Optimal Post-Training Quantization Scales and Where to Find Them
Pith reviewed 2026-06-27 13:56 UTC · model grok-4.3
The pith
PiSO computes exact optimal channel-wise weight scales for round-to-nearest quantization by partitioning the search space into intervals with closed-form minimizers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
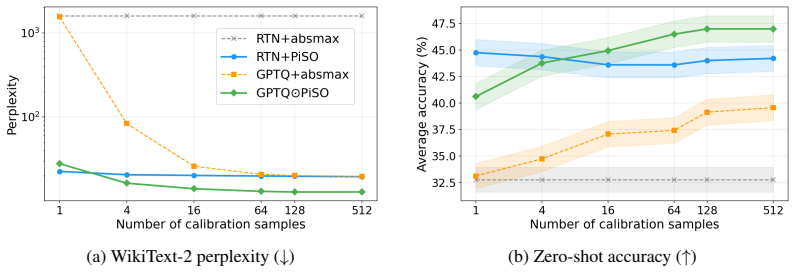
PiSO leverages calibration data to compute the optimal channel-wise weight scales exactly and efficiently under round-to-nearest quantization by partitioning the scale search space into finitely many intervals on which the objective admits a closed-form minimizer. Experiments on Llama and Qwen models show consistent gains in perplexity and zero-shot accuracy, both alone and when interleaved with error correction, with larger benefits at narrower bit widths.
What carries the argument
The partitioning of the scale search space into finitely many intervals, each admitting a closed-form minimizer of the round-to-nearest quantization objective.
If this is right
- Consistent reductions in perplexity and gains in zero-shot accuracy on Llama and Qwen models of varying sizes.
- Larger accuracy improvements appear as the target weight bit-width is lowered.
- The method combines effectively with existing error-correction techniques.
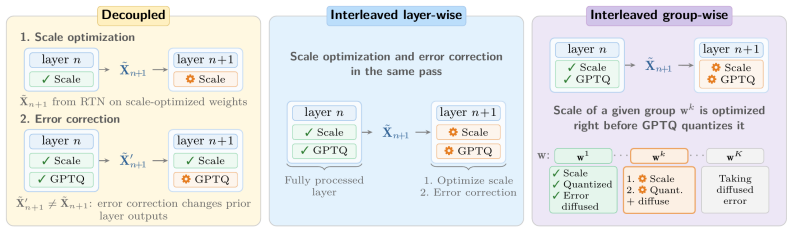
- Group-wise quantization is handled through principled heuristics that preserve the core partitioning approach.
Where Pith is reading between the lines
- The closed-form property could be checked on other common quantization objectives to see whether similar exact solutions exist without search.
- Because the method is exact on the calibration set, it supplies a reproducible baseline that heuristic scale choices can be measured against directly.
- The computational cost of the interval enumeration stays independent of model size once the per-channel statistics are collected, suggesting the technique remains practical for very large models.
Load-bearing premise
The quantization error objective can be partitioned into finitely many intervals each having a closed-form minimizer.
What would settle it
A counter-example in which the scale returned by PiSO produces strictly higher quantization error than the scale found by exhaustive search over a fine grid on the same calibration data.
Figures


read the original abstract
Post-training quantization (PTQ) compresses large language models by mapping weights to low-bit representations. The scaling factor that defines the quantization grid is typically chosen using simple, data-free heuristics. In this work, we present PiSO (Piecewise Scale Optimization), an algorithm that leverages calibration data to compute the optimal channel-wise weight scales exactly and efficiently under round-to-nearest quantization. PiSO partitions the scale search space into finitely many intervals on which the objective admits a closed-form minimizer. We extend PiSO to group-wise quantization via principled heuristics and propose effective strategies for interleaving scale optimization with error correction. Experiments on Llama and Qwen models across multiple model sizes and target weight bit-widths demonstrate consistent improvements in perplexity and downstream zero-shot accuracy, both standalone and combined with error correction. In particular, we observe increased benefits as the target bit-width narrows and quantization becomes more challenging.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PiSO (Piecewise Scale Optimization) for post-training quantization of LLMs. It claims to compute exact optimal channel-wise weight scales under round-to-nearest by partitioning the scale domain into finitely many intervals at critical points s = w_i/k (for each weight w_i and admissible integer k), such that rounding assignments are constant inside each open interval; the per-channel MSE then reduces to a quadratic whose minimizer is the closed-form least-squares solution s* = (r·w)/||r||^2. The global optimum is found by evaluating the O(1) candidate s* that fall inside their originating intervals plus endpoints. The method is extended to group-wise quantization via heuristics and interleaved with error correction; experiments on Llama and Qwen models report consistent perplexity and zero-shot accuracy gains, larger at narrower bit-widths.
Significance. If the partitioning argument and closed-form derivation hold, the work supplies a principled, data-driven alternative to heuristic scale selection in PTQ. The finite-interval construction yielding exact minimizers without exhaustive search or fitting is a technical strength, as is the reported empirical improvement that grows with quantization difficulty. Reproducible closed-form solutions and calibration-data grounding are positive features.
minor comments (2)
- [Abstract] The abstract states that PiSO is extended to group-wise quantization 'via principled heuristics,' but does not name or derive those heuristics; a short description or reference to the relevant section would clarify how the channel-wise closed-form result is adapted without losing the exactness claim.
