Continual LLM Upcycling: A Predictor-Gated Bank-Wise Sparsity Training Recipe for Dense-to-Sparse LLMs
Pith reviewed 2026-06-27 13:02 UTC · model grok-4.3
The pith
Continual training with a predictor-gated bank-wise sparse FFN upcycles a dense Qwen2.5-8B into a 4x channel-sparse LLM at 32K context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
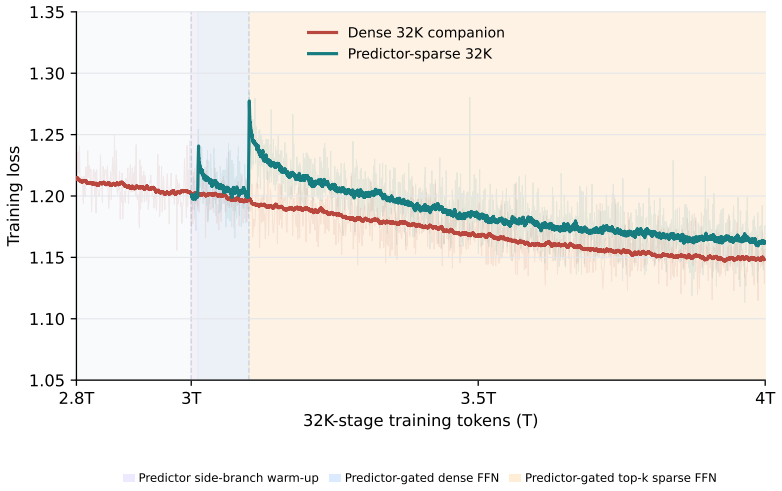
Placing a low-rank predictor on the main training path to generate per-token, per-layer FFN routing logits, then enforcing bank-wise top-k selection of 16 channels out of 64 during the 32K continual training stage, converts the dense backbone into a hardware-oriented sparse model while maintaining downstream performance.
What carries the argument
The predictor-gated bank-wise sparse SwiGLU FFN, in which a low-rank module produces routing logits and a fixed bank-wise top-k rule keeps exactly 16 channels active per 64-channel bank for each token and layer.
If this is right
- The resulting model delivers 4x reduction in FFN intermediate activations while remaining trainable from a dense checkpoint.
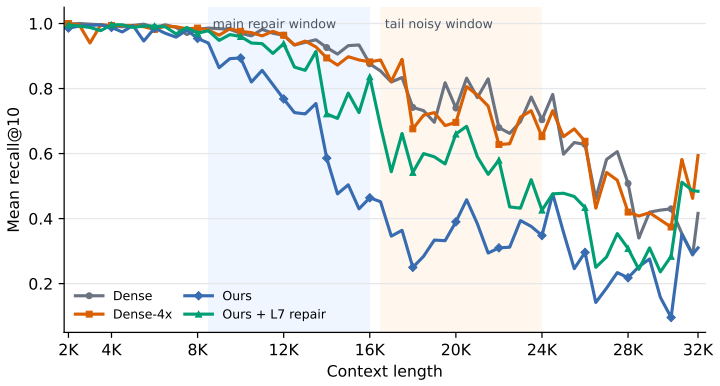
- A single-layer repair algorithm corrects the observed layer-local failure on RULER-CWE long-context tasks.
- The training recipe includes explicit lessons on predictor placement and sparsity scheduling that apply to similar upcycling runs.
- The sparse architecture is directly compatible with hardware accelerators that exploit channel-level sparsity.
Where Pith is reading between the lines
- The same predictor-plus-bank-wise rule might be applied to other linear layers beyond the FFN without changing the overall training loop.
- Inference latency on sparsity-aware accelerators could be measured directly to quantify the hardware benefit beyond the reported training metrics.
- Extending the bank size or predictor rank would test whether the current 64-to-16 ratio is optimal or merely convenient.
