SpenseGPT: Practical One-shot Pruning Enabling Sparse and Dense GEMMs for LLM Inference
Pith reviewed 2026-06-27 13:54 UTC · model grok-4.3
The pith
Splitting LLM weight matrices into 2:4 sparse and dense regions allows one-shot pruning to achieve 1.2x end-to-end decoding speedup on B200 GPUs while preserving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
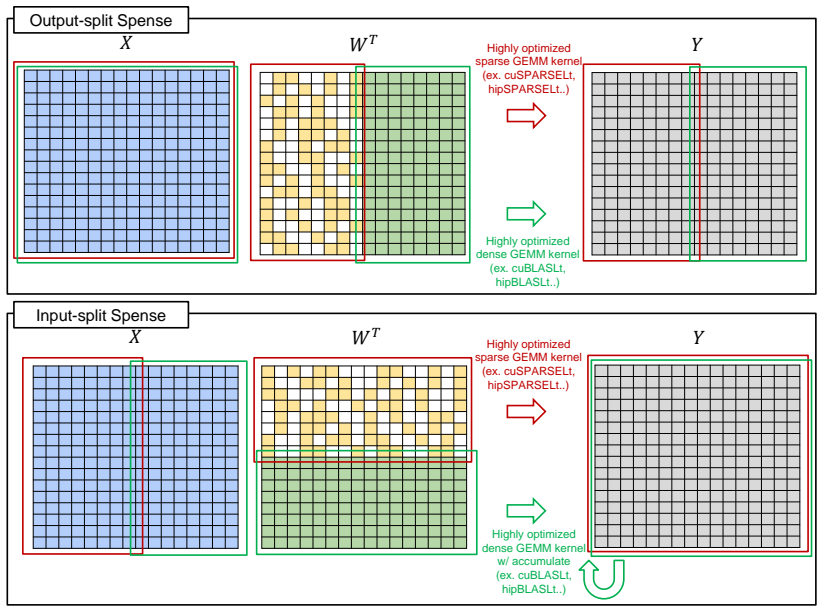
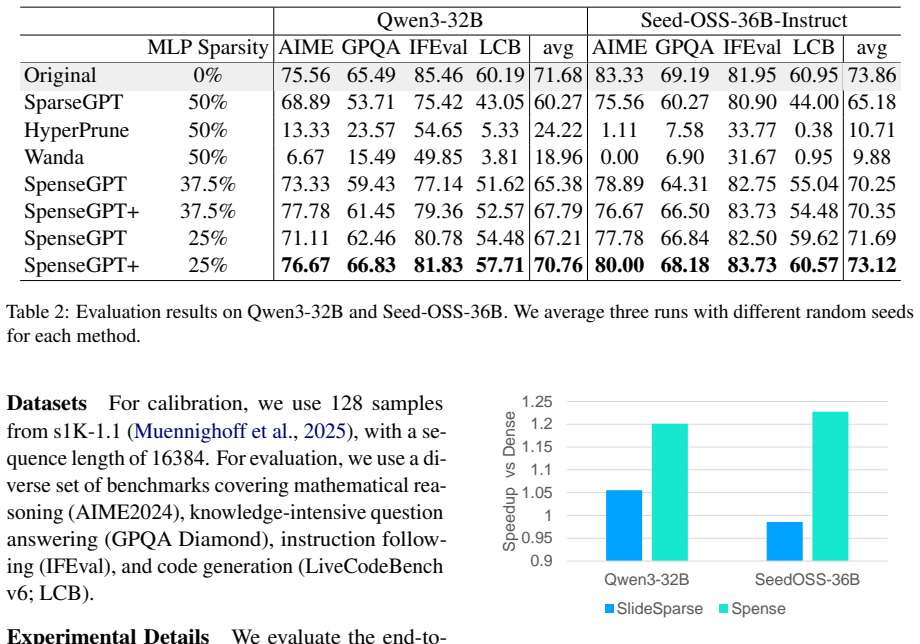
SpenseGPT is a one-shot post-training pruning method that produces sparse and dense regions in weight matrices using two strategies for dense region selection. This hybrid format remains compatible with existing high-performance sparse and dense GEMM libraries without requiring custom compiler support or input activation expansion, resulting in up to 1.2x end-to-end decoding speedup on B200 GPUs with FP8 precision for Qwen3-32B and Seed-OSS-36B models while preserving accuracy.
