Leveraging Machine-Learned Advice in Strategic Interactions with No-Regret Learners
Pith reviewed 2026-06-27 11:33 UTC · model grok-4.3
The pith
A player cannot guarantee both near-Stackelberg performance from good advice and no-regret behavior from bad advice against a no-regret learner.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In general, a player cannot simultaneously guarantee near Stackelberg performance when the advice is approximately accurate and a no-regret condition when the advice is inaccurate. It is possible, however, for an advice-aided player to weakly dominate their utility in some (coarse)-correlated equilibria.
What carries the argument
A pseudo-metric on advice instances that quantifies their usefulness for achieving Stackelberg-like performance against no-regret dynamics.
If this is right
- Simulators equipped with correctness guarantees let the advice-aided player compute approximate Stackelberg strategies using substantially fewer rounds than standard methods.
- Payoff-matrix predictions with accuracy guarantees improve the advice-aided player's outcomes when the advice is reliable.
- An advice-aided player can still obtain utilities that weakly dominate those of certain coarse correlated equilibria even without advice guarantees.
Where Pith is reading between the lines
- Learning algorithms may need explicit safeguards against opponents who receive external advice sources.
- Advice mechanisms could be designed to detect inaccuracy and switch to no-regret behavior automatically.
- The same trade-off between performance and regret may appear when more than two players interact or when different no-regret algorithms are used.
Load-bearing premise
The opponent follows a no-regret learning algorithm throughout the entire repeated interaction.
What would settle it
A concrete repeated game together with an advice instance in which the advice-aided player simultaneously achieves near-Stackelberg payoff when the advice is accurate and no-regret behavior when the advice is inaccurate.
