5% > 100%: Flatness Preference is All You Need for Multimodal Parameter-Efficient Fine-Tuning
Pith reviewed 2026-06-27 14:01 UTC · model grok-4.3
The pith
A small fraction of sharp dimensions dominates generalization in multimodal PEFT methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Various PEFT methods exhibit a flatness preference where a small fraction of sharp dimensions dominates the generalization of PEFT. Flatness Preference Optimization (FlatPO) flattens these key sharpness dimensions, leading various PEFTs toward better generalization.
What carries the argument
Flatness preference, the property that a small fraction of sharp dimensions dominates generalization in PEFT, addressed via Flatness Preference Optimization (FlatPO) to selectively flatten them.
If this is right
- Various existing PEFT methods achieve better generalization when FlatPO flattens their identified sharp dimensions.
- A small fraction of dimensions, as little as around 5 percent, suffices for superior performance over optimizing the full set.
- The approach applies across different PEFT techniques on multimodal downstream tasks.
- Generalization improves by focusing optimization on flatness of the dominant sharp dimensions.
Where Pith is reading between the lines
- PEFT techniques could be redesigned to detect and prioritize sharp dimensions during initial adaptation.
- The same preference might appear in fine-tuning outside multimodal settings, such as in language or vision-only tasks.
- Scaling experiments on larger models would test whether the controlling fraction remains small.
Load-bearing premise
The flatness preference in the sharp dimensions is what causes better generalization, and selectively flattening them improves results across PEFT methods without side effects.
What would settle it
Applying FlatPO to a held-out multimodal dataset and observing no gain or a drop in generalization performance compared to standard PEFT would falsify the claim.
Figures

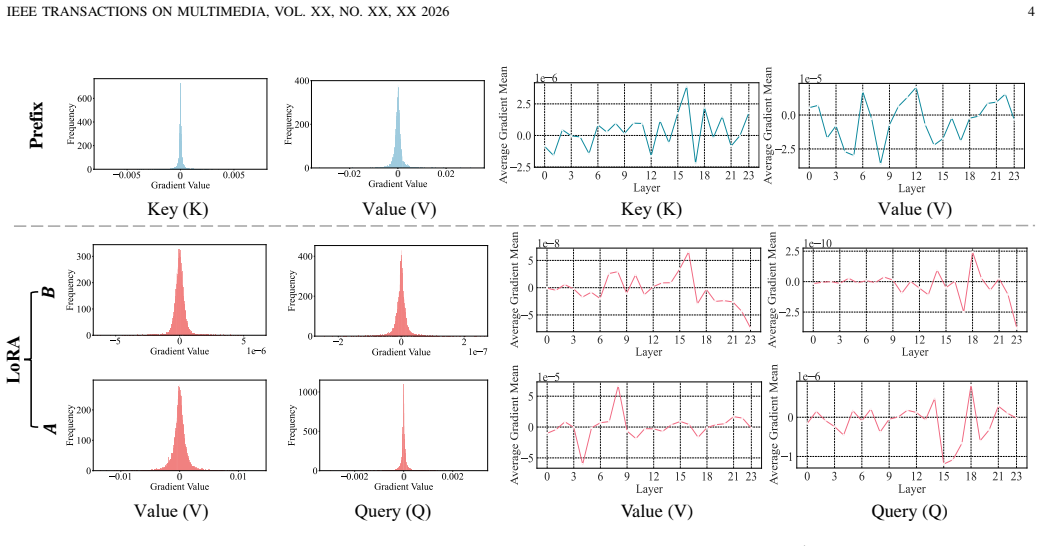
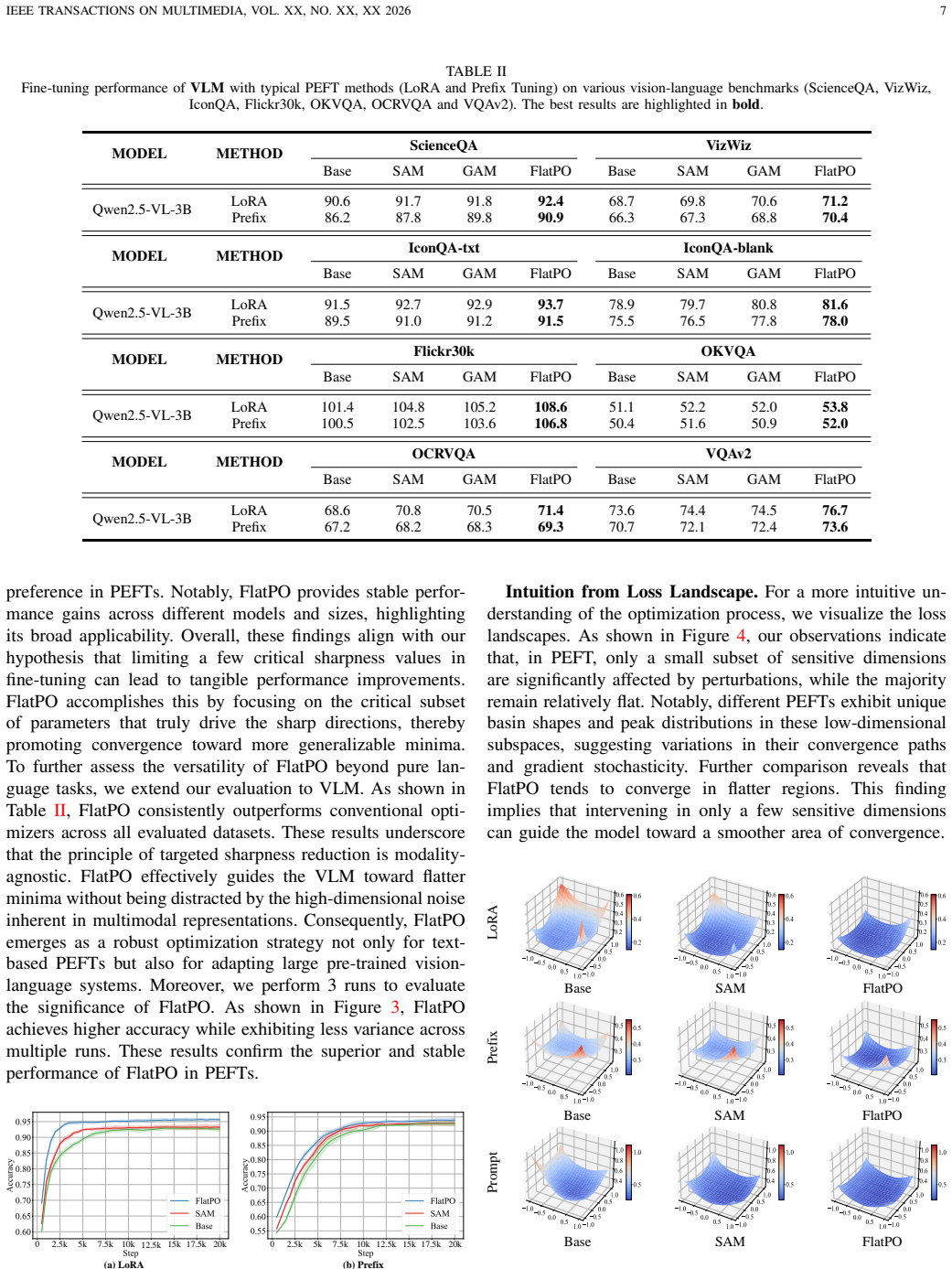
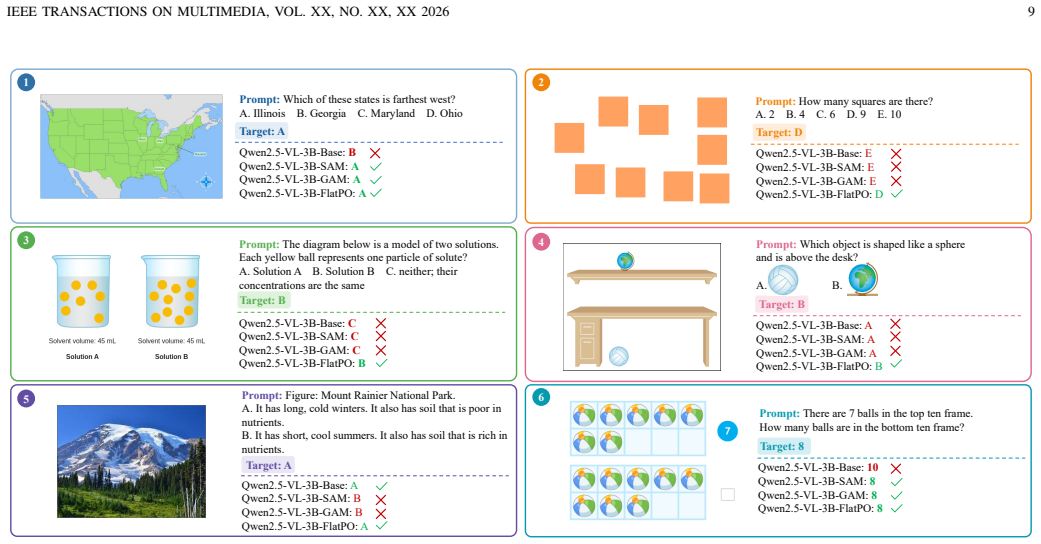
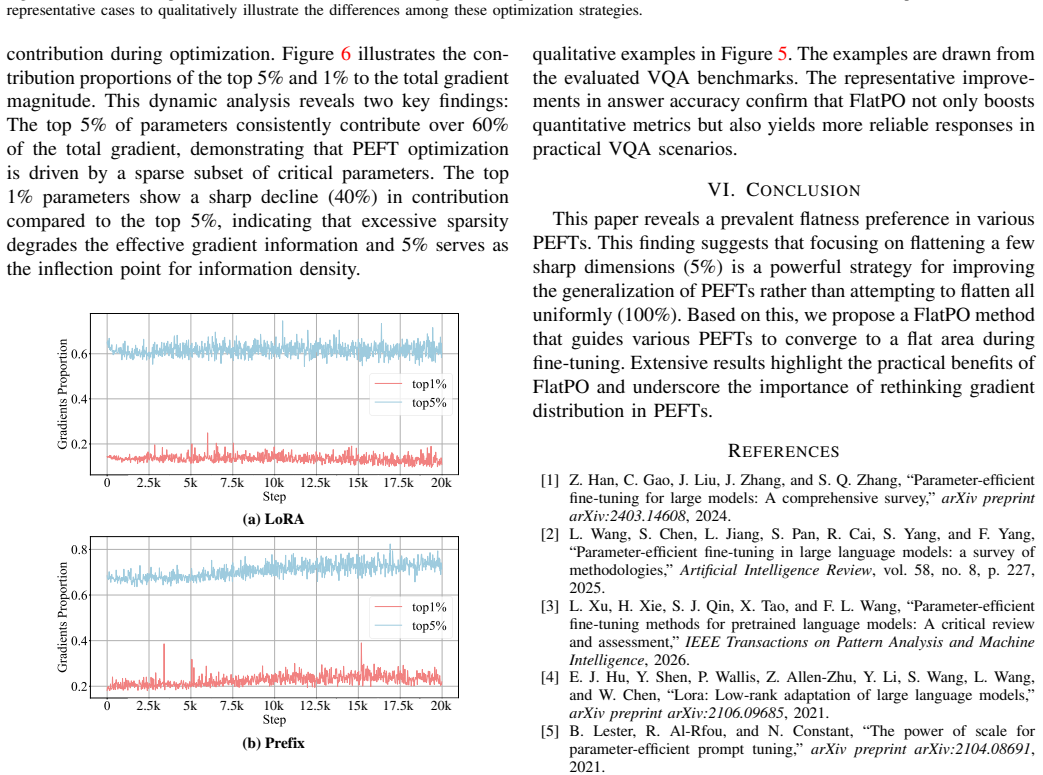
read the original abstract
Parameter-Efficient Fine-Tuning (PEFT) methods provide a streamlined and efficient tool for adapting large models to domain-specific multimodal downstream tasks. Although these methods proved their tangible effects in practice, their principal aspects remain under-explored. Therefore we remain curious about the underlying generalization mechanisms in various PEFT methods and how they can be further enhanced. In this paper, we reveal the flatness preference widely present in various PEFTs, where a small fraction of sharp dimensions dominates the generalization of PEFT. This finding suggests an appealing possibility: we may be satisfied with a better generalization by merely attending to this small fraction of sharp dimensions instead of all of them. Furthermore, we propose Flatness Preference Optimization (FlatPO) to flatten these key sharpness dimensions, leading various PEFTs toward better