RATrain: A Resource-Aware Training Runtime for Large Language Models on Bandwidth-Constrained Heterogeneous Supercomputing Platforms
Pith reviewed 2026-06-27 12:10 UTC · model grok-4.3
The pith
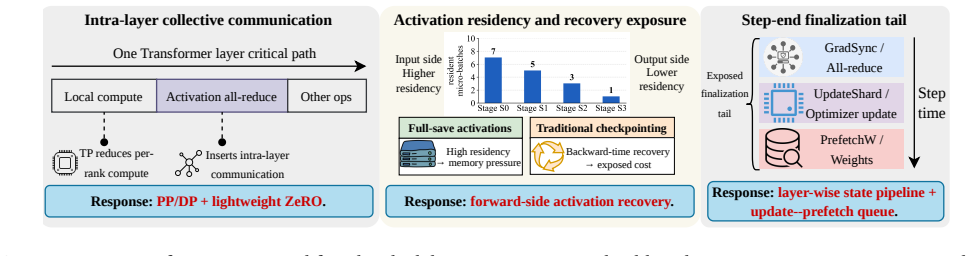
RATrain reformulates 1F1B LLM training as layer-granular scheduling to fit MT-3000 memory and bandwidth limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
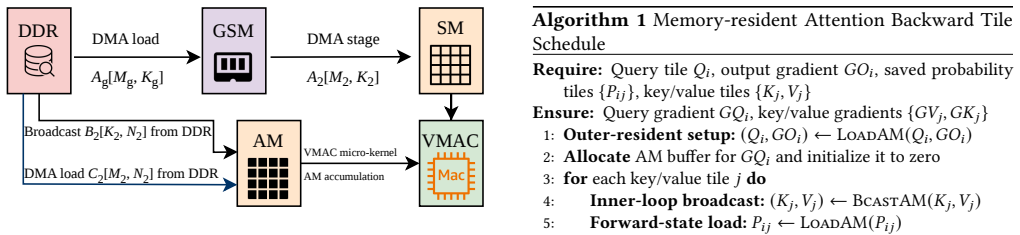
RATrain schedules gradient synchronization, parameter update, parameter-view prefetching, and activation recovery at layer-level granularity on MT-3000 platforms, combined with a resource-aware planner that selects feasible configurations under the 20GB usable-DDR constraint per cluster and an MT-3000-aware execution backend for FP16 GEMM and attention backward passes.
What carries the argument
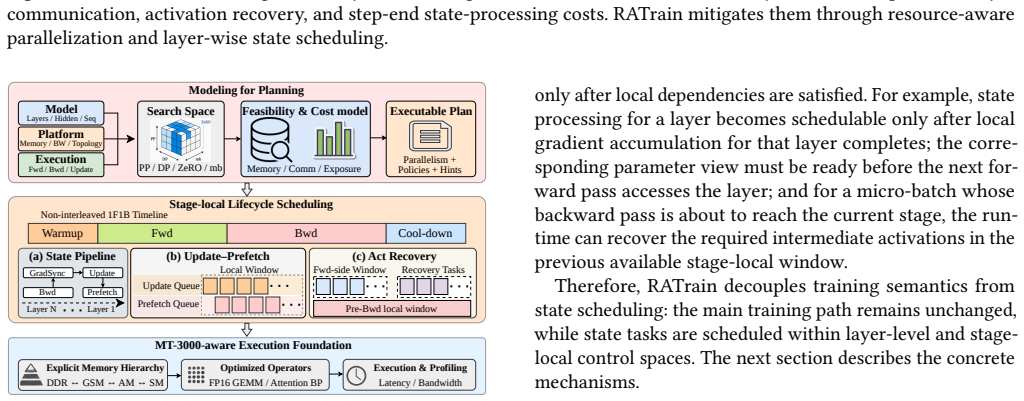
Layer-level training-state lifecycle scheduler that coordinates gradient sync, parameter update, prefetch, and recovery under explicit 20GB DDR and inter-cluster bandwidth limits, paired with an MT-3000-specific FP16 execution backend.