- The derivation summary notes O(N·2^b) candidate intervals; if the manuscript contains an explicit complexity statement or pseudocode for interval enumeration and candidate filtering, it should be cross-referenced in the main text for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their accurate summary of the manuscript, positive assessment of the technical contribution, and recommendation of minor revision. No major comments were raised.
Circularity Check
No significant circularity; derivation is self-contained mathematical partitioning
full rationale
The paper derives PiSO by partitioning the scale search space at the finitely many critical points s = w_i / k where rounding assignments change under round-to-nearest, then solving the quadratic MSE objective in closed form within each interval. This follows directly from the definition of the quantization objective and the round-to-nearest operator; no parameter is fitted and then renamed as a prediction, no self-citation chain is load-bearing for the central claim, and the construction uses only calibration data plus the standard MSE model. The method is therefore internally consistent and does not reduce to its inputs by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Quantization uses round-to-nearest mapping
Reference graph
Works this paper leans on
-
[1]
OPTQ: Accurate post-training quantization for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. OPTQ: Accurate post-training quantization for generative pre-trained transformers. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[2]
GPTAQ: Efficient finetuning-free quantization for asymmetric calibration
Yuhang Li, Ruokai Yin, Donghyun Lee, Shiting Xiao, and Priyadarshini Panda. GPTAQ: Efficient finetuning-free quantization for asymmetric calibration. InForty-second International Conference on Machine Learning, 2025
2025
-
[3]
Qronos: Correcting the past by shaping the future
Shihao Zhang, Haoyu Zhang, Ian Colbert, and Rayan Saab. Qronos: Correcting the past by shaping the future... in post-training quantization. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[4]
Castro, Denis Kuznedelev, Andrei Panferov, Eldar Kurtic, Shubhra Pandit, Alexandre Noll Marques, Mark Kurtz, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh
Vage Egiazarian, Roberto L. Castro, Denis Kuznedelev, Andrei Panferov, Eldar Kurtic, Shubhra Pandit, Alexandre Noll Marques, Mark Kurtz, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Bridging the gap between promise and performance for microscaling FP4 quantization. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[5]
MixQuant: Pushing the limits of block rotations in post-training quantization
Sai Sanjeet, Ian Colbert, Pablo Monteagudo-Lago, Giuseppe Franco, Yaman Umuroglu, and Nicholas J Fraser. MixQuant: Pushing the limits of block rotations in post-training quantization. arXiv preprint arXiv:2601.22347, 2026
Pith/arXiv arXiv 2026
-
[6]
Pranav Ajit Nair and Arun Sai Suggala. CDQuant: Accurate post-training weight quantization of large pre-trained models using greedy coordinate descent.CoRR, abs/2406.17542, 2024
arXiv 2024
-
[7]
COMQ: A backpropagation-free algorithm for post-training quantization.IEEE Access, 2025
Aozhong Zhang, Zi Yang, Naigang Wang, Yingyong Qi, Jack Xin, Xin Li, and Penghang Yin. COMQ: A backpropagation-free algorithm for post-training quantization.IEEE Access, 2025
2025
-
[8]
Beacon: Post-training quantization with integrated grid selection
Shihao Zhang and Rayan Saab. Beacon: Post-training quantization with integrated grid selection. IEEE Signal Processing Letters, 2026
2026
-
[9]
Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. QuaRot: Outlier-free 4-bit inference in rotated LLMs. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[10]
SpinQuant: LLM quantization with learned rotations
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. SpinQuant: LLM quantization with learned rotations. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[11]
Optimal brain compression: A framework for accurate post- training quantization and pruning.Advances in Neural Information Processing Systems, 35: 4475–4488, 2022
Elias Frantar and Dan Alistarh. Optimal brain compression: A framework for accurate post- training quantization and pruning.Advances in Neural Information Processing Systems, 35: 4475–4488, 2022
2022
-
[12]
A greedy algorithm for quantizing neural networks.Journal of Machine Learning Research, 22(156):1–38, 2021
Eric Lybrand and Rayan Saab. A greedy algorithm for quantizing neural networks.Journal of Machine Learning Research, 22(156):1–38, 2021
2021
-
[13]
Up or down? Adaptive rounding for post-training quantization
Markus Nagel, Rana Ali Amjad, Mart Van Baalen, Christos Louizos, and Tijmen Blankevoort. Up or down? Adaptive rounding for post-training quantization. InInternational conference on machine learning, pages 7197–7206. PMLR, 2020
2020
-
[14]
BRECQ: Pushing the limit of post-training quantization by block reconstruction
