Hand-centric Human-to-Robot Trajectory Transfer from Video Demonstrations via Open-World Contact Localization
Pith reviewed 2026-06-27 13:13 UTC · model grok-4.3
The pith
HOWTransfer distills video demonstrations into contact-aware robot trajectories by localizing hand-object contacts from visual cues alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HOWTransfer recovers temporally consistent 3D hand motion from video and localizes temporal contact intervals by reasoning over hand-object interaction cues, then retargets grasp intent into multi-modal parallel-jaw grasp hypotheses propagated along the wrist trajectory, followed by editing to refine contact alignment and produce diverse variants, achieving 86% success in manipulation tasks.
What carries the argument
Contact localization from hand-object interaction cues to retarget grasps and generate trajectories without object-specific descriptions.
If this is right
- Contact localization enables retargeting of human grasp intent into multi-modal robot grasp hypotheses.
- Propagating grasps along recovered wrist trajectories produces robot-executable motions.
- Trajectory editing refines contact alignment and creates diverse executable variants from one demonstration.
- High-quality retargeting succeeds on 86% of diverse manipulation tasks.
- Blinded studies show preference for these trajectories over teleoperated ones.
Where Pith is reading between the lines
- Methods relying on hand cues might extend to scenarios with heavy occlusion if hand pose estimation improves.
- Removing the need for object tracking could simplify systems for novel objects in open worlds.
- Combining this with other modalities like audio might further enhance contact detection.
- The preference in studies suggests better naturalness in the resulting motions.
Load-bearing premise
Observed hand-object interaction cues in video are sufficient to recover temporally consistent 3D hand motion and localize temporal contact intervals without object-specific descriptions, vision-language queries, or explicit object-state tracking.
What would settle it
Videos of hand-object interactions where contact onsets cannot be accurately determined from visual cues alone, resulting in mislocalized contacts and low success rates for the generated robot trajectories.
Figures


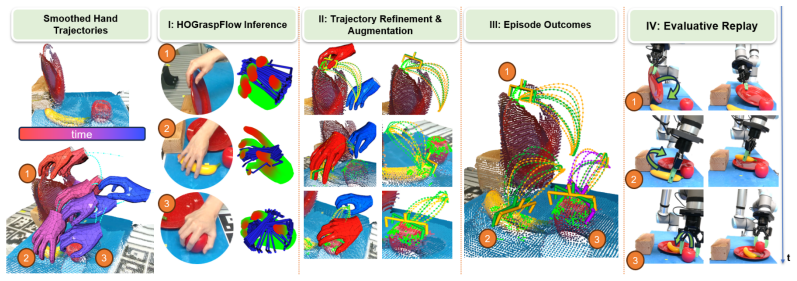


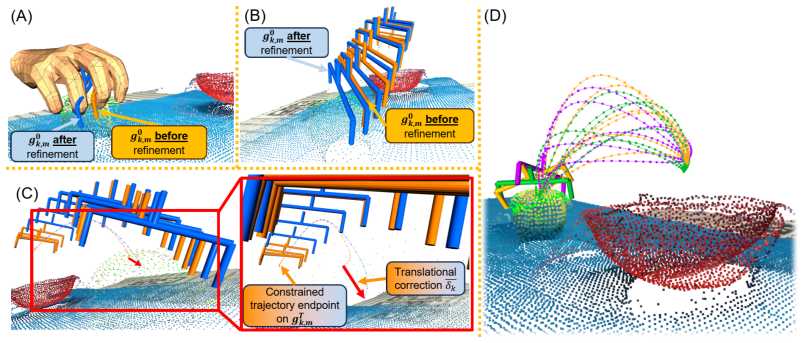






read the original abstract
Learning from human video demonstrations remains challenging due to noisy hand-object interactions, unseen objects with partial observation, and cross-embodiment discrepancy. To address these challenges, we present \textit{HOWTransfer} (\emph{H}and-\emph{O}bject \emph{O}pen-\emph{W}orld Transfer), a hand-centric framework that distills human demonstrations into contact-aware, taxonomy-informed, and diverse robotic trajectories. Instead of relying on object-specific descriptions, vision-language queries, or explicit object-state tracking, \emph{HOWTransfer} recovers temporally consistent 3D hand motion and localizes temporal contact intervals by reasoning over observed hand-object interaction cues. The localized contact onsets are then used to retarget human grasp intent into multi-modal parallel-jaw grasp hypotheses, which are propagated along the recovered wrist trajectory to generate robot-executable motions. Finally, a trajectory editing stage refines contact alignment and produces diverse executable variants from a single demonstration. Experiments across diverse manipulation tasks show that \emph{HOWTransfer} enables accurate contact localization and high-quality robot motion retargeting with $86\%$ success, which is preferred over teleoperated trajectories in a blinded preference study.