Figures
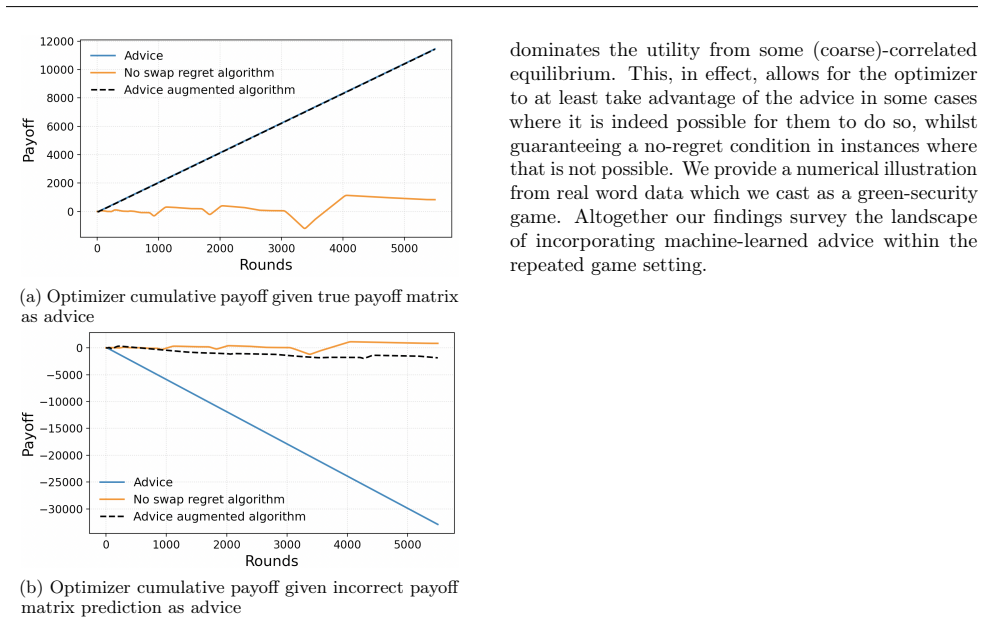
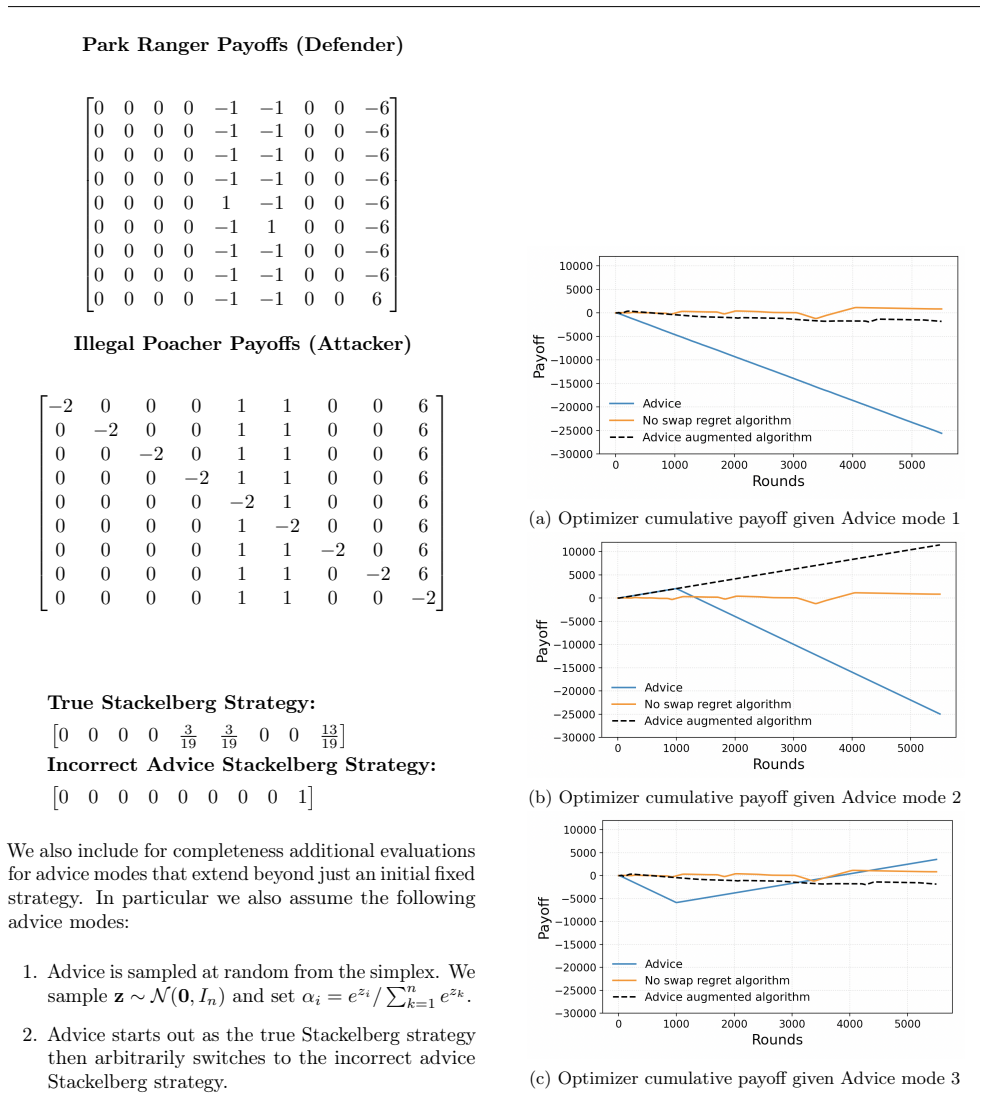
read the original abstract
We study how an agent in a two-player repeated game can effectively utilize potentially imperfect advice when interacting with a no-regret learner. We characterize the advice landscape by introducing a pseudo-metric to quantify the usefulness of an advice instance. We demonstrate the pseudo-metric's applicability through two forms of advice: simulators and payoff matrix predictions. We then show how an optimizing player, equipped with correctness guarantees on the advice, could leverage simulators to compute approximate Stackelberg strategies more efficiently, reducing the interaction complexity traditionally required and illustrating the power of good advice. Finally, we extend our analysis to settings where the advice does not have any guarantee of correctness. We find that, in general, a player cannot simultaneously guarantee near Stackelberg performance when the advice is approximately accurate and a no-regret condition when the advice is inaccurate. We do show, however, that it is possible for an advice-aided player to weakly dominate their utility in some (coarse)-correlated equilibria.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies an agent in a two-player repeated game that can use potentially imperfect machine-learned advice when facing a no-regret learner. It introduces a pseudo-metric on advice instances to characterize usefulness, applies the metric to two concrete forms (simulators and payoff-matrix predictions), shows that correct advice allows efficient computation of approximate Stackelberg strategies, proves a general impossibility result that near-Stackelberg performance (under accurate advice) cannot be simultaneously guaranteed with a no-regret guarantee (under inaccurate advice), and establishes a positive result that an advice-aided player can weakly dominate its utility in certain coarse-correlated equilibria.