Load-bearing premise
Jointly optimizing the routing predictor with the base model during continual training will discover channel selections that keep downstream performance close to the dense baseline at 4x sparsity.
What would settle it
If the final sparse model scores substantially lower than a dense model continued under identical 32K training conditions on the same benchmarks, the joint-optimization premise does not hold.
Figures




read the original abstract
We study dense-to-sparse continual training as a way to construct channel-sparse large language models from dense checkpoints. Starting from a Qwen2.5-8B dense backbone, we continue training at 32K context and introduce a predictor-gated sparse SwiGLU FFN in the 32K stage. For each token and layer, we use a low-rank predictor to produce FFN-channel routing logits. We then apply a bank-wise top-k rule to retain 16 channels in every 64-channel bank, yielding 4x sparsity in the FFN intermediate activation. Unlike post-hoc sparse inference methods, the routing module is placed on the main language modeling path and optimized during continual training, enabling the dense model to be upcycled into a hardware-oriented sparse model. We report the architecture, training recipe, benchmark performance, and training lessons. We also identify a layer-local long-context failure mode on RULER-CWE and propose a single-layer repair algorithm that substantially improves the affected length range.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that dense-to-sparse continual training can upcycle a Qwen2.5-8B checkpoint into a hardware-oriented 4x channel-sparse LLM. Starting from the dense backbone, the authors continue training at 32K context while replacing the SwiGLU FFN with a predictor-gated version: a low-rank predictor produces per-token, per-layer routing logits, a bank-wise top-k rule keeps 16 of 64 channels per bank, and the predictor is placed on the main LM path and jointly optimized. They also report a layer-local long-context failure mode on RULER-CWE together with a single-layer repair algorithm.
Significance. If the joint optimization of the low-rank predictor with the bank-wise top-k selection succeeds in preserving downstream performance, the recipe would supply a concrete, training-based route from dense checkpoints to sparse models that is more hardware-friendly than post-hoc pruning. The explicit identification and repair of the RULER-CWE length-range failure is a secondary but useful empirical contribution.
major comments (1)
- [Abstract / §3] Abstract / §3 (Training Recipe): the central claim requires that joint optimization of the low-rank predictor with the discrete bank-wise top-k (16/64) produces effective routing. No relaxation, straight-through estimator, or auxiliary loss is described for propagating gradients through the hard selection; without such a mechanism the gradients to the predictor are undefined or noisy, undermining the assertion that the learned routing itself is responsible for retained performance.
minor comments (2)
- The abstract states that benchmark performance and training lessons are reported, yet no tables, numbers, or ablation controls appear in the provided text; these must be added with error bars and dense/sparse comparisons.
- Notation for the bank-wise top-k operation and the low-rank predictor dimensions should be formalized with equations rather than prose only.
Simulated Author's Rebuttal
We thank the referee for highlighting the critical issue of gradient flow through the discrete bank-wise top-k selection. This is a valid point regarding the training recipe description. We address it directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract / §3 (Training Recipe): the central claim requires that joint optimization of the low-rank predictor with the discrete bank-wise top-k (16/64) produces effective routing. No relaxation, straight-through estimator, or auxiliary loss is described for propagating gradients through the hard selection; without such a mechanism the gradients to the predictor are undefined or noisy, undermining the assertion that the learned routing itself is responsible for retained performance.
