Cross-Modal Knowledge Distillation without Paired Data: Theoretical Foundation and Algorithm
Pith reviewed 2026-06-27 13:05 UTC · model grok-4.3
The pith
Cross-modal distillation succeeds without paired data by aligning feature and label distributions instead of matching samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
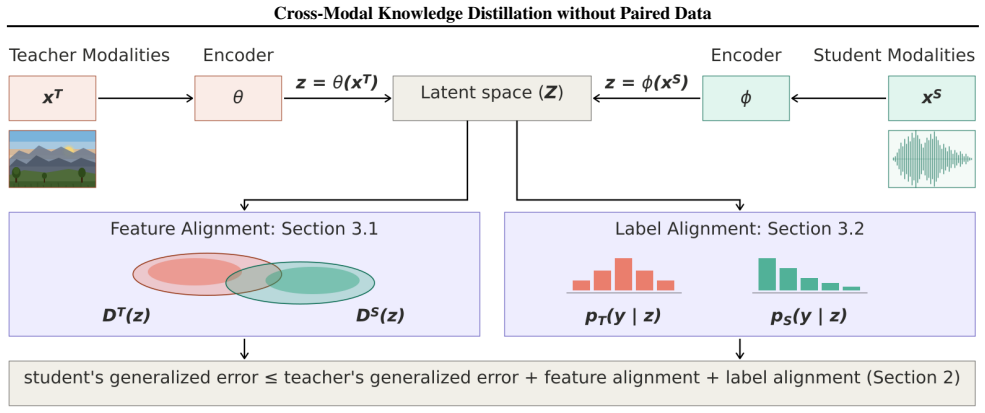
We establish a cross-modal distributional relationship between teacher and student models, which reveals two fundamental quantities governing effective distillation: feature alignment and label alignment. These quantities characterize semantic discrepancy between modalities at the levels of representation and prediction distributions, respectively. Motivated by this insight, we propose a principled framework, with theoretical guarantees, that enables effective cross-modal knowledge distillation by aligning distributions rather than individual samples.
What carries the argument
The cross-modal distributional relationship between teacher and student models that isolates feature alignment and label alignment as the quantities controlling distillation performance.
If this is right
- Distillation becomes feasible in settings where paired multi-modal data cannot be obtained.
- Distribution-level alignment replaces the need for sample-level matching across modalities.
- The same framework delivers gains in both unpaired and paired data regimes.
- Theoretical guarantees accompany the alignment procedure.
- Performance improves significantly over prior cross-modal distillation methods on standard benchmarks.
Where Pith is reading between the lines
- The same alignment principle could be chained across three or more modalities without requiring any direct pairings.
- Quantifying semantic discrepancy at the distribution level may apply to other transfer settings such as domain adaptation between entirely different data formats.
- If the relationship holds, it opens the possibility of distilling from generative models trained on one modality to discriminative models on another.
Load-bearing premise
A cross-modal distributional relationship exists between the modalities and aligning the resulting feature and label distributions is sufficient for effective distillation without any paired data.
What would settle it
An experiment in which a student model trained by aligning feature and label distributions on unpaired data shows no improvement over a student trained from scratch on the same target modality would falsify the central claim.
