Kwai Keye-VL-2.0 Technical Report
Pith reviewed 2026-06-27 13:51 UTC · model grok-4.3
The pith
A 30B MoE multimodal model processes 256K video contexts by activating only 3B parameters and leads on long-video benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
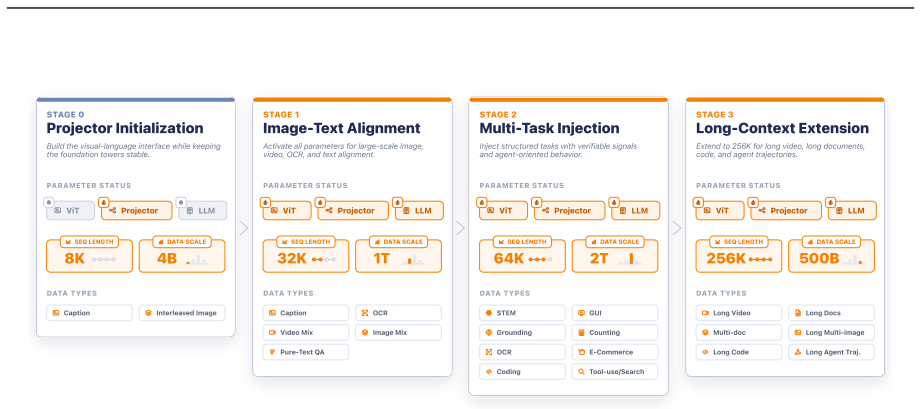
Keye-VL-2.0-30B-A3B is the first model to adapt DeepSeek Sparse Attention to GQA-based multimodal setups, supporting lossless 256K context while selecting critical frames. Cross-Modal Multi-Teacher On-Policy Distillation combined with Context-RL and Video-RL prevents catastrophic forgetting during multi-task alignment, allowing the MoE backbone to deliver strong agentic performance in code, tool, and search scenarios with multimodal self-correction. The model reaches state-of-the-art results among similar-scale systems on TimeLens for fine-grained temporal localization and on Video-MME-v2 and LongVideoBench for long-video comprehension.
What carries the argument
Adaptation of sparse attention to GQA-based multimodal architectures together with Cross-Modal Multi-Teacher On-Policy Distillation that feeds token-level teacher signals from on-policy rollouts back into the 3B-active-parameter MoE backbone.
If this is right
- Hour-level videos can be processed while retaining long-range temporal dependencies at manageable compute cost.
- Multi-task alignment for agent collaboration becomes feasible without the model forgetting prior capabilities.
- Only 3B parameters need activation during inference while still supporting advanced multimodal self-correction.
- Custom kernels and heterogeneous parallelism can scale training and inference throughput for video inputs.
- Open release of checkpoints enables community extension to new agentic applications.
Where Pith is reading between the lines
- The same sparse-attention plus distillation pattern could be tested on non-video modalities to check if the efficiency gains transfer.
- If the infrastructure optimizations generalize, similar active-parameter ratios might appear in other large multimodal systems.
- Longer contexts beyond 256K could be explored by extending the same attention adaptation.
- The agentic results suggest the model could be evaluated on interactive tasks that require sustained self-correction over many turns.
Load-bearing premise
The reported benchmark scores reflect performance that would hold under standard prompting and without test-set-specific tuning or data selection.
What would settle it
Reproduction on a fresh long-video benchmark with no training overlap showing the model no longer leads similar-scale open models on temporal localization or video comprehension metrics.
