PADD: Path-Aligned Decompression Distillation for Non-Router Teacher to Guide MoE Student Learning
Pith reviewed 2026-06-27 13:16 UTC · model grok-4.3
The pith
A four-stage distillation process lets MoE students learn from dense non-routed teachers and match or surpass them at the same inference cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PADD organizes distillation into an initialization phase (Stage I) using teacher neuron clustering and student-expert warmup to build diverse functionality, then a training phase (Stages II-IV) that combines online adaptive distillation, path-refined policy optimization, and reward-augmented load balancing; this pipeline produces MoE students that match or exceed their dense teachers on mathematical reasoning benchmarks at identical inference cost while maintaining stable routing.
What carries the argument
Path-Aligned Decompression Distillation (PADD) four-stage pipeline that first creates expert diversity via clustering and warmup, then integrates adaptive distillation with routing policy optimization and load balancing.
If this is right
- MoE students reach or exceed dense teacher performance on math reasoning tasks without increasing inference cost.
- The method produces stable routing behavior and effective knowledge transfer from non-routed teachers.
- Gains appear over strong distillation baselines when the full four-stage pipeline is used.
- The approach enables training of routed sparse models directly from standard dense checkpoints.
Where Pith is reading between the lines
- The same staged initialization and path-alignment approach could be tested on non-reasoning tasks such as code generation or long-context understanding.
- If the clustering step proves robust, it might reduce the need for expensive teacher-side routing supervision in future sparse-model training.
- The load-balancing reward term suggests a general way to prevent expert collapse that could be adapted to other sparse architectures beyond the specific MoE variant used here.
- Success at equal inference cost implies that further scaling of MoE capacity under fixed budgets may become more practical once routing policies are learned this way.
Load-bearing premise
Teacher neuron clustering combined with student-expert warmup produces diverse expert behaviors that later stages can refine without the experts collapsing or the router failing to assign them meaningfully.
What would settle it
Run the same mathematical reasoning benchmarks with the final MoE student at the reported inference cost; if it fails to match or surpass the dense teacher or if expert utilization becomes highly unbalanced or unstable, the central claim does not hold.
Figures




read the original abstract
As large language models (LLMs) continue to scale, it becomes increasingly challenging to grow model capacity under fixed computation budgets. We propose Path-Aligned Decompression Distillation (PADD), a framework for distilling knowledge from dense teachers without explicit routing into mixture-of-experts (MoE) students while learning high-quality routing policies. PADD organizes knowledge distillation into four stages in two phases: an initialization phase (Stage I) that builds diverse functionality in the student's experts through teacher neuron clustering and student-expert warmup, and a training phase (Stages II--IV) that integrates online adaptive distillation, path-refined policy optimization, and reward-augmented load balancing in a single training pipeline. Experiments on mathematical reasoning benchmarks demonstrate that PADD yields substantial gains over strong baselines at the same inference cost and that the MoE student can match or surpass its dense teacher. They also demonstrate effective teacher-to-student knowledge distillation and stable routing behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Path-Aligned Decompression Distillation (PADD), a four-stage framework in two phases for distilling from a dense non-router teacher LLM into an MoE student. Stage I performs teacher neuron clustering and student-expert warmup to initialize diverse expert functionality; Stages II-IV then apply online adaptive distillation, path-refined policy optimization, and reward-augmented load balancing. The central empirical claim is that this yields substantial gains over strong baselines on mathematical reasoning benchmarks at equal inference cost, allows the MoE student to match or surpass its dense teacher, and produces effective distillation with stable routing.
Significance. If the results hold with proper validation of the initialization assumptions, the work could be significant for scaling MoE capacity under fixed compute budgets by enabling high-quality routing policies without requiring a routed teacher. The staged path-alignment approach offers a concrete pipeline for teacher-to-student transfer that addresses both functionality diversity and load balancing.
