Higher-order Diffusion Sampling via Chebyshev Interpolation and Gauss--Seidel Iterations
Pith reviewed 2026-06-27 12:47 UTC · model grok-4.3
The pith
A Chebyshev-Gauss-Seidel sampler approximates target distributions on R^d to total variation distance epsilon using at most d^{1+o_T(1)} epsilon^{-1/K_1} score evaluations under polynomial second-moment bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the exact-score setting the Chebyshev-Gauss-Seidel sampler achieves approximation of any target distribution on R^d to total variation distance epsilon with at most d^{1+o_T(1)} epsilon^{-1/K_1} score evaluations, where the o_T(1) term vanishes as the number of outer iterations T grows and K_1 is a sufficiently large constant; the same guarantee continues to hold under additive errors in the score and Jacobian and under the sole assumption of a polynomial second-moment bound.
What carries the argument
The Chebyshev-Gauss-Seidel higher-order sampler, which uses Chebyshev interpolation to raise the local approximation order and Gauss-Seidel iterations to solve the resulting linear systems at each step, permitting the order to grow logarithmically with the number of outer iterations.
If this is right
- Higher approximation orders become usable without extra smoothness assumptions on the score.
- The same sampler remains accurate even when the score and Jacobian are estimated with additive noise.
- The method applies to targets whose support is unbounded, provided only polynomial second-moment control.
- The accuracy-cost tradeoff improves on finite budgets compared with fixed-order solvers on the same benchmarks.
Where Pith is reading between the lines
- The logarithmic growth of order with outer iterations may extend to other linear multistep or Runge-Kutta schemes for the probability flow ODE.
- The relaxed moment assumption could allow application to heavy-tailed targets common in image and language diffusion models.
- The iteration structure suggests a natural way to incorporate adaptive step-size control while preserving the higher-order guarantee.
Load-bearing premise
The target distribution satisfies only a polynomial bound on its second moment.
What would settle it
A numerical counter-example on an anisotropic Gaussian mixture in which the observed number of score evaluations needed to reach total variation distance epsilon exceeds d^{1.5} for small epsilon would falsify the stated complexity bound.
Figures

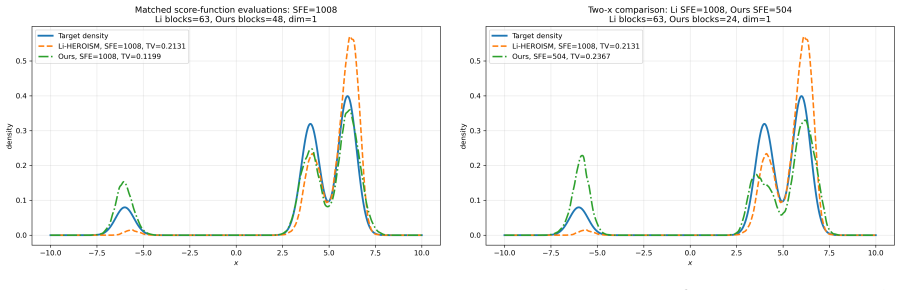
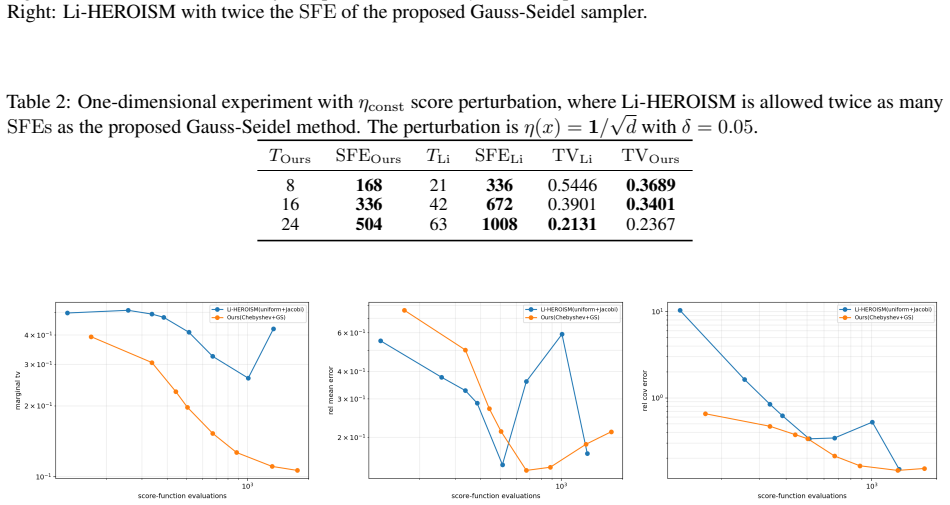
read the original abstract
Higher-order ODE solvers have shown strong empirical promise for accelerating diffusion models through the probability flow ODE, but rigorous non-asymptotic guarantees for such acceleration remain limited. In this paper, we develop a Chebyshev--Gauss--Seidel higher-order sampler and establish a non-asymptotic convergence guarantee that allows the approximation order to grow logarithmically with the number of outer iterations. In the exact-score setting, up to logarithmic factors, the proposed sampler requires at most \[ d^{1+o_T(1)}\varepsilon^{-1/K_1} \] score functions to approximate the target distribution on \(\mathbb{R}^d\) within total variation distance \(\varepsilon\), where \(o_T(1)\to 0\) as \(T\to\infty\) and \(K_1>0\) is a sufficiently large constant. The analysis assumes only a polynomial second-moment bound on the target distribution, thereby relaxing the bounded-support condition imposed in existing higher-order theory. Moreover, the guarantee is robust to score and Jacobian estimation errors and does not require higher-order smoothness assumptions on the score estimates. Numerical experiments on anisotropic Gaussian mixture benchmarks support the predicted improvement in the accuracy--cost tradeoff under finite score-evaluation budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a Chebyshev interpolation combined with Gauss-Seidel iteration scheme for higher-order sampling from the probability flow ODE in diffusion models. It proves a non-asymptotic convergence result allowing the approximation order to grow logarithmically in the number of outer iterations, yielding an exact-score complexity bound of d^{1+o_T(1)} ε^{-1/K_1} score evaluations to reach total-variation distance ε (with o_T(1)→0 as T→∞). The analysis requires only a polynomial second-moment bound on the target rather than bounded support, and the guarantee is stated to be robust to score/Jacobian errors without higher-order smoothness assumptions on the estimates. Numerical results on anisotropic Gaussian mixtures are reported to support improved accuracy-cost tradeoffs.
