TabClaw: An Interactive and Self-Evolving Agent for Spreadsheet Manipulation and Table Reasoning
Pith reviewed 2026-06-27 13:24 UTC · model grok-4.3
The pith
TabClaw turns natural-language spreadsheet requests into editable execution plans that run via ReAct loops and improve through distilled skills.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TabClaw turns spreadsheets and tables into inspectable analytical workflows while gradually personalizing itself to recurring data-analysis tasks by exposing editable execution plans, streaming ReAct-style tool-using loops, dispatching parallel specialist agents for multi-table reasoning, synthesizing results with explicit consensus and uncertainty markers, and distilling persistent skills from recorded workflows and user feedback.
What carries the argument
Editable execution plan combined with ReAct loops, parallel specialist agents, and feedback-driven skill distillation that records workflows to extract reusable skills.
If this is right
- Users gain the ability to inspect and modify the full analysis plan before execution, reducing silent errors on complex spreadsheet tasks.
- Parallel specialist agents improve accuracy on multi-table comparison and reasoning benchmarks.
- Repeated use leads to extraction of reusable skills that raise future task completion rates without re-deriving the same steps.
- Negative feedback triggers skill upgrades, allowing the agent to avoid previously observed mistakes on similar data.
- The workflow remains inspectable at every stage even as performance on table reasoning tasks increases.
Where Pith is reading between the lines
- The same pattern of editable plans plus skill distillation could transfer to other structured-data domains such as SQL query construction or report generation.
- Over repeated sessions the system might accumulate industry-specific skill packages that users can share without retraining from scratch.
- The explicit uncertainty markers could support audit requirements in regulated settings where analysts must justify each automated step.
- Direct integration with spreadsheet interfaces could let users alternate between manual cell edits and agent-driven plan steps in one view.
Load-bearing premise
Adding editable plans, parallel specialist agents, ReAct loops, and skill distillation produces net gains in task completion without creating new failure modes or extra user burden.
What would settle it
A side-by-side run of the same spreadsheet and table benchmarks with and without the editable-plan or skill-distillation components, measuring changes in executable task success rate and total user edits required.
Figures

read the original abstract
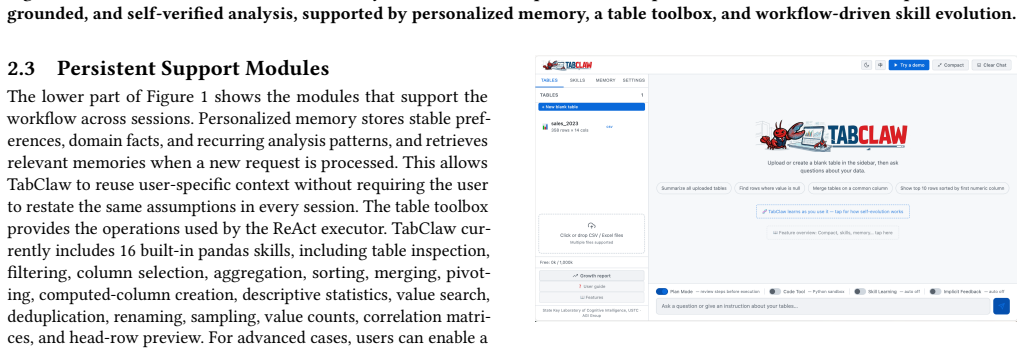
Spreadsheets and tables are widely used representations for structured data analysis, but effective analysis still requires substantial manual effort and domain expertise. Recent large language model (LLM) agents can automate parts of this process, but they often provide limited transparency into intermediate decisions, rely on implicit assumptions, struggle with multi-table comparison, and repeat similar workflows without adapting to a user's preferences. This paper presents TabClaw, an open-source interactive AI agent for spreadsheet manipulation and table reasoning. Users upload CSV or Excel files and issue natural-language requests; TabClaw clarifies ambiguous intent, exposes an editable execution plan, streams a ReAct-style tool-using analysis loop, dispatches specialist agents for parallel multi-table reasoning, and synthesizes findings with explicit consensus and uncertainty markers. Beyond one-off analysis, TabClaw records completed workflows, extracts persistent user memory, distills reusable skills from repeated tool-use patterns, supports package-style skill import, and upgrades skills from negative feedback. Experiments on spreadsheet manipulation and table reasoning benchmarks show that TabClaw improves executable task completion and reasoning performance while preserving an inspectable user workflow. This paper shows how TabClaw turns spreadsheets and tables into inspectable analytical workflows while gradually personalizing itself to recurring data-analysis tasks. Our code is available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TabClaw, an open-source interactive LLM-based agent for spreadsheet manipulation and table reasoning. Key features include natural-language intent clarification, editable execution plans, ReAct-style tool-using loops, parallel specialist agents for multi-table reasoning, explicit consensus/uncertainty markers, and self-evolution via workflow recording, persistent user memory, skill distillation from tool-use patterns, package-style imports, and negative-feedback upgrades. The central claim is that experiments on spreadsheet manipulation and table reasoning benchmarks demonstrate improved executable task completion and reasoning performance while preserving an inspectable user workflow.
