Trace Only What You Need: Structure-Aware On-Demand Hypergraph Memory for Long-Document Question Answering
Pith reviewed 2026-06-27 13:19 UTC · model grok-4.3
The pith
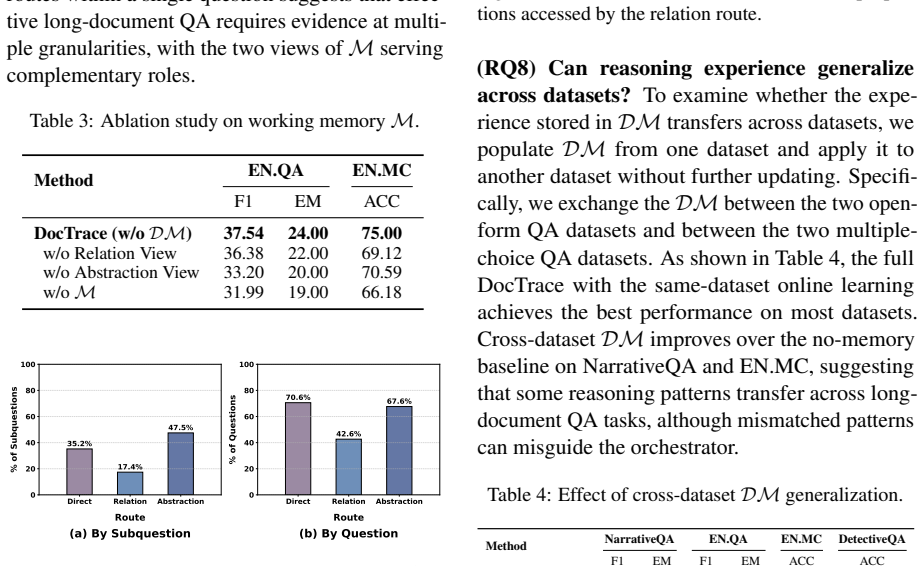
DocTrace builds on-demand hypergraph memory from document structure to improve long-document question answering while lowering computational cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
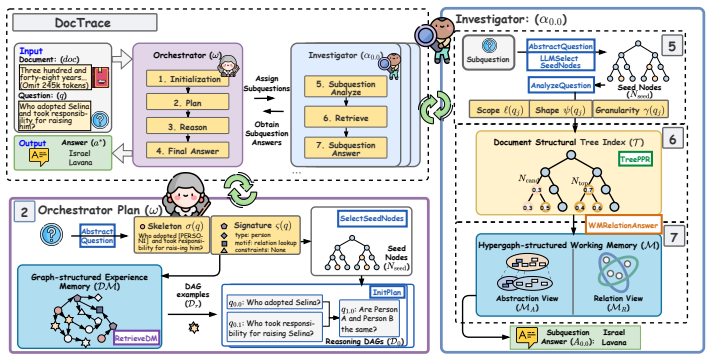
DocTrace preserves document hierarchy with a lightweight document structural tree index, constructs agent-shared hypergraph-structured working memory on demand during reasoning, and stores successful reasoning plans in graph-structured experience memory for future reuse, enabling adaptive exploration across related long-document questions and achieving superior performance with reduced cost.
What carries the argument
Query-triggered hypergraph-structured working memory built from the document structural tree combined with graph-structured experience memory for reuse.