Significance. If the central complexity bound holds under the stated assumptions, the result would be significant: it relaxes a key restriction in existing higher-order diffusion sampling theory and supplies the first non-asymptotic guarantee that permits growing approximation order while remaining robust to estimation error. The explicit dependence on dimension and accuracy, together with the polynomial-moment relaxation, would constitute a concrete advance for rigorous analysis of accelerated samplers.
major comments (2)
- [§4 (error analysis)] The central complexity claim (abstract and §4) rests on controlling Chebyshev interpolation and Gauss-Seidel iteration errors under only a polynomial second-moment bound E[||X||^2]<∞. Standard approximation theory on unbounded domains requires either compact support or sufficiently rapid tail decay to bound the Lebesgue constant and Runge phenomenon; the manuscript must exhibit an explicit truncation-radius argument showing that the resulting pointwise error remains absorbable into the o_T(1) term when the order grows with the iteration count.
- [Theorem 4.3] Theorem 4.3 (or the main convergence theorem) asserts robustness to score and Jacobian estimation errors without higher-order smoothness on the estimates. The proof sketch must clarify how the Jacobian error term is controlled when the score is only assumed Lipschitz or weakly differentiable; any hidden dependence on higher derivatives would undermine the “no higher-order smoothness” claim.
minor comments (2)
- [§3] Notation for the Chebyshev nodes and the Gauss-Seidel update operator should be introduced once in §3 and used consistently; several inline definitions repeat the same symbols with slightly different normalizations.
- [Numerical experiments] Figure 2 (accuracy-cost curves) would benefit from error bars or multiple random seeds; the current single-run plots make it difficult to assess variability of the reported improvement.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments on our manuscript. We address the two major comments point by point below, indicating where clarifications or additions will be made in the revision.
read point-by-point responses
-
Referee: [§4 (error analysis)] The central complexity claim (abstract and §4) rests on controlling Chebyshev interpolation and Gauss-Seidel iteration errors under only a polynomial second-moment bound E[||X||^2]<∞. Standard approximation theory on unbounded domains requires either compact support or sufficiently rapid tail decay to bound the Lebesgue constant and Runge phenomenon; the manuscript must exhibit an explicit truncation-radius argument showing that the resulting pointwise error remains absorbable into the o_T(1) term when the order grows with the iteration count.
Authors: We agree that the truncation argument requires more explicit treatment to fully justify the bounds under only polynomial moments. The current analysis selects a truncation radius that grows slowly with the number of iterations (ensuring the probability mass outside the interval is absorbed into the o_T(1) term as T→∞) and controls the Lebesgue constant on the truncated interval via standard Chebyshev properties. However, we acknowledge that this step is not stated with sufficient detail. In the revision we will insert a dedicated lemma in §4 that explicitly constructs the radius R_T, bounds the tail contribution using the second-moment assumption, and verifies that the resulting pointwise interpolation error remains compatible with the logarithmic growth of the approximation order. revision: yes
-
Referee: [Theorem 4.3] Theorem 4.3 (or the main convergence theorem) asserts robustness to score and Jacobian estimation errors without higher-order smoothness on the estimates. The proof sketch must clarify how the Jacobian error term is controlled when the score is only assumed Lipschitz or weakly differentiable; any hidden dependence on higher derivatives would undermine the “no higher-order smoothness” claim.