Authors: We agree that the current manuscript text in §3 does not explicitly describe the mechanism for back-propagating through the hard bank-wise top-k (16/64) selection. In the implementation, gradients were propagated using the straight-through estimator (STE), with the forward pass applying the discrete top-k and the backward pass treating the selection as the identity function. No auxiliary loss was used. This detail was omitted from the description of the training recipe. We will revise §3 (and the abstract if space permits) to state that the low-rank predictor is jointly optimized via STE through the discrete selection, thereby clarifying how the routing logits receive gradients and supporting the claim that the learned routing contributes to performance retention. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description outline an empirical continual-training recipe that introduces a low-rank predictor for routing logits followed by bank-wise top-k selection during the 32K stage. No equations, fitted parameters, or derivations are shown that reduce by construction to their own inputs (e.g., no self-definitional scaling, no prediction of a quantity used in its own fit). No self-citations, uniqueness theorems, or ansatzes are invoked in the given text. The central claim concerns the outcome of joint optimization on downstream performance, which is an empirical assertion rather than a closed mathematical reduction. This matches the default expectation for non-circular papers; the method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V . N. Vishwanathan, and Roman Garnett, editors,Advances in Neural Information Processing Systems 30: Annual Conference...
2017
-
[2]
GLU variants improve transformer.ArXiv preprint, abs/2002.05202, 2020
Noam Shazeer. GLU variants improve transformer.ArXiv preprint, abs/2002.05202, 2020. URLhttps://arxiv.org/abs/2002.05202
Pith/arXiv arXiv 2002
-
[3]
Deja vu: Contextual sparsity for efficient llms at inference time
Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shri- vastava, Ce Zhang, Yuandong Tian, Christopher Ré, and Beidi Chen. Deja vu: Contextual sparsity for efficient llms at inference time. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,International Confer- e...
2023
-
[4]
Gshard: Scaling giant models with con- ditional computation and automatic sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with con- ditional computation and automatic sharding. In9th International Conference on Learning 9 Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. URLhtt...
2021
-
[5]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (120):1–39, 2022
2022
-
[6]
AbouElhamayed, Jordan Dotzel, Zhiru Zhang, Alexander M
Yash Akhauri, Ahmed F. AbouElhamayed, Jordan Dotzel, Zhiru Zhang, Alexander M. Rush, Safeen Huda, and Mohamed S. Abdelfattah. Shadowllm: Predictor-based contextual sparsity for large language models.ArXiv preprint, abs/2406.16635, 2024. URL https://arxiv.org/ abs/2406.16635
arXiv 2024
-
[7]
Sirius: Contextual sparsity with correction for efficient llms.ArXiv preprint, abs/2409.03856, 2024
Yang Zhou, Zhuoming Chen, Zhaozhuo Xu, Victoria Lin, and Beidi Chen. Sirius: Contextual sparsity with correction for efficient llms.ArXiv preprint, abs/2409.03856, 2024. URL https: //arxiv.org/abs/2409.03856
arXiv 2024
-
[8]
Tong Wu, Yutong He, Bin Wang, and Kun Yuan. Mixture-of-channels: Exploiting sparse ffns for efficient llms pre-training and inference.ArXiv preprint, abs/2511.09323, 2025. URL https://arxiv.org/abs/2511.09323
arXiv 2025
-
[9]
Qwen2.5 technical report.ArXiv preprint, abs/2412.15115, 2024
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report.ArXiv preprint, abs/2412.15115, 2024. URLhttps://arxiv.org/abs/2412.15115
Pith/arXiv arXiv 2024
-
[10]
Sparse upcycling: Training mixture-of-experts from dense checkpoints
Aran Komatsuzaki, Joan Puigcerver, James Lee-Thorp, Carlos Riquelme Ruiz, Basil Mustafa, Joshua Ainslie, Yi Tay, Mostafa Dehghani, and Neil Houlsby. Sparse upcycling: Training mixture-of-experts from dense checkpoints. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URLht...
