Quo Vadis, Visual In-Context Learning? A Unified Benchmark Across Domains and Tasks
Pith reviewed 2026-06-27 13:23 UTC · model grok-4.3
The pith
A broad benchmark shows visual in-context models have limited ability to adapt to new image domains and tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that visual in-context learning models exhibit limited adaptation capabilities when evaluated on diverse new imaging domains and a wide range of tasks under a unified one-shot protocol, uncovering systematic failure modes not visible in prior narrow setups that reused pre-training distributions.
What carries the argument
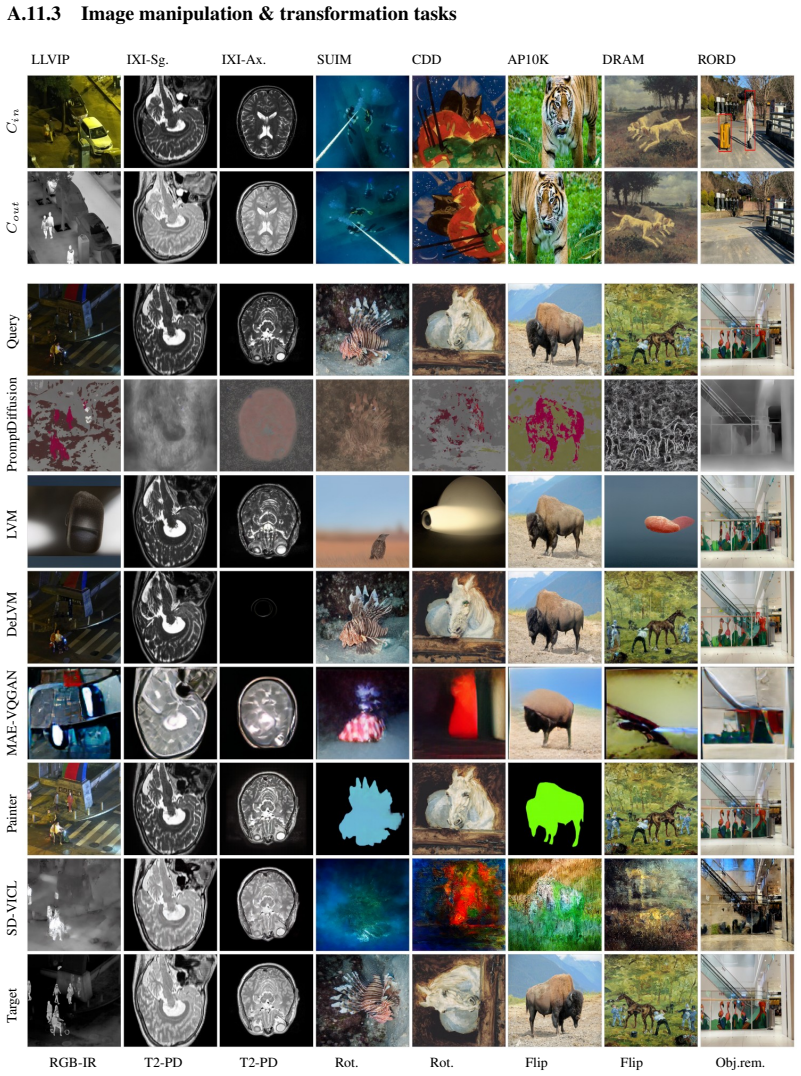
The VIBE benchmark, which organizes 106 dataset-task combinations under a reproducible one-shot evaluation protocol to measure adaptation to new distributions.
If this is right
- Current visual in-context models require targeted improvements to handle shifts in both image appearance and task structure.
- Evaluation of these models must use out-of-distribution datasets to avoid overestimating adaptation ability.
- Observed failure modes point to concrete areas where model design can be refined for better generalization.
Where Pith is reading between the lines
- Wider use of cross-domain benchmarks like this one could guide development of more robust test-time adaptation methods.
- The same stress-testing approach could be applied to in-context methods in other data modalities to check for parallel limits.
- Experiments that vary the number of context examples beyond one shot could test whether the identified failures are fixed by additional demonstrations.
