VeriSpace: Spatially Grounded Action Verification for Vision-Language-Action Models
Pith reviewed 2026-06-27 12:46 UTC · model grok-4.3
The pith
VeriSpace adds dual-path 3D scene encoding and spatial reasoning to verify candidate actions before execution in VLA robotic systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
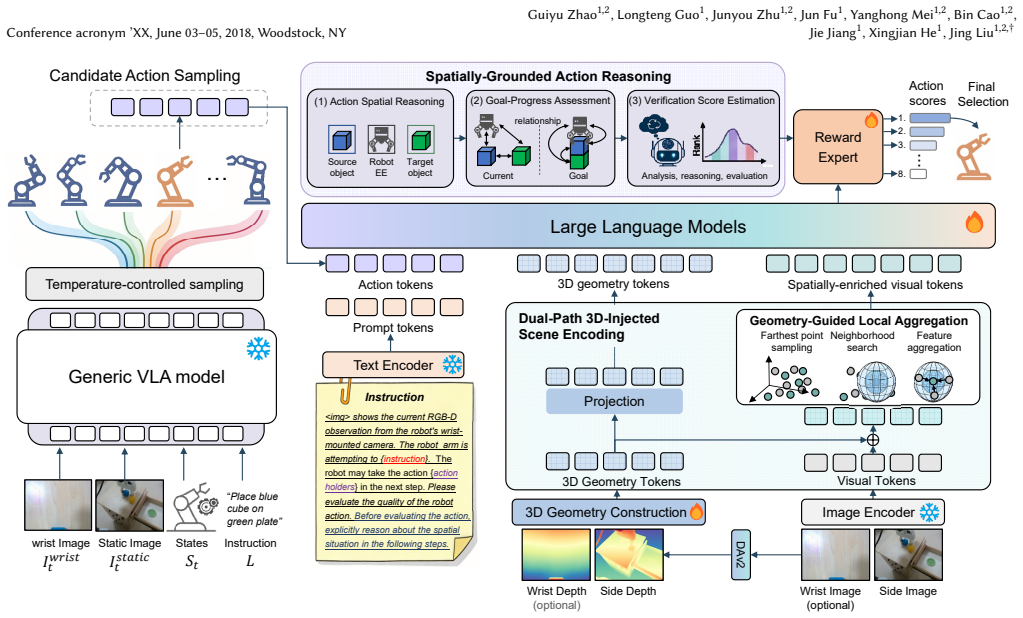
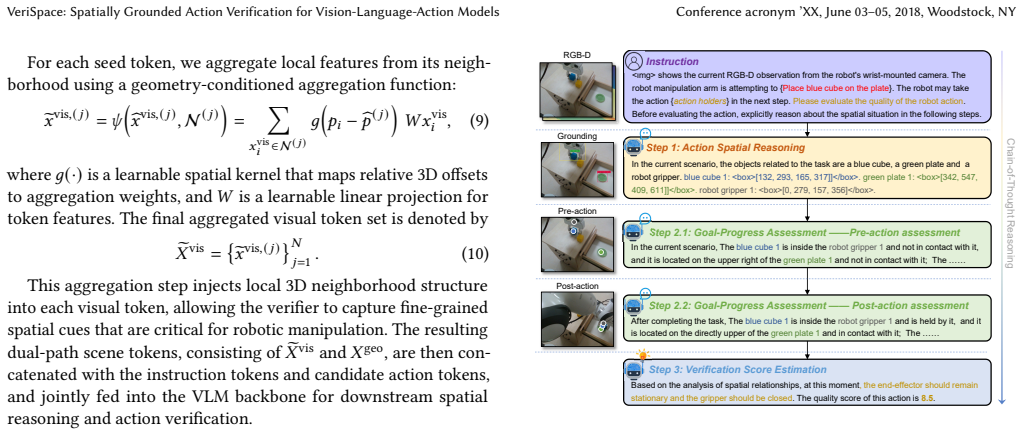
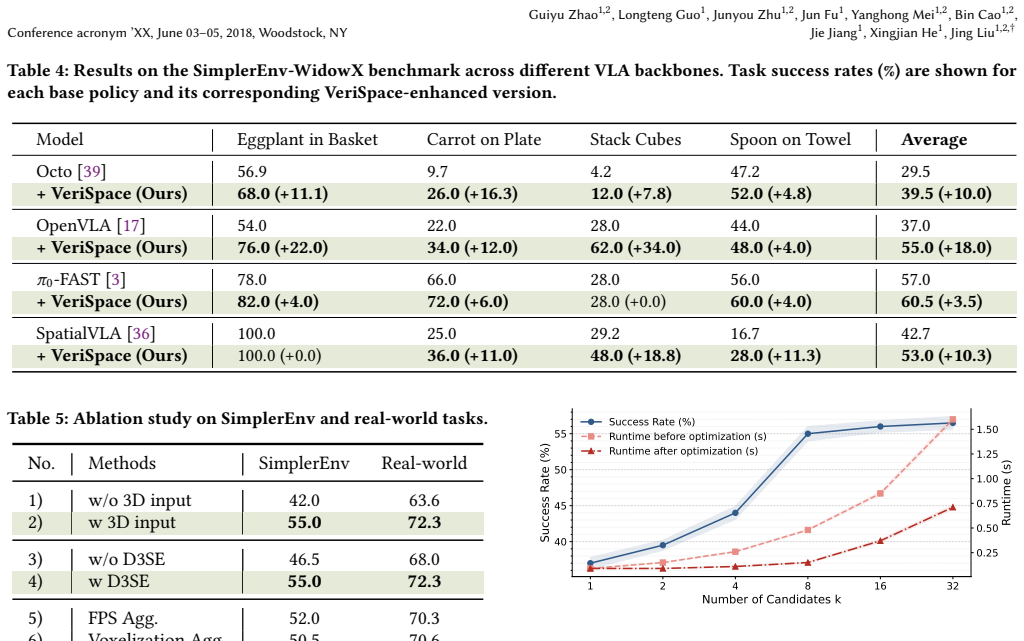
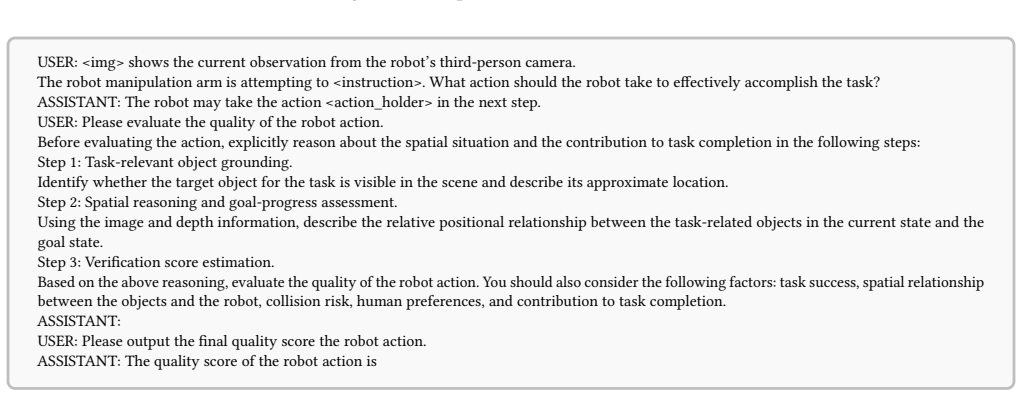
VeriSpace evaluates candidate actions for VLA systems through Dual-Path 3D-Injected Scene Encoding, which constructs a joint visual-semantic and explicit 3D geometric scene representation, and Spatially-Grounded Action Reasoning, which assesses each action on task-relevant spatial relations, geometric validity, and expected goal progress, enabling reliable selection among subtle yet outcome-critical candidates while remaining compatible with existing VLA policies.
