweitzer. Mitigating automation bias in generative AI through nudges: A cognitive reflection test study.Procedia Computer Science, 270:2106–2114, 2025. 29th International Conference on Knowledge-Based and Intelligent Information & Engineering Systems (KES 2025). doi: 10.1016/j.procs.2025.09.331 8
-
[51]
J. Wu, J. Zhu, Y . Qi, J. Chen, M. Xu, F. Menolascina et al. Medical graph RAG: Towards safe medical large language model via graph retrieval- augmented generation, 2024. doi: 10.48550/arXiv.2408.04187 1
-
[52]
J. Youn, F. Li, G. Simmons, S. Kim, and I. Tagkopoulos. FoodAtlas: Automated knowledge extraction of food and chemicals from literature. Computers in Biology and Medicine, 181:109072, 2024. doi: 10.1016/j. compbiomed.2024.109072 1, 2
work page doi:10.1016/j 2024
-
[53]
H. Yu, A. Gan, K. Zhang, S. Tong, Q. Liu, and Z. Liu.Evaluation of Retrieval-Augmented Generation: A Survey, pp. 102–120. Springer Nature Singapore, 2025. doi: 10.1007/978-981-96-1024-2_8 1
-
[54]
J. Zamfirescu-Pereira, R. Y . Wong, B. Hartmann, and Q. Yang. Why johnny can’t prompt: How non-AI experts try (and fail) to design LLM prompts. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23), art. no. 437, 21 pages, 2023. doi: 10. 1145/3544548.3581388 2
arXiv 2023
-
[55]
H. Zhai. Law GraphRAG: An advanced legal question-answering sys- tem. In2025 5th International Conference on Artificial Intelligence and Industrial Technology Applications (AIITA), pp. 1407–1410, 2025. doi: 10 .1109/AIITA65135.2025.11047851 1
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.