MOFA-VTON: More Fashion Possibilities with Fine-Grained Adaptations in Virtual Try-On
Pith reviewed 2026-06-27 13:49 UTC · model grok-4.3
The pith
User-drawn sketches let virtual try-on adjust clothing layout in fine detail instead of fixed replacement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
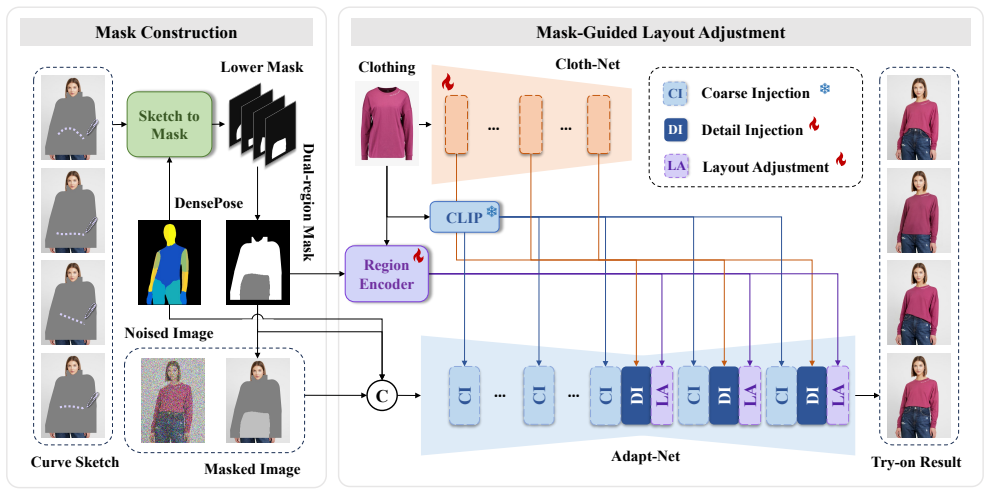
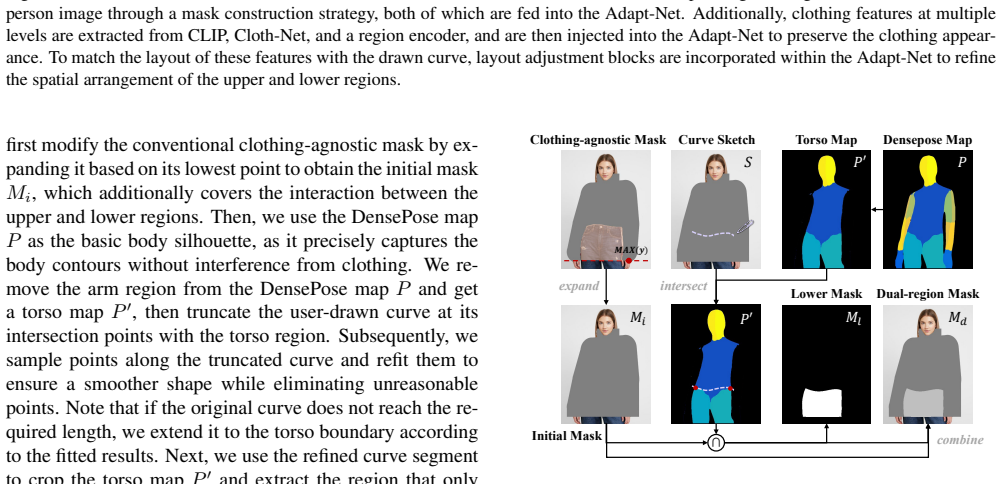
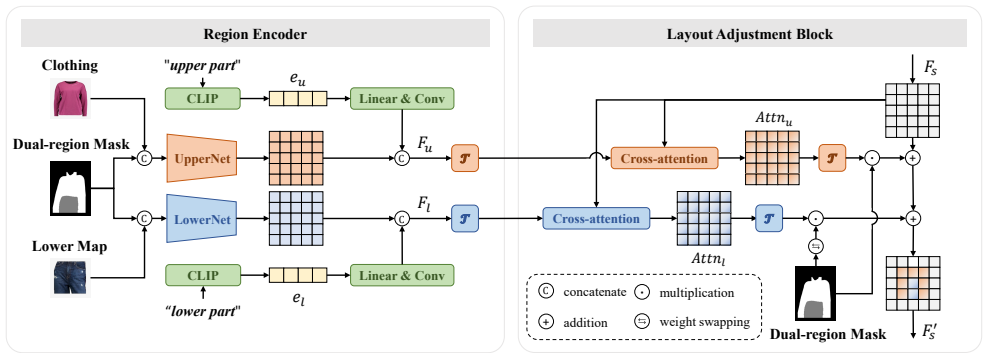
The central claim is that replacing the standard clothing-agnostic mask with a dual-region mask built from user curve sketches, together with layout adjustment blocks that independently model upper and lower body correspondences via cross-attention, removes the fixed-layout constraint and produces flexible, fine-grained clothing adaptations in the generated try-on images.