What carries the argument
Dual-Path 3D-Injected Scene Encoding paired with Spatially-Grounded Action Reasoning, which together evaluate actions by preserving 3D geometry and checking progress toward the task goal.
If this is right
- Decision reliability increases over both the underlying VLA policy and earlier verification methods.
- Performance gains appear in both in-distribution and out-of-distribution robotic tasks.
- The verifier integrates with existing VLA policies without requiring retraining or architectural changes.
- The same components apply to public benchmarks and real-world manipulation setups.
Where Pith is reading between the lines
- Test-time verification of this form could reduce reliance on perfect one-shot prediction from the base model.
- The modular design suggests the verifier could be stacked on top of future VLA improvements.
- In deployed systems the approach might catch physically unsafe actions before they reach the robot.
Load-bearing premise
The dual-path encoding and spatial reasoning modules can reliably detect small geometric differences between candidate actions and judge whether an action advances the overall task goal.
What would settle it
A controlled test set of action candidates that differ only in subtle 3D geometry where VeriSpace selects the wrong action at rates no better than random or the base VLA policy.
Figures









read the original abstract
Vision-language-action (VLA) models have shown strong promise for robotic manipulation, but their reliability at test time remains limited by one-shot action prediction, where even small action errors can cause grasp failure, collision, or incorrect task progression. A natural alternative is to equip VLA systems with test-time verification, allowing multiple candidate actions to be proposed and evaluated before execution. However, reliable action verification is challenging because it requires not only distinguishing subtle geometric differences between candidate actions, but also assessing whether an action makes meaningful progress toward the task goal. We present VeriSpace, a 3D-aware action verifier for test-time action selection in VLA systems. VeriSpace evaluates candidate actions through two key components: Dual-Path 3D-Injected Scene Encoding, which constructs a scene representation that jointly preserves visual semantics and explicit 3D geometry, and Spatially-Grounded Action Reasoning, which evaluates each action by reasoning over task-relevant spatial relations, geometric validity, and expected goal progress. Together, these components enable more reliable discrimination between subtle yet outcome-critical action candidates while remaining fully compatible with existing VLA policies. Experiments on public benchmarks and real-world robotic manipulation tasks show that VeriSpace consistently improves decision reliability over both underlying VLA policies and prior verification-based methods, yielding substantial gains in both in-distribution and out-of-distribution settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VeriSpace, a test-time action verifier for vision-language-action (VLA) models in robotic manipulation. It consists of two components: Dual-Path 3D-Injected Scene Encoding, which builds a joint visual-semantic and explicit 3D geometric scene representation, and Spatially-Grounded Action Reasoning, which scores candidate actions on spatial relations, geometric validity, and task-goal progress. The verifier is designed to be compatible with existing VLA policies by evaluating multiple proposed actions before execution. The central claim is that this yields consistent reliability gains over base VLA policies and prior verification methods on public benchmarks and real-world tasks, in both in-distribution and out-of-distribution regimes.
Significance. If the claimed improvements are supported by rigorous experiments, the work would address a practical limitation of one-shot VLA prediction by adding lightweight, 3D-aware verification. The emphasis on compatibility with unmodified VLA policies and the focus on subtle geometric distinctions are plausible contributions to reliable robotic control. However, the provided manuscript text contains only the abstract and no methods, equations, ablations, quantitative tables, or experimental protocols, preventing any assessment of whether the dual-path encoding or spatial reasoning components actually deliver the stated gains.
major comments (1)
- [Abstract] Abstract: The central empirical claim (consistent improvements over VLA baselines and prior verifiers in ID/OOD settings) cannot be evaluated because the manuscript supplies no experimental setup, baselines, metrics, or results. This is load-bearing for the paper's contribution.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below, noting that the full manuscript (beyond the abstract) contains the requested details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim (consistent improvements over VLA baselines and prior verifiers in ID/OOD settings) cannot be evaluated because the manuscript supplies no experimental setup, baselines, metrics, or results. This is load-bearing for the paper's contribution.