Figures










read the original abstract
We introduce Kwai Keye-VL-2.0-30B-A3B, an open-source Mixture-of-Experts (MoE) multimodal foundation model designed to advance long-video understanding and agentic intelligence. To address the challenges of ultra-long contexts, information redundancy, and prohibitive computational costs inherent in hour-level videos, Keye-VL-2.0 is the first to adapt DeepSeek Sparse Attention (DSA) to GQA-based multimodal architectures, enabling lossless 256K context processing while capturing critical frames and long-range temporal dependencies. This architecture is underpinned by a highly optimized training and inference infrastructure, including scalable video I/O, heterogeneous ViT-LM parallelism, and custom DSA kernels that significantly maximize throughput and minimize computational overhead. Furthermore, to overcome the algorithmic dilemma of catastrophic forgetting during multi-task alignment, we introduce Cross-Modal Multi-Teacher On-Policy Distillation (MOPD) paired with Context-RL and Video-RL. By distilling dense token-level teacher feedback from on-policy rollouts back into the MoE backbone, which activates only 3B parameters, Keye-VL-2.0 natively empowers advanced agent collaboration across Code, Tool, and Search scenarios with multimodal self-correction. Extensive evaluations across video understanding, temporal grounding, reasoning, STEM, and agent benchmarks demonstrate that Keye-VL-2.0-30B-A3B achieves state-of-the-art performance among models of similar scale, particularly excelling in fine-grained temporal localization on TimeLens and long-video comprehension on Video-MME-v2 and LongVideoBench. We release our model checkpoints to accelerate community progress toward scalable and robust multimodal agentic applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Kwai Keye-VL-2.0-30B-A3B, an open-source Mixture-of-Experts (MoE) multimodal foundation model for long-video understanding and agentic intelligence. It adapts DeepSeek Sparse Attention (DSA) to GQA-based architectures to enable lossless 256K context processing for hour-level videos, describes optimized training/inference infrastructure (scalable video I/O, heterogeneous ViT-LM parallelism, custom DSA kernels), and proposes Cross-Modal Multi-Teacher On-Policy Distillation (MOPD) paired with Context-RL and Video-RL to address catastrophic forgetting during multi-task alignment. The model is claimed to achieve state-of-the-art performance among similar-scale models on video understanding, temporal grounding, reasoning, STEM, and agent benchmarks, with particular strength on TimeLens (fine-grained temporal localization), Video-MME-v2, and LongVideoBench (long-video comprehension). Model checkpoints are released.
Significance. If the performance claims hold under standard evaluation protocols, the work would advance efficient long-context multimodal modeling by showing how sparse attention and on-policy distillation can be combined in an MoE backbone (activating only 3B parameters) for video and agentic tasks. The open release of checkpoints is a concrete community benefit. However, the current manuscript provides no visible experimental details, so the significance cannot yet be assessed.
major comments (2)
- [Abstract] Abstract: the central claim that Keye-VL-2.0-30B-A3B 'achieves state-of-the-art performance among models of similar scale' is presented with no accompanying evaluation details, baselines, metrics, error bars, prompting protocols, or result tables. This is load-bearing for the paper's primary assertion.
- [Evaluation (missing)] No evaluation section is visible in the supplied manuscript text. Without benchmark protocols, data splits, comparison tables, or ablation studies, the SOTA statements on TimeLens, Video-MME-v2, and LongVideoBench cannot be verified and the risk of undisclosed test-set tuning or non-standard prompting cannot be ruled out.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We agree that the absence of an evaluation section prevents verification of the SOTA claims and will add a comprehensive Evaluation section with all protocols, tables, baselines, and metrics in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Keye-VL-2.0-30B-A3B 'achieves state-of-the-art performance among models of similar scale' is presented with no accompanying evaluation details, baselines, metrics, error bars, prompting protocols, or result tables. This is load-bearing for the paper's primary assertion.
Authors: We accept this criticism. The abstract condenses results that are described at a high level in the manuscript, but without the supporting evaluation details the claim cannot stand alone. In revision we will either qualify the abstract language or add explicit forward references to the new Evaluation section while retaining the overall claim. revision: yes
-
Referee: [Evaluation (missing)] No evaluation section is visible in the supplied manuscript text. Without benchmark protocols, data splits, comparison tables, or ablation studies, the SOTA statements on TimeLens, Video-MME-v2, and LongVideoBench cannot be verified and the risk of undisclosed test-set tuning or non-standard prompting cannot be ruled out.