Load-bearing premise
The chosen datasets and tasks are new enough relative to the models' pre-training data that performance differences reflect genuine adaptation rather than recall.
What would settle it
If the six models achieved similar accuracy on the VIBE tasks as they do on tasks drawn from their original pre-training distributions, the claim of limited adaptation to new distributions would be weakened.
Figures


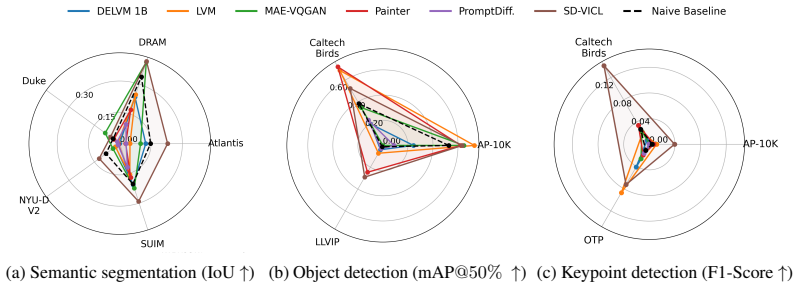
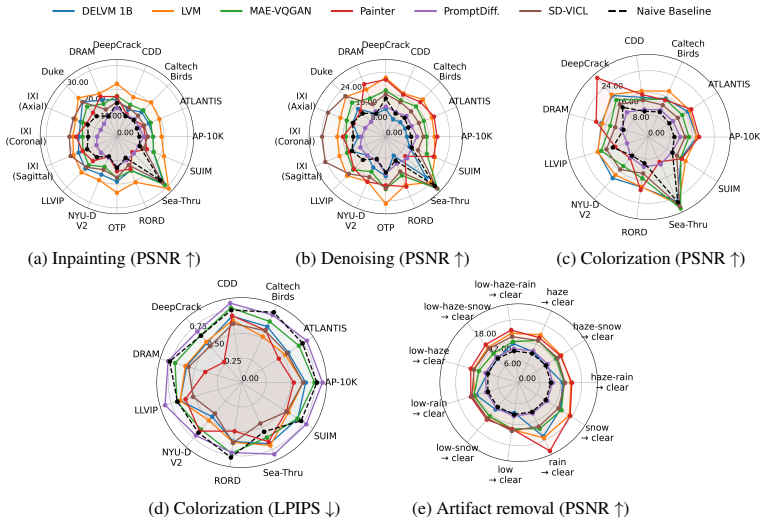
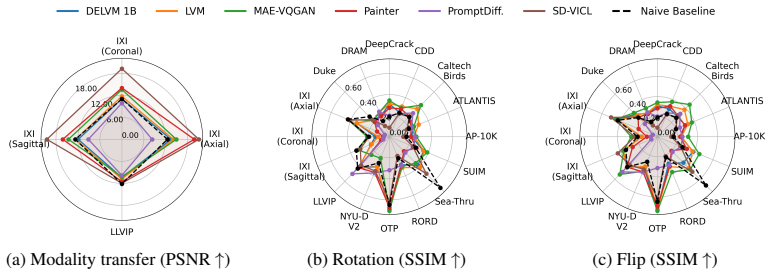
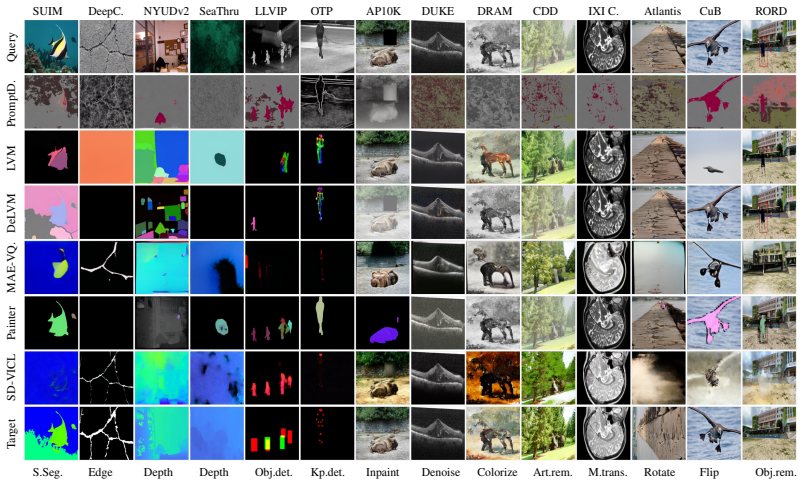







read the original abstract
Visual in-context learning has been proposed as a pathway towards dynamic models that can generate predictions based on a provided context and thereby can adapt to new vision tasks at test-time. Yet, the evaluation of the adaptation capabilities of these models has been limited to narrow setups that mainly mirror tasks or image domains from pre-training for which real adaptation is not required. We address this gap by constructing a broad Visual In-Context BEnchmark (VIBE) with a focus on diverse imaging domains and a wide range of tasks. With this, we are able to get a much clearer picture of the adaptive capabilities of visual in-context models when faced with new image- and task distributions. We stress test six models on $14$ datasets and $12$ tasks (in total, we explore $106$ dataset-task combinations) and compare them under a unified, reproducible evaluation protocol, in an one-shot setting. Our evaluation uncovers key insights on the state of visual in-context learning, including limitations, systematic failure modes and promising directions. To foster broader evaluation, we will openly release our VIBE toolkit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Visual In-Context BEnchmark (VIBE) to address limitations in prior evaluations of visual in-context learning, which often overlap with pre-training distributions. It constructs a benchmark spanning 14 datasets and 12 tasks (106 dataset-task combinations), evaluates six models in a unified one-shot protocol, and reports insights on limitations, systematic failure modes, and promising directions, with plans to release the VIBE toolkit.
Significance. If the datasets satisfy the OOD condition, the work provides a more rigorous assessment of genuine adaptation in visual in-context models than prior narrow setups. The unified reproducible protocol, broad coverage across domains and tasks, and commitment to open-sourcing the toolkit are clear strengths that would support future research.
major comments (2)