Significance. If the performance claims hold with proper evidence, the work could be significant for advancing transparent, user-inspectable LLM agents in structured data analysis. The emphasis on editable plans, parallel specialists, and self-distillation from user workflows addresses common limitations in current agents (opacity, lack of personalization). The open-source release and code availability are strengths that support reproducibility.
major comments (2)
- [Abstract] Abstract: The claim that 'Experiments on spreadsheet manipulation and table reasoning benchmarks show that TabClaw improves executable task completion and reasoning performance' provides no metrics, baselines, error bars, dataset details, ablation studies, or statistical tests. This absence makes the central performance claim impossible to evaluate and prevents assessment of whether the combination of editable plans, parallel agents, ReAct loops, and skill distillation yields net gains without new failure modes.
- [Experiments (or equivalent results section)] No experiments section or results subsection supplies quantitative evidence (e.g., task completion rates, reasoning accuracy scores, or comparisons to prior agents). Without these, the causal link between the described architecture and the asserted improvements cannot be established, rendering the empirical contribution unevaluable.
minor comments (2)
- The description of skill distillation and feedback-driven upgrades would benefit from a concrete example or pseudocode showing how negative feedback is incorporated into reusable skills.
- Figure or diagram clarity: An architecture overview diagram illustrating the flow from user request through editable plan, parallel specialists, and skill update would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for quantitative evidence. We agree that the current submission lacks sufficient empirical detail to support the performance claims and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'Experiments on spreadsheet manipulation and table reasoning benchmarks show that TabClaw improves executable task completion and reasoning performance' provides no metrics, baselines, error bars, dataset details, ablation studies, or statistical tests. This absence makes the central performance claim impossible to evaluate and prevents assessment of whether the combination of editable plans, parallel agents, ReAct loops, and skill distillation yields net gains without new failure modes.
Authors: We agree the abstract's claim is unsupported by specifics. In revision we will rewrite the abstract to include concrete metrics (e.g., task completion rates and accuracy deltas versus baselines), dataset names, and a brief note on ablations and statistical significance where available. revision: yes
-
Referee: [Experiments (or equivalent results section)] No experiments section or results subsection supplies quantitative evidence (e.g., task completion rates, reasoning accuracy scores, or comparisons to prior agents). Without these, the causal link between the described architecture and the asserted improvements cannot be established, rendering the empirical contribution unevaluable.
Authors: The submitted manuscript contains only a high-level claim without a dedicated experiments section or quantitative results. We accept this renders the empirical contribution unevaluable. We will add a full Experiments section reporting benchmark details, baseline comparisons, task completion and reasoning scores, ablations, error bars, and statistical tests to establish the claimed improvements. revision: yes
Circularity Check
No derivation chain or self-referential reductions present
full rationale