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HOWTransfer, a hand-centric framework for distilling human video demonstrations into contact-aware robotic trajectories. It recovers temporally consistent 3D hand motion and localizes temporal contact intervals solely by reasoning over observed hand-object interaction cues (without object-specific descriptions, vision-language queries, or explicit object-state tracking), retargets grasp intent into multi-modal parallel-jaw hypotheses propagated along the wrist trajectory, and applies a trajectory editing stage to refine contact alignment and generate diverse executable variants. Experiments across diverse manipulation tasks report 86% success and blinded preference over teleoperated trajectories.
Significance. If validated, the hand-centric open-world approach could advance video-based robot learning by reducing reliance on object models or VLMs, supporting generalization to unseen objects with partial observations. The trajectory editing stage for diversity from single demonstrations and the blinded preference study are explicit strengths that strengthen the evaluation beyond raw success rates.
major comments (1)
- [Experiments section] Experiments section: the central claim of 86% success (and preference over teleoperation) is reported without task definitions, number of trials, failure mode analysis, or statistical tests. This directly undermines evaluation of the performance numbers that support the framework's effectiveness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation. We address the major comment below and commit to a revised manuscript that strengthens the experimental reporting.
read point-by-point responses
-
Referee: [Experiments section] Experiments section: the central claim of 86% success (and preference over teleoperation) is reported without task definitions, number of trials, failure mode analysis, or statistical tests. This directly undermines evaluation of the performance numbers that support the framework's effectiveness.
Authors: We agree that the current Experiments section lacks sufficient detail on task definitions, trial counts, failure modes, and statistical analysis, which weakens the interpretability of the 86% success rate and blinded preference results. In the revised version we will expand this section to explicitly define each manipulation task, report the exact number of trials per task (including breakdowns for contact localization and full trajectory execution), provide a failure mode analysis, and include statistical tests (e.g., confidence intervals or significance tests) comparing against teleoperation baselines. revision: yes
Circularity Check
No circularity; empirical claims rest on direct experimental measurement
full rationale
The provided abstract and description contain no equations, fitted parameters, self-citations, or derivation steps that reduce any result to its inputs by construction. The central claims (86% success rate, preference over teleoperation) are presented as outcomes of experiments on diverse tasks and a blinded user study, with the framework described at a high level without mathematical self-reference. This is a standard empirical robotics paper whose performance numbers are externally falsifiable via replication and thus self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hand-object interaction cues visible in monocular video are sufficient to recover temporally consistent 3D hand motion and localize contact onsets.
