SkillAxe: Sharpening LLM-Authored Agent Skills Through Evaluation-Guided Self-Refinement
Pith reviewed 2026-06-27 11:20 UTC · model grok-4.3
The pith
SkillAxe enables LLMs to refine their own agent skills by breaking quality into four dimensions and generating improvement briefs without labels or rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SkillAxe decomposes skill quality into four interpretable dimensions (quality impact, trigger precision, instruction compliance with fault attribution, and solution-path coverage), producing structured improvement briefs that require no ground-truth labels, test suites, or environment rewards and enable iterative self-refinement of LLM-authored agent skills.
What carries the argument
The four dimensions of skill quality that produce structured improvement briefs without ground-truth labels, test suites, or environment rewards.
If this is right
- LLM-authored skills achieve a 28% relative pass-rate increase on SkillsBench.
- 47-67% of the performance gap to human-authored skills is closed.
- A SkillAxe-built library raises pass rates from 16.0% to 52.0% on SpreadsheetBench using 22 skills.
- Skill libraries improve continuously by incorporating lessons from past agent trajectories without external supervision.
Where Pith is reading between the lines
- The same decomposition could be reused to refine other structured agent outputs such as plans or code snippets.
- Over repeated cycles the method could reduce the need for human experts to author initial skills.
- Adding a fifth dimension focused on execution cost might produce more efficient skills as a side effect.
- Embedding the loop inside live agent deployments could yield systems that steadily improve from their own usage data.
Load-bearing premise
The LLM can reliably assess the four dimensions and produce useful improvement briefs without ground-truth labels, test suites, or environment rewards.
What would settle it
Applying SkillAxe to a held-out benchmark where the refined skills show no pass-rate gain or a decline relative to the original LLM skills would falsify the central claim.
Figures

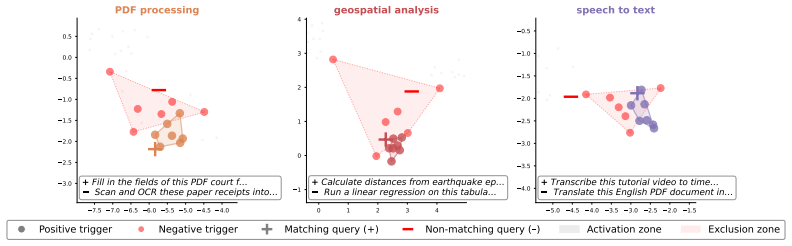
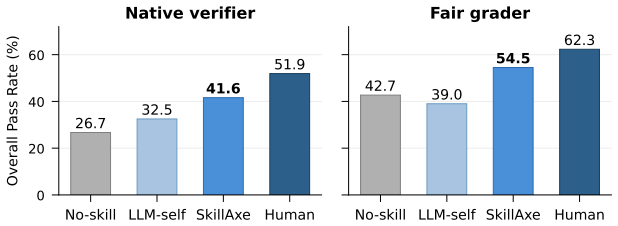
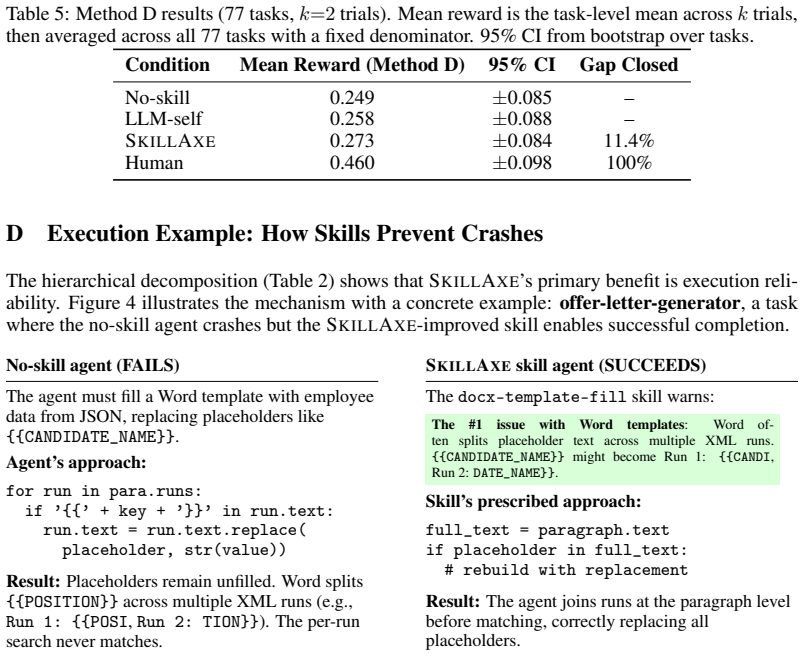

read the original abstract
Skill documents, structured natural-language instructions that guide Large Language Model (LLM) agents, are critical to modern agent frameworks, yet LLMs struggle to write skills that actually work. On SkillsBench, human-authored skills improve pass rates by 16.2 percentage points, while LLM-authored skills provide no measurable gain. We introduce SkillAxe, a fully unsupervised framework that enables LLMs to iteratively diagnose and refine their own skills. SkillAxe decomposes skill quality into four interpretable dimensions (quality impact, trigger precision, instruction compliance with fault attribution, and solution-path coverage), producing structured improvement briefs that require no ground-truth labels, test suites, or environment rewards. On SkillsBench, SkillAxe improves pass rates by 28\% relative over unimproved LLM skills and closes 47--67\% of the gap to human-authored skills. We validate the approach as a continuous improvement engine in the wild on SpreadsheetBench, where a SkillAxe-built skill library learns from past agent trajectories and raises pass rate from 16.0\% to 52.0\% using only 22 skills.