OpenPCC: Open and Confidential LLM Serving on Commodity TEEs
Pith reviewed 2026-06-27 12:27 UTC · model grok-4.3
The pith
OpenPCC enables confidential LLM cloud serving on commodity TEEs without proprietary hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present OpenPCC, a Confidential CIS framework that does not rely on proprietary hardware but instead uses commercially available TEEs. We implement an open-source prototype and characterize it end-to-end on a Llama-3 8B vLLM workload, separating OpenPCC's own cost from the underlying TEE hardware. Our analysis and evaluation demonstrated the feasibility and security of the system.
What carries the argument
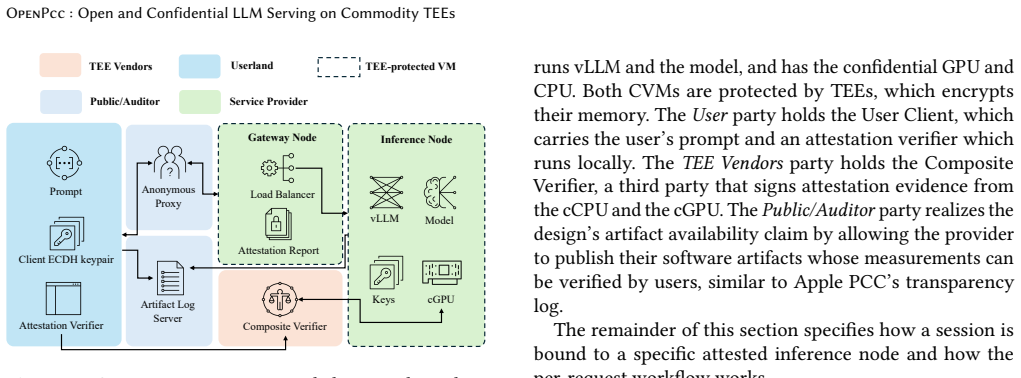
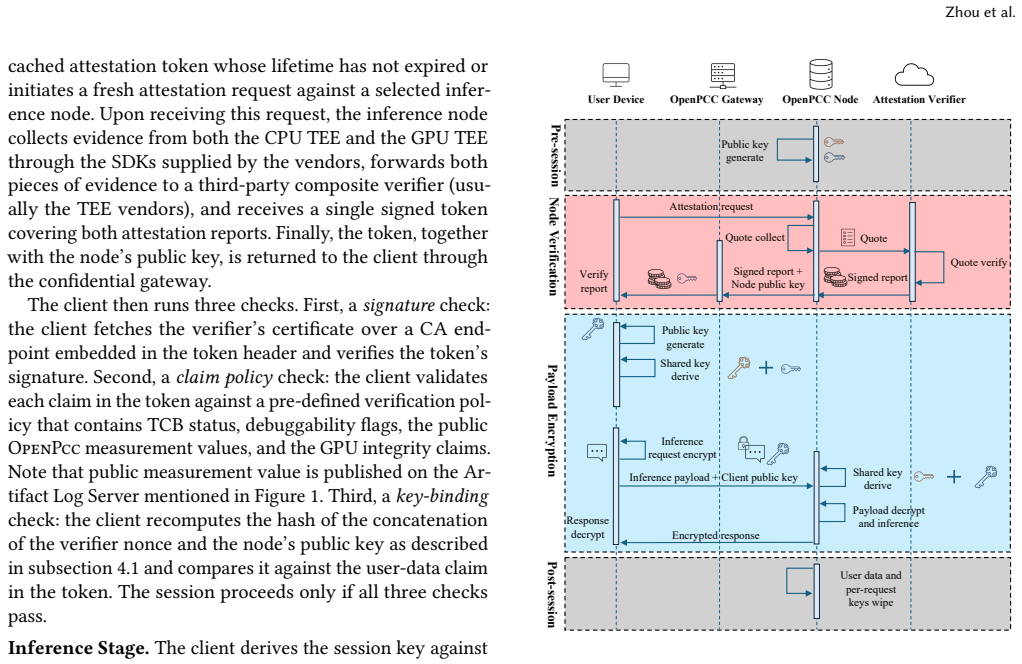
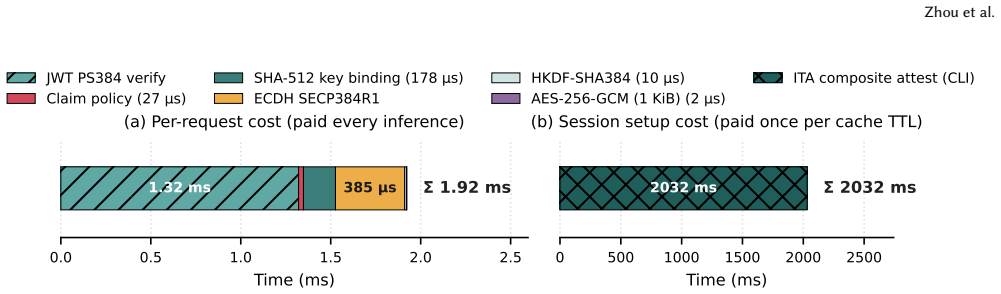
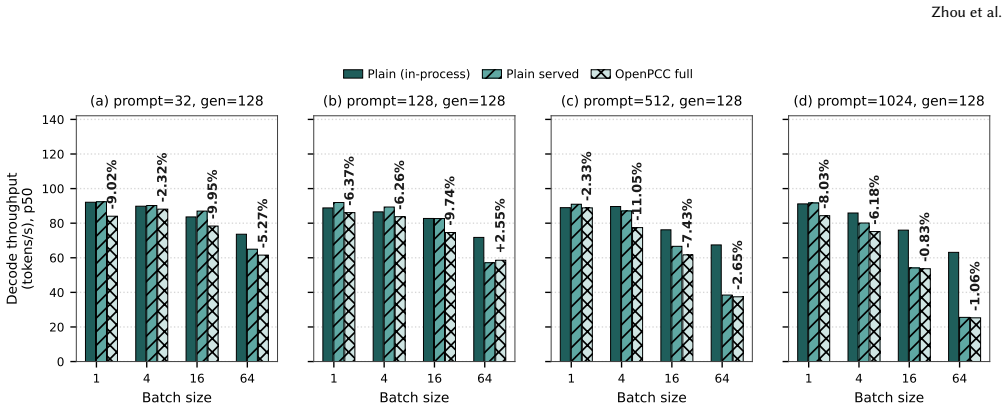
OpenPCC framework for enforcing confidentiality and isolation in LLM inference using commodity TEEs.
Load-bearing premise
Commodity TEEs deliver the required privacy protection for LLM inference without design glitches, and the open-source implementation correctly enforces isolation and confidentiality.
What would settle it
Discovery of a data leak or isolation failure in the OpenPCC prototype running the Llama-3 workload would falsify the security and feasibility claims.
Figures

read the original abstract
Generative AI applications such as personal AI agents, image generators, and chat assistants offer advanced capabilities to improve user experience. Behind the scenes, Large Language Models (LLMs) that power these services require a massive amount of computation and are usually deployed in the cloud, available as APIs, meaning that