Significance. If the central claims hold, the work supplies a precise language (via the pseudo-metric) for reasoning about advice quality in strategic learning settings and cleanly separates the regimes in which reliable advice is helpful from those in which it creates unavoidable trade-offs. The impossibility result and the weak-dominance construction in CCE are the most load-bearing contributions; together they delineate both the limits and the safe uses of advice against no-regret opponents.
major comments (2)
- [impossibility result section] The impossibility statement (abstract and the section extending the analysis to advice without correctness guarantees) is stated at a high level; the precise statement should make explicit whether the no-regret condition must hold for every possible advice instance or only for instances whose pseudo-metric distance exceeds a given threshold, and whether the Stackelberg approximation is with respect to the same pseudo-metric.
- [positive result on CCE] The positive weak-dominance result in (coarse) correlated equilibria should specify the equilibrium selection criterion and whether the dominance holds only in expectation or pathwise; without this, it is unclear how the result interfaces with the no-regret dynamics of the second player.
minor comments (2)
- [advice landscape characterization] The pseudo-metric is introduced without an explicit statement of the triangle inequality or symmetry properties that are actually used in the subsequent arguments; adding a short lemma verifying the metric axioms would improve readability.
- [applications of the pseudo-metric] Notation for the two advice forms (simulators vs. payoff predictions) should be unified so that the same pseudo-metric distance symbol is used for both, or the distinction should be made explicit in every theorem statement that applies to only one form.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our results. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [impossibility result section] The impossibility statement (abstract and the section extending the analysis to advice without correctness guarantees) is stated at a high level; the precise statement should make explicit whether the no-regret condition must hold for every possible advice instance or only for instances whose pseudo-metric distance exceeds a given threshold, and whether the Stackelberg approximation is with respect to the same pseudo-metric.
Authors: We agree the statement would benefit from greater precision. The intended claim is that no-regret cannot be guaranteed simultaneously with near-Stackelberg performance when the advice instance is inaccurate (pseudo-metric distance above a threshold), while near-Stackelberg holds under accurate advice (distance below threshold). The approximation is taken with respect to the same pseudo-metric. We will revise both the abstract and the relevant section to state the conditions explicitly in terms of the pseudo-metric thresholds. revision: yes
-
Referee: [positive result on CCE] The positive weak-dominance result in (coarse) correlated equilibria should specify the equilibrium selection criterion and whether the dominance holds only in expectation or pathwise; without this, it is unclear how the result interfaces with the no-regret dynamics of the second player.
Authors: We will clarify that the weak dominance is with respect to the player's expected utility under a coarse correlated equilibrium that is inducible by the advice-aided strategy when the opponent follows no-regret dynamics. The result holds in expectation (consistent with the average-payoff guarantees of no-regret learning) rather than pathwise. The equilibrium selection is any CCE that can be realized as the empirical distribution of play under the advice-aided strategy against a no-regret opponent. We will add this specification to the relevant section. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces a pseudo-metric on advice instances as a new definition to characterize usefulness, then derives impossibility and dominance results from the standard repeated-game setup with a no-regret opponent. These steps rely on explicit game-theoretic definitions and standard no-regret properties rather than reducing any claimed prediction or theorem to a fitted parameter or self-citation chain. The two advice forms (simulators, payoff predictions) are analyzed as applications of the metric, not as inputs that force the main theorems. The central impossibility (near-Stackelberg + no-regret incompatibility) and weak-dominance result in CCE follow directly from the interaction model without circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The opponent follows a no-regret learning algorithm in the repeated game.