If this is right
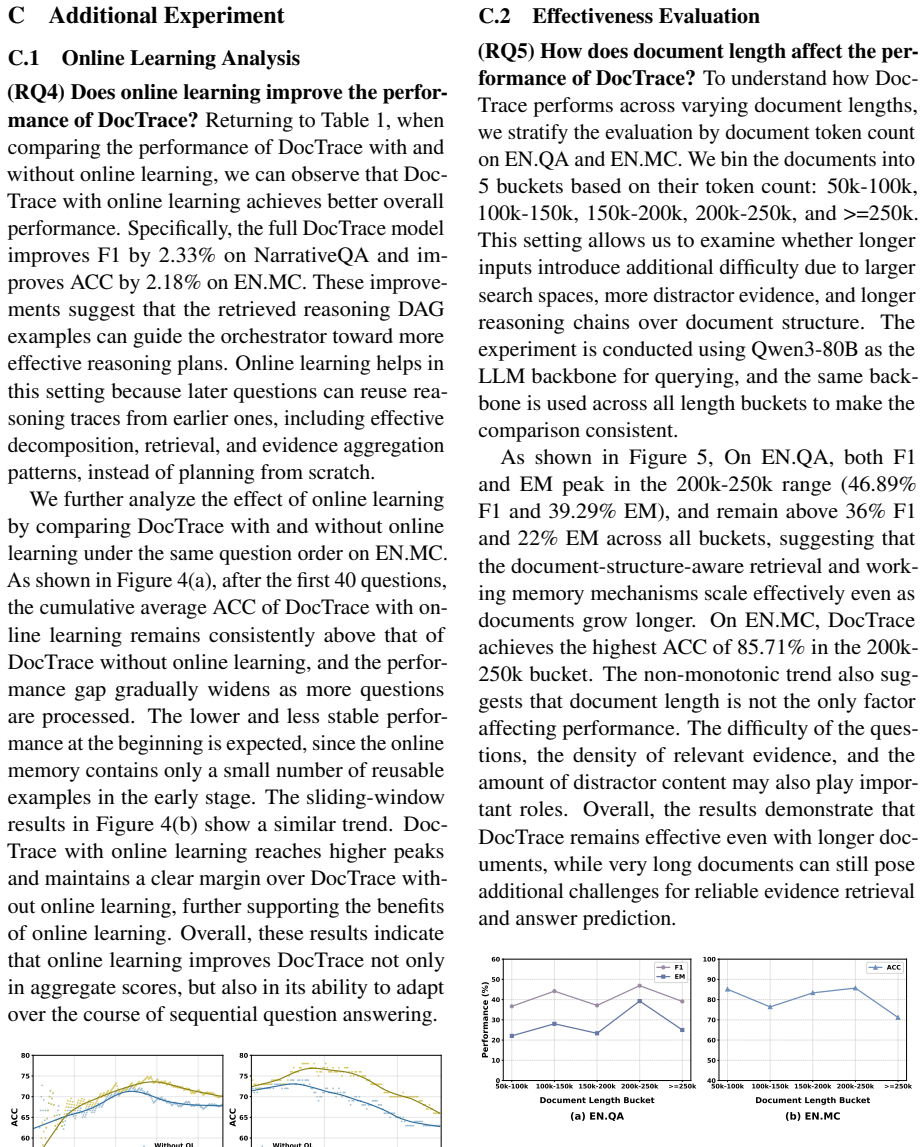
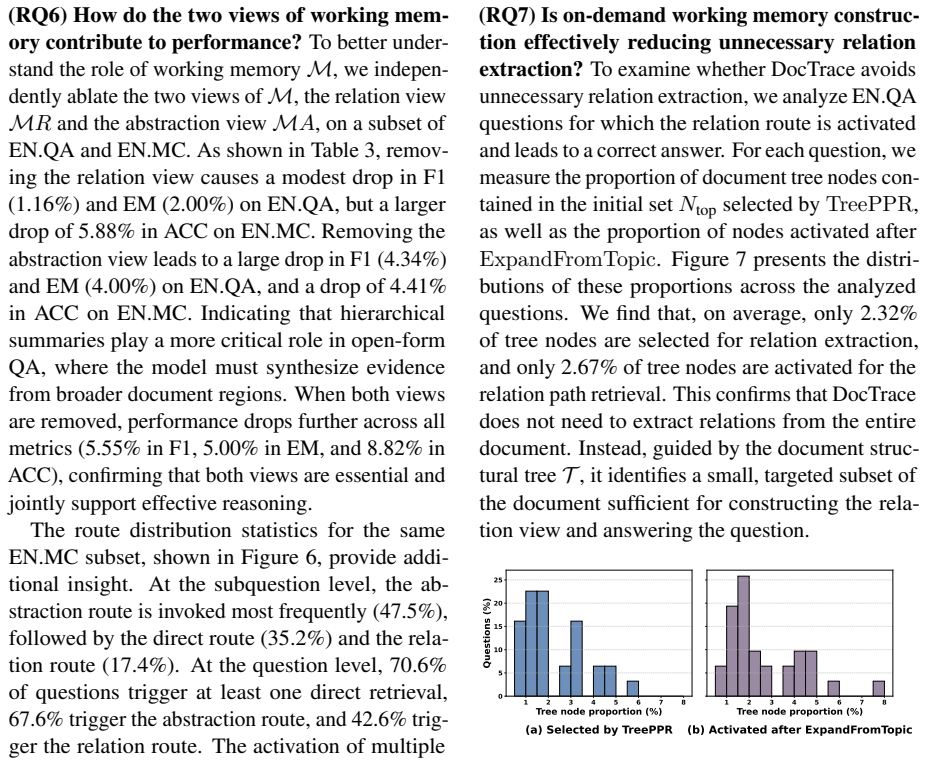
- Achieves best performance on three long-document QA datasets.