generalization. Extensive experiments demonstrate the effectiveness of our findings and the proposed method. Code is available at https://github.com/Can-Lin/FlatPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that PEFT methods for multimodal tasks exhibit a 'flatness preference' in which a small fraction (~5%) of sharp dimensions dominates generalization performance. It proposes Flatness Preference Optimization (FlatPO) to selectively flatten these dimensions, yielding better generalization across various PEFT methods, with the claim supported by extensive experiments.
Significance. If the causal relationship between the identified sharp dimensions and generalization holds after proper controls, the result could simplify PEFT by showing that focusing on a small subset of dimensions suffices, with potential efficiency gains. The empirical observation across multiple PEFT methods is noteworthy, but the absence of ablations for causality reduces the strength of the central claim.
major comments (2)
- [Abstract / Experiments] The central claim that a small fraction of sharp dimensions causally dominates PEFT generalization requires controls that are not described. Experiments must demonstrate that flattening random or non-sharp dimensions does not produce comparable gains; without such ablations the observed preference remains correlational rather than causal.
- [Experiments] Stability of the identified sharp dimensions across random seeds, tasks, and PEFT methods is not addressed. If the dimensions vary substantially, the proposed FlatPO method would require method-specific retuning, undermining the claim that the preference is a general property.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. The concerns about establishing causality and assessing stability are valid and will be addressed through additional experiments in the revised manuscript. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract / Experiments] The central claim that a small fraction of sharp dimensions causally dominates PEFT generalization requires controls that are not described. Experiments must demonstrate that flattening random or non-sharp dimensions does not produce comparable gains; without such ablations the observed preference remains correlational rather than causal.
Authors: We agree that explicit controls are required to move from correlation to causation. In the revision we will add ablation experiments that (i) randomly select and flatten an equal number of dimensions and (ii) flatten the least-sharp dimensions, then compare generalization performance against FlatPO on the same multimodal tasks and PEFT backbones. These results will be reported in a new subsection of the Experiments section together with statistical significance tests. revision: yes
-
Referee: [Experiments] Stability of the identified sharp dimensions across random seeds, tasks, and PEFT methods is not addressed. If the dimensions vary substantially, the proposed FlatPO method would require method-specific retuning, undermining the claim that the preference is a general property.