What carries the argument
Dual-region mask derived from user curve sketches plus layout adjustment blocks that apply cross-attention separately to upper and lower body regions.
If this is right
- Target clothing can be adapted to multiple wearing styles from a single in-shop image.
- Upper and lower body regions can be adjusted independently to match user preferences.
- Try-on results better reflect varied real-world dressing patterns.
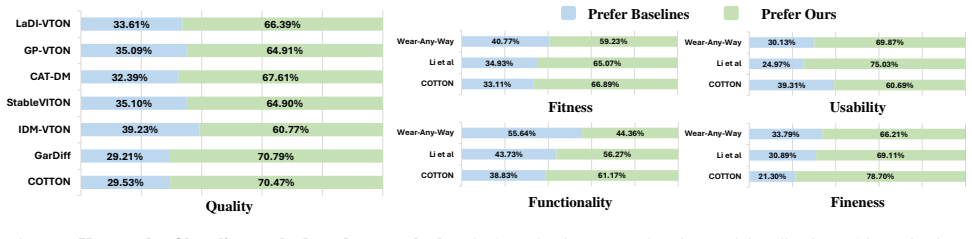
- Performance improves over prior methods on the VITON-HD and DressCode benchmarks.
Where Pith is reading between the lines
- The sketch-to-mask step could be combined with real-time drawing interfaces to support live fashion experimentation.
- Separate region handling may extend naturally to editing layered outfits or complex poses in other image tasks.
- One clothing image could generate a wider range of catalog variants without additional photography.
Load-bearing premise
User-drawn curve sketches can be turned into a dual-region mask that gives accurate fine-grained layout guidance without introducing artifacts or requiring extra corrections.
What would settle it
Generated images that contain visible boundary artifacts or mismatched clothing placement when the input sketches deviate from standard clothing edges on the VITON-HD test set.
Figures









read the original abstract
Virtual try-on aims to fit an in-shop clothing image onto a specific human body. An optimal virtual try-on method should provide diverse and flexible dressing options, accurately reflecting the varied wearing styles encountered in real-life scenarios, tailored to individual preferences and fashion aspirations. However, current methods predominantly perform a direct replacement of the original clothing with the target clothing, following the same dressing pattern. This limited control over clothing adaptation may result in fixed and monotonous try-on outputs. To delve into More Fashion Possibilities with Fine-Grained Adaptations in Virtual Try-On, we propose a novel virtual try-on method, termed MOFA-VTON, which allows adjustment for clothing adaptations in try-on results through simple sketches by users. Specifically, we first design a mask construction strategy that transforms user-drawn curve sketches into a dual-region mask, replacing the traditional clothing-agnostic mask and providing fine-grained layout guidance for the subsequent generation process. Further, we propose layout adjustment blocks that utilize the cross-attention mechanism to independently learn layout correspondences for upper and lower regions of the human body, refining the spatial arrangement of the two regions. With these implementations, our method enables flexible and fine-grained adaptations of target clothing, overcoming the constraints of a fixed layout. Extensive experiments on VITON-HD and DressCode datasets demonstrate that our proposed MOFA-VTON outperforms previous state-of-the-art methods and provides more fashion possibilities for virtual try-on.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MOFA-VTON, a virtual try-on framework that enables fine-grained clothing adaptations via user-drawn curve sketches. It introduces a mask construction strategy that converts sketches into a dual-region mask (replacing the clothing-agnostic mask) to supply layout guidance, along with layout adjustment blocks that apply cross-attention independently to upper and lower body regions. The method is evaluated on VITON-HD and DressCode, with the abstract claiming outperformance over prior SOTA and greater fashion flexibility.