2023
-
[11]
Ruler: What’s the real context size of your long-context language models? In First Conference on Language Modeling, 2024
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models? In First Conference on Language Modeling, 2024
2024
-
[12]
Chong You, Kan Wu, Zhipeng Jia, Lin Chen, Srinadh Bhojanapalli, Jiaxian Guo, Utku Evci, Jan Wassenberg, Praneeth Netrapalli, Jeremiah J. Willcock, Suvinay Subramanian, Felix Chern, Alek Andreev, Shreya Pathak, Felix Yu, Prateek Jain, David E. Culler, Henry M. Levy, and Sanjiv Kumar. Spark transformer: Reactivating sparsity in ffn and attention.ArXiv prepr...
arXiv 2025
-
[13]
MoEfication: Transformer feed-forward layers are mixtures of experts
Zhengyan Zhang, Yankai Lin, Zhiyuan Liu, Peng Li, Maosong Sun, and Jie Zhou. MoEfication: Transformer feed-forward layers are mixtures of experts. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors,Findings of the Association for Computational Linguistics: ACL 2022, pages 877–890, Dublin, Ireland, 2022. Association for Computational Ling...
2022
-
[14]
Measuring short-form factuality in large language models
Jason Wei, Nguyen Karina, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, and William Fedus. Measuring short-form factuality in large language models. ArXiv preprint, abs/2411.04368, 2024. URLhttps://arxiv.org/abs/2411.04368
Pith/arXiv arXiv 2024
-
[15]
Yancheng He, Shilong Li, Jiaheng Liu, Yingshui Tan, Weixun Wang, Hui Huang, Xingyuan Bu, Hangyu Guo, Chengwei Hu, Boren Zheng, Zhuoran Lin, Xuepeng Liu, Dekai Sun, Shirong Lin, Zhicheng Zheng, Xiaoyong Zhu, Wenbo Su, and Bo Zheng. Chinese SimpleQA: A chinese factuality evaluation for large language models.ArXiv preprint, abs/2411.07140, 2024. URL https://...
arXiv 2024
-
[16]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc V . Le, and Charles Sutton. Program synthesis with large language models.ArXiv preprint, abs/2108.07732, 2021. URL https: //arxiv.org/abs/2108.07732. 10
Pith/arXiv arXiv 2021
-
[17]
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Ne...
2023
-
[18]
Feldman, Arjun Guha, Michael Greenberg, and Abhinav Jangda
Federico Cassano, John Gouwar, Daniel Nguyen, Sydney Nguyen, Luna Phipps-Costin, Donald Pinckney, Ming-Ho Yee, Yangtian Zi, Carolyn Jane Anderson, Molly Q. Feldman, Arjun Guha, Michael Greenberg, and Abhinav Jangda. MultiPL-E: A scalable and extensible approach to benchmarking neural code generation.IEEE Transactions on Software Engineering, 2023
2023
-
[19]
Multi-lingual evaluation of code generation models
Ben Athiwaratkun, Sanjay Krishna Gouda, Zijian Wang, Xiaopeng Li, Yuchen Tian, Ming Tan, Wasi Uddin Ahmad, Shiqi Wang, Qing Sun, Mingyue Shang, Sujan Kumar Gonugondla, Hantian Ding, Varun Kumar, Nathan Fulton, Arash Farahani, Siddhartha Jain, Robert Gi- aquinto, Haifeng Qian, Murali Krishna Ramanathan, and Ramesh Nallapati. Multi-lingual evaluation of cod...