major comments (2)
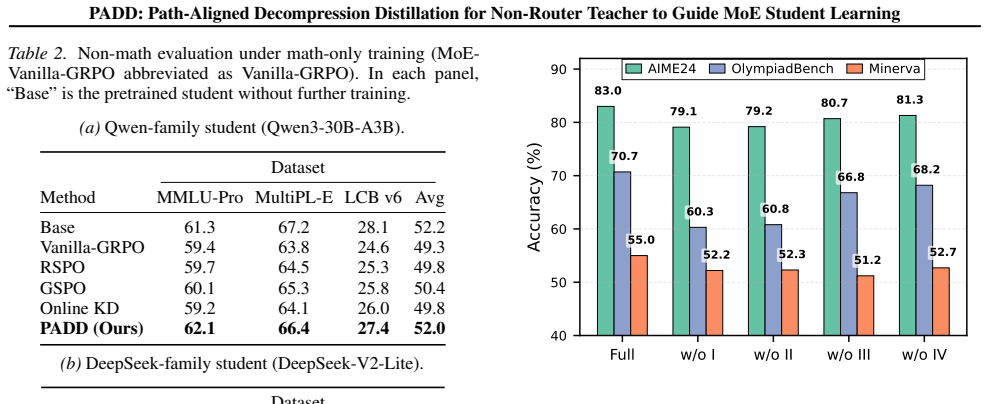
- [Stage I / initialization phase] Stage I description (and its role in the overall pipeline): the headline claim that the MoE student matches or surpasses the dense teacher at equal inference cost depends on the assumption that teacher neuron clustering plus student-expert warmup successfully produces exploitable expert diversity without collapse. No direct post-Stage-I metrics (expert activation correlations, per-expert specialization scores, or routing entropy) are supplied to validate this; final benchmark gains alone do not isolate whether the assumption held or whether gains arose from later stages.
- [Experiments / abstract claims] Experiments section: the abstract states 'substantial gains' and 'stable routing' but supplies no concrete numbers, baselines, metrics (e.g., accuracy deltas, routing entropy values), error bars, dataset details, or ablation results isolating Stage I. This prevents verification of the central claim against evidence.
minor comments (2)
- [Abstract] Abstract: lacks any quantitative results, specific benchmark names, or baseline comparisons, which is atypical for an empirical ML paper and hinders quick assessment.
- [Method overview] Notation and terminology: 'path-refined policy optimization' and 'reward-augmented load balancing' are introduced without immediate formal definitions or equations, making the pipeline description harder to follow on first reading.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment point by point below, proposing revisions where appropriate to strengthen the validation of Stage I and the presentation of experimental results.
read point-by-point responses
-
Referee: [Stage I / initialization phase] Stage I description (and its role in the overall pipeline): the headline claim that the MoE student matches or surpasses the dense teacher at equal inference cost depends on the assumption that teacher neuron clustering plus student-expert warmup successfully produces exploitable expert diversity without collapse. No direct post-Stage-I metrics (expert activation correlations, per-expert specialization scores, or routing entropy) are supplied to validate this; final benchmark gains alone do not isolate whether the assumption held or whether gains arose from later stages.
Authors: We agree that direct post-Stage-I metrics are needed to validate the initialization assumptions and isolate their contribution from later stages. The current manuscript emphasizes end-to-end benchmark gains, but we will add these analyses in the revision, including expert activation correlations, per-expert specialization scores, and routing entropy after Stage I to demonstrate diversity without collapse. revision: yes
-
Referee: [Experiments / abstract claims] Experiments section: the abstract states 'substantial gains' and 'stable routing' but supplies no concrete numbers, baselines, metrics (e.g., accuracy deltas, routing entropy values), error bars, dataset details, or ablation results isolating Stage I. This prevents verification of the central claim against evidence.
Authors: Abstracts are conventionally high-level and concise. The experiments section provides the requested quantitative details (accuracy deltas, baselines, routing entropy, error bars, dataset information, and Stage I ablations), but we acknowledge the need for clearer linkage to the abstract claims. We will revise the abstract to incorporate key concrete numbers and ensure Stage I isolation results are more prominently featured. revision: partial
Circularity Check
No circularity in derivation or claims
full rationale
The paper describes a multi-stage distillation process (initialization via neuron clustering and warmup, followed by adaptive distillation, policy optimization, and load balancing) whose outputs are benchmark performance numbers on mathematical reasoning tasks. No equations, fitted parameters, or derivations appear in the abstract or summary text that reduce any claimed result to an input by construction, self-definition, or self-citation chain. Experimental claims rest on external benchmark comparisons rather than internal re-labeling of fitted quantities as predictions. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Teacher neuron clustering produces diverse expert functionality that supports later path-aligned training.