a user's request has to be sent to a Cloud Inference Service (CIS) for processing. However, the strong capabilities of LLM also mean that user's requests now contain much more personal sensitive or enterprise confidential information, demanding equally strong protection in CIS. While early industry efforts such as Apple Private Cloud Compute (PCC) and Google Private AI Compute have emerged to show the potential of secure CIS, they are not adoptable for deployment by others due to their reliance on proprietary hardware and closed ecosystem. In addition, they all suffer from their own design glitches that can undermine the ambitious goal of bringing in true privacy protection to end users. In this paper, we present our analysis of the fundamental requirements of building a secure yet open CIS. We then present OpenPCC, a Confidential CIS framework that does not rely on proprietary hardware but instead uses commercially available TEEs. We implement an open-source prototype and characterize it end-to-end on a Llama-3 8B vLLM workload, separating OpenPCC's own cost from the underlying TEE hardware. Our analysis and evaluation demonstrated the feasibility and security of the system.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OpenPCC, a framework for confidential cloud inference services (CIS) for LLMs that relies on commodity TEEs rather than proprietary hardware. It analyzes fundamental requirements for secure open CIS, implements an open-source prototype, and evaluates it end-to-end on a Llama-3 8B vLLM workload while separating OpenPCC overhead from underlying TEE costs, claiming that the analysis and evaluation demonstrate feasibility and security.