Authors: The referee correctly observes that no Evaluation section appears in the text provided for review. This is an omission in the current draft. We will insert a full Evaluation section that reports benchmark protocols, data splits, comparison tables against similar-scale models, prompting templates, error bars where applicable, and ablation studies on DSA, MOPD, and RL components. This will directly address verification concerns. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The provided abstract and description contain no mathematical derivations, equations, or 'predictions' that reduce to inputs by construction. Claims rest on empirical benchmark results and architectural descriptions (DSA adaptation, MOPD) without self-referential fitting, self-citation load-bearing for uniqueness theorems, or renaming of known results. No load-bearing steps match the enumerated circularity patterns, so the report is treated as self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2026 , month =
OpenAI , title =. 2026 , month =
2026
-
[2]
2026 , month =
Anthropic , title =. 2026 , month =
2026
-
[3]
Gemini 3.5 Flash , year =
-
[4]
Qwen3.7: The Agent Frontier , year =
-
[5]
arXiv preprint arXiv:2507.01949 , year=
Kwai Keye-VL Technical Report , author=. arXiv preprint arXiv:2507.01949 , year=
-
[6]
arXiv preprint arXiv:2509.01563 , year=
Kwai Keye-VL 1.5 Technical Report , author=. arXiv preprint arXiv:2509.01563 , year=
-
[7]
2025 , url =
Zhang, Jun and Wang, Teng and Ge, Yuying and Ge, Yixiao and Li, Xinhao and Shan, Ying and Wang, Limin , journal =. 2025 , url =
2025
-
[8]
arXiv preprint arXiv:2604.05015 , year =
Fu, Chaoyou and others , title =. arXiv preprint arXiv:2604.05015 , year =
-
[9]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Wu, Haoning and Li, Dongxu and Chen, Bei and Li, Junnan , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[10]
2025 , url =
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models , journal =. 2025 , url =
2025
-
[11]
2026 , eprint=
GLM-5: from Vibe Coding to Agentic Engineering , author=. 2026 , eprint=
2026
-
[12]
arXiv preprint arXiv:2605.10943 , year =
-
[13]
International Conference on Learning Representations (ICLR) , year =
Shazeer, Noam and Mirhoseini, Azalia and Maziarz, Krzysztof and Davis, Andy and Le, Quoc and Hinton, Geoffrey and Dean, Jeff , title =. International Conference on Learning Representations (ICLR) , year =
-
[14]
5: Visual Agentic Intelligence , author=
Kimi K2. 5: Visual Agentic Intelligence , author=. arXiv preprint arXiv:2602.02276 , year=
-
[15]
arXiv preprint arXiv:2602.22623 , year=
ContextRL: Enhancing MLLM's Knowledge Discovery Efficiency with Context-Augmented RL , author=. arXiv preprint arXiv:2602.22623 , year=
-
[16]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[17]
5-vl technical report , author=
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
-
[18]
arXiv preprint arXiv:2410.18558 , year=
Infinity-mm: Scaling multimodal performance with large-scale and high-quality instruction data , author=. arXiv preprint arXiv:2410.18558 , year=
-
[19]
arXiv preprint arXiv:2409.05840 , year=
Mmevol: Empowering multimodal large language models with evol-instruct , author=. arXiv preprint arXiv:2409.05840 , year=
-
[20]
Science China Information Sciences , volume=
Mminstruct: A high-quality multi-modal instruction tuning dataset with extensive diversity , author=. Science China Information Sciences , volume=. 2024 , publisher=
2024
-
[21]
2023 , eprint=
Sigmoid Loss for Language Image Pre-Training , author=. 2023 , eprint=
2023
-
[22]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[23]
Neurocomputing , volume=
Roformer: Enhanced transformer with rotary position embedding , author=. Neurocomputing , volume=. 2024 , publisher=
2024
-
[24]
Advances in neural information processing systems , volume=
Laion-5b: An open large-scale dataset for training next generation image-text models , author=. Advances in neural information processing systems , volume=
-
[25]
Advances in Neural Information Processing Systems , volume=
Datacomp: In search of the next generation of multimodal datasets , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