- [§3 and §4] §3 (Dataset Curation) and §4 (Evaluation Protocol): The central claim that measured one-shot performance reflects genuine adaptation (rather than recall) requires the 14 datasets to lie outside the pre-training distributions of the six models. The manuscript motivates this via diverse domains but supplies no overlap statistics, pre-training corpus comparisons, or explicit OOD verification for the chosen datasets and tasks; this verification is load-bearing for interpreting the 106 combinations as testing adaptation.
- [§5] §5 (Results and Analysis): The reported insights on systematic failure modes and promising directions are presented without quantitative breakdowns (e.g., per-model error patterns or statistical significance tests across the 106 combinations) that would allow readers to assess whether the observed limitations are robust or driven by a subset of tasks.
minor comments (2)
- [Abstract and §4] The abstract and introduction use 'one-shot setting' inconsistently with the later description of the protocol; clarify whether support examples are strictly one or few-shot.
- [Table 1] Table 1 (or equivalent dataset summary) should include explicit columns for domain diversity metrics or pre-training overlap indicators to make the selection criteria transparent.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps strengthen the claims regarding genuine adaptation and the robustness of the reported insights. We address each major comment below.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Dataset Curation) and §4 (Evaluation Protocol): The central claim that measured one-shot performance reflects genuine adaptation (rather than recall) requires the 14 datasets to lie outside the pre-training distributions of the six models. The manuscript motivates this via diverse domains but supplies no overlap statistics, pre-training corpus comparisons, or explicit OOD verification for the chosen datasets and tasks; this verification is load-bearing for interpreting the 106 combinations as testing adaptation.
Authors: We agree that explicit OOD verification is important for interpreting the results as genuine adaptation. The 14 datasets were deliberately chosen from domains (medical imaging, remote sensing, microscopy, and other specialized scientific imaging) that are known to have minimal overlap with common pre-training corpora such as ImageNet, LAION, or COCO. However, the manuscript does not include quantitative overlap statistics or direct corpus comparisons. In revision, we will add an appendix providing dataset provenance details, references to known pre-training data distributions, and any available overlap analyses or citations that support the OOD status of these tasks and domains. revision: yes
-
Referee: [§5] §5 (Results and Analysis): The reported insights on systematic failure modes and promising directions are presented without quantitative breakdowns (e.g., per-model error patterns or statistical significance tests across the 106 combinations) that would allow readers to assess whether the observed limitations are robust or driven by a subset of tasks.