What carries the argument
The Spense hybrid sparse-dense format, which splits each weight matrix into a 2:4 sparse region and a dense region to relax the 50% sparsity constraint.
If this is right
- Up to 1.2x end-to-end decoding speedup on B200 GPUs with FP8 precision.
- Accuracy preservation on Qwen3-32B and Seed-OSS-36B models.
- Compatibility with existing sparse and dense GEMM libraries without custom compiler support.
- No runtime overheads from input activation expansion.
- Practical one-shot pruning that avoids iterative search or model-specific tuning.
Where Pith is reading between the lines
- The method could be tested on additional model sizes and architectures to see if the speedup generalizes.
- Future GPUs with enhanced sparse tensor core support might benefit more from this hybrid format.
- Combining this with other optimization techniques like quantization could compound the inference gains.
Load-bearing premise
The two strategies for choosing which weights belong in the dense region can be applied in a single post-training pass without requiring model-specific tuning or iterative search.
What would settle it
Running SpenseGPT on Qwen3-32B and measuring the end-to-end decoding time and accuracy on B200 GPUs using FP8 precision would determine if the 1.2x speedup is achieved without accuracy degradation.
Figures


read the original abstract
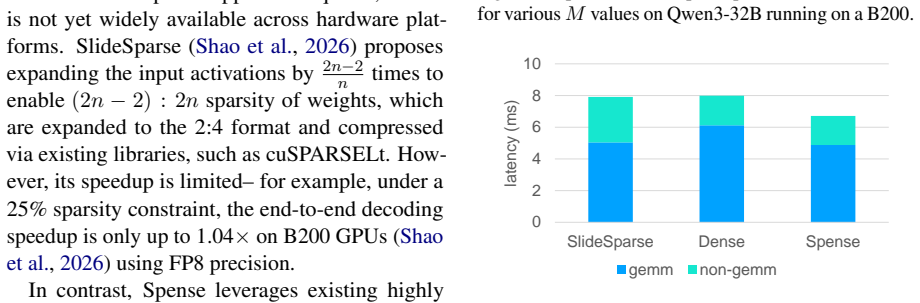
Semi-structured 2:4 sparsity is widely supported by modern accelerators, providing up to a 2x theoretical speedup. However, its strict 50% sparsity constraint often causes non-negligible accuracy degradation under post-training pruning. Meanwhile, existing relaxed sparsity formats either require specialized compiler support or introduce runtime overheads that limit end-to-end speedup. We propose Spense, a practical hybrid sparse-dense format that splits each weight matrix into a 2:4 sparse region and a dense region. This design relaxes the effective sparsity constraint while remaining compatible with existing high-performance sparse and dense GEMM libraries, avoiding both custom compiler support and input activation expansion. Building on this format, we introduce SpenseGPT, a one-shot post-training pruning method that produces sparse and dense regions. Notably, we show that selecting the right dense regions is important, and we devise two different strategies to choose them. Experiments on Qwen3-32B and Seed-OSS-36B demonstrate that our method achieves up to 1.2x end-to-end decoding speedup on B200 GPUs with FP8 precision, while preserving accuracy. To the best of our knowledge, this is the first one-shot pruning demonstration of real-world end-to-end LLM decoding speedup from semi-structured sparse tensor cores on recent GPUs such as B200s, while maintaining model quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Spense, a hybrid sparse-dense format that partitions each weight matrix into a 2:4 sparse region and a dense region to relax the strict sparsity constraint while remaining compatible with existing GEMM libraries. Building on this, SpenseGPT is presented as a one-shot post-training pruning method with two strategies for selecting the dense regions. Experiments on Qwen3-32B and Seed-OSS-36B report up to 1.2× end-to-end decoding speedup on B200 GPUs using FP8 precision without accuracy degradation, claiming to be the first such demonstration using semi-structured sparse tensor cores.