Figures
read the original abstract
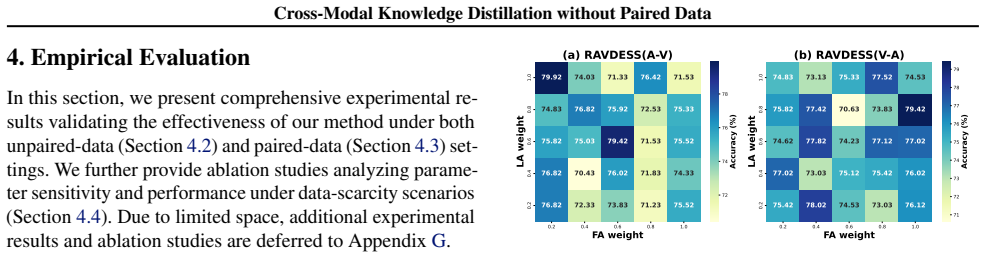
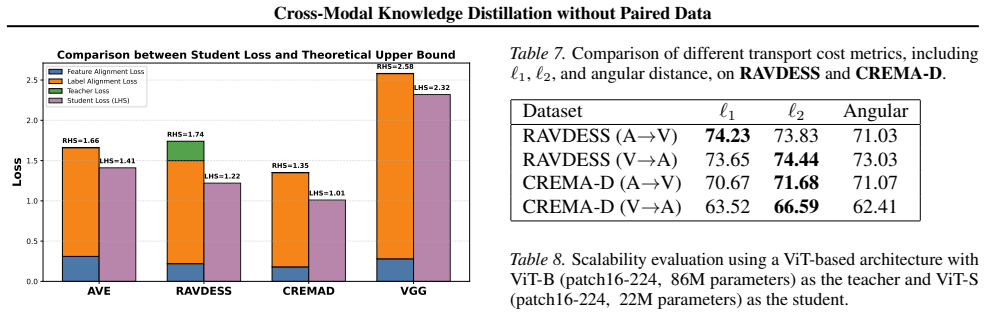
Cross-modal knowledge distillation (CMKD) studies how a (large) teacher model trained on one type of data (e.g., images) can guide a (smaller) student model building on another type of data (e.g., text/audio). Existing CMKD methods often require paired multi-modal data with aligned semantics, but obtaining such paired data are often costly and impractical. To mitigate this limitation, we develop a new CMKD framework for the more challenging setting where paired data are unavailable. In particular, we establish a cross-modal distributional relationship between teacher and student models, which reveals two fundamental quantities governing effective distillation: feature alignment and label alignment. These quantities characterize semantic discrepancy between modalities at the levels of representation and prediction distributions, respectively. Motivated by this insight, we propose a principled framework, with theoretical guarantees, that enables effective cross-modal knowledge distillation by aligning distributions rather than individual samples. Extensive experiments across a wide range of multimodal benchmarks show that our framework is highly effective in both unpaired and paired data settings, improving significantly over prior work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to develop a CMKD framework for unpaired data by deriving a cross-modal distributional relationship between teacher (one modality) and student (another modality) models. This relationship is said to identify feature alignment and label alignment as the two governing quantities for effective distillation. The authors propose a distribution-alignment algorithm with theoretical guarantees and report empirical gains over prior work on multimodal benchmarks in both unpaired and paired settings.
Significance. If the claimed distributional relationship can be rigorously derived from marginal distributions alone without hidden joint or correspondence assumptions, the work would enable practical CMKD in settings where paired data are unavailable, addressing a key limitation of existing methods.
major comments (2)
- [Abstract, §3] Abstract and §3 (theoretical foundation): the central claim that a cross-modal distributional relationship can be established from unpaired marginals alone must be shown explicitly. The skeptic note raises that the derivation may implicitly require joint terms or correspondences; the proof steps establishing identifiability without any paired samples or shared latent variables need to be provided and verified, as this is load-bearing for the sufficiency of distribution alignment.
- [§4] §4 (algorithm): the proposed alignment procedure is motivated by the two quantities, but without the derivation in §3 being free of joint-distribution assumptions, the theoretical guarantees for the unpaired case cannot be assessed. Please clarify whether any step in the algorithm or its analysis reintroduces implicit pairing.
minor comments (1)
- Notation for feature and label distributions should be defined consistently across sections to avoid ambiguity when moving from the theoretical relationship to the alignment objectives.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments correctly identify that the core theoretical claim requires fully explicit derivation from marginals alone. We address both points below and will incorporate the requested clarifications and expanded proofs.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (theoretical foundation): the central claim that a cross-modal distributional relationship can be established from unpaired marginals alone must be shown explicitly. The skeptic note raises that the derivation may implicitly require joint terms or correspondences; the proof steps establishing identifiability without any paired samples or shared latent variables need to be provided and verified, as this is load-bearing for the sufficiency of distribution alignment.
Authors: We agree that the identifiability argument must be presented with complete transparency. The derivation in §3 begins from the two marginal distributions and proceeds via a chain of inequalities that bound the cross-modal discrepancy using only quantities computable from each marginal separately (specifically, via the triangle inequality on a chosen divergence and properties of the label marginals). No joint distribution or correspondence is invoked. To eliminate any ambiguity, the revised manuscript will insert a dedicated lemma sequence that (i) states the precise assumptions, (ii) shows each algebraic step, and (iii) explicitly notes where joint information is provably unnecessary. We will also add a short remark addressing the skeptic’s concern directly. revision: yes
-
Referee: [§4] §4 (algorithm): the proposed alignment procedure is motivated by the two quantities, but without the derivation in §3 being free of joint-distribution assumptions, the theoretical guarantees for the unpaired case cannot be assessed. Please clarify whether any step in the algorithm or its analysis reintroduces implicit pairing.