Reference graph
Works this paper leans on
-
[1]
J. Ma, E. Zhang, H. Yang, D. Li, C. Xu, G. Wang, and H. Wang. Robot learning from human videos: A survey.arXiv preprint arXiv:2604.27621, 2026
Pith/arXiv arXiv 2026
- [2]
-
[3]
J. Shi, Z. Zhao, T. Wang, I. Pedroza, A. Luo, J. Wang, J. Ma, and D. Jayaraman. Zeromimic: Distilling robotic manipulation skills from web videos. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 16939–16947. IEEE, 2025
2025
-
[4]
H. Zhou, R. Wang, Y . Tai, Y . Deng, G. Liu, and K. Jia. You only teach once: Learn one-shot bimanual robotic manipulation from video demonstrations.arXiv preprint arXiv:2501.14208, 2025
arXiv 2025
-
[5]
J. Ren, P. Sundaresan, D. Sadigh, S. Choudhury, and J. Bohg. Motion tracks: A unified repre- sentation for human-robot transfer in few-shot imitation learning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8802–8810. IEEE, 2025
2025
-
[6]
Papagiannis, N
G. Papagiannis, N. Di Palo, P. Vitiello, and E. Johns. R+ x: Retrieval and execution from everyday human videos. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8284–8290. IEEE, 2025
2025
-
[7]
H. Freeman, C. H. Kim, and G. Kantor. Warped: Wrist-aligned rendering for robot policy learning from egocentric human demonstrations.arXiv preprint arXiv:2604.10809, 2026
Pith/arXiv arXiv 2026
-
[8]
S. Bahl, R. Mendonca, L. Chen, U. Jain, and D. Pathak. Affordances from human videos as a versatile representation for robotics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13778–13790, 2023
2023
- [9]
-
[10]
Bharadhwaj, R
H. Bharadhwaj, R. Mottaghi, A. Gupta, and S. Tulsiani. Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation. InEuropean Conference on Computer Vision, pages 306–324. Springer, 2024
2024
-
[11]
H. G. Singh, A. Loquercio, C. Sferrazza, J. Wu, H. Qi, P. Abbeel, and J. Malik. Hand-object interaction pretraining from videos. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 3352–3360. IEEE, 2025
2025
-
[12]
H. Chen, C. Zhu, S. Liu, Y . Li, and K. Driggs-Campbell. Tool-as-interface: Learning robot policies from observing human tool use.arXiv preprint arXiv:2504.04612, 2025. 9
arXiv 2025
-
[13]
Y . Zhu, A. Lim, P. Stone, and Y . Zhu. Vision-based manipulation from single human video with open-world object graphs.arXiv preprint arXiv:2405.20321, 2024
arXiv 2024
-
[14]
M. A. Pace, P. Dan, C. Ning, A. Bhardwaj, A. Du, E. W. Duan, W.-C. Ma, and K. Kedia. X-diffusion: Training diffusion policies on cross-embodiment human demonstrations.arXiv preprint arXiv:2511.04671, 2025
Pith/arXiv arXiv 2025
-
[15]
Kareer, D
S. Kareer, D. Patel, R. Punamiya, P. Mathur, S. Cheng, C. Wang, J. Hoffman, and D. Xu. Egomimic: Scaling imitation learning via egocentric video. In2025 IEEE International Con- ference on Robotics and Automation (ICRA), pages 13226–13233. IEEE, 2025
2025
-
[16]
V . Liu, A. Adeniji, H. Zhan, S. Haldar, R. Bhirangi, P. Abbeel, and L. Pinto. Egozero: Robot learning from smart glasses.arXiv preprint arXiv:2505.20290, 2025
arXiv 2025
-
[17]
W. Dong, D. Huang, J. Liu, C. Tang, and H. Zhang. Rtagrasp: Learning task-oriented grasping from human videos via retrieval, transfer, and alignment. In2025 IEEE International Confer- ence on Robotics and Automation (ICRA), pages 1–7. IEEE, 2025
2025
-
[18]
Z. Xiao, R. Wang, and X. Chen. Robopca: Pose-centered affordance learning from human demonstrations for robot manipulation.arXiv preprint arXiv:2603.07691, 2026
arXiv 2026
-
[19]
T. Feix, J. Romero, H.-B. Schmiedmayer, A. M. Dollar, and D. Kragic. The grasp taxonomy of human grasp types.IEEE Transactions on human-machine systems, 46(1):66–77, 2015
2015
-
[20]