invented entities (1)
-
pseudo-metric on advice instances
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 35th International Conference on Machine Learning , pages =
Dynamic Regret of Strongly Adaptive Methods , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[2]
, year =
Hazan, Elad and Seshadhri, C. , year =. Adaptive Algorithms for Online Decision Problems. , volume =
-
[3]
Proceedings of the 26th ACM Conference on Economics and Computation , pages =
Arunachaleswaran, Eshwar Ram and Collina, Natalie and Schneider, Jon , title =. Proceedings of the 26th ACM Conference on Economics and Computation , pages =. 2025 , isbn =
2025
-
[4]
Balcan, Maria-Florina and Blum, Avrim and Mansour, Yishay , title =. SIAM J. Comput. , month = jan, pages =. 2013 , issue_date =
2013
-
[6]
Improved equilibria via public service advertising
Balcan, Maria Florina and Avrim Blum and Yishay Mansour. Improved equilibria via public service advertising. Proceedings of the 20th Annual ACM-SIAM Symposium on Discrete Algorithms. 2009
2009
-
[7]
Neural Information Processing Systems , year=
Strategizing against No-regret Learners , author=. Neural Information Processing Systems , year=
-
[8]
American Economic Review , volume=
Predicting and understanding initial play , author=. American Economic Review , volume=. 2019 , publisher=
2019
-
[9]
Advances in Neural Information Processing Systems , volume=
Model-based opponent modeling , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Advances in Neural Information Processing Systems , volume=
Autobidder's Dilemma: Why More Sophisticated Autobidders Lead to Worse Auction Efficiency , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Review of industrial organization , volume=
Spectrum auction design , author=. Review of industrial organization , volume=. 2013 , publisher=
2013
-
[12]
Advances in Neural Information Processing Systems , volume=
Eai: Emotional decision-making of llms in strategic games and ethical dilemmas , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
LLM-Based Explicit Models of Opponents for Multi-Agent Games , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[14]
Proceedings of the AAAI conference on artificial intelligence , volume=
Multi-step reinforcement learning: A unifying algorithm , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[15]
2006 , publisher=
Prediction, Learning, and Games , author=. 2006 , publisher=
2006
-
[16]
Advances in Neural Information Processing Systems , volume=
Large language models play starcraft ii: Benchmarks and a chain of summarization approach , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Safe Exploitative Play with Untrusted Type Beliefs , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[18]
International Conference on Machine Learning , pages=
The mechanics of n-player differentiable games , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[19]
Econometrica , volume=
A simple adaptive procedure leading to correlated equilibrium , author=. Econometrica , volume=. 2000 , publisher=
2000
-
[20]
, author=
From external to internal regret. , author=. Journal of Machine Learning Research , volume=
-
[21]
Journal of Optimization Theory and Applications , volume=
On the Stackelberg strategy in nonzero-sum games , author=. Journal of Optimization Theory and Applications , volume=. 1973 , publisher=
1973
-
[22]
Games and Economic Behavior , volume=
Adaptive game playing using multiplicative weights , author=. Games and Economic Behavior , volume=. 1999 , publisher=
1999
-
[23]
nature , volume=
Mastering the game of Go with deep neural networks and tree search , author=. nature , volume=. 2016 , publisher=
2016
-
[24]
2008 , publisher=
Essentials of game theory: A concise multidisciplinary introduction , author=. 2008 , publisher=
2008
-
[25]
Learning and equilibrium , author=. Annu. Rev. Econ. , volume=. 2009 , publisher=
2009
-
[26]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Can Large Language Model Agents Simulate Human Trust Behavior? , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[27]
Advances in Neural Information Processing Systems , volume=
GUIDE: Real-time human-shaped agents , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