Authors: The full manuscript includes dedicated Methods sections describing Dual-Path 3D-Injected Scene Encoding (with explicit 3D geometry injection and joint visual-semantic representations) and Spatially-Grounded Action Reasoning (with scoring over spatial relations, geometric validity, and goal progress). The Experiments section specifies public benchmarks, real-world tasks, baselines (base VLA policies and prior verification methods), metrics (success rate, reliability gains), and quantitative results demonstrating consistent improvements in both in-distribution and out-of-distribution regimes. These sections were available in the complete submission; if only the abstract was reviewed, we can supply the relevant excerpts or page references. revision: no
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe VeriSpace as an additive test-time verifier with two new components (Dual-Path 3D-Injected Scene Encoding and Spatially-Grounded Action Reasoning) layered on top of existing VLA policies. No derivation chain, equations, fitted parameters presented as predictions, uniqueness theorems, or self-citations are present. The central claim rests on experimental gains rather than any self-referential construction or reduction to inputs by definition. This is a standard non-circular presentation of an engineering addition to prior models.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Suneel Belkhale, Tianli Ding, Ted Xiao, Pierre Sermanet, Quon Vuong, Jonathan Tompson, Yevgen Chebotar, Debidatta Dwibedi, and Dorsa Sadigh. 2024. Rt-h: Action hierarchies using language.arXiv preprint arXiv:2403.01823(2024)
Pith/arXiv arXiv 2024
-
[2]
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschan- nen, Emanuele Bugliarello, et al. 2024. Paligemma: A versatile 3b vlm for transfer. arXiv preprint arXiv:2407.07726(2024)
Pith/arXiv arXiv 2024
-
[3]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. 2024. pi0: A Vision-Language-Action Flow Model for General Robot Control.arXiv preprint arXiv:2410.24164(2024)
Pith/arXiv arXiv 2024
-
[4]
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. 2022. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817(2022)
Pith/arXiv arXiv 2022
-
[5]
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christo- pher Ré, and Azalia Mirhoseini. 2024. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787(2024)
Pith/arXiv arXiv 2024
-
[6]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.NeurIPS33 (2020), 1877–1901
2020
-
[7]
Guoxin Chen, Minpeng Liao, Chengxi Li, and Kai Fan. 2024. Alphamath almost zero: Process supervision without process, 2024.URL https://arxiv. org/abs/2405.03553(2024)
arXiv 2024
-
[8]
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. 2024. Spatialrgpt: Grounded spatial reasoning in vision-language models.Advances in Neural Information Processing Systems37 (2024), 135062–135093
2024
-
[9]
Mingtong Dai, Lingbo Liu, Yongjie Bai, Yang Liu, Zhouxia Wang, Rui Su, Chunjie Chen, Liang Lin, and Xinyu Wu. 2025. RoVer: Robot Reward Model as Test- Time Verifier for Vision-Language-Action Model.arXiv preprint arXiv:2510.10975 (2025)
arXiv 2025
-
[10]
Runpei Dong, Chunrui Han, Yuang Peng, Zekun Qi, Zheng Ge, Jinrong Yang, Liang Zhao, Jianjian Sun, Hongyu Zhou, Haoran Wei, Xiangwen Kong, Xiangyu Zhang, Kaisheng Ma, and Li Yi. 2024. DreamLLM: Synergistic Multimodal Com- prehension and Creation. InICLR
2024
-
[11]
David Heineman, Yao Dou, and Wei Xu. 2024. Improving minimum Bayes risk decoding with multi-prompt. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 22525–22545
2024
-
[12]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.Iclr1, 2 (2022), 3
2022
-
[13]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al
-
[14]
arXiv preprint arXiv:2504.16054(2025)
pi0.5: a Vision-Language-Action Model with Open-World Generalization. arXiv preprint arXiv:2504.16054(2025)
Pith/arXiv arXiv 2025
-
[15]
Suhyeok Jang, Dongyoung Kim, Changyeon Kim, Youngsuk Kim, and Jinwoo Shin. 2025. Verifier-free Test-Time Sampling for Vision Language Action Models. arXiv preprint arXiv:2510.05681(2025)
arXiv 2025
-
[16]
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. 2024. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945(2024)