Significance. If the method is genuinely one-shot and the reported speedups hold across a broader set of models and hardware, this work could have practical significance for accelerating LLM inference on modern GPUs by leveraging existing sparse and dense kernels without requiring specialized compilers or incurring runtime overheads from activation expansion. The hybrid format addresses a key limitation of pure 2:4 sparsity.
major comments (2)
- [Abstract] Abstract: The central claim that SpenseGPT is strictly one-shot rests on the two dense-region selection strategies being tuning-free and general; the abstract states only that 'selecting the right dense regions is important' and 'we devise two different strategies' without evidence that either is parameter-free or that their cost is negligible relative to a single forward pass, which is load-bearing for the practicality claim on 32B–36B models.
- [Experiments] Experiments section (results on Qwen3-32B and Seed-OSS-36B): The headline 1.2× end-to-end FP8 decoding speedup is reported without error bars, without ablation of the two selection strategies, and without comparison to stronger baselines such as dense FP8 inference or other post-training pruning methods; this weakens the ability to attribute the speedup specifically to the hybrid format.
minor comments (2)
- [Abstract] The abstract claims 'to the best of our knowledge, this is the first one-shot pruning demonstration...' but does not cite or compare against the closest prior hybrid sparsity or semi-structured pruning works; add a related-work paragraph.
- [Method] Notation for the hybrid format (sparse region + dense region) should be defined with a diagram or pseudocode in the method section for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to strengthen the presentation of the one-shot claim and experimental results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that SpenseGPT is strictly one-shot rests on the two dense-region selection strategies being tuning-free and general; the abstract states only that 'selecting the right dense regions is important' and 'we devise two different strategies' without evidence that either is parameter-free or that their cost is negligible relative to a single forward pass, which is load-bearing for the practicality claim on 32B–36B models.
Authors: The two strategies are simple, heuristic-based selection rules (one magnitude-driven and one activation-aware) that operate without additional hyperparameters beyond the target sparsity ratio. Their implementation requires only a single linear pass over each weight matrix to identify and partition the dense region, incurring negligible cost relative to even one forward pass through a 32B–36B model. We will revise the abstract to explicitly note that both strategies are tuning-free and to quantify their overhead. revision: yes
-
Referee: [Experiments] Experiments section (results on Qwen3-32B and Seed-OSS-36B): The headline 1.2× end-to-end FP8 decoding speedup is reported without error bars, without ablation of the two selection strategies, and without comparison to stronger baselines such as dense FP8 inference or other post-training pruning methods; this weakens the ability to attribute the speedup specifically to the hybrid format.
Authors: We agree that error bars, an ablation of the two selection strategies, and explicit baseline comparisons would improve clarity. The reported 1.2× figure is measured against dense FP8 inference on the same B200 hardware; the hybrid format enables partial use of the sparse tensor cores while keeping the remainder dense. In revision we will add (i) error bars from repeated measurements, (ii) an ablation comparing the two region-selection strategies, and (iii) a direct side-by-side table against dense FP8. Additional post-training pruning baselines can be referenced if space allows, though our emphasis remains on one-shot methods that reuse existing GEMM libraries. revision: yes
Circularity Check
No circularity; central claims are empirical measurements on hardware
full rationale
The paper presents an empirical method for hybrid sparse-dense pruning and reports measured end-to-end speedups on specific models and GPUs. No equations, fitted parameters, or first-principles derivations are supplied in the provided text that could reduce to self-definition or self-citation. The one-shot claim is supported by the description of two selection strategies, but these are presented as part of the method rather than as outputs derived from prior fitted quantities within the paper. The result therefore stands as an independent experimental finding rather than a tautological restatement of its inputs.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Spense hybrid sparse-dense format
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Maximiliana Behnke and Kenneth Heafield. 2021. https://aclanthology.org/2021.wmt-1.116 Pruning Neural Machine Translation for Speed Using Group Lasso . In Proceedings of the Sixth Conference on Machine Translation , pages 1074--1086, Online. Association for Computational Linguistics
2021
-
[2]
Hongrong Cheng, Miao Zhang, and Javen Qinfeng Shi. 2024. https://doi.org/10.48550/arXiv.2407.11681 MINI-LLM : Memory-Efficient Structured Pruning for Large Language Models . Preprint, arXiv:2407.11681
-
[3]
Joel Coburn, Chunqiang Tang, Sameer Abu Asal, Neeraj Agrawal, Raviteja Chinta, Harish Dixit, Brian Dodds, Saritha Dwarakapuram, Amin Firoozshahian, Cao Gao, Kaustubh Gondkar, Tyler Graf, Junhan Hu, Jian Huang, Sterling Hughes, Adam Hutchin, Bhasker Jakka, Guoqiang Jerry Chen, Indu Kalyanaraman, and 40 others. 2025. https://doi.org/10.1145/3695053.3731409 ...