Authors: We will include a new stability analysis in the revised manuscript. For each PEFT method we will compute the Jaccard overlap of the top-5% sharp dimensions across five random seeds, across three distinct multimodal tasks, and across the different PEFT families. The results will be presented in a dedicated table; if overlap is high we will also report the performance of a single set of dimensions transferred across settings to quantify the practical generality of FlatPO. revision: yes
Circularity Check
No circularity: empirical observation and method proposal are independent of fitted inputs
full rationale
The paper's central contribution is an empirical finding of flatness preference in PEFT methods followed by the proposal of FlatPO to act on identified sharp dimensions. No derivation chain, equations, or self-citation load-bearing steps are present that reduce a claimed prediction or result to its own inputs by construction. The abstract and description frame the work as observational discovery plus a new optimization technique validated by experiments, with no evidence of self-definitional fits, renamed known results, or uniqueness theorems imported from prior author work. This is a standard empirical paper whose claims rest on external validation rather than internal reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Parameter-efficient fine-tuning for large models: A comprehensive survey,
Z. Han, C. Gao, J. Liu, J. Zhang, and S. Q. Zhang, “Parameter-efficient fine-tuning for large models: A comprehensive survey,”arXiv preprint arXiv:2403.14608, 2024
Pith/arXiv arXiv 2024
-
[2]
Parameter-efficient fine-tuning in large language models: a survey of methodologies,
L. Wang, S. Chen, L. Jiang, S. Pan, R. Cai, S. Yang, and F. Yang, “Parameter-efficient fine-tuning in large language models: a survey of methodologies,”Artificial Intelligence Review, vol. 58, no. 8, p. 227, 2025
2025
-
[3]
Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment,
L. Xu, H. Xie, S. J. Qin, X. Tao, and F. L. Wang, “Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[4]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” arXiv preprint arXiv:2106.09685, 2021
Pith/arXiv arXiv 2021
-
[5]
The power of scale for parameter-efficient prompt tuning,
B. Lester, R. Al-Rfou, and N. Constant, “The power of scale for parameter-efficient prompt tuning,”arXiv preprint arXiv:2104.08691, 2021
Pith/arXiv arXiv 2021
-
[6]
Llm-adapters: An adapter family for parameter-efficient fine- tuning of large language models,
Z. Hu, L. Wang, Y . Lan, W. Xu, E.-P. Lim, L. Bing, X. Xu, S. Poria, and R. Lee, “Llm-adapters: An adapter family for parameter-efficient fine- tuning of large language models,” inProceedings of the 2023 conference on empirical methods in natural language processing, 2023, pp. 5254– 5276. IEEE TRANSACTIONS ON MULTIMEDIA, VOL. XX, NO. XX, XX 2026 10
2023
-
[7]
Dual modality prompt tuning for vision-language pre-trained model,
Y . Xing, Q. Wu, D. Cheng, S. Zhang, G. Liang, P. Wang, and Y . Zhang, “Dual modality prompt tuning for vision-language pre-trained model,” IEEE Transactions on Multimedia, vol. 26, pp. 2056–2068, 2024
2056
-
[8]
Unleash the power of vision-language models by visual attention prompt and multimodal interaction,
W. Zhang, L. Wu, Z. Zhang, T. Yu, C. Ma, X. Jin, X. Yang, and W. Zeng, “Unleash the power of vision-language models by visual attention prompt and multimodal interaction,”IEEE Transactions on Multimedia, vol. 27, pp. 2399–2411, 2024
2024
-
[9]
Unleashing the power of singular values for parameter-efficient fine- tuning of large pre-trained models,
C. Sun, J. Wei, Y . Wu, Y . Shi, S. He, Z. Ma, N. Xie, and Y . Yang, “Unleashing the power of singular values for parameter-efficient fine- tuning of large pre-trained models,”IEEE Transactions on Multimedia, 2026