Authors: The current manuscript already reports full performance tables and figures covering all 106 dataset-task combinations, which form the basis for the discussed patterns and failure modes. To increase rigor, we will augment Section 5 with additional quantitative elements: per-model aggregated statistics across task categories, breakdowns of error patterns (e.g., by failure type), and statistical significance tests (such as paired comparisons or non-parametric tests) across the combinations to confirm that the observed limitations are not driven by outliers. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or self-referential reductions
full rationale
The paper constructs and applies the VIBE benchmark to evaluate six models across 106 dataset-task combinations in a one-shot setting. No equations, fitted parameters, or derivations are present. The central claims rest on direct experimental comparisons under a unified protocol rather than any quantity that reduces to its own inputs by construction. Dataset selection is motivated by the goal of testing adaptation outside pre-training distributions, but this is an empirical assumption (not a derived result) and does not create circularity. No self-citation chains or ansatzes are invoked to justify core results. The work is self-contained as a benchmark study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption One-shot evaluation is a valid protocol for measuring adaptation to new distributions.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Akkaynak, D., Treibitz, T.: Sea-thru: A method for removing water from underwater images. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1682–1691 (2019)
2019
-
[2]
In: ACM SIGGRAPH 2024 conference papers
Alaluf, Y ., Garibi, D., Patashnik, O., Averbuch-Elor, H., Cohen-Or, D.: Cross-image attention for zero-shot appearance transfer. In: ACM SIGGRAPH 2024 conference papers. pp. 1–12 (2024)
2024
-
[3]
arXiv preprint arXiv:2503.09837 (2025)
Anis, A.M., Ali, H., Sarfraz, S.: On the limitations of vision-language models in understanding image transforms. arXiv preprint arXiv:2503.09837 (2025)
arXiv 2025
-
[4]
In: 2020 International joint conference on neural networks (IJCNN)
Arazo, E., Ortego, D., Albert, P., O’Connor, N.E., McGuinness, K.: Pseudo-labeling and confirmation bias in deep semi-supervised learning. In: 2020 International joint conference on neural networks (IJCNN). pp. 1–8. IEEE (2020)
2020
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Bai, Y ., Geng, X., Mangalam, K., Bar, A., Yuille, A.L., Darrell, T., Malik, J., Efros, A.A.: Sequential modeling enables scalable learning for large vision models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22861–22872 (2024)
2024
-
[6]
arXiv preprint arXiv:2106.08254 (2021)
Bao, H., Dong, L., Piao, S., Wei, F.: Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254 (2021)
Pith/arXiv arXiv 2021
-
[7]
Advances in neural information processing systems35, 25005–25017 (2022)
Bar, A., Gandelsman, Y ., Darrell, T., Globerson, A., Efros, A.: Visual prompting via image inpainting. Advances in neural information processing systems35, 25005–25017 (2022)
2022
-
[8]
In: International conference on machine learning
Barrett, D., Hill, F., Santoro, A., Morcos, A., Lillicrap, T.: Measuring abstract reasoning in neural networks. In: International conference on machine learning. pp. 511–520. PMLR (2018)
2018
-
[9]
Journal of machine learning research3(Feb), 1137–1155 (2003)
Bengio, Y ., Ducharme, R., Vincent, P., Jauvin, C.: A neural probabilistic language model. Journal of machine learning research3(Feb), 1137–1155 (2003)
2003
-
[10]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Bitton, Y ., Yosef, R., Strugo, E., Shahaf, D., Schwartz, R., Stanovsky, G.: Vasr: Visual analogies of situation recognition. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 241–249 (2023)
2023
-
[11]
Advances in Neural Information Processing Systems36, 73299–73311 (2023)
Blumenstiel, B., Jakubik, J., Kühne, H., Vössing, M.: What a mess: Multi-domain evaluation of zero-shot semantic segmentation. Advances in Neural Information Processing Systems36, 73299–73311 (2023)
2023
-
[12]
arXiv preprint arXiv:2604.13883 (2026)