Reference graph
Works this paper leans on
-
[1]
ArXiv , year=
Scaling Laws for Neural Language Models , author=. ArXiv , year=
-
[2]
Advances in Neural Information Processing Systems , editor=
An empirical analysis of compute-optimal large language model training , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[3]
International Conference on Learning Representations , year=
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author=. International Conference on Learning Representations , year=
-
[4]
Journal of Machine Learning Research , year =
William Fedus and Barret Zoph and Noam Shazeer , title =. Journal of Machine Learning Research , year =
-
[5]
2023 , url=
Emergent Modularity in Pre-trained Transformers , author=. 2023 , url=
2023
-
[6]
The Eleventh International Conference on Learning Representations , year=
Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints , author=. The Eleventh International Conference on Learning Representations , year=
-
[7]
2024 , eprint=
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model , author=. 2024 , eprint=
2024
-
[8]
2015 , eprint=
Distilling the Knowledge in a Neural Network , author=. 2015 , eprint=
2015
-
[9]
doi: 10.18653/v1/2022.acl-long.489
Dai, Damai and Dong, Li and Ma, Shuming and Zheng, Bo and Sui, Zhifang and Chang, Baobao and Wei, Furu. S table M o E : Stable Routing Strategy for Mixture of Experts. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.489
-
[10]
2023 , eprint=
Decoding the Silent Majority: Inducing Belief Augmented Social Graph with Large Language Model for Response Forecasting , author=. 2023 , eprint=
2023
-
[11]
The Twelfth International Conference on Learning Representations , year=
Mixture-of-Experts Meets Instruction Tuning: A Winning Combination for Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[12]
2022 , eprint=
ST-MoE: Designing Stable and Transferable Sparse Expert Models , author=. 2022 , eprint=
2022
-
[13]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[14]
2025 , eprint=
DeepSeek-V3 Technical Report , author=. 2025 , eprint=
2025
-
[15]
Yuxian Gu and Li Dong and Furu Wei and Minlie Huang , booktitle=. Mini. 2024 , url=
2024
-
[16]
Unlocking Emergent Modularity in Large Language Models
Qiu, Zihan and Huang, Zeyu and Fu, Jie. Unlocking Emergent Modularity in Large Language Models. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.144
-
[17]
arXiv preprint arXiv:2510.23027 , year=
Towards Stable and Effective Reinforcement Learning for Mixture-of-Experts , author=. arXiv preprint arXiv:2510.23027 , year=
-
[18]
arXiv preprint arXiv:2212.05055 , year=
Sparse upcycling: Training mixture-of-experts from dense checkpoints , author=. arXiv preprint arXiv:2212.05055 , year=
-
[19]
The twelfth international conference on learning representations , year=
On-policy distillation of language models: Learning from self-generated mistakes , author=. The twelfth international conference on learning representations , year=
-
[20]
Group Sequence Policy Optimization
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Notion Blog , year=
Deepscaler: Surpassing o1-preview with a 1.5 b model by scaling rl , author=. Notion Blog , year=
-
[23]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Gshard: Scaling giant models with conditional computation and automatic sharding , author=. arXiv preprint arXiv:2006.16668 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[25]
Advances in Neural Information Processing Systems , volume=
Mixture-of-experts with expert choice routing , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Artificial Intelligence Review , volume=
Mixture of experts: a literature survey , author=. Artificial Intelligence Review , volume=. 2014 , publisher=
2014
-
[27]
arXiv preprint arXiv:2510.11370 , year=
Stabilizing moe reinforcement learning by aligning training and inference routers , author=. arXiv preprint arXiv:2510.11370 , year=
-
[28]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Dense2moe: Restructuring diffusion transformer to moe for efficient text-to-image generation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[29]
ArXiv , year=
Distilling the Knowledge in a Neural Network , author=. ArXiv , year=
-
[30]
Advances in Neural Information Processing Systems , volume=
Scaling vision with sparse mixture of experts , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
International Conference on Machine Learning , pages=
Base layers: Simplifying training of large, sparse models , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[32]
Black-box on-policy distillation of large language models.arXiv preprint arXiv:2511.10643,
Black-Box On-Policy Distillation of Large Language Models , author=. arXiv preprint arXiv:2511.10643 , year=
-
[33]
2026 , eprint=
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author=. 2026 , eprint=
2026
-
[34]
2022 , url=
Knowledge Distillation for Mixture of Experts Models in Speech Recognition , author=. 2022 , url=
2022
-
[35]
Hugging Face repository , volume=
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions , author=. Hugging Face repository , volume=
-
[36]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Advances in neural information processing systems , volume=
Solving quantitative reasoning problems with language models , author=. Advances in neural information processing systems , volume=
-
[38]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[39]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement , author=. arXiv preprint arXiv:2409.12122 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
IEEE Transactions on Software Engineering , volume=
Multipl-e: A scalable and polyglot approach to benchmarking neural code generation , author=. IEEE Transactions on Software Engineering , volume=. 2023 , publisher=
2023
-
[43]
International Conference on Learning Representations , volume=
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. International Conference on Learning Representations , volume=
-
[44]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Program Synthesis with Large Language Models
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Findings of the Association for Computational Linguistics: ACL 2022 , pages=
Moefication: Transformer feed-forward layers are mixtures of experts , author=. Findings of the Association for Computational Linguistics: ACL 2022 , pages=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.