2026
-
[10]
Sharpness-aware minimization: General analysis and improved rates,
D. Oikonomou and N. Loizou, “Sharpness-aware minimization: General analysis and improved rates,”arXiv preprint arXiv:2503.02225, 2025
arXiv 2025
-
[11]
Bi-lora: Efficient sharpness-aware minimization for fine-tuning large-scale models,
Y . Liu, T. Li, Z. Huang, Z. Yang, and X. Huang, “Bi-lora: Efficient sharpness-aware minimization for fine-tuning large-scale models,”arXiv preprint arXiv:2508.19564, 2025
Pith/arXiv arXiv 2025
-
[12]
Sparse is enough in fine-tuning pre-trained large language model,
W. Song, Z. Li, L. Zhang, H. Zhao, and B. Du, “Sparse is enough in fine-tuning pre-trained large language model,”International Conference on Machine Learning, 2024
2024
-
[13]
Understanding pre-training and fine-tuning from loss landscape per- spectives,
H. Chen, Y . Dong, Z. Wei, Y . Huang, Y . Zhang, H. Su, and J. Zhu, “Understanding pre-training and fine-tuning from loss landscape per- spectives,”arXiv e-prints, pp. arXiv–2505, 2025
2025
-
[14]
Towards understanding con- vergence and generalization of adamw,
P. Zhou, X. Xie, Z. Lin, and S. Yan, “Towards understanding con- vergence and generalization of adamw,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[15]
Eflat-lora: Efficiently seeking flat minima for better generalization in fine-tuning large language models and beyond,
J. Deng, Q. Zhu, J. Pang, L. Yang, Z. Fu, and B. Zhang, “Eflat-lora: Efficiently seeking flat minima for better generalization in fine-tuning large language models and beyond,”arXiv e-prints, pp. arXiv–2508, 2025
2025
-
[16]
Flat- lora: Low-rank adaption over a flat loss landscape,
T. Li, Z. He, Y . Li, Y . Wang, L. Shang, and X. Huang, “Flat- lora: Low-rank adaption over a flat loss landscape,”arXiv preprint arXiv:2409.14396, 2024
arXiv 2024
-
[17]
Improving generalization and convergence by enhancing implicit regularization,
M. Wang, J. Wang, H. He, Z. Wang, G. Huang, F. Xiong, Z. Li, L. Wu et al., “Improving generalization and convergence by enhancing implicit regularization,”Advances in Neural Information Processing Systems, vol. 37, pp. 118 701–118 744, 2024
2024
-
[18]
Domain generalization using large pretrained models with mixture-of-adapters,
G. Lee, W. Jang, J. H. Kim, J. Jung, and S. Kim, “Domain generalization using large pretrained models with mixture-of-adapters,”arXiv preprint arXiv:2310.11031, 2023
arXiv 2023
-
[19]
Ptp: Boosting stability and per- formance of prompt tuning with perturbation-based regularizer,
L. Chen, H. Huang, and M. Cheng, “Ptp: Boosting stability and per- formance of prompt tuning with perturbation-based regularizer,”arXiv preprint arXiv:2305.02423, 2023
arXiv 2023
-
[20]
P. Saha, C. Rajbangshi, R. Goyal, M. Goyal, A. Deo, B. Roy, N. D. Singh, R. Goswami, and A. Das, “Grit–geometry-aware peft with k- facpreconditioning, fisher-guided reprojection, anddynamic rank adapta- tion,”arXiv preprint arXiv:2601.00231, 2026
arXiv 2026
-
[21]
Sharpness-aware minimization efficiently selects flatter minima late in training,
Z. Zhou, M. Wang, Y . Mao, B. Li, and J. Yan, “Sharpness-aware minimization efficiently selects flatter minima late in training,” in International Conference on Learning Representations, vol. 2025, 2025, pp. 20 949–20 980
2025
-
[22]
Parameter-efficient transfer learning for nlp,
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for nlp,” inInternational conference on machine learning. PMLR, 2019, pp. 2790–2799
2019
-
[23]
Adamix: Mixture-of-adapter for parameter-efficient tuning of large language models,
Y . Wang, S. Mukherjee, X. Liu, J. Gao, A. H. Awadallah, and J. Gao, “Adamix: Mixture-of-adapter for parameter-efficient tuning of large language models,”arXiv preprint arXiv:2205.12410, vol. 1, no. 2, p. 4, 2022