Born, F., Neuhäuser, T., Muttenthaler, L., Roads, B.D., Spitzer, B., Lampinen, A.K., Jones, M., Müller, K.R., Mozer, M.C.: Context sensitivity improves human-machine visual alignment. arXiv preprint arXiv:2604.13883 (2026)
Pith/arXiv arXiv 2026
-
[13]
Bradski, G.: The OpenCV Library. Dr. Dobb’s Journal of Software Tools (2000) 10
2000
-
[14]
In: DAGM German Conference on Pattern Recognition
Bratuli´c, J., Mittal, S., Hoffmann, D.T., Böhm, S., Schirrmeister, R.T., Ball, T., Rupprecht, C., Brox, T.: Unlocking in-context learning for natural datasets beyond language modelling. In: DAGM German Conference on Pattern Recognition. pp. 303–319. Springer (2025)
2025
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Brooks, T., Holynski, A., Efros, A.A.: Instructpix2pix: Learning to follow image editing instructions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18392–18402 (2023)
2023
-
[16]
Advances in neural information processing systems33, 1877–1901 (2020)
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020)
1901
-
[17]
Machine learning28(1), 41–75 (1997)
Caruana, R.: Multitask learning. Machine learning28(1), 41–75 (1997)
1997
-
[18]
Advances in neural information processing systems35, 18878–18891 (2022)
Chan, S., Santoro, A., Lampinen, A., Wang, J., Singh, A., Richemond, P., McClelland, J., Hill, F.: Data distributional properties drive emergent in-context learning in transformers. Advances in neural information processing systems35, 18878–18891 (2022)
2022
-
[19]
In: International conference on machine learning
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. In: International conference on machine learning. pp. 1597–1607. PmLR (2020)
2020
-
[20]
In: Computer graphics forum
Cohen, N., Newman, Y ., Shamir, A.: Semantic segmentation in art paintings. In: Computer graphics forum. vol. 41, pp. 261–275. Wiley Online Library (2022)
2022
-
[21]
O’Reilly (2013)
Collette, A.: Python and HDF5. O’Reilly (2013)
2013
-
[22]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3213–3223 (2016)
2016
-
[23]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Czolbe, S., Dalca, A.V .: Neuralizer: General neuroimage analysis without re-training. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6217–6230 (2023)
2023
-
[24]
In: 2009 IEEE conference on computer vision and pattern recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009)
2009
-
[25]
In: International conference on machine learning
Donahue, J., Jia, Y ., Vinyals, O., Hoffman, J., Zhang, N., Tzeng, E., Darrell, T.: Decaf: A deep convolutional activation feature for generic visual recognition. In: International conference on machine learning. pp. 647–655. PMLR (2014)
2014
-
[26]
In: 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., De- hghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021....
2021
-
[27]
Environmental Modelling & Software149, 105333 (2022)
Erfani, S.M.H., Wu, Z., Wu, X., Wang, S., Goharian, E.: Atlantis: A benchmark for semantic segmentation of waterbody images. Environmental Modelling & Software149, 105333 (2022)
2022
-
[28]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y ., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[29]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution image synthesis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12873–12883 (2021)
2021
-
[30]
International journal of computer vision88(2), 303–338 (2010)
Everingham, M., Van Gool, L., Williams, C.K., Winn, J., Zisserman, A.: The pascal visual object classes (voc) challenge. International journal of computer vision88(2), 303–338 (2010)
2010
-
[31]
In: International conference on machine learning
Finn, C., Abbeel, P., Levine, S.: Model-agnostic meta-learning for fast adaptation of deep networks. In: International conference on machine learning. pp. 1126–1135. PMLR (2017) 11
2017
-
[32]
https://www.iwf.org.uk/about-us/why-we-exist/our-research/ how-ai-is-being-abused-to-create-child-sexual-abuse-imagery/ (2026), ac- cessed: 2026-05-05
Foundation, I.W.: Ai-generated child sexual abuse: 2026 report on trends, data & human impact. https://www.iwf.org.uk/about-us/why-we-exist/our-research/ how-ai-is-being-abused-to-create-child-sexual-abuse-imagery/ (2026), ac- cessed: 2026-05-05