Authors: The proof of Theorem 4.3 controls the Jacobian error via a duality argument that integrates the error against test functions in the total-variation metric, relying only on the Lipschitz continuity of the (estimated) score and the weak differentiability implied by the second-moment bound. No higher derivatives of the estimated score are invoked; the Gauss-Seidel error propagation is bounded directly through the first-order Lipschitz constant and L² integrability. We will expand the proof sketch in the revised manuscript to display this integration step explicitly, thereby removing any ambiguity about hidden smoothness requirements. revision: partial
Circularity Check
No significant circularity; derivation self-contained under stated assumptions
full rationale
The abstract and provided text present the complexity bound as a non-asymptotic guarantee derived from the Chebyshev-Gauss-Seidel construction under a polynomial second-moment assumption on the target. No quoted steps reduce the claimed prediction to a fitted input, self-definition, or load-bearing self-citation chain. The analysis is positioned as relaxing prior bounded-support conditions via explicit assumptions, with the result independent of the target result itself. This is the standard case of an honest non-finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption polynomial second-moment bound on the target distribution
Reference graph
Works this paper leans on
-
[1]
J. S. Dickstein, E. A. Weiss, N. Maheswaranathan, and S. Ganguli. Deep unsupervised learning using nonequilib- rium thermodynamics. InInternational Conference on Machine Learning, pages 2256–2265, 2015
2015
-
[2]
Song and S
Y . Song and S. Ermon. Generative modeling by estimating gradients of the data distribution.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[3]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
2020
-
[4]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models. InInternational Conference on Learning Representations, 2021
2021
-
[5]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations, 2021
2021
-
[6]
Dhariwal and A
P. Dhariwal and A. Nichol. Diffusion models beat GANs on image synthesis.Advances in Neural Information Processing Systems, 34:8780–8794, 2021
2021
-
[7]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022. 37
2022
-
[8]
Saharia, W
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. Denton, S. K. Seyed Ghasemipour, B. K. Ayan, S. S. Mahdavi, R. G. Lopes, T. Salimans, J. Ho, D. J. Fleet, and M. Norouzi. Photorealistic text-to-image diffusion models with deep language understanding.Advances in Neural Information Processing Systems, 35:36479–36494, 2022
2022
-
[9]
Goodfellow, J
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio. Generative adversarial nets.Advances in Neural Information Processing Systems, 27, 2014
2014
-
[10]
D. P. Kingma and M. Welling. Auto-encoding variational bayes. InInternational Conference on Learning Representations, 2014
2014
-
[11]
D. J. Rezende and S. Mohamed. Variational inference with normalizing flows. InInternational Conference on Machine Learning, pages 1530–1538, 2015
2015
-
[12]
B. D. O. Anderson. Reverse-time diffusion equation models.Stochastic Processes and their Applications, 12(3):313–326, 1982
1982
-
[13]
U. G. Haussmann and É. Pardoux. Time reversal of diffusions.The Annals of Probability, 14(4):1188–1205, 1986
1986
-
[14]
Hyvärinen
A. Hyvärinen. Estimation of non-normalized statistical models by score matching.Journal of Machine Learning Research, 6:695–709, 2005
2005
-
[15]
P. Vincent. A connection between score matching and denoising autoencoders.Neural Computation, 23(7):1661– 1674, 2011
2011
-
[16]
C. Lu, Y . Zhou, F. Bao, J. Chen, C. Li, and J. Zhu. DPM-Solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps.Advances in Neural Information Processing Systems, 35:5775–5787, 2022
2022
-
[17]
Zhang and Y
Q. Zhang and Y . Chen. Fast sampling of diffusion models with exponential integrator. InInternational Conference on Learning Representations, 2023
2023
-
[18]
W. Zhao, L. Bai, Y . Rao, J. Zhou, and J. Lu. UniPC: A unified predictor-corrector framework for fast sampling of diffusion models.Advances in Neural Information Processing Systems, 36:49842–49869, 2023
2023
-
[19]
C. Lu, Y . Zhou, F. Bao, J. Chen, C. Li, and J. Zhu. DPM-Solver++: Fast solver for guided sampling of diffusion probabilistic models.Machine Intelligence Research, 22(4):730–751, 2025
2025
-
[20]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