Pith/arXiv arXiv 2024
-
[17]
Moo Jin Kim, Chelsea Finn, and Percy Liang. 2025. Fine-tuning vision-language- action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645 (2025)
Pith/arXiv arXiv 2025
-
[18]
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakr- ishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al
-
[19]
Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246(2024)
Pith/arXiv arXiv 2024
-
[20]
Jacky Kwok, Christopher Agia, Rohan Sinha, Matt Foutter, Shulu Li, Ion Stoica, Azalia Mirhoseini, and Marco Pavone. 2025. Robomonkey: Scaling test-time sampling and verification for vision-language-action models.arXiv preprint arXiv:2506.17811(2025)
arXiv 2025
-
[21]
Tony Lee, Andrew Wagenmaker, Karl Pertsch, Percy Liang, Sergey Levine, and Chelsea Finn. 2026. RoboReward: General-Purpose Vision-Language Reward Models for Robotics.arXiv preprint arXiv:2601.00675(2026)
arXiv 2026
-
[22]
Chengmeng Li, Junjie Wen, Yaxin Peng, Yan Peng, and Yichen Zhu. 2026. Pointvla: Injecting the 3d world into vision-language-action models.IEEE Robotics and Automation Letters11, 3 (2026), 2506–2513
2026
-
[23]
Peiyan Li, Yixiang Chen, Hongtao Wu, Xiao Ma, Xiangnan Wu, Yan Huang, Liang Wang, Tao Kong, and Tieniu Tan. 2025. Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models.arXiv preprint arXiv:2506.07961(2025). VeriSpace: Spatially Grounded Action Verification for Vision-Language-Action Models Conference acronym ...
arXiv 2025
-
[24]
Xiaoqi Li, Liang Heng, Jiaming Liu, Yan Shen, Chenyang Gu, Zhuoyang Liu, Hao Chen, Nuowei Han, Renrui Zhang, Hao Tang, et al . 2025. 3ds-vla: A 3d spatial-aware vision language action model for robust multi-task manipulation. In9th Annual Conference on Robot Learning
2025
-
[25]
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. 2024. Evaluating Real- World Robot Manipulation Policies in Simulation.arXiv preprint arXiv:2405.05941 (2024)
Pith/arXiv arXiv 2024
-
[26]
Xinghang Li, Peiyan Li, Minghuan Liu, Dong Wang, Jirong Liu, Bingyi Kang, Xiao Ma, Tao Kong, Hanbo Zhang, and Huaping Liu. 2024. Towards generalist robot policies: What matters in building vision-language-action models.arXiv preprint arXiv:2412.14058(2024)
Pith/arXiv arXiv 2024
-
[27]
Tao Lin, Gen Li, Yilei Zhong, Yanwen Zou, Yuxin Du, Jiting Liu, Encheng Gu, and Bo Zhao. 2025. Evo-0: Vision-language-action model with implicit spatial understanding.arXiv preprint arXiv:2507.00416(2025)
arXiv 2025
-
[28]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. 2023. Libero: Benchmarking knowledge transfer for lifelong robot learning. Advances in Neural Information Processing Systems36 (2023), 44776–44791
2023
-
[29]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
-
[30]
Jiaming Liu, Hao Chen, Pengju An, Zhuoyang Liu, Renrui Zhang, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, et al . 2025. Hybridvla: Collaborative diffusion and autoregression in a unified vision-language-action model.arXiv preprint arXiv:2503.10631(2025)
Pith/arXiv arXiv 2025
-
[31]
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. 2024. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864(2024)
Pith/arXiv arXiv 2024
-
[32]
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. 2024. Grounding dino: Marry- ing dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision. Springer, 38–55
2024
-
[33]
Mitsuhiko Nakamoto, Oier Mees, Aviral Kumar, and Sergey Levine. 2024. Steering your generalists: Improving robotic foundation models via value guidance.arXiv preprint arXiv:2410.13816(2024)
arXiv 2024
-
[34]
OpenAI. 2023. GPT-4V(ision) System Card. https://openai.com/research/gpt-4v- system-card
2023
-
[35]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[36]
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. 2017. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems30 (2017)
2017
-
[37]
Zekun Qi, Runpei Dong, Shaochen Zhang, Haoran Geng, Chunrui Han, Zheng Ge, Li Yi, and Kaisheng Ma. 2024. ShapeLLM: Universal 3D Object Understanding for Embodied Interaction. InComputer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XLIII (Lecture Notes in Computer Science, Vol. 15101). Springe...