2026
-
[33]
arXiv preprint arXiv:2306.09344 (2023)
Fu, S., Tamir, N., Sundaram, S., Chai, L., Zhang, R., Dekel, T., Isola, P.: Dreamsim: Learning new dimensions of human visual similarity using synthetic data. arXiv preprint arXiv:2306.09344 (2023)
Pith/arXiv arXiv 2023
-
[34]
In: Proceedings of the IEEE international conference on computer vision
Girshick, R.: Fast r-cnn. In: Proceedings of the IEEE international conference on computer vision. pp. 1440–1448 (2015)
2015
-
[35]
ACM Transactions on Graphics (TOG)43(4), 1–15 (2024)
Gu, Z., Yang, S., Liao, J., Huo, J., Gao, Y .: Analogist: Out-of-the-box visual in-context learning with image diffusion model. ACM Transactions on Graphics (TOG)43(4), 1–15 (2024)
2024
-
[36]
In: European conference on computer vision
Guo, Y ., Gao, Y ., Lu, Y ., Zhu, H., Liu, R.W., He, S.: Onerestore: A universal restoration framework for composite degradation. In: European conference on computer vision. pp. 255–272. Springer (2024)
2024
-
[37]
In: European conference on computer vision
Guo, Y ., Codella, N.C., Karlinsky, L., Codella, J.V ., Smith, J.R., Saenko, K., Rosing, T., Feris, R.: A broader study of cross-domain few-shot learning. In: European conference on computer vision. pp. 124–141. Springer (2020)
2020
-
[38]
In: Salakhutdinov, R., Kolter, Z., Heller, K.A., Weller, A., Oliver, N., Scarlett, J., Berkenkamp, F
Hao, Z., Guo, J., Wang, C., Tang, Y ., Wu, H., Hu, H., Han, K., Xu, C.: Data-efficient large vision models through sequential autoregression. In: Salakhutdinov, R., Kolter, Z., Heller, K.A., Weller, A., Oliver, N., Scarlett, J., Berkenkamp, F. (eds.) Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. Pr...
2024
-
[39]
Harris, C.R., Millman, K.J., van der Walt, S.J., Gommers, R., Virtanen, P., Cournapeau, D., Wieser, E., Taylor, J., Berg, S., Smith, N.J., Kern, R., Picus, M., Hoyer, S., van Kerkwijk, M.H., Brett, M., Haldane, A., del Río, J.F., Wiebe, M., Peterson, P., Gérard-Marchant, P., Sheppard, K., Reddy, T., Weckesser, W., Abbasi, H., Gohlke, C., Oliphant, T.E.: A...
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Chen, X., Xie, S., Li, Y ., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16000–16009 (2022)
2022
-
[41]
In: Pro- ceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques
Hertzmann, A., Jacobs, C.E., Oliver, N., Curless, B., Salesin, D.H.: Image analogies. In: Pro- ceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques. p. 327–340. SIGGRAPH ’01, Association for Computing Machinery, New York, NY , USA (2001). https://doi.org/10.1145/383259.383295,https://doi.org/10.1145/383259.383295
-
[42]
arXiv preprint arXiv:1902.00120 (2019)
Hill, F., Santoro, A., Barrett, D.G., Morcos, A.S., Lillicrap, T.: Learning to make analogies by contrasting abstract relational structure. arXiv preprint arXiv:1902.00120 (2019)
Pith/arXiv arXiv 1902
-
[43]
CoRR (2015),http://arxiv.org/abs/1503.02531
Hinton, G.E., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. CoRR (2015),http://arxiv.org/abs/1503.02531
Pith/arXiv arXiv 2015
-
[44]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[45]
The analogical mind: Perspectives from cognitive science pp
Hofstadter, D.R., et al.: Analogy as the core of cognition. The analogical mind: Perspectives from cognitive science pp. 499–538 (2001)
2001
-
[46]
In: International Conference on Learning Representations (2022),https://openreview.net/forum?id=nZeVKeeFYf9 12
Hu, E.J., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: International Conference on Learning Representations (2022),https://openreview.net/forum?id=nZeVKeeFYf9 12
2022
-
[47]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Hu, S., Ma, Y ., Liu, X., Wei, Y ., Bai, S.: Stratified rule-aware network for abstract visual reasoning. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 35, pp. 1567–1574 (2021)
2021
-
[48]
In: Proceedings of the IEEE international conference on computer vision
Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive instance normaliza- tion. In: Proceedings of the IEEE international conference on computer vision. pp. 1501–1510 (2017)
2017
-
[49]
Computing in Science and Engineering , keywords =