Significance. If the security and isolation properties are rigorously established, the work would provide a practical, auditable alternative to closed systems such as Apple Private Cloud Compute, enabling broader deployment of privacy-preserving LLM inference on standard hardware and addressing a key barrier to confidential AI services.
major comments (3)
- [Abstract] The abstract asserts that 'analysis and evaluation demonstrated the feasibility and security of the system,' yet the provided description supplies no quantitative security metrics, threat-model coverage, or experimental evidence of isolation (e.g., side-channel resistance or attestation results); this leaves the central security claim unsupported by visible data.
- [Evaluation] The evaluation on the Llama-3 8B vLLM workload separates OpenPCC cost from TEE hardware but does not report targeted checks for cache-timing, page-fault, or integration side channels that would confirm confinement of model weights, KV cache, prompts, and outputs inside the TEE boundary under realistic inference traffic.
- [Security Analysis] The claim that commodity TEEs avoid the design glitches identified in proprietary systems is asserted without a concrete mapping of those glitches to the chosen TEEs or a verification that the open-source integration correctly enforces the required isolation properties for the full vLLM stack.
minor comments (1)
- Notation for TEE-specific overhead components should be defined consistently across text and figures to improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below with clarifications from the manuscript and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts that 'analysis and evaluation demonstrated the feasibility and security of the system,' yet the provided description supplies no quantitative security metrics, threat-model coverage, or experimental evidence of isolation (e.g., side-channel resistance or attestation results); this leaves the central security claim unsupported by visible data.
Authors: We agree the abstract phrasing is too strong. The security argument rests on the requirements analysis (Section 3) showing how commodity TEEs satisfy the isolation and attestation properties needed for confidential CIS, together with the open prototype that places the full vLLM stack inside the TEE. No new quantitative side-channel or attestation experiments were performed; the evaluation measures only performance overhead. We will revise the abstract to read that the analysis and evaluation demonstrate feasibility, with security properties inherited from the chosen TEEs. This change will be made. revision: yes
-
Referee: [Evaluation] The evaluation on the Llama-3 8B vLLM workload separates OpenPCC cost from TEE hardware but does not report targeted checks for cache-timing, page-fault, or integration side channels that would confirm confinement of model weights, KV cache, prompts, and outputs inside the TEE boundary under realistic inference traffic.
Authors: The evaluation (Section 5) deliberately isolates OpenPCC software overhead from TEE hardware cost on the Llama-3 8B workload; it does not include new side-channel measurements. Confinement is enforced by the TEE boundary and its attestation, which we treat as given under the standard TEE threat model. We will add a short discussion subsection that enumerates the relevant side-channel vectors (cache timing, page faults) and explains why they are outside the OpenPCC threat model once the model and KV cache reside inside the enclave. Full empirical side-channel testing remains outside the scope of this paper, so the revision will be partial. revision: partial
-
Referee: [Security Analysis] The claim that commodity TEEs avoid the design glitches identified in proprietary systems is asserted without a concrete mapping of those glitches to the chosen TEEs or a verification that the open-source integration correctly enforces the required isolation properties for the full vLLM stack.