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SkillAxe, an unsupervised framework enabling LLMs to iteratively diagnose and refine their own structured skill documents by decomposing quality into four dimensions (quality impact, trigger precision, instruction compliance with fault attribution, and solution-path coverage) and generating improvement briefs. It claims that on SkillsBench this yields a 28% relative pass-rate improvement over unimproved LLM skills while closing 47-67% of the gap to human-authored skills, and that on SpreadsheetBench a SkillAxe-built library of 22 skills raises pass rate from 16.0% to 52.0% by learning from past trajectories.
Significance. If the empirical claims hold under proper statistical controls and external validation, the work would offer a practical, label-free mechanism for continuous skill improvement in LLM agent systems, addressing a documented gap between human- and LLM-authored skills on existing benchmarks.
major comments (2)
- [Abstract] Abstract: the central empirical claims (28% relative gain on SkillsBench; 16.0%→52.0% lift on SpreadsheetBench) are presented without any report of statistical significance, variance across runs, number of trials, or controls for post-hoc skill selection, rendering the magnitude and reliability of the reported improvements unverifiable from the given text.
- [Abstract] Abstract: the method's load-bearing assumption—that LLM self-scoring on the four dimensions produces reliable improvement briefs without ground-truth labels, test suites, or environment rewards—is stated but not supported by any cross-validation against held-out human ratings or alternate evaluators, leaving open the possibility that gains reflect self-reinforcement rather than genuine sharpening.
minor comments (1)
- [Abstract] The abstract does not define how the four dimensions are scored or aggregated into briefs; adding a short operational description would improve clarity.
Simulated Author's Rebuttal
We thank the referee for highlighting issues in the abstract. We address each comment below with targeted revisions where the manuscript can be strengthened without altering its core unsupervised claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claims (28% relative gain on SkillsBench; 16.0%→52.0% lift on SpreadsheetBench) are presented without any report of statistical significance, variance across runs, number of trials, or controls for post-hoc skill selection, rendering the magnitude and reliability of the reported improvements unverifiable from the given text.