The paper is a system-description manuscript introducing TabClaw's architecture (editable plans, ReAct loops, specialist agents, skill distillation). No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the provided abstract or description. The central claim of benchmark improvements is asserted without supporting metrics or derivations, but this absence does not create circularity; the work contains no mathematical chain that reduces to its own inputs by construction. External validation via experiments would be required for the performance claims, yet the text itself is self-contained as an engineering description with no self-definitional or ansatz-smuggling patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Wenhu Chen, Hongmin Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. 2019. Tabfact: A large-scale dataset for table-based fact verification.arXiv preprint arXiv:1909.02164(2019)
arXiv 2019
-
[2]
Yibin Chen, Yifu Yuan, Zeyu Zhang, Yan Zheng, Jinyi Liu, Fei Ni, and Jianye Hao
-
[3]
InICML 2024 Workshop on LLMs and Cognition
Sheetagent: A generalist agent for spreadsheet reasoning and manipulation via large language models. InICML 2024 Workshop on LLMs and Cognition
2024
-
[4]
Mingyue Cheng, Qingyang Mao, Qi Liu, Yitong Zhou, Yupeng Li, Jiahao Wang, Jiaying Lin, Jiawei Cao, and Enhong Chen. 2025. A survey on table mining with large language models: Challenges, advancements and prospects.Authorea Preprints(2025)
2025
-
[5]
Mingyue Cheng, Shuo Yu, Chuang Jiang, Xiaoyu Tao, Qingyang Mao, Jie Ouyang, Qi Liu, and Enhong Chen. 2026. TableMind++: An Uncertainty-Aware Programmatic Agent for Tool-Augmented Table Reasoning.arXiv preprint arXiv:2603.07528(2026)
arXiv 2026
-
[6]
Zhoujun Cheng, Haoyu Dong, Zhiruo Wang, Ran Jia, Jiaqi Guo, Yan Gao, Shi Han, Jian-Guang Lou, and Dongmei Zhang. 2021. Hitab: A hierarchical table dataset for question answering and natural language generation.arXiv preprint arXiv:2108.06712(2021)
arXiv 2021
-
[7]
Zhoujun Cheng, Tianbao Xie, Peng Shi, Chengzu Li, Rahul Nadkarni, Yushi Hu, Caiming Xiong, Dragomir Radev, Mari Ostendorf, Luke Zettlemoyer, et al. 2022. Binding language models in symbolic languages.arXiv preprint arXiv:2210.02875 (2022)
arXiv 2022
-
[8]
Haoyu Dong, Jianbo Zhao, Yuzhang Tian, Junyu Xiong, Shiyu Xia, Mengyu Zhou, Yun Lin, José Cambronero, Yeye He, Shi Han, et al. 2024. Spreadsheetllm: Encoding spreadsheets for large language models.arXiv preprint arXiv:2407.09025 (2024)
arXiv 2024
-
[9]
Lutfi Eren Erdogan, Nicholas Lee, Sehoon Kim, Suhong Moon, Hiroki Furuta, Gopala Anumanchipalli, Kurt Keutzer, and Amir Gholami. 2025. Plan-and-act: Im- proving planning of agents for long-horizon tasks.arXiv preprint arXiv:2503.09572 (2025)
Pith/arXiv arXiv 2025
-
[10]
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. 2023. Critic: Large language models can self-correct with tool-interactive critiquing.arXiv preprint arXiv:2305.11738(2023)
Pith/arXiv arXiv 2023
-
[11]
Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno, and Julian Martin Eisenschlos. 2020. TaPas: Weakly supervised table parsing via pre-training.arXiv preprint arXiv:2004.02349(2020)
arXiv 2020
-
[12]
Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang, and Enhong Chen. 2024. Understanding the planning of LLM agents: A survey.arXiv preprint arXiv:2402.02716(2024)
Pith/arXiv arXiv 2024
-
[13]
Chuang Jiang, Mingyue Cheng, Xiaoyu Tao, Qingyang Mao, Jie Ouyang, and Qi Liu. 2025. TableMind: An Autonomous Programmatic Agent for Tool-Augmented Table Reasoning.arXiv preprint arXiv:2509.06278(2025)
arXiv 2025
-
[14]
Ziqi Jin and Wei Lu. 2023. Tab-cot: Zero-shot tabular chain of thought.arXiv preprint arXiv:2305.17812(2023)
arXiv 2023
-
[15]
Hongxin Li, Jingran Su, Yuntao Chen, Qing Li, and Zhao-Xiang Zhang. 2023. Sheetcopilot: Bringing software productivity to the next level through large language models.Advances in Neural Information Processing Systems36 (2023), 4952–4984
2023
-
[16]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al . 2025. Deepseek- v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
Pith/arXiv arXiv 2025
-
[17]
Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, and Jian- Guang Lou. 2021. TAPEX: Table pre-training via learning a neural SQL executor. arXiv preprint arXiv:2107.07653(2021)
arXiv 2021
-
[18]
Weizheng Lu, Jing Zhang, Ju Fan, Zihao Fu, Yueguo Chen, and Xiaoyong Du
-
[19]