Authors: The algorithm operates exclusively on unpaired batches drawn from each modality’s marginal; the loss terms are expectations over these separate batches and contain no cross-modal sample matching. The convergence analysis likewise relies only on the marginal alignment bounds established in §3. Nevertheless, we acknowledge that the current write-up does not spell out this separation at every step. In the revision we will add an explicit paragraph in §4.2 stating that no pairing is used or assumed, together with a short proof sketch showing that the same marginal-based guarantees carry through to the optimization procedure. revision: yes
Circularity Check
No significant circularity detected; derivation remains self-contained
full rationale
The paper's central step is establishing a cross-modal distributional relationship between teacher and student models that identifies feature alignment and label alignment as the governing quantities for unpaired distillation. No equations, definitions, or load-bearing claims in the abstract or described framework reduce this relationship to a fitted parameter, a self-citation chain, or an input by construction. The relationship is presented as derived from distributional properties of the separate modalities, with subsequent alignment motivated by that derivation rather than presupposing the target result. Experiments are described as providing independent validation across benchmarks. This satisfies the criteria for a non-circular theoretical foundation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SurFree: a fast surrogate-free black-box attack,
URL https://api.semanticscholar. org/CorpusID:216522760. Chen, P., Liu, S., Zhao, H., and Jia, J. Distilling knowledge via knowledge review. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5006–5015, 2021. doi: 10.1109/CVPR46437.2021. 00497. Damodaran, B., Kellenberger, B., Flamary, R., Tuia, D., and Courty, N. Deepjdot: ...
-
[2]
Distilling the Knowledge in a Neural Network
URL https://api.semanticscholar. org/CorpusID:6719686. Gupta, S., Hoffman, J., and Malik, J. Cross modal distillation for supervision transfer.2016 IEEE Con- ference on Computer Vision and Pattern Recognition (CVPR), pp. 2827–2836, 2015. URL https://api. semanticscholar.org/CorpusID:6832420. He, K., Zhang, X., Ren, S., and Sun, J. Deep resid- ual learning...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/cvpr52733.2024.01515 2016
-
[3]
Liu, T., Lam, K.-M., Zhao, R., and Qiu, G
URL https://openreview.net/forum? id=prQT0gN81oG. Liu, T., Lam, K.-M., Zhao, R., and Qiu, G. Deep cross-modal representation learning and distillation for illumination-invariant pedestrian detection.IEEE Trans- actions on Circuits and Systems for Video Technology, 32 (1):315–329, 2022. doi: 10.1109/TCSVT.2021.3060162. Liu, X., LI, L., Li, C., and Yao, A. ...
-
[4]
Fernando López, Santosh Kesiraju, and Jordi Luque
doi: 10.1371/journal.pone.0196391. Lv, J., Yang, H., and Li, P. Wasserstein distance rivals kullback-leibler divergence for knowledge distillation. InThe Thirty-eighth Annual Conference on Neural In- formation Processing Systems, 2024. URL https: //openreview.net/forum?id=1qfdCAXn6K. Menon, A. K., Rawat, A. S., Reddi, S., Kim, S., and Kumar, S. A statisti...
-
[5]
Mohri, M., Rostamizadeh, A., and Talwalkar, A.Foun- dations of Machine Learning
URL https://proceedings.mlr.press/ v139/menon21a.html. Mohri, M., Rostamizadeh, A., and Talwalkar, A.Foun- dations of Machine Learning. Adaptive Computation and Machine Learning series. MIT Press, 2012. ISBN 9780262018258. URL https://books.google. com.vn/books?id=maz6AQAAQBAJ. Nguyen, C. V ., Hassner, T., Archambeau, C., and Seeger, M. W. Leep: A new mea...
2012
-
[6]
org/CorpusID:211572839
URL https://api.semanticscholar. org/CorpusID:211572839. Park, W., Kim, D., Lu, Y ., and Cho, M. Relational knowledge distillation.2019 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pp. 3962–3971, 2019. URL https: //api.semanticscholar.org/CorpusID: 131765296. Peng, X., Wei, Y ., Deng, A., Wang, D., and Hu, D. Bal- anced multimo...
2019
-
[7]
URL https://api.semanticscholar. org/CorpusID:247779156. Peyr´e, G. and Cuturi, M. Computational optimal trans- port, 2020. URL https://arxiv.org/abs/1803. 00567. Roheda, S., Riggan, B. S., Krim, H., and Dai, L. Cross- modality distillation: A case for conditional generative adversarial networks. In2018 IEEE International Con- ference on Acoustics, Speech...