- Surpasses the strongest baseline by up to 8.85% in F1 and 4.40% in EM.
- Reduces overall computational cost by 53.32%.
- Enables adaptive exploration across related questions through experience reuse.
Where Pith is reading between the lines
- The on-demand construction could generalize to other retrieval tasks where full pre-processing is expensive.
- Reusing experience might help in few-shot adaptation for similar question types on the same document.
- If the structural tree is easy to build, it could be applied to web pages or books with clear hierarchies.
- Future work might explore dynamic updates to the experience memory as new questions are answered.
Load-bearing premise
The assumption that query-triggered hypergraph construction from the document structural tree and reuse of graph-structured experience memory will improve accuracy and reduce cost without new failure modes on unseen long-document distributions.
What would settle it
Evaluation on a held-out long-document QA dataset showing no improvement over baselines or an increase in computational cost.
Figures

read the original abstract
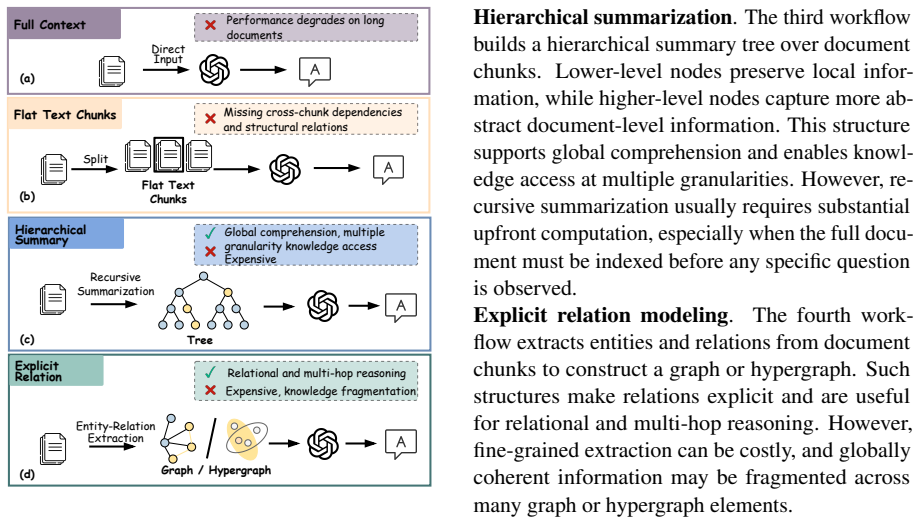
Long-document question answering (QA) requires large language models (LLMs) to reason over evidence scattered across lengthy documents, where answers often depend on event order, section-level context, and cross-part evidence connections. Although retrieval-augmented generation (RAG) reduces the input context by retrieving relevant evidence, existing structured RAG methods still face three limitations: costly query-agnostic knowledge organization, insufficient use of original document structure, and no reuse of historical reasoning experience. To address these limitations, we propose DocTrace, a multi-agent RAG framework for long-document QA that supports query-triggered knowledge organization, document-structure-aware and experience-guided reasoning. DocTrace preserves document hierarchy with a lightweight document structural tree index, constructs agent-shared