Large language model for table processing: A survey.Frontiers of Computer Science19, 2 (2025), 192350
2025
-
[20]
Zeyao Ma, Bohan Zhang, Jing Zhang, Jifan Yu, Xiaokang Zhang, Xiaohan Zhang, Sijia Luo, Xi Wang, and Jie Tang. 2024. Spreadsheetbench: Towards challenging real world spreadsheet manipulation.Advances in Neural Information Processing Systems37 (2024), 94871–94908
2024
-
[21]
Qingyang Mao, Qi Liu, Zhi Li, Mingyue Cheng, Zheng Zhang, and Rui Li. 2024. PoTable: Towards Systematic Thinking via Stage-oriented Plan-then-Execute Reasoning on Tables.arXiv preprint arXiv:2412.04272(2024)
Pith/arXiv arXiv 2024
-
[22]
Md Mahadi Hasan Nahid and Davood Rafiei. 2024. Normtab: Improving sym- bolic reasoning in llms through tabular data normalization. InFindings of the Association for Computational Linguistics: EMNLP 2024. 3569–3585
2024
-
[23]
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonzalez. 2023. MemGPT: Towards LLMs as Operating Systems. (2023)
2023
-
[24]
Panupong Pasupat and Percy Liang. 2015. Compositional semantic parsing on semi-structured tables.arXiv preprint arXiv:1508.00305(2015)
Pith/arXiv arXiv 2015
-
[25]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems36 (2023), 68539–68551
2023
-
[26]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems36 (2023), 8634–8652
2023
-
[27]
Daoyu Wang, Qingchuan Li, Mingyue Cheng, Jie Ouyang, Shuo Yu, Qi Liu, and Enhong Chen. 2026. StepPO: Step-Aligned Policy Optimization for Agentic Reinforcement Learning.arXiv preprint arXiv:2604.18401(2026)
Pith/arXiv arXiv 2026
-
[28]
Jiahao Wang, Mingyue Cheng, Qingyang Mao, Yitong Zhou, Daoyu Wang, Qi Liu, Feiyang Xu, and Xin Li. 2025. Tabletime: Reformulating time series classification as training-free table understanding with large language models. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 3009–3019
2025
-
[29]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. 2024. A survey on large language model based autonomous agents.Frontiers of Computer Science18, 6 (2024), 186345
2024
-
[30]
Zihao Wang, Shaofei Cai, Guanzhou Chen, Anji Liu, Xiaojian Shawn Ma, and Yitao Liang. 2023. Describe, explain, plan and select: interactive planning with llms enables open-world multi-task agents.Advances in Neural Information Processing Systems36 (2023), 34153–34189
2023
-
[31]
Zhiruo Wang, Haoyu Dong, Ran Jia, Jia Li, Zhiyi Fu, Shi Han, and Dongmei Zhang
-
[32]
InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining
Tuta: Tree-based transformers for generally structured table pre-training. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 1780–1790
-
[33]
Zilong Wang, Hao Zhang, Chun-Liang Li, Julian Martin Eisenschlos, Vincent Perot, Zifeng Wang, Lesly Miculicich, Yasuhisa Fujii, Jingbo Shang, Chen-Yu Lee, et al. 2024. Chain-of-table: Evolving tables in the reasoning chain for table understanding.arXiv preprint arXiv:2401.04398(2024)
arXiv 2024
-
[34]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR)
2023
-
[35]
Yunhu Ye, Binyuan Hui, Min Yang, Binhua Li, Fei Huang, and Yongbin Li. 2023. Large language models are versatile decomposers: Decomposing evidence and questions for table-based reasoning. InProceedings of the 46th international ACM SIGIR conference on research and development in information retrieval. 174–184
2023
-
[36]
Liangyu Zha, Junlin Zhou, Liyao Li, Rui Wang, Qingyi Huang, Saisai Yang, Jing Yuan, Changbao Su, Xiang Li, Aofeng Su, et al . 2023. Tablegpt: Towards unifying tables, nature language and commands into one gpt.arXiv preprint arXiv:2307.08674(2023)
arXiv 2023
-
[37]
Huajian Zhang, Mingyue Cheng, Yucong Luo, and Xiaoyu Tao. 2026. STaR: Towards Effective and Stable Table Reasoning via Slow-Thinking Large Language Models. InProceedings of the ACM Web Conference 2026. 7189–7200
2026
-
[38]
Xiaokang Zhang, Sijia Luo, Bohan Zhang, Zeyao Ma, Jing Zhang, Yang Li, Guan- lin Li, Zijun Yao, Kangli Xu, Jinchang Zhou, et al . 2024. Tablellm: Enabling tabular data manipulation by llms in real office usage scenarios.arXiv preprint arXiv:2403.19318(2024)
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.