S. Chen, S. Chewi, J. Li, Y . Li, A. Salim, and A. R. Zhang. Sampling is as easy as learning the score: Theory for diffusion models with minimal data assumptions. InInternational Conference on Learning Representations, 2023
2023
-
[22]
H. Lee, J. Lu, and Y . Tan. Convergence for score-based generative modeling with polynomial complexity. Advances in Neural Information Processing Systems, 35:22870–22882, 2022
2022
-
[23]
H. Lee, J. Lu, and Y . Tan. Convergence of score-based generative modeling for general data distributions. In International Conference on Algorithmic Learning Theory, pages 946–985, 2023
2023
-
[24]
Benton, V
J. Benton, V . De Bortoli, A. Doucet, and G. Deligiannidis. Nearly d-linear convergence bounds for diffusion models via stochastic localization. InInternational Conference on Learning Representations, 2024
2024
-
[25]
S. Chen, S. Chewi, H. Lee, Y . Li, J. Lu, and A. Salim. The probability flow ODE is provably fast.Advances in Neural Information Processing Systems, 36:68552–68575, 2023
2023
- [26]
-
[27]
D. Z. Huang, J. Huang, and Z. Lin. Convergence analysis of probability flow ODE for score-based generative models.IEEE Transactions on Information Theory, 71(6):4581–4601, 2025
2025
- [28]
-
[29]
H. Chen, H. Lee, and J. Lu. Improved analysis of score-based generative modeling: User-friendly bounds under minimal smoothness assumptions. InInternational Conference on Machine Learning, pages 4735–4763, 2023
2023
-
[30]
Bruno, Y
S. Bruno, Y . Zhang, D. Lim, O. D. Akyildiz, and S. Sabanis. On diffusion-based generative models and their error bounds: The log-concave case with full convergence estimates.Transactions on Machine Learning Research, 2025
2025
-
[31]
Conforti, A
G. Conforti, A. Durmus, and M. Gentiloni Silveri. KL convergence guarantees for score diffusion models under minimal data assumptions.SIAM Journal on Mathematics of Data Science, 7(1):86–109, 2025
2025
-
[32]
X. Gao, H. M. Nguyen, and L. Zhu. Wasserstein convergence guarantees for a general class of score-based generative models.Journal of Machine Learning Research, 26(43):1–54, 2025. 38
2025
-
[33]
Pedrotti, J
F. Pedrotti, J. Maas, and M. Mondelli. Improved convergence of score-based diffusion models via prediction- correction.Transactions on Machine Learning Research, 2024
2024
-
[34]
Gao and L
X. Gao and L. Zhu. Convergence analysis for general probability flow ODEs of diffusion models in wasserstein distances. InInternational Conference on Artificial Intelligence and Statistics, pages 1009–1017, 2025
2025
-
[35]
J. Tang and Y . Yan. Adaptivity and convergence of probability flow ODEs in diffusion generative models.arXiv preprint arXiv:2501.18863, 2025
-
[36]
E. Beyler and F. Bach. Convergence of deterministic and stochastic diffusion-model samplers: A simple analysis in wasserstein distance.arXiv preprint arXiv:2508.03210, 2025
-
[37]
G. Li, Y . Huang, T. Efimov, Y . Wei, Y . Chi, and Y . Chen. Accelerating convergence of score-based diffusion models, provably. InInternational Conference on Machine Learning, pages 27942–27954, 2024
2024
- [38]
- [39]
-
[40]
K. Gatmiry, S. Chen, and A. Salim. High-accuracy and dimension-free sampling with diffusions.arXiv preprint arXiv:2601.10708, 2026
-
[41]
F. Chen, S. Chewi, C. Daskalakis, and A. Rakhlin. High-accuracy sampling for diffusion models and log-concave distributions.arXiv preprint arXiv:2602.01338, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [42]
-
[43]
Li and Y
G. Li and Y . Yan.O(d/T) convergence theory for diffusion probabilistic models under minimal assumptions. Journal of Machine Learning Research, 26(292):1–55, 2025
2025
-
[44]
Huang, Y
Z. Huang, Y . Wei, and Y . Chen. Denoising diffusion probabilistic models are optimally adaptive to unknown low dimensionality.Mathematics of Operations Research, 2026
2026
-
[45]
B. W. Silverman.Density estimation for statistics and data analysis. Routledge, 2018
2018
-
[46]
B. Efron. Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106(496):1602– 1614, 2011
2011
-
[47]
K. Ball. An elementary introduction to modern convex geometry. In S. Levy, editor,Flavors of Geometry, volume 31 ofMathematical Sciences Research Institute Publications, pages 1–58. Cambridge University Press, Cambridge, 1997
1997
-
[48]
Abramowitz and I
M. Abramowitz and I. A. Stegun, editors.Handbook of mathematical functions with formulas, graphs, and mathematical tables, volume 55 ofApplied Mathematics Series. National Bureau of Standards, Washington, DC, 1964
1964
-
[49]
L. N. Trefethen.Approximation theory and approximation practice, extended edition. SIAM, 2019
2019
-
[50]
J. C. Mason and D. C. Handscomb.Chebyshev polynomials. Chapman and Hall/CRC, 2002. 39
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.