2005 , institution=
The Multiplicative Weights Update Method: A Meta-Algorithm and Applications , author=. 2005 , institution=
2005
-
[30]
2023 , eprint=
Is Learning in Games Good for the Learners? , author=. 2023 , eprint=
2023
-
[31]
Proceedings of the 7th ACM Conference on Electronic Commerce , pages =
Conitzer, Vincent and Sandholm, Tuomas , title =. Proceedings of the 7th ACM Conference on Electronic Commerce , pages =. 2006 , isbn =. doi:10.1145/1134707.1134717 , abstract =
-
[32]
Algorithmic Game Theory , year=
Learning and Approximating the Optimal Strategy to Commit To , author=. Algorithmic Game Theory , year=
-
[33]
Langley , title =
P. Langley , title =. 2000 , booktitle =
2000
-
[34]
2011 , url =
Credit Fusion, Will Cukierski , title =. 2011 , url =
2011
-
[35]
doi:10.5281/zenodo.3875775 , url =
John Miller and Chloe Hsu and Jordan Troutman and Juan Perdomo and Tijana Zrnic and Lydia Liu and Yu Sun and Ludwig Schmidt and Moritz Hardt , title =. doi:10.5281/zenodo.3875775 , url =
-
[36]
Degenerate Feedback Loops in Recommender Systems , url=
Jiang, Ray and Chiappa, Silvia and Lattimore, Tor and György, András and Kohli, Pushmeet , year=. Degenerate Feedback Loops in Recommender Systems , url=. doi:10.1145/3306618.3314288 , booktitle=
-
[37]
2023 , eprint=
How is ChatGPT's behavior changing over time? , author=. 2023 , eprint=
2023
-
[38]
Inefficiency of Nash Equilibria , volume =
Pradeep Dubey , journal =. Inefficiency of Nash Equilibria , volume =
-
[39]
, title =
Hu, Junling and Wellman, Michael P. , title =. J. Mach. Learn. Res. , month =. 2003 , issue_date =
2003
-
[40]
Decision Support Systems , author =
Employees recruitment:. Decision Support Systems , author =. 2020 , pages =
2020
-
[41]
1999 , author =
Dynamic noncooperative game theory: second edition , publisher =. 1999 , author =
1999
-
[42]
Informational properties of the Nash solutions of two stochastic nonzero-sum games , volume =
Tamer Basar and Yu-Chi Ho , journal =. Informational properties of the Nash solutions of two stochastic nonzero-sum games , volume =
-
[43]
The Eleventh International Conference on Learning Representations , year=
Scaling Laws for a Multi-Agent Reinforcement Learning Model , author=. The Eleventh International Conference on Learning Representations , year=
-
[44]
Machine Learning with Applications , author =
Chatbots:. Machine Learning with Applications , author =
-
[45]
Big Data & Society , volume =
Robert Gorwa and Reuben Binns and Christian Katzenbach , title =. Big Data & Society , volume =
-
[46]
and AL Shawabkeh, Tahani and Salameh, Walid A
Mahmoud, Ali A. and AL Shawabkeh, Tahani and Salameh, Walid A. and Al Amro, Ibrahim , booktitle=. Performance Predicting in Hiring Process and Performance Appraisals Using Machine Learning , year=
-
[47]
Proceeding of the 31st Conference on Neural Information Processing Systems (NIPS 2017) , year=
Best Response Regression , author=. Proceeding of the 31st Conference on Neural Information Processing Systems (NIPS 2017) , year=
2017
-
[48]
The Gig Economy: A Critical Introduction , author=
-
[49]
Proceedings of the 37th International Conference on Machine Learning , pages =
Performative Prediction , author =. Proceedings of the 37th International Conference on Machine Learning , pages =
-
[50]
and Sastry, S
Mazumdar, Eric and Ratliff, Lillian J. and Sastry, S. Shankar , journal =. On Gradient-Based Learning in Continuous Games , volume =
-
[51]
1998 , author =
The theory of learning in games , publisher =. 1998 , author =
1998
-
[52]
Proceedings of the 2018 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA) , author =
2018
-
[53]
Learning in games with continuous action sets and unknown payoff functions , volume =
Mertikopoulos, Panayotis and Zhou, Zhengyuan , journal =. Learning in games with continuous action sets and unknown payoff functions , volume =
-
[54]
Proceedings of The 24th International Conference on Artificial Intelligence and Statistics , pages =
Gaming Helps! Learning from Strategic Interactions in Natural Dynamics , author =. Proceedings of The 24th International Conference on Artificial Intelligence and Statistics , pages =
-
[55]
6th International Conference on Learning Representations,