-
[4]
Rocktim Jyoti Das, Mingjie Sun, Liqun Ma, and Zhiqiang Shen. 2024. https://doi.org/10.48550/arXiv.2311.04902 Beyond Size : How Gradients Shape Pruning Decisions in Large Language Models . Preprint, arXiv:2311.04902
-
[5]
Lucio Dery, Steven Kolawole, Jean-Fran c ois Kagy, Virginia Smith, Graham Neubig, and Ameet Talwalkar. 2024. https://doi.org/10.48550/arXiv.2402.05406 Everybody Prune Now : Structured Pruning of LLMs with only Forward Passes . Preprint, arXiv:2402.05406
-
[6]
Peijie Dong, Lujun Li, Zhenheng Tang, Xiang Liu, Xinglin Pan, Qiang Wang, and Xiaowen Chu. 2024. https://openreview.net/forum?id=1tRLxQzdep&referrer= In Forty-First International Conference on Machine Learning
2024
-
[7]
Elias Frantar and Dan Alistarh. 2023. https://proceedings.mlr.press/v202/frantar23a.html SparseGPT : Massive language models can be accurately pruned in one-shot . In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 10323--10337. PMLR
2023
-
[8]
Babak Hassibi and David Stork. 1992. https://proceedings.neurips.cc/paper/1992/hash/303ed4c69846ab36c2904d3ba8573050-Abstract.html Second order derivatives for network pruning: Optimal Brain Surgeon . In Advances in Neural Information Processing Systems , volume 5. Morgan-Kaufmann
1992
-
[9]
Bai Hongxiao and Li Yun. 2023. https://developer.nvidia.com/blog/structured-sparsity-in-the-nvidia-ampere-architecture-and-applications-in-search-engines/ Structured Sparsity in the NVIDIA Ampere Architecture and Applications in Search Engines
2023
-
[10]
Younes Hourri, Mohammad Mozaffari, and Maryam Mehri Dehnavi. 2025. https://doi.org/10.48550/arXiv.2509.23410 PATCH : Learnable Tile-level Hybrid Sparsity for LLMs . Preprint, arXiv:2509.23410
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.23410 2025
-
[11]
Eldar Kurtic, Denis Kuznedelev, Elias Frantar, Michael Goinv, Shubhra Pandit, Abhinav Agarwalla, Tuan Nguyen, Alexandre Marques, Mark Kurtz, and Dan Alistarh. 2025. https://doi.org/10.1007/978-3-031-85747-8_6 Sparse Fine-Tuning for Inference Acceleration of Large Language Models . In Peyman Passban, Andy Way, and Mehdi Rezagholizadeh, editors, Enhancing L...
-
[12]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. https://doi.org/10.1145/3600006.3613165 Efficient Memory Management for Large Language Model Serving with PagedAttention . In Proceedings of the 29th Symposium on Operating Systems Principles , SOSP '23, pages 611--626, New Yor...