Hunter, J.D.: Matplotlib: A 2d graphics environment. Computing in Science & Engineering 9(3), 90–95 (2007). https://doi.org/10.1109/MCSE.2007.55
-
[50]
In: 2020 IEEE/RSJ international conference on intelligent robots and systems (IROS)
Islam, M.J., Edge, C., Xiao, Y ., Luo, P., Mehtaz, M., Morse, C., Enan, S.S., Sattar, J.: Semantic segmentation of underwater imagery: Dataset and benchmark. In: 2020 IEEE/RSJ international conference on intelligent robots and systems (IROS). pp. 1769–1776. IEEE (2020)
2020
-
[51]
org/ixi-dataset/,https://brain-development.org/ixi-dataset/
IXI Project: Ixi dataset: Information extraction from images.https://brain-development. org/ixi-dataset/,https://brain-development.org/ixi-dataset/
-
[52]
In: Proceedings of the IEEE/CVF international conference on computer vision
Jia, X., Zhu, C., Li, M., Tang, W., Zhou, W.: Llvip: A visible-infrared paired dataset for low-light vision. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3496–3504 (2021)
2021
-
[53]
arXiv preprint arXiv:2401.04088 (2024)
Jiang, A.Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D.S., Casas, D.d.l., Hanna, E.B., Bressand, F., et al.: Mixtral of experts. arXiv preprint arXiv:2401.04088 (2024)
Pith/arXiv arXiv 2024
-
[54]
arXiv preprint arXiv:2303.14969 (2023)
Kim, D., Kim, J., Cho, S., Luo, C., Hong, S.: Universal few-shot learning of dense prediction tasks with visual token matching. arXiv preprint arXiv:2303.14969 (2023)
arXiv 2023
-
[55]
Advances in neural information processing systems25(2012)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems25(2012)
2012
-
[56]
In: 2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG)
Kuzdeuov, A., Taratynova, D., Tleuliyev, A., Varol, H.A.: Openthermalpose: An open-source annotated thermal human pose dataset and initial yolov8-pose baselines. In: 2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG). pp. 1–8. IEEE (2024)
2024
-
[57]
IEEE Transactions on Biometrics, Behavior, and Identity Science (2025)
Kuzdeuov, A., Zakaryanov, M., Tleuliyev, A., Varol, H.A.: Openthermalpose2: Extending the open-source annotated thermal human pose dataset with more data, subjects, and poses. IEEE Transactions on Biometrics, Behavior, and Identity Science (2025)
2025
-
[58]
Current Opinion in Behavioral Sciences29, 97–104 (2019)
Lake, B.M., Salakhutdinov, R., Tenenbaum, J.B.: The omniglot challenge: a 3-year progress report. Current Opinion in Behavioral Sciences29, 97–104 (2019)
2019
-
[59]
In: Workshop on challenges in representation learning, ICML
Lee, D.H., et al.: Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In: Workshop on challenges in representation learning, ICML. vol. 3, p. 896. Atlanta (2013)
2013
-
[60]
arXiv preprint arXiv:2602.03210 (2026)
Li, Z., Duan, Z., Ye, J., Chen, C., Chen, D., Li, Y ., Chen, Y .: Viral: Visual in-context reasoning via analogy in diffusion transformers. arXiv preprint arXiv:2602.03210 (2026)
arXiv 2026
-
[61]
In: European conference on computer vision
Lin, T.Y ., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
2014
-
[62]
Neurocomputing338, 139–153 (2019)
Liu, Y ., Yao, J., Lu, X., Xie, R., Li, L.: Deepcrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing338, 139–153 (2019)
2019
-
[63]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3431–3440 (2015)
2015
-
[64]
In: Proceedings of the Annual Meeting of the Cognitive Science Society
Lu, H., Liu, Q., Ichien, N., Yuille, A.L., Holyoak, K.J.: Seeing the meaning: Vision meets semanticsin solving pictorial analogy problems. In: Proceedings of the Annual Meeting of the Cognitive Science Society. vol. 41 (2019) 13
2019
-
[65]
https:// github.com/pytorch/vision(2016)
maintainers, T., contributors: Torchvision: Pytorch’s computer vision library. https:// github.com/pytorch/vision(2016)
2016
-
[66]
https://doi.org/10.5281/zenodo.18944560, https://doi.org/10.5281/zenodo.18944560
Markiewicz, C.J., Brett, M., Hanke, M., Côté, M.A., Cipollini, B., McCarthy, P., Papadopou- los Orfanos, D., Jarecka, D., Cheng, C.P., Larson, E., Halchenko, Y .O., Cottaar, M., Ghosh, S., Wassermann, D., Gerhard, S., Lee, G.R., Baratz, Z., Moloney, B., Wang, H.T., Kastman, E., Kaczmarzyk, J., Guidotti, R., Daniel, J., Duek, O., Rokem, A., Scheltienne, M....