Yuhang Li, Ruihao Gong, Xu Tan, Yang Yang, Peng Hu, Qi Zhang, Fengwei Yu, Wei Wang, and Shi Gu. BRECQ: Pushing the limit of post-training quantization by block reconstruction. InInternational Conference on Learning Representations, 2021. 10
2021
-
[15]
Accurate post training quantization with small calibration sets
Itay Hubara, Yury Nahshan, Yair Hanani, Ron Banner, and Daniel Soudry. Accurate post training quantization with small calibration sets. InInternational conference on machine learning, pages 4466–4475. PMLR, 2021
2021
-
[16]
Optimize weight rounding via signed gradient descent for the quantization of llms
Wenhua Cheng, Weiwei Zhang, Haihao Shen, Yiyang Cai, Xin He, Lv Kaokao, and Yi Liu. Optimize weight rounding via signed gradient descent for the quantization of llms. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 11332–11350, 2024
2024
-
[17]
OmniQuant: Omnidirectionally calibrated quan- tization for large language models
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. OmniQuant: Omnidirectionally calibrated quan- tization for large language models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[18]
Optimal brain surgeon and general network pruning
Babak Hassibi, David G Stork, and Gregory J Wolff. Optimal brain surgeon and general network pruning. InIEEE international conference on neural networks, pages 293–299. IEEE, 1993
1993
-
[19]
Esser, Jeffrey L
Steven K. Esser, Jeffrey L. McKinstry, Deepika Bablani, Rathinakumar Appuswamy, and Dharmendra S. Modha. Learned step size quantization. InInternational Conference on Learning Representations, 2020
2020
-
[20]
ParetoQ: Improving scaling laws in extremely low-bit LLM quantization
Zechun Liu, Changsheng Zhao, Hanxian Huang, Sijia Chen, Jing Zhang, Jiawei Zhao, Scott Roy, Lisa Jin, Yunyang Xiong, Yangyang Shi, Lin Xiao, Yuandong Tian, Bilge Soran, Raghuraman Krishnamoorthi, Tijmen Blankevoort, and Vikas Chandra. ParetoQ: Improving scaling laws in extremely low-bit LLM quantization. InThe Thirty-ninth Annual Conference on Neural Info...
2026
-
[21]
GPTQ, 2022
IST-DASLab. GPTQ, 2022. URLhttps://github.com/ist-daslab/gptq
2022
-
[22]
Xilinx/brevitas: Release v0
Alessandro Pappalardo, Giuseppe Franco, Ian Colbert, Fabian Grob, Timothy Costigan, Oscar Savolainen, Andrei Stoian, Anton Gerdelan, Yaman Umuroglu, Tim Paine, et al. Xilinx/brevitas: Release v0. 12.0, 2025
2025
-
[23]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[24]
Qwen2.5 Technical Report, 2025
Qwen Team, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao L...
2025
-
[25]
Transformers: State- of-the-art natural language processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. Transformers: State- of-the-art natural language processing. InProceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, pages 38–45, 2020
2020
-
[26]
Pointer sentinel mixture models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. InInternational Conference on Learning Representations, 2017
2017
-
[27]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
Pith/arXiv arXiv 2018
-
[28]
Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 4791–4800, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 4791–4800, 2019
2019
-
[29]
LightEval: A lightweight framework for llm evaluation, 2023
Nathan Habib, Clémentine Fourrier, Hynek Kydlí ˇcek, Thomas Wolf, and Lewis Tunstall. LightEval: A lightweight framework for llm evaluation, 2023. URL https://github.com/ huggingface/lighteval. 11
2023
-
[30]
OCP microscaling formats (MX) specification.Open Compute Project, 2023
Bita Darvish Rouhani, Nitin Garegrat, Tom Savell, Ankit More, Kyung-Nam Han, Ritchie Zhao, Mathew Hall, Jasmine Klar, Eric Chung, Yuan Yu, et al. OCP microscaling formats (MX) specification.Open Compute Project, 2023
2023
-
[31]
Introducing NVFP4 for efficient and accurate low-precision inference, June
Eduardo Alvarez, Omri Almog, Eric Chung, Simon Layton, Dusan Stosic, Ronny Krashinsky, and Kyle Aubrey. Introducing NVFP4 for efficient and accurate low-precision inference, June
-
[32]
NVIDIA Developer Blog
-
[33]
Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael V oznesen- sky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, Geeta Chauhan, Anjali Chourdia, Will Constable, Alban Desmaison, Zachary DeVito, Elias Ellison, Will Feng, Jiong Gong, Michael Gschwind, Brian Hirsh, Sherlock Huang, Kshiteej Kalambarkar, Laurent Kirsch, Michae...
-
[34]
On the expected complexity of integer least-squares problems
Babak Hassibi and Haris Vikalo. On the expected complexity of integer least-squares problems. In2002 IEEE International Conference on Acoustics, Speech, and Signal Processing, volume 2, pages II–1497. IEEE, 2002
2002
-
[35]
Haoyu Zhang, Shihao Zhang, Ian Colbert, and Rayan Saab. Provable post-training quantization: Theoretical analysis of OPTQ and Qronos.arXiv preprint arXiv:2508.04853, 2025. 12 Algorithm 1PiSO: Piecewise Scale Optimization Require: Weight vectorw∈R D, matrices H∈R D×D, G∈R D×D, sorted grid G={g 1, . . . , gL} Ensure:Optimal scaleˆs 1:Compute transition scal...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.