Authors: We agree the abstract should convey experimental reliability. The full manuscript reports results from multiple independent runs with variance, and skill refinement occurs iteratively without post-hoc selection or cherry-picking. We will revise the abstract to state the number of trials and note consistency of the reported relative gains. revision: yes
-
Referee: [Abstract] Abstract: the method's load-bearing assumption—that LLM self-scoring on the four dimensions produces reliable improvement briefs without ground-truth labels, test suites, or environment rewards—is stated but not supported by any cross-validation against held-out human ratings or alternate evaluators, leaving open the possibility that gains reflect self-reinforcement rather than genuine sharpening.
Authors: SkillAxe is designed as an unsupervised method precisely to avoid reliance on labels or external rewards. Validation comes from downstream task performance: the 28% relative lift on SkillsBench closes 47-67% of the gap to human-authored skills, and the SpreadsheetBench result (16% to 52%) demonstrates practical gains when the refined library is deployed on unseen trajectories. These external benchmarks provide evidence against pure self-reinforcement, as improvements translate to measurable agent success. revision: no
Circularity Check
No significant circularity; gains measured on external benchmarks
full rationale
The paper describes an unsupervised self-refinement loop in which an LLM generates structured improvement briefs by scoring its own skills along four dimensions, then applies those briefs to produce revised skills. The reported outcomes (28% relative pass-rate lift on SkillsBench; 16%→52% lift on SpreadsheetBench) are obtained by executing the resulting agent skills on held-out benchmark tasks and counting successes, not by feeding the LLM's internal dimension scores back into the metric. No equations, parameter fits, or self-citations appear in the provided text that would reduce the claimed improvement to a definitional identity or to a prior result authored by the same team. The evaluation therefore remains externally falsifiable and independent of the refinement procedure itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four dimensions (quality impact, trigger precision, instruction compliance with fault attribution, solution-path coverage) suffice to diagnose and improve LLM-authored skills without external supervision
Reference graph
Works this paper leans on
-
[1]
Build effective agents: Custom tools and skills.https://docs.anthropic
Anthropic. Build effective agents: Custom tools and skills.https://docs.anthropic. com/en/docs/build-with-claude/tool-use, 2025. Accessed: 2026-05-01
2025
-
[2]
Renjun Xu and Yang Yan. Agent skills for large language models: Architecture, acquisition, security, and the path forward.arXiv preprint arXiv:2602.12430, 2026
Pith/arXiv arXiv 2026
-
[3]
SoK: Agentic skills – beyond tool use in LLM agents.arXiv preprint arXiv:2602.20867, 2026
Yanna Jiang, Delong Li, Haiyu Deng, Baihe Ma, Xu Wang, Qin Wang, and Guangsheng Yu. SoK: Agentic skills – beyond tool use in LLM agents.arXiv preprint arXiv:2602.20867, 2026
Pith/arXiv arXiv 2026
-
[4]
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, Shuyi Wang, Binxu Li, Qunhong Zeng, Di Wang, Xuandong Zhao, Yuanli Wang, Roey Ben Chaim, Zonglin Di, Yipeng Gao, Junwei He, Yizhuo He, Liqiang Jing, Luyang Kong, Xin Lan, Jiachen Li, Songlin Li, Yijiang Li, Yueqian Lin, Xinyi Liu, X...