hypergraph-structured working memory on demand during reasoning, and stores successful reasoning plans in graph-structured experience memory for future reuse, enabling adaptive exploration across related long-document questions. Experiments on four long-document QA datasets show that DocTrace achieves the best performance on three datasets, surpassing the strongest baseline, ComoRAG, by up to 8.85% in F1 and 4.40% in EM, while reducing the overall computational cost by 53.32%
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
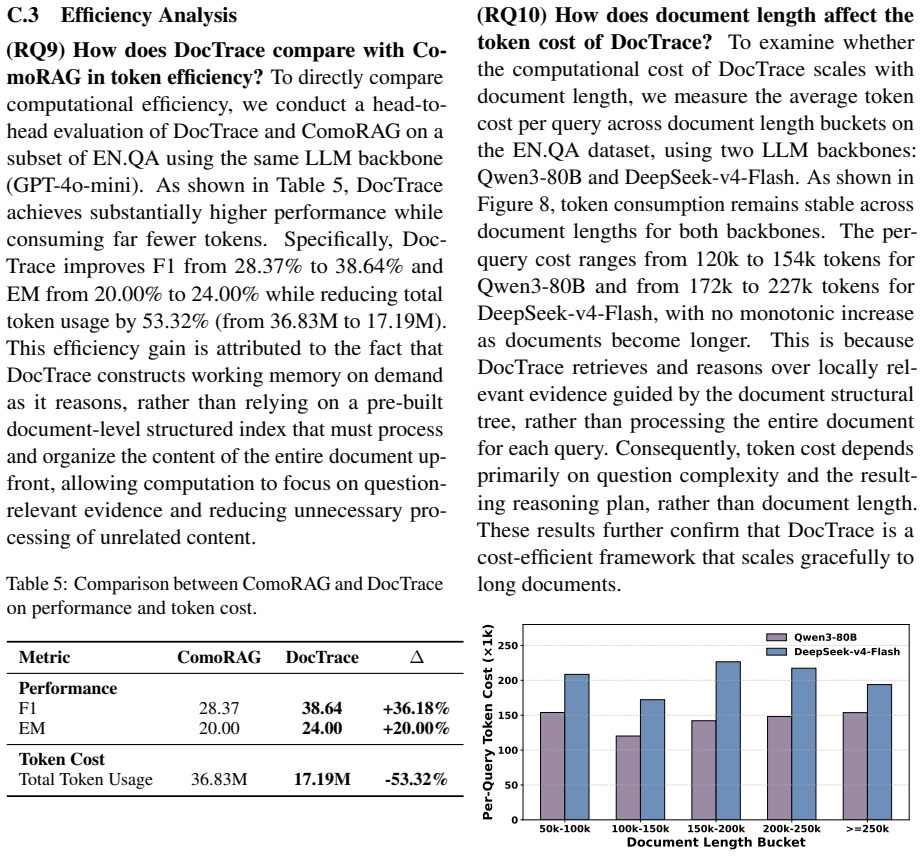
Summary. The paper introduces DocTrace, a multi-agent RAG framework for long-document QA. It preserves document hierarchy via a lightweight structural tree index, constructs agent-shared hypergraph-structured working memory on demand during reasoning, and stores successful reasoning plans in graph-structured experience memory for reuse across related questions. The central empirical claim is that DocTrace achieves the best performance on three of four long-document QA datasets, surpassing the strongest baseline ComoRAG by up to 8.85% F1 and 4.40% EM while reducing computational cost by 53.32%.
Significance. If the reported gains prove robust, the framework offers a practical advance in structured RAG by combining query-triggered hypergraph construction with experience reuse, directly targeting the limitations of query-agnostic organization and underused document structure. The on-demand memory and graph-structured experience storage are coherent design choices that could improve both accuracy and efficiency in long-context reasoning tasks.
major comments (2)
- [Abstract] Abstract: the central claim of outperforming ComoRAG by up to 8.85% F1 / 4.40% EM and achieving a 53.32% cost reduction is presented without any reference to statistical significance testing, variance across multiple runs, exact baseline re-implementations, or data splits. These omissions are load-bearing for the empirical superiority assertion on three datasets.