2023
-
[20]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. LiveCodeBench: Holistic and contami- nation free evaluation of large language models for code.ArXiv preprint, abs/2403.07974, 2024. URLhttps://arxiv.org/abs/2403.07974
Pith/arXiv arXiv 2024
-
[21]
Kaijing Ma, Xinrun Du, Yunran Wang, Haoran Zhang, Zhoufutu Wen, Xingwei Qu, Jian Yang, Jiaheng Liu, Minghao Liu, Xiang Yue, Wenhao Huang, and Ge Zhang. KOR-Bench: Benchmarking language models on knowledge-orthogonal reasoning tasks.ArXiv preprint, abs/2410.06526, 2024. URLhttps://arxiv.org/abs/2410.06526
arXiv 2024
-
[22]
ZebraLogic: On the scaling limits of LLMs for logical reasoning.ArXiv preprint, abs/2502.01100, 2025
Bill Yuchen Lin, Ronan Le Bras, Kyle Richardson, Ashish Sabharwal, Radha Poovendran, Peter Clark, and Yejin Choi. ZebraLogic: On the scaling limits of LLMs for logical reasoning.ArXiv preprint, abs/2502.01100, 2025. URLhttps://arxiv.org/abs/2502.01100
arXiv 2025
-
[23]
Ippei Fujisawa, Sensho Nobe, Hiroki Seto, Rina Onda, Yoshiaki Uchida, Hiroki Ikoma, Pei- Chun Chien, and Ryota Kanai. ProcBench: Benchmark for multi-step reasoning and following procedure.ArXiv preprint, abs/2410.03117, 2024. URL https://arxiv.org/abs/2410. 03117
arXiv 2024
-
[24]
On the measure of intelligence.ArXiv preprint, abs/1911.01547, 2019
François Chollet. On the measure of intelligence.ArXiv preprint, abs/1911.01547, 2019. URL https://arxiv.org/abs/1911.01547
Pith/arXiv arXiv 1911
-
[25]
DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs
Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In Jill Burstein, Christy Doran, and Thamar Solorio, editors,Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Hu...
2019
-
[26]
Challenging BIG - Bench Tasks and Whether Chain -of- Thought Can Solve Them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, and Jason Wei. Chal- lenging BIG-bench tasks and whether chain-of-thought can solve them. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Findings of the Association for Com- putational Linguistics:...
-
[27]
American invitational mathematics examination (AIME)
Mathematical Association of America. American invitational mathematics examination (AIME). https://maa.org/student-programs/amc/, 2025. 11
2025
-
[28]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InAdvances in Neural Information Processing Systems, volume 34, 2021
2021
-
[29]
LiveBench: A challenging, contamination- free LLM benchmark.ArXiv preprint, abs/2406.19314, 2024
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Ben Feuer, Siddhartha Jain, Ravid Shwartz-Ziv, Neel Jain, Khalid Saifullah, Siddartha Naidu, Chinmay Hegde, Yann LeCun, Tom Goldstein, Willie Neiswanger, and Micah Goldblum. LiveBench: A challenging, contamination- free LLM benchmark.ArXiv preprint, abs/2406.19314, 2024. URL https://arxiv.org/ abs/2406.19314
Pith/arXiv arXiv 2024
-
[30]
SuperGPQA: Scaling LLM evaluation across 285 graduate disciplines
M-A-P Team et al. SuperGPQA: Scaling LLM evaluation across 285 graduate disciplines. ArXiv preprint, abs/2502.14739, 2025. URLhttps://arxiv.org/abs/2502.14739
Pith/arXiv arXiv 2025
-
[31]
AGIEval: A human-centric benchmark for evaluating foundation models
Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. AGIEval: A human-centric benchmark for evaluating foundation models. In Kevin Duh, Helena Gomez, and Steven Bethard, editors,Findings of the Association for Computational Linguistics: NAACL 2024, pages 2299–2314, Mexico City, Mexico, 2024. Ass...
2024
-
[32]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela ...
2024
-
[33]
C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models
Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Jun- teng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, Yao Fu, Maosong Sun, and Junxian He. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models. In Al- ice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editor...
2023
-
[34]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. URLhttps://openreview.net/forum?id=d7KBjmI3GmQ
2021
-
[35]
LLMTest_NeedleInAHaystack: Doing simple retrieval from LLM models at various context lengths to measure accuracy
Greg Kamradt. LLMTest_NeedleInAHaystack: Doing simple retrieval from LLM models at various context lengths to measure accuracy. https://github.com/gkamradt/LLMTest_ NeedleInAHaystack, 2023. GitHub repository. 12 Appendix A Predictor Top-k Ablation This section records the diagnostic ablation that motivates the predictor-before-top-k sparse-routing order. ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.