Pith/arXiv arXiv 2026
-
[5]
Testing agent skills systematically with evals.https://developers.openai
OpenAI. Testing agent skills systematically with evals.https://developers.openai. com/blog/eval-skills, 2026. Accessed: 2026-05-01
2026
-
[6]
Evaluating skills.https://www.langchain.com/blog/evaluating-skills,
LangChain. Evaluating skills.https://www.langchain.com/blog/evaluating-skills,
-
[7]
Accessed: 2026-05-01
2026
-
[8]
Yujian Liu, Jiabao Ji, Li An, Tommi Jaakkola, Yang Zhang, and Shiyu Chang. How well do agentic skills work in the wild: Benchmarking LLM skill usage in realistic settings.arXiv preprint arXiv:2604.04323, 2026
Pith/arXiv arXiv 2026
-
[9]
SkillCraft: Can LLM agents learn to use tools skillfully? arXiv preprint arXiv:2603.00718, 2026
Shiqi Chen, Jingze Gai, Ruochen Zhou, Jinghan Zhang, Tongyao Zhu, Junlong Li, Kangrui Wang, Zihan Wang, Zhengyu Chen, Klara Kaleb, Ning Miao, Siyang Gao, Cong Lu, Manling Li, Junxian He, and Yee Whye Teh. SkillCraft: Can LLM agents learn to use tools skillfully? arXiv preprint arXiv:2603.00718, 2026
arXiv 2026
-
[10]
Excel copilot agent.https://www.microsoft.com, 2025
Microsoft Corporation. Excel copilot agent.https://www.microsoft.com, 2025. Ac- cessed: 2026-05-01
2025
-
[11]
SpreadsheetBench: Towards challenging real world spreadsheet ma- nipulation
Zeyao Ma, Bohan Zhang, Jing Zhang, Jifan Yu, Xiaokang Zhang, Xiaohan Zhang, Sijia Luo, Xi Wang, and Jie Tang. SpreadsheetBench: Towards challenging real world spreadsheet ma- nipulation. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2024
2024
-
[12]
V oyager: An open-ended embodied agent with large language models.Transactions on Machine Learning Research, 2024
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.Transactions on Machine Learning Research, 2024
2024
-
[13]
Jiongxiao Wang, Qiaojing Yan, Yawei Wang, Yijun Tian, Soumya Smruti Mishra, Zhichao Xu, Megha Gandhi, Panpan Xu, and Lin Lee Cheong. Reinforcement learning for self-improving agent with skill library.arXiv preprint arXiv:2512.17102, 2025
Pith/arXiv arXiv 2025
-
[14]
SkillAct: Using skill abstractions improves LLM agents
Anthony Zhe Liu, Jongwook Choi, Sungryull Sohn, Yao Fu, Jaekyeom Kim, Dong-Ki Kim, Xinhe Wang, Jaewon Yoo, and Honglak Lee. SkillAct: Using skill abstractions improves LLM agents. InICML 2024 Workshop on LLMs and Cognition, 2024
2024
-
[15]
SkillRouter: Skill routing for LLM agents at scale.arXiv preprint arXiv:2603.22455, 2026
YanZhao Zheng, ZhenTao Zhang, Chao Ma, YuanQiang Yu, JiHuai Zhu, Wu Yong, Tianze Xu, Baohua Dong, Hangcheng Zhu, Ruohui Huang, and Gang Yu. SkillRouter: Skill routing for LLM agents at scale.arXiv preprint arXiv:2603.22455, 2026
arXiv 2026
-
[16]
SkillNet: Create, evaluate, and connect AI skills.arXiv preprint arXiv:2603.04448, 2026
Yuan Liang, Ruobin Zhong, Haoming Xu, Chen Jiang, Yi Zhong, Runnan Fang, Jia-Chen Gu, Shumin Deng, Yunzhi Yao, Mengru Wang, et al. SkillNet: Create, evaluate, and connect AI skills.arXiv preprint arXiv:2603.04448, 2026. 10
arXiv 2026
-
[17]
Xiyang Wu, Zongxia Li, Guangyao Shi, Alexander Duffy, Tyler Marques, Matthew Lyle Olson, Tianyi Zhou, and Dinesh Manocha. Co-evolving LLM decision and skill bank agents for long- horizon tasks.arXiv preprint arXiv:2604.20987, 2026
Pith/arXiv arXiv 2026
-
[18]
Yudong Gao, Zongjie Li, Yuanyuan Yuan, Zimo Ji, Pingchuan Ma, and Shuai Wang. SkillRe- ducer: Optimizing LLM agent skills for token efficiency.arXiv preprint arXiv:2603.29919, 2026
Pith/arXiv arXiv 2026
-
[19]
Jingzhi Gong, Ruizhen Gu, Zhiwei Fei, Yazhuo Cao, Lukas Twist, Alina Geiger, Shuo Han, Dominik Sobania, Federica Sarro, and Jie M. Zhang. SkillMOO: Multi-objective optimization of agent skills for software engineering.arXiv preprint arXiv:2604.09297, 2026
Pith/arXiv arXiv 2026
-
[20]
Large language models are human-level prompt engineers
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human-level prompt engineers. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[21]
Large language models as optimizers
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. InInternational Conference on Learning Repre- sentations (ICLR), 2024
2024
-
[22]
Prashant Trivedi, Souradip Chakraborty, Avinash Reddy, Vaneet Aggarwal, Amrit Singh Bedi, and George K. Atia. Align-pro: a principled approach to prompt optimization for llm align- ment. InProceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifte...