- [Experiments] The manuscript provides no information on how the four datasets were split, how baselines were reproduced, or whether the reported metrics reflect single runs or averages; this directly affects the reliability of the cross-dataset performance comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the empirical claims and experimental details. We address each major comment below and commit to revisions that improve the transparency and reproducibility of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of outperforming ComoRAG by up to 8.85% F1 / 4.40% EM and achieving a 53.32% cost reduction is presented without any reference to statistical significance testing, variance across multiple runs, exact baseline re-implementations, or data splits. These omissions are load-bearing for the empirical superiority assertion on three datasets.
Authors: We agree that the abstract should contextualize the reported gains with reference to the experimental protocol. In the revised version we will update the abstract to state that improvements are averaged over multiple runs and direct readers to the Experiments section for variance, data splits, and baseline reproduction details. This addresses the load-bearing concern without altering the core claims. revision: yes
-
Referee: [Experiments] The manuscript provides no information on how the four datasets were split, how baselines were reproduced, or whether the reported metrics reflect single runs or averages; this directly affects the reliability of the cross-dataset performance comparison.
Authors: The observation is accurate: the current manuscript omits these specifics. We will expand the Experiments section to document the exact train/validation/test splits for each dataset, the precise reproduction steps and hyperparameters for all baselines (including ComoRAG), and confirmation that all metrics are means over three independent runs with standard deviations. These additions will allow direct assessment of the reported comparisons. revision: yes
Circularity Check
No significant circularity; empirical framework evaluation
full rationale
The paper proposes DocTrace, a multi-agent RAG framework using document structural trees, on-demand hypergraphs, and experience memory. Its central claims are empirical performance improvements on four QA datasets (best on three, with specific F1/EM gains and cost reduction vs. ComoRAG). No equations, derivations, fitted parameters, or load-bearing self-citations appear in the provided text. The work is self-contained as a standard systems paper whose validity rests on external experimental details rather than internal reduction to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rossi and Seunghyun Yoon and Hinrich Sch
Ali Modarressi and Hanieh Deilamsalehy and Franck Dernoncourt and Trung Bui and Ryan A. Rossi and Seunghyun Yoon and Hinrich Sch. NoLiMa: Long-Context Evaluation Beyond Literal Matching , booktitle =
-
[2]
Kuan Li and Liwen Zhang and Yong Jiang and Pengjun Xie and Fei Huang and Shuai Wang and Minhao Cheng , title =
-
[3]
Jiajie Jin and Xiaoxi Li and Guanting Dong and Yuyao Zhang and Yutao Zhu and Yongkang Wu and Zhonghua Li and Ye Qi and Zhicheng Dou , title =
-
[4]
Yushi Bai and Shangqing Tu and Jiajie Zhang and Hao Peng and Xiaozhi Wang and Xin Lv and Shulin Cao and Jiazheng Xu and Lei Hou and Yuxiao Dong and Jie Tang and Juanzi Li , title =
-
[5]
A Survey on the Memory Mechanism of Large Language Model-based Agents , journal =
Zeyu Zhang and Quanyu Dai and Xiaohe Bo and Chen Ma and Rui Li and Xu Chen and Jieming Zhu and Zhenhua Dong and Ji. A Survey on the Memory Mechanism of Large Language Model-based Agents , journal =
-
[6]
Memory in the Age of
Yuyang Hu and Shichun Liu and Yanwei Yue and Guibin Zhang and Boyang Liu and Fangyi Zhu and Jiahang Lin and Honglin Guo and Shihan Dou and Zhiheng Xi and Senjie Jin and Jiejun Tan and Yanbin Yin and Jiongnan Liu and Zeyu Zhang and Zhongxiang Sun and Yutao Zhu and Hao Sun and Boci Peng and Zhenrong Cheng and Xuanbo Fan and Jiaxin Guo and Xinlei Yu and Zhen...