Aleksander Madry and Aleksandar Makelov and Ludwig Schmidt and Dimitris Tsipras and Adrian Vladu , title =. 6th International Conference on Learning Representations,
-
[56]
Multi-Agent Reinforcement Learning: A Selective Overview of Theories and Algorithms , year =
Zhang, Kaiqing and Yang, Zhuoran and Ba. Multi-Agent Reinforcement Learning: A Selective Overview of Theories and Algorithms , year =
-
[57]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[58]
M. J. Kearns , title =
-
[59]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[60]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[61]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[62]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[63]
2019 , note =
Simple and optimal high-probability bounds for strongly-convex stochastic gradient descent , author =. 2019 , note =
2019
-
[64]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter , author=. arXiv preprint arXiv:1910.01108 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[65]
Empirical Methods in Natural Language Processing: System Demonstrations , year=
Transformers: State-of-the-art natural language processing , author=. Empirical Methods in Natural Language Processing: System Demonstrations , year=
-
[66]
How Waze Tries to Keep Its Crowd Honest , author=
-
[67]
Neural Computing and Applications , volume=
Skills prediction based on multi-label resume classification using CNN with model predictions explanation , author=. Neural Computing and Applications , volume=. 2021 , publisher=
2021
-
[68]
A critical introduction
The gig economy , author=. A critical introduction. Cambridge: Polity , year=
-
[69]
2021 , publisher=
After the gig: How the sharing economy got hijacked and how to win it back , author=. 2021 , publisher=
2021
-
[70]
Challenging Codes: Collective Action in the Information Age , publisher=
Melucci, Alberto , year=. Challenging Codes: Collective Action in the Information Age , publisher=
-
[71]
Conference on Fairness, Accountability, and Transparency , pages=
Adversarial Scrutiny of Evidentiary Statistical Software , author=. Conference on Fairness, Accountability, and Transparency , pages=
-
[72]
Social Media + Society , volume =
Stefania Milan , title =. Social Media + Society , volume =
-
[73]
Vincent, Nicholas and Hecht, Brent and Sen, Shilad , booktitle=. “
-
[74]
Information, Communication & Society , volume=
Platform labor: on the gendered and racialized exploitation of low-income service work in the ‘on-demand’economy , author=. Information, Communication & Society , volume=. 2017 , publisher=
2017
-
[75]
International Journal of Information Management , volume=
The sharing economy and digital platforms: A review and research agenda , author=. International Journal of Information Management , volume=. 2018 , publisher=
2018
-
[76]
International conference on information , pages=
Algorithmic management and algorithmic competencies: Understanding and appropriating algorithms in gig work , author=. International conference on information , pages=. 2019 , organization=
2019
-
[77]
Your order, their labor: An exploration of algorithms and laboring on food delivery platforms in
Sun, Ping , journal=. Your order, their labor: An exploration of algorithms and laboring on food delivery platforms in. 2019 , publisher=
2019
-
[78]
2023 , eprint=
Emergent segmentation from participation dynamics and multi-learner retraining , author=. 2023 , eprint=
2023
-
[79]
2018 , booktitle =
Dong, Jinshuo and Roth, Aaron and Schutzman, Zachary and Waggoner, Bo and Wu, Zhiwei Steven , title =. 2018 , booktitle =
2018
-
[80]
Weapons of the chic: Instagram influencer engagement pods as practices of resistance to
O’Meara, Victoria , journal=. Weapons of the chic: Instagram influencer engagement pods as practices of resistance to. 2019 , publisher=
2019
-
[81]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Strategic Distribution Shift of Interacting Agents via Coupled Gradient Flows , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[82]
J. B. Rosen , journal =. Existence and Uniqueness of Equilibrium Points for Concave N-Person Games , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.