If this is right
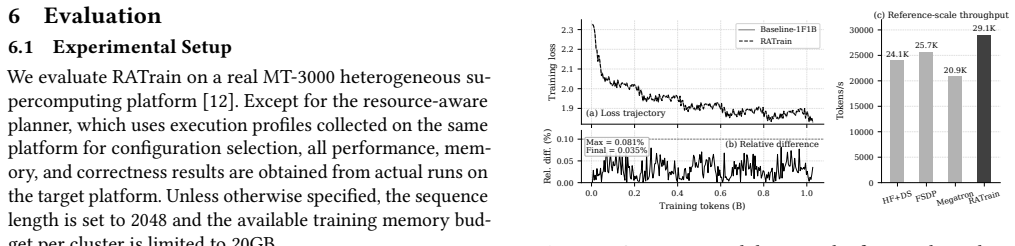
- LLaMA-2-7B reaches 112790.55 tokens per second at 1024 clusters with 97 percent scaling efficiency
- The same scheduler delivers measured speedups on Baichuan2-13B, Qwen2.5-32B, and LLaMA-2-70B
- Loss curves stay within 0.081 percent relative deviation of a baseline 1F1B run over more than one billion tokens
- Training configurations remain feasible inside the 20GB usable DDR limit per cluster
Where Pith is reading between the lines
- The layer-granular scheduling pattern may transfer to other memory-hierarchy platforms that lack mature collective libraries
- Explicit separation of prefetch and recovery stages could reduce peak memory in other pipeline-parallel LLM setups
- Preservation of loss trajectory suggests the method can be dropped into existing training loops without hyper-parameter retuning
Load-bearing premise
The resource-aware planner and layer scheduler correctly model all memory, communication, and compute costs on MT-3000 so that selected configurations incur no hidden overheads or training instability.
What would settle it
Running the same LLaMA-2-7B configuration on 1024 MT-3000 clusters and measuring either actual per-cluster memory footprint exceeding the planner's prediction or end-to-end tokens-per-second falling below the reported 112790 value.
Figures







read the original abstract
Production heterogeneous supercomputing platforms are increasingly used to host large language model (LLM) training workloads. However, existing GPU-oriented training runtimes typically rely on high-bandwidth device memory, fast interconnects, and mature collective communication libraries, making them difficult to directly adapt to MT-3000, a platform with an explicit memory hierarchy, limited usable DDR capacity, and constrained inter-cluster communication. This paper presents RATrain, a resource-aware training runtime for dense LLMs on bandwidth-constrained heterogeneous supercomputing platforms. RATrain formulates standard non-interleaved 1F1B training as a training-state lifecycle scheduling problem, and schedules gradient synchronization, parameter update, parameter-view prefetching, and activation recovery at layer-level and stage-local granularity. RATrain further combines an MT-3000-aware execution backend for efficient and predictable FP16 GEMM, Attention Backward, and explicit data movement with a resource-aware planner that selects feasible training configurations under the 20GB usable-DDR constraint per compute cluster. We implement RATrain on a real MT-3000 platform and evaluate it using LLaMA-2-7B, Baichuan2-13B, Qwen2.5-32B, and LLaMA-2-70B configurations. Results show that RATrain achieves up to 1.35$\times$ end-to-end speedup over MT-3000-adapted GPU-style training strategies. For LLaMA-2-7B, RATrain scales to 1024 compute clusters, reaches 112,790.55 tokens/s, and achieves 97.0\% scaling efficiency. A further 1.028B-token correctness run shows that RATrain preserves the loss trajectory of a semantically equivalent Baseline-1F1B run, with a maximum relative loss deviation of 0.081\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RATrain, a resource-aware training runtime for dense LLMs on the MT-3000 heterogeneous supercomputing platform. It reformulates standard non-interleaved 1F1B training as a training-state lifecycle scheduling problem, performing gradient synchronization, parameter update, parameter-view prefetching, and activation recovery at layer-level and stage-local granularity. RATrain includes an MT-3000-aware execution backend for FP16 GEMM, Attention Backward, and explicit data movement, plus a resource-aware planner that selects feasible configurations under the 20GB usable-DDR constraint per compute cluster. Evaluation on LLaMA-2-7B, Baichuan2-13B, Qwen2.5-32B, and LLaMA-2-70B reports up to 1.35× end-to-end speedup over MT-3000-adapted GPU-style strategies; for LLaMA-2-7B it scales to 1024 clusters at 112,790.55 tokens/s with 97.0% efficiency, and a 1.028B-token run shows maximum relative loss deviation of 0.081% versus a semantically equivalent Baseline-1F1B.
Significance. If the reported end-to-end measurements hold, the work is significant for demonstrating practical, high-efficiency LLM training on bandwidth-constrained heterogeneous platforms that lack GPU-style high-bandwidth memory and interconnects. The direct implementation on physical MT-3000 hardware, scaling results to 1024 clusters, and explicit loss-trajectory verification constitute concrete, falsifiable contributions that could broaden the set of usable supercomputing resources for dense model training.
minor comments (2)
- [Abstract] Abstract: the reported throughput (112,790.55 tokens/s) and scaling efficiency (97.0%) are given to high precision without error bars, number of runs, or data-exclusion criteria; adding these in the results section would improve verifiability of the central performance claims.