2024
-
[38]
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. 2025. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830 (2025)
Pith/arXiv arXiv 2025
-
[39]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
-
[40]
Lin Sun, Bin Xie, Yingfei Liu, Hao Shi, Tiancai Wang, and Jiale Cao. 2025. Geovla: Empowering 3d representations in vision-language-action models.arXiv preprint arXiv:2508.09071(2025)
arXiv 2025
-
[41]
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. 2024. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213(2024)
Pith/arXiv arXiv 2024
-
[42]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models. arXiv 2023.arXiv preprint arXiv:2302.1397110 (2023)
Pith/arXiv arXiv 2023
-
[43]
Homer Rich Walke, Kevin Black, Tony Z Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen-Estruch, Andre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. 2023. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning. PMLR, 1723–1736
2023
-
[44]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171(2022)
Pith/arXiv arXiv 2022
-
[45]
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Zhibin Tang, Kun Wu, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, et al. 2025. Tinyvla: Towards fast, data- efficient vision-language-action models for robotic manipulation.IEEE Robotics and Automation Letters(2025)
2025
-
[46]
Kun Wu, Chengkai Hou, Jiaming Liu, Zhengping Che, Xiaozhu Ju, Zhuqin Yang, Meng Li, Yinuo Zhao, Zhiyuan Xu, Guang Yang, et al. 2024. Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation.arXiv preprint arXiv:2412.13877(2024)
Pith/arXiv arXiv 2024
-
[47]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. 2024. Depth anything v2.Advances in Neural Information Processing Systems37 (2024), 21875–21911
2024
-
[48]
Jiahui Zhang, Yurui Chen, Yueming Xu, Ze Huang, Yanpeng Zhou, Yu-Jie Yuan, Xinyue Cai, Guowei Huang, Xingyue Quan, Hang Xu, et al. 2025. 4d-vla: Spa- tiotemporal vision-language-action pretraining with cross-scene calibration. arXiv preprint arXiv:2506.22242(2025)
arXiv 2025
-
[49]
Zhengshen Zhang, Hao Li, Yalun Dai, Zhengbang Zhu, Lei Zhou, Chenchen Liu, Dong Wang, Francis EH Tay, Sijin Chen, Ziwei Liu, et al. 2025. From spatial to actions: Grounding vision-language-action model in spatial foundation priors. arXiv preprint arXiv:2510.17439(2025)
arXiv 2025
-
[50]
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yin- ing Hong, and Chuang Gan. 2024. 3d-vla: A 3d vision-language-action generative world model.arXiv preprint arXiv:2403.09631(2024)
Pith/arXiv arXiv 2024
-
[51]
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. 2023. Rt-2: Vision-language- action models transfer web knowledge to robotic control. InConference on Robot Learning. PMLR, 2165–2183. Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Guiyu Zhao1,2, Longteng Guo1, Junyo...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.