arXiv 2022
-
[24]
H. Lin, J. Cho, A. Zala, and M. Bansal, “Ctrl-adapter: An efficient and versatile framework for adapting diverse controls to any diffusion model,”arXiv preprint arXiv:2404.09967, 2024
arXiv 2024
-
[25]
Adapter-x: A novel general parameter-efficient fine-tuning framework for vision,
M. Li, P. Ye, Y . Huang, L. Zhang, T. Chen, T. He, J. Fan, and W. Ouyang, “Adapter-x: A novel general parameter-efficient fine-tuning framework for vision,”arXiv preprint arXiv:2406.03051, 2024
arXiv 2024
-
[26]
Prefix-tuning: Optimizing continuous prompts for generation,
X. L. Li and P. Liang, “Prefix-tuning: Optimizing continuous prompts for generation,”arXiv preprint arXiv:2101.00190, 2021
Pith/arXiv arXiv 2021
-
[27]
Visual prompt tuning,
M. Jia, L. Tang, B.-C. Chen, C. Cardie, S. Belongie, B. Hariharan, and S.-N. Lim, “Visual prompt tuning,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 709–727
2022
-
[28]
Cp-prompt: Composition-based cross-modal prompting for domain- incremental continual learning,
Y . Feng, Z. Tian, Y . Zhu, Z. Han, H. Luo, G. Zhang, and M. Song, “Cp-prompt: Composition-based cross-modal prompting for domain- incremental continual learning,” inProceedings of the 32nd ACM International Conference on Multimedia, MM 2024, Melbourne, VIC, Australia, 28 October 2024 - 1 November 2024. ACM, 2024, pp. 2729–2738
2024
-
[29]
Adalora: Adaptive budget allocation for parameter-efficient fine-tuning,
Q. Zhang, M. Chen, A. Bukharin, N. Karampatziakis, P. He, Y . Cheng, W. Chen, and T. Zhao, “Adalora: Adaptive budget allocation for parameter-efficient fine-tuning,”arXiv preprint arXiv:2303.10512, 2023
Pith/arXiv arXiv 2023
-
[30]
Lora+: Efficient low rank adaptation of large models,
S. Hayou, N. Ghosh, and B. Yu, “Lora+: Efficient low rank adaptation of large models,”arXiv preprint arXiv:2402.12354, 2024
arXiv 2024
-
[31]
Moelora: An moe-based parameter efficient fine-tuning method for multi-task medical applications,
Q. Liu, X. Wu, X. Zhao, Y . Zhu, D. Xu, F. Tian, and Y . Zheng, “Moelora: An moe-based parameter efficient fine-tuning method for multi-task medical applications,”arXiv preprint arXiv:2310.18339, 2023
arXiv 2023
-
[32]
S. Chen, Z. Jie, and L. Ma, “Llava-mole: Sparse mixture of lora experts for mitigating data conflicts in instruction finetuning mllms,”arXiv preprint arXiv:2401.16160, 2024
arXiv 2024
-
[33]
Self-regulating prompts: Foundational model adaptation without forgetting,
M. U. Khattak, S. T. Wasim, M. Naseer, S. Khan, M.-H. Yang, and F. S. Khan, “Self-regulating prompts: Foundational model adaptation without forgetting,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 15 190–15 200
2023
-
[34]
Consistency-guided prompt learning for vision- language models,
S. Roy and A. Etemad, “Consistency-guided prompt learning for vision- language models,”arXiv preprint arXiv:2306.01195, 2023
arXiv 2023
-
[35]
Make continual learning stronger via c-flat,
A. Bian, W. Li, H. Yuan, M. Wang, Z. Zhao, A. Lu, P. Ji, T. Feng et al., “Make continual learning stronger via c-flat,”Advances in Neural Information Processing Systems, vol. 37, pp. 7608–7630, 2024
2024
-
[36]
Pace: Marrying generalization in parameter-efficient fine-tuning with consistency regularization,
Y . Ni, S. Zhang, and P. Koniusz, “Pace: Marrying generalization in parameter-efficient fine-tuning with consistency regularization,”Ad- vances in Neural Information Processing Systems, vol. 37, pp. 61 238– 61 266, 2024
2024
-
[37]
Glad: Generalizable tuning for vision-language models,
Y . Peng, P. Wang, J. Liu, and S. Chen, “Glad: Generalizable tuning for vision-language models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 4310–4320
2025
-
[38]
Sharpness-aware minimization for efficiently improving generalization,