- The manuscript would benefit from an explicit statement of the number of independent training runs underlying the loss-deviation figure and any rules used to select the 1.028B-token window.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the work's significance, and recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity identified
full rationale
The paper describes an engineering implementation of a scheduling runtime for LLM training on MT-3000 hardware, with all reported results (1.35× speedup, 97% scaling efficiency at 1024 clusters, 0.081% max loss deviation after 1.028B tokens) presented as direct measurements from physical execution rather than outputs of any equations, fitted parameters, or self-citation chains. No load-bearing derivation steps, ansatzes, or uniqueness theorems appear in the abstract or description; the resource-aware planner and layer scheduler are exercised inside the measured system, so any modeling mismatch would manifest directly in the tokens/s and loss figures. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kaifeng Bi, Lingxi Xie, Hengheng Zhang, Xin Chen, Xiaotao Gu, and Qi Tian. 2023. Accurate medium-range global weather forecasting with 3D neural networks.Nature619, 7970 (2023), 533–538. doi:10. 1038/s41586-023-06185-3
2023
-
[2]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al . 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[3]
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. 2016. Training Deep Nets with Sublinear Memory Cost.arXiv preprint arXiv:1604.06174(2016)
Pith/arXiv arXiv 2016
-
[4]
Jesse Dodge, Maarten Sap, Ana Marasović, William Agnew, Gabriel Ilharco, Dirk Groeneveld, Margaret Mitchell, and Matt Gardner. 2021. Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus.arXiv preprint arXiv:2104.08758(2021)
arXiv 2021
-
[5]
Le, Yonghui Wu, and Zhifeng Chen
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Mia Xu Chen, Dehao Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V. Le, Yonghui Wu, and Zhifeng Chen. 2019. GPipe: Efficient Training of Giant Neural Networks Using Pipeline Parallelism. InAdvances in Neural Information Processing Systems, Vol. 32. 13
2019
-
[6]
Yuzhou Huang, Yapeng Jiang, and Zicong Hong. 2025. Obscura: Con- cealing Recomputation Overhead in Training of Large Language Mod- els with Bubble-filling Pipeline Transformation. In2025 USENIX An- nual Technical Conference. 663–678
2025
-
[7]
Gonzalez
Paras Jain, Ajay Jain, Aniruddha Nrusimha, Amir Gholami, Pieter Abbeel, Kurt Keutzer, Ion Stoica, and Joseph E. Gonzalez. 2020. Check- mate: Breaking the Memory Wall with Optimal Tensor Rematerializa- tion. InProceedings of Machine Learning and Systems, Vol. 2. 497–511
2020
-
[8]
Xianyan Jia, Le Jiang, Ang Wang, Wencong Xiao, Ziji Shi, Jie Zhang, Xinyuan Li, Langshi Chen, Yong Li, Zhen Zheng, Xiaoyong Liu, and Wei Lin. 2020. Whale: Efficient Giant Model Training over Heteroge- neous GPUs.arXiv preprint arXiv:2011.09208(2020)
arXiv 2020
-
[9]
Zhihao Jia, Matei Zaharia, and Alex Aiken. 2019. Beyond Data and Model Parallelism for Deep Neural Networks. InProceedings of Machine Learning and Systems, Vol. 1. 1–13
2019
-
[10]
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ronneberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Zidek, Anna Potapenko, et al. 2021. Highly accurate protein structure prediction with AlphaFold.Nature596, 7873 (2021), 583–589. doi:10.1038/s41586-021-03819-2
-
[11]
Remi Lam, Alvaro Sanchez-Gonzalez, Matthew Willson, Peter Wirns- berger, Meire Fortunato, Ferran Alet, Suman Ravuri, Timo Ewalds, Zach Eaton-Rosen, Weihua Hu, et al. 2023. Learning skillful medium- range global weather forecasting.Science382, 6677 (2023), 1416–1421. doi:10.1126/science.adi2336
-
[12]
Kai Lu, Yaohua Wang, Yang Guo, Chun Huang, Sheng Liu, Ruibo Wang, Jianbin Fang, Tao Tang, Zhaoyun Chen, Biwei Liu, et al. 2022. MT-3000: a heterogeneous multi-zone processor for HPC.CCF Transactions on High Performance Computing4, 2 (2022), 150–164
2022
-
[13]
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R. Devanur, Gregory R. Ganger, Phillip B. Gibbons, and Matei Zaharia. 2019. PipeDream: Generalized Pipeline Parallelism for DNN Training. InProceedings of the 27th ACM Symposium on Operating Systems Principles. 1–15. doi:10.1145/3341301.3359646
-
[14]
Deepak Narayanan, Amar Phanishayee, Kaiyu Shi, Xie Chen, and Matei Zaharia. 2021. Memory-Efficient Pipeline-Parallel DNN Training. In Proceedings of the 38th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 139). 7937–7947
2021
-
[15]
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGres- ley, Mostofa Patwary, Vijay Anand Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, Amar Phan- ishayee, and Matei Zaharia. 2021. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM. InProceed- ings of the International Conferenc...