-
[7]
Rethinking Memory Mechanisms of Foundation Agents in the Second Half:
Wei. Rethinking Memory Mechanisms of Foundation Agents in the Second Half:. CoRR , volume =
-
[8]
2026 , url=
Rui Li and Zeyu Zhang and Xiaohe Bo and Zihang Tian and Xu Chen and Quanyu Dai and Zhenhua Dong and Ruiming Tang , booktitle=. 2026 , url=
2026
-
[9]
From Isolated Conversations to Hierarchical Schemas: Dynamic Tree Memory Representation for
Alireza Rezazadeh and Zichao Li and Wei Wei and Yujia Bao , booktitle=. From Isolated Conversations to Hierarchical Schemas: Dynamic Tree Memory Representation for. 2025 , url=
2025
-
[10]
Wenyu Tao and Xiaofen Xing and Zeliang Li and Xiangmin Xu , title =
-
[11]
From Local to Global:
Edge, Darren and Trinh, Ha and others , journal=. From Local to Global:
-
[12]
Juyuan Wang and Rongchen Zhao and Wei Wei and Yufeng Wang and Mo Yu and Jie Zhou and Jin Xu and Liyan Xu , title =
-
[13]
When to use Graphs in
Zhishang Xiang and Chuanjie Wu and Qinggang Zhang and Shengyuan Chen and Zijin Hong and Xiao Huang and Jinsong Su , booktitle=. When to use Graphs in. 2026 , url=
2026
-
[14]
arXiv preprint arXiv:2510.10114 , year=
Linearrag: Linear graph retrieval augmented generation on large-scale corpora , author=. arXiv preprint arXiv:2510.10114 , year=
-
[15]
Honnibal, Matthew and Montani, Ines and Van Landeghem, Sofie and Boyd, Adriane , doi =
-
[16]
HyperGraphRAG: Retrieval-Augmented Generation via Hypergraph-Structured Knowledge Representation , url =
Luo, Haoran and E, Haihong and Chen, Guanting and Zheng, Yandan and Wu, Xiaobao and Guo, Yikai and Lin, Qika and Feng, Yu and Kuang, Zemin and Song, Meina and Zhu, Yifan and Luu, Anh Tuan , booktitle =. HyperGraphRAG: Retrieval-Augmented Generation via Hypergraph-Structured Knowledge Representation , url =
-
[17]
2026 , booktitle =
Zai, Xiangjun and Tan, Xingyu and Wang, Xiaoyang and Liu, Qing and Xu, Xiwei and Zhang, Wenjie , title =. 2026 , booktitle =
2026
-
[18]
Bernal Jim. From. Forty-second International Conference on Machine Learning,
-
[19]
Manning , title =
Parth Sarthi and Salman Abdullah and Aditi Tuli and Shubh Khanna and Anna Goldie and Christopher D. Manning , title =
-
[20]
Akari Asai and Zeqiu Wu and Yizhong Wang and Avirup Sil and Hannaneh Hajishirzi , title =
-
[21]
L ight RAG : Simple and Fast Retrieval-Augmented Generation
Guo, Zirui and Xia, Lianghao and Yu, Yanhua and Ao, Tu and Huang, Chao. L ight RAG : Simple and Fast Retrieval-Augmented Generation. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025
2025
-
[22]
NeurIPS , year =
Bernal Jimenez Gutierrez and Yiheng Shu and Yu Gu and Michihiro Yasunaga and Yu Su , title =. NeurIPS , year =
-
[23]
Yiqian Huang and Shiqi Zhang and Xiaokui Xiao , title =
-
[24]
Jinyuan Fang and Zaiqiao Meng and Craig MacDonald , title =
-
[25]
Hyper-RAG: Combating LLM hallucina- tions using hypergraph-driven retrieval-augmented generation,
Hyper-RAG: combating LLM hallucinations using hypergraph-driven retrieval-augmented generation , author =. Nature Communications , year =. doi:10.1038/s41467-026-71411-1 , url =
-
[26]
2025 , eprint=
Improving Multi-step RAG with Hypergraph-based Memory for Long-Context Complex Relational Modeling , author=. 2025 , eprint=