Authors: Section 4 presents a requirements-driven comparison that identifies specific glitches in closed systems (e.g., limited auditability, hardware lock-in) and shows how commodity TEEs plus open attestation address them. A more explicit mapping was omitted for brevity. We will insert a concise table that links each cited proprietary glitch to the corresponding commodity-TEE mechanism and will add a paragraph clarifying the vLLM integration points that keep weights, KV cache, and I/O inside the enclave. These additions will be included in the revision. revision: yes
Circularity Check
No circularity: claims rest on new design, implementation, and evaluation
full rationale
The paper describes analysis of CIS requirements, followed by presentation of OpenPCC using commodity TEEs, an open-source prototype, and end-to-end characterization on Llama-3 8B vLLM (separating OpenPCC overhead from TEE cost). No equations, fitted parameters, predictions, or self-citations appear as load-bearing elements in the abstract or described structure. The central claims derive from the implemented system and measurements rather than reducing to inputs by construction. This is a standard systems paper with independent empirical content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AMD Memory Encryption.https://docs.amd.com/api/khub/ documents/ZcsCCmeL80dbtuf_VlGpvw/content
AMD. AMD Memory Encryption.https://docs.amd.com/api/khub/ documents/ZcsCCmeL80dbtuf_VlGpvw/content
-
[2]
Make your llm fully utilize the context
Shengnan An, Zexiong Ma, Zeqi Lin, Nanning Zheng, Jian-Guang Lou, and Weizhu Chen. Make your llm fully utilize the context. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tom- czak, and C. Zhang, editors,Advances in Neural Information Process- ing Systems, volume 37, pages 62160–62188. Curran Associates, Inc.,
-
[3]
URL:https://proceedings.neurips.cc/paper_files/paper/2024/ file/71c3451f6cd6a4f82bb822db25cea4fd-Paper-Conference.pdf, doi: 10.52202/079017-1986
-
[4]
Privacy-preserving llm infer- ence in practice: A comparative survey of techniques, trade-offs, and deployability, 2026
Davide Andreoletti, Alessandro Rudi, Emanuele Carpanzano, Francesco Lelli, and Tiziano Leidi. Privacy-preserving llm infer- ence in practice: A comparative survey of techniques, trade-offs, and deployability, 2026. URL:https://api.semanticscholar.org/CorpusID: 285144126
2026
-
[5]
Confidential Inference Systems.https://assets.anthropic
Anthropic. Confidential Inference Systems.https://assets.anthropic. com/m/c52125297b85a42/original/Confidential_Inference_Paper. pdf, 2025
2025
-
[6]
iCloud Private Relay Overview.https://www.apple.com/ privacy/docs/iCloud_Private_Relay_Overview_Dec2021.PDF, 2021
Apple. iCloud Private Relay Overview.https://www.apple.com/ privacy/docs/iCloud_Private_Relay_Overview_Dec2021.PDF, 2021
2021
-
[7]
Longbench: A bilingual, multitask benchmark for long context understanding, 2024
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Longbench: A bilingual, multitask benchmark for long context understanding, 2024. URL:https://arxiv.org/abs/2308. 14508,arXiv:2308.14508
Pith/arXiv arXiv 2024
-
[8]
CPA Canada. WEBTRUST FOR CERTIFICATION AUTHORITIES PRINCIPLES AND CRITERIA.https://www.cpacanada.ca/business- and-accounting-resources/audit-and-assurance/overview-of- webtrust-services/principles-and-criteria, 2023
2023
-
[9]
Sprint: Scalable secure & differentially private inference for transformers
Francesco Capano, Jonas Böhler, and Benjamin Weggenmann. Sprint: Scalable secure & differentially private inference for transformers. Proceedings on Privacy Enhancing Technologies, 2026
2026
-
[10]
Dissecting cpu-gpu unified physical memory on amd mi300a apus,