-
[67]
In: van der Walt, S., Millman, J
McKinney, W.: Data structures for statistical computing in python. In: van der Walt, S., Millman, J. (eds.) Proceedings of the 9th Python in Science Conference. pp. 56–61. Proceedings of the Python in Science Conference, SciPy (2010). https://doi.org/10.25080/Majora-92bf1922- 00a
-
[68]
Annals of the New York Academy of Sciences1505(1), 79–101 (2021)
Mitchell, M.: Abstraction and analogy-making in artificial intelligence. Annals of the New York Academy of Sciences1505(1), 79–101 (2021)
2021
-
[69]
In: International Workshop on Efficient Medical Artificial Intelligence
Negrini, A., Reiß, S.: Conquering the retina: Bringing visual in-context learning to oct. In: International Workshop on Efficient Medical Artificial Intelligence. pp. 21–30. Springer (2025)
2025
-
[70]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Oorloff, T., Sindagi, V ., Bandara, W.G.C., Shafahi, A., Ghiasi, A., Prakash, C., Ardekani, R.: Stable diffusion models are secretly good at visual in-context learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23604–23613 (2025)
2025
-
[71]
In: Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., Garnett, R
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., Chintala, S.: Pytorch: An imperative style, high-performance deep learning library. In: Wallach, H., Larochelle, H....
2019
-
[72]
Journal of Machine Learning Research12, 2825–2830 (2011)
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V ., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V ., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., Duchesnay, E.: Scikit-learn: Machine learning in Python. Journal of Machine Learning Research12, 2825–2830 (2011)
2011
-
[73]
In: Proceedings of the IEEE/CVF international conference on computer vision
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[74]
arXiv preprint arXiv:2604.11998 (2026)
Qiu, X., Fu, Y ., Geng, J., Ren, B., Pan, J., Wu, Z., Tang, H., Fu, Y ., Timofte, R., Sebe, N., et al.: The second challenge on cross-domain few-shot object detection at ntire 2026: Methods and results. arXiv preprint arXiv:2604.11998 (2026)
Pith/arXiv arXiv 2026
-
[75]
OpenAI blog1(8), 9 (2019)
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., et al.: Language models are unsupervised multitask learners. OpenAI blog1(8), 9 (2019)
2019
-
[76]
British Journal of Medical Psy- chology (1941) 14
Raven, J.C.: Standardization of progressive matrices, 1938. British Journal of Medical Psy- chology (1941) 14
1938
-
[77]
In: International conference on learning representations (2017)
Ravi, S., Larochelle, H.: Optimization as a model for few-shot learning. In: International conference on learning representations (2017)
2017
-
[78]
Reiß, S., Marinov, Z., Jaus, A., Seibold, C., Sarfraz, M.S., Rodner, E., Stiefelhagen, R.: Is visual in-context learning for compositional medical tasks within reach? In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2642–2652 (2025)
2025
-
[79]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[80]
In: International Conference on Medical image computing and computer- assisted intervention
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: International Conference on Medical image computing and computer- assisted intervention. pp. 234–241. Springer (2015)
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.