2025
-
[27]
arXiv preprint arXiv:2506.06313 , year=
Beyond Chunking: Discourse-Aware Hierarchical Retrieval for Long Document Question Answering , author=. arXiv preprint arXiv:2506.06313 , year=
-
[28]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Treerag: Unleashing the power of hierarchical storage for enhanced knowledge retrieval in long documents , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[29]
Wenyu Tao and Xiaofen Xing and Yirong Chen and Linyi Huang and Xiangmin Xu , title =
-
[30]
arXiv preprint arXiv:2512.03413 , year =
BookRAG: A Hierarchical Structure-aware Index-based Approach for Retrieval-Augmented Generation on Complex Documents , author =. arXiv preprint arXiv:2512.03413 , year =. 2512.03413 , archivePrefix =
-
[31]
Xueyu Chen and Kaitao Song and Zifan Song and Dongsheng Li and Cairong Zhao , title =
-
[32]
Narasimhan and Yuan Cao , title =
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik R. Narasimhan and Yuan Cao , title =
-
[33]
NeurIPS , year =
Shunyu Yao and Dian Yu and Jeffrey Zhao and Izhak Shafran and Tom Griffiths and Yuan Cao and Karthik Narasimhan , title =. NeurIPS , year =
-
[34]
Harsh Trivedi and Niranjan Balasubramanian and Tushar Khot and Ashish Sabharwal , title =
-
[35]
arXiv preprint arXiv:2410.20753 , year=
Plan* rag: Efficient test-time planning for retrieval augmented generation , author=. arXiv preprint arXiv:2410.20753 , year=
-
[36]
Xinyan Guan and Jiali Zeng and Fandong Meng and Chunlei Xin and Yaojie Lu and Hongyu Lin and Xianpei Han and Le Sun and Jie Zhou , booktitle=. Deep. 2026 , url=
2026
-
[37]
Hongjin Qian and Zheng Liu and Peitian Zhang and Kelong Mao and Defu Lian and Zhicheng Dou and Tiejun Huang , title =
-
[38]
A-Mem: Agentic Memory for
Wujiang Xu and Zujie Liang and Kai Mei and Hang Gao and Juntao Tan and Yongfeng Zhang , booktitle=. A-Mem: Agentic Memory for. 2026 , url=
2026
-
[39]
2026 , url=
Zijian Zhou and Ao Qu and Zhaoxuan Wu and Sunghwan Kim and Alok Prakash and Daniela Rus and Bryan Kian Hsiang Low and Paul Pu Liang , booktitle=. 2026 , url=
2026
-
[40]
2025 , eprint=
MemEvolve: Meta-Evolution of Agent Memory Systems , author=. 2025 , eprint=
2025
-
[41]
arXiv preprint arXiv:2501.13956 , year=
Zep: a temporal knowledge graph architecture for agent memory , author=. arXiv preprint arXiv:2501.13956 , year=
-
[42]
Narasimhan and Shunyu Yao , title =
Yitao Liu and Chenglei Si and Karthik R. Narasimhan and Shunyu Yao , title =
-
[43]
The NarrativeQA Reading Comprehension Challenge , journal =
Tom. The NarrativeQA Reading Comprehension Challenge , journal =
-
[44]
B ench: Extending Long Context Evaluation Beyond 100 K Tokens
Zhang, Xinrong and Chen, Yingfa and Hu, Shengding and Xu, Zihang and Chen, Junhao and Hao, Moo and Han, Xu and Thai, Zhen and Wang, Shuo and Liu, Zhiyuan and Sun, Maosong. B ench: Extending Long Context Evaluation Beyond 100 K Tokens. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024
2024
-
[45]
arXiv preprint arXiv:2409.02465 , year=
Detectiveqa: Evaluating long-context reasoning on detective novels , author=. arXiv preprint arXiv:2409.02465 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.