J. Bohg, A. Morales, T. Asfour, and D. Kragic. Data-driven grasp synthesis—a survey.IEEE Transactions on robotics, 30(2):289–309, 2013
2013
-
[21]
Y . Shi, Z. Guo, R. Wolf, E. Welte, and R. Rayyes. Hograspflow: Taxonomy-aware hand-object retargeting for multi-modal se(3) grasp generation.arXiv preprint arXiv:2509.16871, 2026
arXiv 2026
-
[22]
C. Xin, M. Yu, Y . Jiang, Z. Zhang, and X. Li. Analyzing key objectives in human-to-robot retargeting for dexterous manipulation.IEEE Robotics and Automation Practice, 2026
2026
-
[23]
J. Ma, E. Zhang, Y .-D. Zheng, Y . Xie, Y . Zhou, and H. Wang. Egoloc: A generalizable solution for temporal interaction localization in egocentric videos.arXiv preprint arXiv:2508.12349, 2025
arXiv 2025
- [24]
-
[25]
S. Haldar and L. Pinto. Point policy: Unifying observations and actions with key points for robot manipulation.arXiv preprint arXiv:2502.20391, 2025
arXiv 2025
-
[26]
D. Cho, Y . Jang, D. Xu, and S. Ha. Egoavflow: Robot policy learning with active vision from human egocentric videos via 3d flow.arXiv preprint arXiv:2602.22461, 2026
arXiv 2026
-
[27]
H. Chen, B. Sun, A. Zhang, M. Pollefeys, and S. Leutenegger. Vidbot: Learning generalizable 3d actions from in-the-wild 2d human videos for zero-shot robotic manipulation. InProceed- ings of the Computer Vision and Pattern Recognition Conference, pages 27661–27672, 2025
2025
-
[28]
K. Shaw, S. Bahl, and D. Pathak. Videodex: Learning dexterity from internet videos. In Conference on Robot Learning, pages 654–665. PMLR, 2023
2023
-
[29]
Xiong, H
H. Xiong, H. Fu, J. Zhang, C. Bao, Q. Zhang, Y . Huang, W. Xu, A. Garg, and C. Lu. Robotube: Learning household manipulation from human videos with simulated twin environments. In 6th Annual Conference on Robot Learning, 2022
2022
-
[30]
G. Chen, M. Wang, T. Cui, Y . Mu, H. Lu, T. Zhou, Z. Peng, M. Hu, H. Li, L. Yuan, et al. Vlmimic: Vision language models are visual imitation learner for fine-grained actions.Ad- vances in Neural Information Processing Systems, 37:77860–77887, 2024. 10
2024
-
[31]
Kokic, D
M. Kokic, D. Kragic, and J. Bohg. Learning task-oriented grasping from human activity datasets.IEEE Robotics and Automation Letters, 5(2):3352–3359, 2020
2020
-
[32]
X. Dong and W. Zhi. Affordance transfer across object instances via semantically anchored functional map.arXiv preprint arXiv:2602.14874, 2026
arXiv 2026
-
[33]
R. Wang, H. Zhou, X. Yao, G. Liu, and K. Jia. Gat-grasp: Gesture-driven affordance transfer for task-aware robotic grasping. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1076–1083. IEEE, 2025
2025
-
[34]
C. Pan, C. Wang, H. Qi, Z. Liu, H. Bharadhwaj, A. Sharma, T. Wu, G. Shi, J. Malik, and F. Hogan. Spider: Scalable physics-informed dexterous retargeting.arXiv preprint arXiv:2511.09484, 2025
arXiv 2025
- [35]
-
[36]
H.-S. Fang, C. Wang, M. Gou, and C. Lu. Graspnet-1billion: A large-scale benchmark for gen- eral object grasping. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), pages 11441–11450, 2020
2020
-
[37]
Sundermeyer, A
M. Sundermeyer, A. Mousavian, R. Triebel, and D. Fox. Contact-graspnet: Efficient 6-dof grasp generation in cluttered scenes. In2021 IEEE international conference on robotics and automation (ICRA), pages 13438–13444. IEEE, 2021
2021
-
[38]
Urain, N
J. Urain, N. Funk, J. Peters, and G. Chalvatzaki. Se (3)-diffusionfields: Learning smooth cost functions for joint grasp and motion optimization through diffusion. In2023 IEEE interna- tional conference on robotics and automation (ICRA), pages 5923–5930. IEEE, 2023
2023
-
[39]
B. Lim, J. Kim, J. Kim, Y . Lee, and F. C. Park. Equigraspflow: SE(3)-equivariant 6-dof grasp pose generative flows. In8th Annual Conference on Robot Learning, 2024