-
[16]
Xuan Peng, Xuanhua Shi, Hulin Dai, Hai Jin, Weiliang Ma, Qian Xiong, Fan Yang, and Xuehai Qian. 2020. Capuchin: Tensor-based GPU Mem- ory Management for Deep Learning. InProceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Lan- guages and Operating Systems. 891–905. doi:10.1145/3373376.3378505
-
[17]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.Journal of Machine Learning Research21, 140 (2020), 1–67
2020
-
[18]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He
-
[19]
InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis
ZeRO: Memory Optimizations Toward Training Trillion Pa- rameter Models. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 1–
-
[20]
doi:10.1109/SC41405.2020.00024
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/sc41405.2020.00024 2020
-
[21]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He
-
[22]
InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining
DeepSpeed: System Optimizations Enable Training Deep Learn- ing Models with Over 100 Billion Parameters. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 3505–3506. doi:10.1145/3394486.3406703
-
[23]
Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, and Yuxiong He
-
[24]
In 2021 USENIX Annual Technical Conference
ZeRO-Offload: Democratizing Billion-Scale Model Training. In 2021 USENIX Annual Technical Conference. 551–564
2021
-
[25]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv preprint arXiv:1909.08053(2019)
Pith/arXiv arXiv 2019
-
[26]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Alma- hairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open Foundation and Fine-Tuned Chat Models.arXiv preprint arXiv:2307.09288(2023)
Pith/arXiv arXiv 2023
-
[27]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. InAdvances in Neural Information Processing Systems, Vol. 30
2017
-
[28]
Yuanzhong Xu, HyoukJoong Lee, Dehao Chen, Blake Hechtman, Yan- ping Huang, Rahul Joshi, Maxim Krikun, Dmitry Lepikhin, Andy Ly, Marcello Maggioni, Ruoming Pang, Noam Shazeer, Shibo Wang, Tao Wang, Yonghui Wu, and Zhifeng Chen. 2021. GSPMD: General and Scalable Parallelization for ML Computation Graphs.arXiv preprint arXiv:2105.04663(2021)
Pith/arXiv arXiv 2021
-
[29]
Aiyuan Yang, Bin Xiao, Bingning Wang, Borong Zhang, Ce Bian, Chao Yin, Chenxu Lv, Da Pan, Dian Wang, Dong Yan, et al. 2023. Baichuan 2: Open Large-scale Language Models.arXiv preprint arXiv:2309.10305 (2023)
Pith/arXiv arXiv 2023
-
[30]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al
-
[31]
Qwen2.5 Technical Report.arXiv preprint arXiv:2412.15115 (2024)
Pith/arXiv arXiv 2024
-
[32]
Kainan Yu, Xinxin Qi, Peng Zhang, Jianbin Fang, Dezun Dong, Ruibo Wang, Tao Tang, Chun Huang, Yonggang Che, and Zheng Wang. 2024. Optimizing General Matrix Multiplications on Modern Multi-core DSPs. In2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 964–975
2024
-
[33]
Tailing Yuan, Yuliang Liu, Xucheng Ye, Shenglong Zhang, Jianchao Tan, Bin Chen, Chengru Song, and Di Zhang. 2024. Accelerating the Training of Large Language Models Using Efficient Activation Rematerialization and Optimal Hybrid Parallelism. In2024 USENIX Annual Technical Conference. 545–561
2024
-
[34]
Xing, Joseph E
Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yanping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Eric P. Xing, Joseph E. Gonzalez, and Ion Stoica. 2022. Alpa: Au- tomating Inter- and Intra-Operator Parallelism for Distributed Deep Learning. InProceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation. ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.