P. Foret, A. Kleiner, H. Mobahi, and B. Neyshabur, “Sharpness-aware minimization for efficiently improving generalization,”arXiv preprint arXiv:2010.01412, 2020
Pith/arXiv arXiv 2010
-
[39]
Gradient norm aware minimization seeks first-order flatness and improves generalization,
X. Zhang, R. Xu, H. Yu, H. Zou, and P. Cui, “Gradient norm aware minimization seeks first-order flatness and improves generalization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 20 247–20 257
2023
-
[40]
Parameter-efficient fine-tuning of large-scale pre-trained language models,
N. Ding, Y . Qin, G. Yang, F. Wei, Z. Yang, Y . Su, S. Hu, Y . Chen, C.- M. Chan, W. Chenet al., “Parameter-efficient fine-tuning of large-scale pre-trained language models,”Nature Machine Intelligence, 2023
2023
-
[41]
Opt: Open pre-trained transformer language models,
S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. Diab, X. Li, X. V . Linet al., “Opt: Open pre-trained transformer language models,”arXiv preprint arXiv:2205.01068, 2022
Pith/arXiv arXiv 2022
-
[42]
Llama: open and efficient foundation language models. arxiv,
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: open and efficient foundation language models. arxiv,”arXiv preprint arXiv:2302.13971, 2023
Pith/arXiv arXiv 2023
-
[43]
Superglue: A stickier benchmark for general- purpose language understanding systems,
A. Wang, Y . Pruksachatkun, N. Nangia, A. Singh, J. Michael, F. Hill, O. Levy, and S. Bowman, “Superglue: A stickier benchmark for general- purpose language understanding systems,”Advances in neural informa- tion processing systems, vol. 32, 2019
2019
-
[44]
Sci- enceqa: A novel resource for question answering on scholarly articles,
T. Saikh, T. Ghosal, A. Mittal, A. Ekbal, and P. Bhattacharyya, “Sci- enceqa: A novel resource for question answering on scholarly articles,” International Journal on Digital Libraries, vol. 23, no. 3, pp. 289–301, 2022
2022
-
[45]
Vizwiz grand challenge: Answering visual questions from blind people,
D. Gurari, Q. Li, A. J. Stangl, A. Guo, C. Lin, K. Grauman, J. Luo, and J. P. Bigham, “Vizwiz grand challenge: Answering visual questions from blind people,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3608–3617
2018
-
[46]
Iconqa: A new benchmark for abstract diagram understand- ing and visual language reasoning,
P. Lu, L. Qiu, J. Chen, T. Xia, Y . Zhao, W. Zhang, Z. Yu, X. Liang, and S.-C. Zhu, “Iconqa: A new benchmark for abstract diagram understand- ing and visual language reasoning,”arXiv preprint arXiv:2110.13214, 2021
arXiv 2021
-
[47]
Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models,
B. A. Plummer, L. Wang, C. M. Cervantes, J. C. Caicedo, J. Hocken- maier, and S. Lazebnik, “Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models,” inProceedings of the IEEE international conference on computer vision, 2015, pp. 2641– 2649
2015
-
[48]
Ok-vqa: A visual question answering benchmark requiring external knowledge,
K. Marino, M. Rastegari, A. Farhadi, and R. Mottaghi, “Ok-vqa: A visual question answering benchmark requiring external knowledge,” in Proceedings of the IEEE/cvf conference on computer vision and pattern recognition, 2019, pp. 3195–3204
2019
-
[49]
Ocr-vqa: Visual question answering by reading text in images,
A. Mishra, S. Shekhar, A. K. Singh, and A. Chakraborty, “Ocr-vqa: Visual question answering by reading text in images,” in2019 inter- national conference on document analysis and recognition (ICDAR). IEEE, 2019, pp. 947–952
2019
-
[50]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering,
Y . Goyal, T. Khot, D. Summers-Stay, D. Batra, and D. Parikh, “Making the v in vqa matter: Elevating the role of image understanding in visual question answering,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 6904–6913
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.