Marcin Chrapek, Marcin Copik, Etienne Mettaz, and Torsten Hoefler. Confidential llm inference: Performance and cost across cpu and gpu tees, 2025.doi:10.1109/IISWC66894.2025.00017
-
[11]
Christian Schroeder de Witt, Klaudia Krawiecka, Igor Krawczuk, Ben Hagag, William L Anderson, Peter Belcak, Ben Bucknall, Xiaohong Cai, Ayush Chopra, Doron Cohen, et al. Open challenges in multi- agent security: Towards secure systems of interacting ai agents.arXiv preprint arXiv:2505.02077, 2025
Pith/arXiv arXiv 2025
-
[12]
DeepSeek-V3.https://huggingface.co/deepseek-ai/ DeepSeek-V3
Deepseek. DeepSeek-V3.https://huggingface.co/deepseek-ai/ DeepSeek-V3
-
[13]
Ai agents under threat: A survey of key security challenges and future pathways.ACM Computing Surveys, 57(7):1–36, 2025
Zehang Deng, Yongjian Guo, Changzhou Han, Wanlun Ma, Junwu Xiong, Sheng Wen, and Yang Xiang. Ai agents under threat: A survey of key security challenges and future pathways.ACM Computing Surveys, 57(7):1–36, 2025
2025
-
[14]
Google Private AI Compute.https://services.google.com/fh/ files/misc/private_ai_compute_technical_brief.pdf, 2025
Google. Google Private AI Compute.https://services.google.com/fh/ files/misc/private_ai_compute_technical_brief.pdf, 2025
2025
-
[15]
Le, Hani Jamjoom, Shixuan Zhao, and Zhiqiang Lin
Zhongshu Gu, Enriquillo Valdez, Salman Ahmed, Julian James Stephen, Michael V. Le, Hani Jamjoom, Shixuan Zhao, and Zhiqiang Lin. Blue- print, bootstrap, and bridge: A security look at nvidia gpu confiden- tial computing, 2025. URL:https://api.semanticscholar.org/CorpusID: 280150420
2025
-
[16]
Security of ai agents
Yifeng He, Ethan Wang, Yuyang Rong, Zifei Cheng, and Hao Chen. Security of ai agents. In2025 IEEE/ACM International Workshop on Responsible AI Engineering (RAIE), pages 45–52. IEEE, 2025
2025
-
[17]
Shokri, Vitaly Shmatikov, and Emmett Witchel
Tyler Hunt, Congzheng Song, R. Shokri, Vitaly Shmatikov, and Emmett Witchel. Chiron: Privacy-preserving machine learning as a service,
-
[18]
URL:https://api.semanticscholar.org/CorpusID:3970945
-
[19]
Intel Trust Domain Execution.https://www.intel.com/content/ www/us/en/products/docs/accelerator-engines/trust-domain- extensions.html
Intel. Intel Trust Domain Execution.https://www.intel.com/content/ www/us/en/products/docs/accelerator-engines/trust-domain- extensions.html
-
[20]
Intel Trust Authority Client for Python.https://github
Intel. Intel Trust Authority Client for Python.https://github. com/intel/trustauthority-client-for-python, 2025. Includes the trustauthority-pycli CLI for the TDX + NVIDIA H100 composite attestation profile
2025
-
[21]
GPU remote attestation with Intel Trust Authority.https: //docs.trustauthority.intel.com/main/articles/articles/ita/concept- gpu-attestation.html, 2026
Intel. GPU remote attestation with Intel Trust Authority.https: //docs.trustauthority.intel.com/main/articles/articles/ita/concept- gpu-attestation.html, 2026
2026
-
[22]
Je Chiao Ku and Shang Liang Chen. The deployment and implemen- tation of cloud platform for remote automatic correction of artifi- cial intelligence models.IEEE Transactions on Industrial Informatics, 21(4):3466–3474, 2025.doi:10.1109/TII.2025.3528563
-
[23]
Gonzalez, Hao Zhang, and Ion Sto- ica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Sto- ica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP), 2023
2023
-
[24]
Cipherleaks: Breaking constant-time cryptography on amd sev via the ciphertext side channel, 2021
Mengyuan Li, Yinqian Zhang, Huibo Wang, Kang Li, and Yueqiang Cheng. Cipherleaks: Breaking constant-time cryptography on amd sev via the ciphertext side channel, 2021. URL:https://api.semanticscholar. org/CorpusID:237522096
2021
-
[25]
Zhifan Luo, Shuo Shao, Su Zhang, Lijing Zhou, Yuke Hu, Chenxu Zhao, Zhihao Liu, and Zhan Qin. Shadow in the cache: Unveiling and mitigating privacy risks of kv-cache in llm inference. 08 2025. doi:10.48550/arXiv.2508.09442