2022 , howpublished =
COYO-700M: Image-Text Pair Dataset , author =. 2022 , howpublished =
2022
-
[27]
2025 , eprint=
Tarsier2: Advancing Large Vision-Language Models from Detailed Video Description to Comprehensive Video Understanding , author=. 2025 , eprint=
2025
-
[28]
R efer I t G ame: Referring to Objects in Photographs of Natural Scenes
Kazemzadeh, Sahar and Ordonez, Vicente and Matten, Mark and Berg, Tamara. R efer I t G ame: Referring to Objects in Photographs of Natural Scenes. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing ( EMNLP ). 2014. doi:10.3115/v1/D14-1086
-
[29]
International Journal of Computer Vision , year=
Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations , author=. International Journal of Computer Vision , year=
-
[30]
arXiv preprint arXiv:2309.16511 , year=
Toloka visual question answering benchmark , author=. arXiv preprint arXiv:2309.16511 , year=
-
[31]
arXiv preprint arXiv:2010.11929 , year=
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
Pith/arXiv arXiv 2010
-
[32]
arXiv preprint arXiv:2411.10442 , year=
Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization , author=. arXiv preprint arXiv:2411.10442 , year=
-
[33]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[34]
arXiv preprint arXiv:2502.09925 , year=
Taskgalaxy: Scaling multi-modal instruction fine-tuning with tens of thousands vision task types , author=. arXiv preprint arXiv:2502.09925 , year=
-
[35]
arXiv preprint arXiv:2502.10391 , year=
MM-RLHF: The Next Step Forward in Multimodal LLM Alignment , author=. arXiv preprint arXiv:2502.10391 , year=
-
[36]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[37]
DeepEyes: Incentivizing" Thinking with Images" via Reinforcement Learning , author=. arXiv preprint arXiv:2505.14362 , year=
-
[38]
arXiv preprint arXiv:2503.07365 , year=
Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforcement learning , author=. arXiv preprint arXiv:2503.07365 , year=
-
[39]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[40]
arXiv preprint arXiv:2504.10479 , year=
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models , author=. arXiv preprint arXiv:2504.10479 , year=
-
[41]
2025 , eprint=
MiMo-VL Technical Report , author=. 2025 , eprint=
2025
-
[42]
Advances in Neural Information Processing Systems , volume=
Patch n’pack: Navit, a vision transformer for any aspect ratio and resolution , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[44]
Computer Vision--ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11--14, 2016, Proceedings, Part IV 14 , pages=
A diagram is worth a dozen images , author=. Computer Vision--ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11--14, 2016, Proceedings, Part IV 14 , pages=. 2016 , organization=
2016
-
[45]
arXiv preprint arXiv:2502.09696 , year=
Zerobench: An impossible visual benchmark for contemporary large multimodal models , author=. arXiv preprint arXiv:2502.09696 , year=
-
[46]
arXiv preprint arXiv:2501.13826 , year=
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos , author=. arXiv preprint arXiv:2501.13826 , year=
-
[47]
arXiv preprint arXiv:2409.17146 , year=
Molmo and pixmo: Open weights and open data for state-of-the-art multimodal models , author=. arXiv preprint arXiv:2409.17146 , year=
-
[48]
5-omni technical report , author=
Qwen2. 5-omni technical report , author=. arXiv preprint arXiv:2503.20215 , year=
-
[49]
arXiv preprint arXiv:2503.24290 , year=
Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model , author=. arXiv preprint arXiv:2503.24290 , year=
-
[50]
ACM Transactions on Multimedia Computing, Communications and Applications , year=
MMICT: Boosting Multi-Modal Fine-Tuning with In-Context Examples , author=. ACM Transactions on Multimedia Computing, Communications and Applications , year=
-
[51]
arXiv preprint arXiv:2412.05271 , year=
Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling , author=. arXiv preprint arXiv:2412.05271 , year=
-
[52]
arXiv preprint arXiv:2312.11805 , year=
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
-
[53]
arXiv preprint arXiv:2407.07895 , year=
Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models , author=. arXiv preprint arXiv:2407.07895 , year=
-
[54]
arXiv preprint arXiv:2503.20020 , year=
Gemini robotics: Bringing ai into the physical world , author=. arXiv preprint arXiv:2503.20020 , year=
-
[55]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[56]
arXiv preprint arXiv:2504.07491 , year=
Kimi-vl technical report , author=. arXiv preprint arXiv:2504.07491 , year=
-
[57]
arXiv preprint arXiv:2412.01282 , year=
Align-KD: Distilling Cross-Modal Alignment Knowledge for Mobile Vision-Language Model , author=. arXiv preprint arXiv:2412.01282 , year=
-
[58]
arXiv preprint arXiv:2501.01957 , year=
Vita-1.5: Towards gpt-4o level real-time vision and speech interaction , author=. arXiv preprint arXiv:2501.01957 , year=
-
[59]
arXiv preprint arXiv:2410.10441 , year=
Free Video-LLM: Prompt-guided Visual Perception for Efficient Training-free Video LLMs , author=. arXiv preprint arXiv:2410.10441 , year=
-
[60]
arXiv preprint arXiv:2309.07124 , year=
Rain: Your language models can align themselves without finetuning , author=. arXiv preprint arXiv:2309.07124 , year=
-
[61]
arXiv preprint arXiv:2311.10122 , year=
Video-llava: Learning united visual representation by alignment before projection , author=. arXiv preprint arXiv:2311.10122 , year=
-
[62]
Advances in Neural Information Processing Systems , volume=
Cheap and quick: Efficient vision-language instruction tuning for large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[63]
arXiv preprint arXiv:2403.03003 , year=
Feast your eyes: Mixture-of-resolution adaptation for multimodal large language models , author=. arXiv preprint arXiv:2403.03003 , year=
-
[64]
arXiv preprint arXiv:2411.13093 , year=
Video-RAG: Visually-aligned Retrieval-Augmented Long Video Comprehension , author=. arXiv preprint arXiv:2411.13093 , year=
-
[65]
arXiv preprint arXiv:2503.20502 , year=
Mllm-selector: Necessity and diversity-driven high-value data selection for enhanced visual instruction tuning , author=. arXiv preprint arXiv:2503.20502 , year=
-
[66]
arXiv preprint arXiv:2501.04322 , year=
Eve: Efficient Multimodal Vision Language Models with Elastic Visual Experts , author=. arXiv preprint arXiv:2501.04322 , year=
-
[67]
arXiv preprint arXiv:2502.05177 , year=
Long-VITA: Scaling Large Multi-modal Models to 1 Million Tokens with Leading Short-Context Accuray , author=. arXiv preprint arXiv:2502.05177 , year=
-
[68]
5-vl technical report , author=
Seed1. 5-vl technical report , author=. arXiv preprint arXiv:2505.07062 , year=
-
[69]
arXiv preprint arXiv:2505.08617 , year=
Openthinkimg: Learning to think with images via visual tool reinforcement learning , author=. arXiv preprint arXiv:2505.08617 , year=
-
[70]
arXiv preprint arXiv:2411.09968 , year=
Seeing clearly by layer two: Enhancing attention heads to alleviate hallucination in lvlms , author=. arXiv preprint arXiv:2411.09968 , year=
-
[71]
Advances in Neural Information Processing Systems , volume=
Controlmllm: Training-free visual prompt learning for multimodal large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[73]
arXiv preprint arXiv:2409.18869 , year=
Emu3: Next-token prediction is all you need , author=. arXiv preprint arXiv:2409.18869 , year=
-
[74]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[75]
arXiv preprint arXiv:2404.14219 , year=
Phi-3 technical report: A highly capable language model locally on your phone , author=. arXiv preprint arXiv:2404.14219 , year=
-
[76]
Lambert, Nathan and Morrison, Jacob and Pyatkin, Valentina and Huang, Shengyi and Ivison, Hamish and Brahman, Faeze and Miranda, Lester James V and Liu, Alisa and Dziri, Nouha and Lyu, Shane and others , journal=
-
[77]
arXiv preprint arXiv:2507.02029 , year=
RoboBrain 2.0 Technical Report , author=. arXiv preprint arXiv:2507.02029 , year=
-
[78]
2025 , howpublished =
Introducing OpenAI o3 and o4-mini , author=. 2025 , howpublished =
2025
-
[79]
2025 , howpublished =
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation , author=. 2025 , howpublished =
2025
-
[80]
2025 , howpublished=
ERNIE 4.5 Technical Report , author=. 2025 , howpublished=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.