2025
-
[23]
Optimizing generative ai by backpropagating language model feed- back.Nature, 639:609–616, 2025
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Pan Lu, Zhi Huang, Carlos Guestrin, and James Zou. Optimizing generative ai by backpropagating language model feed- back.Nature, 639:609–616, 2025
2025
-
[24]
Trace is the next AutoDiff: Gener- ative optimization with rich feedback, execution traces, and LLMs
Ching-An Cheng, Allen Nie, and Adith Swaminathan. Trace is the next AutoDiff: Gener- ative optimization with rich feedback, execution traces, and LLMs. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[25]
Re- flexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Re- flexion: Language agents with verbal reinforcement learning. InAdvances in Neural Informa- tion Processing Systems (NeurIPS), 2023
2023
-
[26]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegr- effe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bod- hisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing...
2023
-
[27]
Agentrefine: Enhancing agent general- ization through refinement tuning
Dayuan Fu, Keqing He, Yejie Wang, Wentao Hong, Zhuoma GongQue, Weihao Zeng, Wei Wang, Jingang Wang, Xunliang Cai, and Weiran Xu. Agentrefine: Enhancing agent general- ization through refinement tuning. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors, International Conference on Learning Representations, volume 2025, pages 65185–65204, 2025
2025
-
[28]
Which agent causes task failures and when? on automated failure attribution of LLM multi-agent systems
Shaokun Zhang, Ming Yin, Jieyu Zhang, Jiale Liu, Zhiguang Han, Jingyang Zhang, Beibin Li, Chi Wang, Huazheng Wang, Yiran Chen, and Qingyun Wu. Which agent causes task failures and when? on automated failure attribution of LLM multi-agent systems. InForty-second International Conference on Machine Learning, 2025
2025
-
[29]
Large language model instruction following: A survey of progresses and challenges.Computational Linguistics, 50(3):1053–1095, September 2024
Renze Lou, Kai Zhang, and Wenpeng Yin. Large language model instruction following: A survey of progresses and challenges.Computational Linguistics, 50(3):1053–1095, September 2024
2024
-
[30]
Protovae: A trustworthy self-explainable prototypical variational model
Srishti Gautam, Ahcène Boubekki, Stine Hansen, Suaiba Salahuddin, Robert Jenssen, Marina Höhne, and Michael Kampffmeyer. Protovae: A trustworthy self-explainable prototypical variational model. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, 11 editors,Advances in Neural Information Processing Systems, volume 35, pages 17940–17952. C...
2022
-
[31]
G- Eval: NLG evaluation using GPT-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G- Eval: NLG evaluation using GPT-4 with better human alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[32]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Syste...
arXiv 2023
-
[33]
Collects the agent’s output files from the Harbor workspace
-
[34]
Renders visual artifacts: Excel workbooks are converted to sheet-level images, PDFs are rendered page by page, and charts are exported as images
-
[35]
Constructs a multimodal prompt containing the task instruction, input file descriptions, and ren- dered output artifacts
-
[36]
A GPT-5.4 judge evaluates whether the agent substantively completed the task, producing a bi- nary completion judgment, a confidence score (0–1), and a brief reasoning trace. When only agent log extracts are available (no preserved output files), these are labeled asunverified intentand the grader defaults to incomplete unless the extracts contain actual ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.