-
[13]
Jaeseong Lee, Seung-won Hwang, Aurick Qiao, Daniel F Campos, Zhewei Yao, and Yuxiong He. 2025. https://doi.org/10.18653/v1/2025.acl-long.671 STUN : Structured-Then-Unstructured Pruning for Scalable MoE Pruning . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pages 13660--13676, Vienna...
-
[14]
Vin Huang Liao, Carson. 2026. https://rocm.blogs.amd.com/artificial-intelligence/introduce_hipsparselt/README.html Unlocking Sparse Acceleration on AMD GPUs with hipSPARSELt
2026
-
[15]
Hongyi Liu, Rajarshi Saha, Zhen Jia, Youngsuk Park, Jiaji Huang, Shoham Sabach, Yu-Xiang Wang, and George Karypis. 2025. https://openreview.net/forum?id=zkxe5vASi8 PROXSPARSE : REGULARIZED LEARNING OF SEMI-STRUCTURED SPARSITY MASKS FOR PRETRAINED LLMS . In Forty-Second International Conference on Machine Learning
2025
-
[16]
Xinyin Ma, Gongfan Fang, and Xinchao Wang. 2023. https://openreview.net/forum?id=J8Ajf9WfXP LLM-Pruner : On the structural pruning of large language models . In Thirty-Seventh Conference on Neural Information Processing Systems
2023
-
[17]
Asit Mishra, Jorge Albericio Latorre, Jeff Pool, Darko Stosic, Dusan Stosic, Ganesh Venkatesh, Chong Yu, and Paulius Micikevicius. 2021. https://doi.org/10.48550/arXiv.2104.08378 Accelerating Sparse Deep Neural Networks . Preprint, arXiv:2104.08378
-
[18]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei , Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Cand \`e s, and Tatsunori Hashimoto. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1025 S1: Simple test-time scaling . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages 20...
-
[19]
NVIDIA. 2024. https://www.nvidia.com/en-us/data-center/dgx-b200/ NVIDIA DGX B200
2024
-
[20]
Hanyong Shao, Yingbo Hao, Ting Song, Yan Xia, Di Zhang, Shaohan Huang, Xun Wu, Songchen Xu, Le Xu, Li Dong, Zewen Chi, Yi Zou, and Furu Wei. 2026. https://doi.org/10.48550/arXiv.2603.05232 SlideSparse : Fast and Flexible ( 2N-2 ): 2N Structured Sparsity . Preprint, arXiv:2603.05232
-
[21]
Noam Shazeer. 2020. https://arxiv.org/abs/2002.05202 GLU Variants Improve Transformer . Preprint, arXiv:2002.05202
Pith/arXiv arXiv 2020
-
[22]
Lu Sun and Jun Sakuma. 2026. https://openreview.net/forum?id=lqjQs2lVNm Learning Semi-Structured Sparsity for LLMs via Shared and Context-Aware Hypernetwork . In The Fourteenth International Conference on Learning Representations
2026
-
[23]
Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. 2024. https://openreview.net/forum?id=PxoFut3dWW A simple and effective pruning approach for large language models . In The Twelfth International Conference on Learning Representations
2024
-
[24]
ByteDance Seed Team. 2025. https://github.com/ByteDance-Seed/seed-oss Seed- OSS open-source models
2025
-
[25]
ModelScope Team. 2024. https://github.com/modelscope/evalscope EvalScope : Evaluation framework for large models
2024
-
[26]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://doi.org/10.48550/arXiv.2505.09388 Qwen3 Technical Report . Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[27]
Lu Yin, You Wu, Zhenyu Zhang, Cheng-Yu Hsieh, Yaqing Wang, Yiling Jia, Gen Li, Ajay Kumar Jaiswal, Mykola Pechenizkiy, Yi Liang, Michael Bendersky, Zhangyang Wang, and Shiwei Liu. 2024. https://openreview.net/forum?id=ahEm3l2P6w&referrer= In Forty-First International Conference on Machine Learning
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.