-
[26]
Meta-Llama-3-70B.https://huggingface.co/meta-llama/Meta- Llama-3-70B
Meta. Meta-Llama-3-70B.https://huggingface.co/meta-llama/Meta- Llama-3-70B
-
[27]
Meta-Llama-3-8B.https://huggingface.co/meta-llama/Meta- Llama-3-8B
Meta. Meta-Llama-3-8B.https://huggingface.co/meta-llama/Meta- Llama-3-8B
-
[28]
Mistral-Large-Instruct-2407.https://huggingface.co/mistralai/ Mistral-Large-Instruct-2407
Mistral. Mistral-Large-Instruct-2407.https://huggingface.co/mistralai/ Mistral-Large-Instruct-2407
-
[29]
Thor: Secure transformer inference with homomorphic encryption
Jungho Moon, Dongwoo Yoo, Xiaoqian Jiang, and Miran Kim. Thor: Secure transformer inference with homomorphic encryption. InPro- ceedings of the 2025 ACM SIGSAC Conference on Computer and Com- munications Security, CCS ’25, page 3765–3779, New York, NY, USA,
2025
-
[30]
Association for Computing Machinery. doi:10.1145/3719027. 3765150
-
[31]
Deployment Guide for Confidential Computing.https: //docs.nvidia.com/cc-deployment-guide-tdx.pdf
NVIDIA. Deployment Guide for Confidential Computing.https: //docs.nvidia.com/cc-deployment-guide-tdx.pdf
-
[32]
Hopper Multi-GPU (PPCIE) Attestation Ex- ample.https://docs.nvidia.com/attestation/quick-start- guide/latest/attestation-examples/hopper_ppcie.html
NVIDIA. Hopper Multi-GPU (PPCIE) Attestation Ex- ample.https://docs.nvidia.com/attestation/quick-start- guide/latest/attestation-examples/hopper_ppcie.html
-
[33]
NVIDIA Confidential Computing.https://www.nvidia.com/ en-us/data-center/solutions/confidential-computing/
NVIDIA. NVIDIA Confidential Computing.https://www.nvidia.com/ en-us/data-center/solutions/confidential-computing/
-
[34]
SPDM.https://docs.nvidia.com/networking/display/ nvidianvosusermanualfornvlinkswitchesv25022141/spdm
NVIDIA. SPDM.https://docs.nvidia.com/networking/display/ nvidianvosusermanualfornvlinkswitchesv25022141/spdm
-
[35]
Attestation using NRAS.https://docs.nvidia.com/attestation/ poc-to-production/latest/integration-options/remote_verifier.html, 2026
NVIDIA. Attestation using NRAS.https://docs.nvidia.com/attestation/ poc-to-production/latest/integration-options/remote_verifier.html, 2026
2026
-
[36]
AMD SEV-SNP Attestation: Establishing Trust in Guests.https://www.amd.com/content/dam/amd/en/documents/ developer/lss-snp-attestation.pdf, 2022
Jeremy Powell. AMD SEV-SNP Attestation: Establishing Trust in Guests.https://www.amd.com/content/dam/amd/en/documents/ developer/lss-snp-attestation.pdf, 2022
2022
-
[37]
A multi-llm orchestration engine for personalized, context-rich assistance, 2024
Sumedh Rasal. A multi-llm orchestration engine for personalized, context-rich assistance, 2024. URL:https://arxiv.org/abs/2410.10039, arXiv:2410.10039
arXiv 2024
-
[38]
PCC Hardware Design.https: //security.apple.com/documentation/private-cloud-compute/ hardwareintegrity#Hardware-design, 2024
Apple Security Research. PCC Hardware Design.https: //security.apple.com/documentation/private-cloud-compute/ hardwareintegrity#Hardware-design, 2024
2024
-
[39]
Private Cloud Compute: A new frontier for AI privacy in the cloud - Apple Security Research.https://security
Apple Security Research. Private Cloud Compute: A new frontier for AI privacy in the cloud - Apple Security Research.https://security. apple.com/blog/private-cloud-compute/, 2024
2024
-
[40]
Machine learning orchestration in cloud environments: Automating the training and deployment of 13 Zhou et al
I Sakthidevi, G Vinoth Rajkumar, R Sunitha, A Sangeetha, R San- thana Krishnan, and S Sundararajan. Machine learning orchestration in cloud environments: Automating the training and deployment of 13 Zhou et al. distributed machine learning ai model. In2023 7th International Con- ference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud)(I-SMAC), pages...