2024
-
[40]
Khargonkar, N
N. Khargonkar, N. Song, Z. Xu, B. Prabhakaran, and Y . Xiang. Neuralgrasps: Learning im- plicit representations for grasps of multiple robotic hands. InConference on robot learning, pages 516–526. PMLR, 2023
2023
-
[41]
Attarian, M
M. Attarian, M. A. Asif, J. Liu, R. Hari, A. Garg, I. Gilitschenski, and J. Tompson. Geometry matching for multi-embodiment grasping. InConference on Robot Learning, pages 1242–
-
[42]
Huang, W
D. Huang, W. Dong, C. Tang, and H. Zhang. Hgdiffuser: efficient task-oriented grasp gener- ation via human-guided grasp diffusion models. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 19538–19545. IEEE, 2025
2025
-
[43]
R. A. Potamias, J. Zhang, J. Deng, and S. Zafeiriou. Wilor: End-to-end 3d hand localization and reconstruction in-the-wild. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12242–12254, 2025
2025
-
[44]
H. Lin, S. Chen, J. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
Pith/arXiv arXiv 2025
-
[45]
Nierhoff, S
T. Nierhoff, S. Hirche, and Y . Nakamura. Spatial adaption of robot trajectories based on lapla- cian trajectory editing.Autonomous Robots, 40(1):159–173, 2016
2016
-
[46]
S ¨arkk¨a
S. S ¨arkk¨a. Unscented rauch–tung–striebel smoother.IEEE transactions on automatic control, 53(3):845–849, 2008
2008
-
[47]
Jung and K
D. Jung and K. M. Lee. Learning dense hand contact estimation from imbalanced data.Ad- vances in Neural Information Processing Systems, 38:120351–120384, 2026. 11
2026
-
[48]
Prakash, B
A. Prakash, B. Lundell, D. Andreychuk, D. Forsyth, S. Gupta, and H. Sawhney. How do i do that? synthesizing 3d hand motion and contacts for everyday interactions. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7026–7036, 2025
2025
-
[49]
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
Pith/arXiv arXiv 2025
-
[50]
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[51]
J. Sola, J. Deray, and D. Atchuthan. A micro lie theory for state estimation in robotics.arXiv preprint arXiv:1812.01537, 2018
arXiv 2018
-
[52]
W. Cho, J. Lee, M. Yi, M. Kim, T. Woo, D. Kim, T. Ha, H. Lee, J.-H. Ryu, W. Woo, et al. Dense hand-object (ho) graspnet with full grasping taxonomy and dynamics. InEuropean Conference on Computer Vision, pages 284–303. Springer, 2024
2024
-
[53]
L. Yang, K. Li, X. Zhan, F. Wu, A. Xu, L. Liu, and C. Lu. Oakink: A large-scale knowl- edge repository for understanding hand-object interaction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20953–20962, 2022
2022
-
[54]
Ester, H.-P
M. Ester, H.-P. Kriegel, J. Sander, X. Xu, et al. A density-based algorithm for discovering clusters in large spatial databases with noise. Inkdd, volume 96, pages 226–231, 1996
1996
-
[55]
Hampali, M
S. Hampali, M. Rad, M. Oberweger, and V . Lepetit. Honnotate: A method for 3d annotation of hand and object poses. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3196–3206, 2020
2020
-
[56]
Calli, A
B. Calli, A. Singh, A. Walsman, S. Srinivasa, P. Abbeel, and A. M. Dollar. The ycb object and model set: Towards common benchmarks for manipulation research. In2015 international conference on advanced robotics (ICAR), pages 510–517. IEEE, 2015
2015
-
[57]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
Pith/arXiv arXiv 2023
-
[58]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[59]
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations.arXiv preprint arXiv:2403.03954, 2024. 12 A Robust hand motion recovery MANO hand parameterizationMANO [24] provides a low-dimensional hand representation with pose and shape parameters. We denote the wrist pos...
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.