-
[8]
org/CorpusID:254017839
URL https://api.semanticscholar. org/CorpusID:254017839. Sun, W., Chen, D., Lyu, S., Chen, G., Chen, C., and Wang, C. Knowledge distillation with re- fined logits.2025 IEEE/CVF International Confer- ence on Computer Vision (ICCV), pp. 1110–1119,
2025
-
[9]
2021 IEEE/CVF International Conference on Computer Vision (ICCV) , author=
URL https://api.semanticscholar. org/CorpusID:271865571. 11 Cross-Modal Knowledge Distillation without Paired Data Tian, Y ., Shi, J., Li, B., Duan, Z., and Xu, C. Audio-visual event localization in unconstrained videos. InThe Euro- pean Conference on Computer Vision (ECCV), September 2018. Tian, Y ., Krishnan, D., and Isola, P. Contrastive representa- ti...
-
[10]
In: IEEE/CVF International Conference on Computer Vision
URL https://api.semanticscholar. org/CorpusID:252668904. Yang, P., Xie, M.-K., Zong, C.-C., Feng, L., Niu, G., Sugiyama, M., and Huang, S.-J. Multi-label knowledge distillation. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 17225–17234, 2023. doi: 10.1109/ICCV51070.2023.01584. Yun, H., Na, J., and Kim, G. Dense 2d-3d indoor predi...
-
[11]
BoundingA. We have: A=E DS(z)EDS(y|z) h −log(p S(y|z)) i −E DS(z)EDT (y|z) h −log(p T (y|z)) i (26) =E DS(z) h EDS(y|z) h −log(p S(y|z)) i −E DT (y|z) h −log(p T (y|z)) ii (27) =E DS(z) h − X y∈Y DS(y|z) log(p S(y|z))−D T (y|z) log(p T (y|z)) i (28) =E DS(z)EDS(y|z) h −log(p S(y|z)) + DT (y|z) DS(y|z) log(pT (y|z)) i (29) With a mild assumption DS(y|z)>0 ...
-
[12]
BoundingB. We have: B=E DS(z)EDT (y|z) h −log(p T (y|z)) i −E DT (z)EDT (y|z) h −log(p T (y|z)) i (31) =E DS(z) h ℓτ(z) i −E DT (z) h ℓτ(z) i (32) where ℓτ(z)≜E DT (y|z) h −log(p T (y|z)) i is the cross-entropy of the teacher prediction as Definition 2.4. For any cost metricδ∈∆such that|ℓ τ(z1)−ℓ τ(z2)| ≤τ δ ·δ(z 1,z 2), the Kantorovich-Rubinstein duality...
-
[13]
We start with the Rademacher bound (Koltchinskii & Panchenko, 2000), which is stated as follows
Rademacher Bounds. We start with the Rademacher bound (Koltchinskii & Panchenko, 2000), which is stated as follows. Rademacher Bounds. Let F is the family of functions mapping from Z to [0,1] . Then for any 0< δ <1 , with probability at least1−δover sampleS={z 1,· · ·, z n}, the following holds for allf∈ F: E[f]≤ 1 n nX i=1 f(z i) + 2Rn(F) + r log(1/δ) 2n...
2000
-
[14]
Feature Alignment (FA) is formulated asWasserstein Distancewith the momentum p= 1 , cost metric δ, and high dimension d >1
Bounding Wasserstein distance. Feature Alignment (FA) is formulated asWasserstein Distancewith the momentum p= 1 , cost metric δ, and high dimension d >1 . For clear notation, we introduce two true probability distributions ν and µ with their empirical distributions ˆνn and ˆµm which provided by n and m data points, respectively. Using the triangle inequa...
2019
-
[15]
Bounding Label Alignment. Denotingf(z, y)≜−log pS(y|z) pT (y|z) κ(y,z) , we then express Label Alignment (LA) as: LA≜E DS(z,y) h −log pS(y|z) pT (y|z) κ(y,z) i =E DS(z,y) h f(z, y) i (45) With the mild assumption that the class function f∈ F is upper-bounded by a constraint C3 >0 , we can scale the function f to [0,1] by dividing by C3 and denote the new ...
2000
-
[16]
In the Offline CMKD setting, the teacher error is fixed due to the fixed teacher backbone during the distillation process
Bounding the generalized student error on Offline CMKD. In the Offline CMKD setting, the teacher error is fixed due to the fixed teacher backbone during the distillation process. We can treat the teacher’s error as the fixed overhead, then combining E.q(44), and E.q (46), given 0≤δ≤1/3 , the teacher and the student empirical distribution DT nT (z) and DS ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.