2023
-
[41]
Nikolaos-Achilleas Steiakakis and Giorgos Vasiliadis. Trusted yet flexible: High-level runtimes for secure ml inference in tees.Journal of Cybersecurity and Privacy, 6(1), 2026. URL:https://www.mdpi.com/ 2624-800X/6/1/23,doi:10.3390/jcp6010023
-
[42]
Martin Thomson and Christopher A. Wood. RFC 9458: Oblivious HTTP.https://www.rfc-editor.org/rfc/rfc9458.html
-
[43]
Jean-Baptiste Truong, William Gallagher, Tian Guo, and Robert J. Walls. Memory-efficient deep learning inference in trusted execution environments, 2021.doi:10.1109/IC2E52221.2021.00031
-
[44]
vLLM.https://pypi.org/project/vllm/
vllm.ai. vLLM.https://pypi.org/project/vllm/
-
[45]
I know what you asked: Prompt leakage via kv-cache sharing in multi-tenant LLM serving, 2025
Guanlong Wu, Zheng Zhang, Yao Zhang, Weili Wang, Jianyu Niu, Ye Wu, and Yinqian Zhang. I know what you asked: Prompt leakage via kv-cache sharing in multi-tenant LLM serving, 2025. URL: https://www.ndss-symposium.org/ndss-paper/i-know-what-you- asked-prompt-leakage-via-kv-cache-sharing-in-multi-tenant-llm- serving/
2025
-
[46]
I know what you asked: Prompt leakage via kv-cache sharing in multi-tenant llm serving.Proceedings 2025 Network and Distributed System Security Symposium, 2025
Guanlong Wu, Zheng Zhang, Yao Zhang, Weili Wang, Jianyu Niu, Ye Wu, and Yinqian Zhang. I know what you asked: Prompt leakage via kv-cache sharing in multi-tenant llm serving.Proceedings 2025 Network and Distributed System Security Symposium, 2025. URL:https: //api.semanticscholar.org/CorpusID:276842968
2025
-
[47]
Gpu travelling: Efficient confidential collaborative training with tee-enabled gpus, 2025
Shixuan Zhao, Zhongshu Gu, Salman Ahmed, Enriquillo Valdez, Hani Jamjoom, and Zhiqiang Lin. Gpu travelling: Efficient confidential collaborative training with tee-enabled gpus, 2025. doi:10.1145/ 3719027.3765029
arXiv 2025
-
[48]
Too private to tell: Practical token theft attacks on apple intelligence, 2026
Haoling Zhou, Shixuan Zhao, Chao Wang, and Zhiqiang Lin. Too private to tell: Practical token theft attacks on apple intelligence, 2026. URL:https://arxiv.org/abs/2604.15637,arXiv:2604.15637
Pith/arXiv arXiv 2026
-
[49]
Confidential Computing on NVIDIA Hopper GPUs: A Per- formance Benchmark Study, September 2024
Jianwei Zhu, Hang Yin, Peng Deng, Aline Almeida, and Shunfan Zhou. Confidential Computing on NVIDIA Hopper GPUs: A Per- formance Benchmark Study, September 2024. arXiv:2409.03992, doi:10.48550/arXiv.2409.03992. 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.