Significance. If the core components function as described, the work could meaningfully extend virtual try-on beyond rigid replacement to support user-specified wearing styles. The dual-region cross-attention design is a plausible way to decouple layout learning, but the overall significance hinges on whether the sketch-to-mask step reliably produces artifact-free guidance; without that, the flexibility claim does not hold.
major comments (3)
- [mask construction strategy] Mask construction strategy description: the central claim that user sketches yield accurate fine-grained layout guidance rests on the unvalidated assumption that curve-to-dual-region-mask conversion produces reliable boundaries without overlaps or artifacts for typical sketch variations. No quantitative fidelity metrics (e.g., boundary error, region IoU, or robustness tests) are supplied for this transformation, which directly feeds the layout adjustment blocks and replaces the standard mask.
- [abstract / experiments] Abstract and experiments overview: the assertion that MOFA-VTON 'outperforms previous state-of-the-art methods' on VITON-HD and DressCode is stated without any reported metrics, baseline comparisons, or ablation results in the provided text. This prevents verification of whether the mask construction and cross-attention blocks are responsible for any gains.
- [layout adjustment blocks] Layout adjustment blocks: while cross-attention on upper/lower regions is proposed to refine spatial arrangement, the manuscript does not detail how the dual-region mask is encoded or injected into the attention mechanism, nor does it show that this separation actually overcomes fixed-layout constraints when mask quality varies.
minor comments (1)
- [abstract] The abstract refers to 'simple sketches by users' without clarifying the expected sketch complexity or interface, which could affect reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below with clarifications from the manuscript and indicate planned revisions where appropriate to strengthen the presentation of MOFA-VTON.
read point-by-point responses
-
Referee: [mask construction strategy] Mask construction strategy description: the central claim that user sketches yield accurate fine-grained layout guidance rests on the unvalidated assumption that curve-to-dual-region-mask conversion produces reliable boundaries without overlaps or artifacts for typical sketch variations. No quantitative fidelity metrics (e.g., boundary error, region IoU, or robustness tests) are supplied for this transformation, which directly feeds the layout adjustment blocks and replaces the standard mask.
Authors: We agree that quantitative validation of the sketch-to-dual-region-mask conversion would provide stronger support for the reliability claim. The current manuscript demonstrates the strategy through qualitative examples and end-to-end results, but we will add a dedicated evaluation subsection with metrics such as boundary error, region IoU, and robustness tests across varied sketch inputs in the revised version. revision: yes
-
Referee: [abstract / experiments] Abstract and experiments overview: the assertion that MOFA-VTON 'outperforms previous state-of-the-art methods' on VITON-HD and DressCode is stated without any reported metrics, baseline comparisons, or ablation results in the provided text. This prevents verification of whether the mask construction and cross-attention blocks are responsible for any gains.
Authors: The abstract is a concise summary; the full manuscript (Section 4) reports quantitative results including FID, LPIPS, SSIM, and user studies on both VITON-HD and DressCode, with direct comparisons to prior SOTA methods and ablations isolating the mask and layout blocks. We will revise the abstract to include a brief pointer to these specific experimental outcomes for clarity. revision: partial
-
Referee: [layout adjustment blocks] Layout adjustment blocks: while cross-attention on upper/lower regions is proposed to refine spatial arrangement, the manuscript does not detail how the dual-region mask is encoded or injected into the attention mechanism, nor does it show that this separation actually overcomes fixed-layout constraints when mask quality varies.
Authors: Section 3.2 details the encoding of the dual-region mask through separate convolutional embeddings for upper and lower regions, followed by independent cross-attention injection into the respective branches of the generator. To further address robustness, we will add experiments in the revision that vary mask quality and measure the resulting layout flexibility gains. revision: yes
Circularity Check
No significant circularity; method is an engineering construction
full rationale
The paper describes a new virtual try-on architecture built from a mask construction strategy (transforming user sketches into dual-region masks) and layout adjustment blocks (cross-attention on upper/lower regions). No equations, fitted parameters, or derivation steps are presented that reduce by construction to prior outputs or self-citations. The central claims rest on the novelty of these components plus empirical results on VITON-HD and DressCode, which are external benchmarks. This satisfies the default expectation of a non-circular engineering paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multimodal garment designer: Human-centric latent diffusion models for fashion image editing
Alberto Baldrati, Davide Morelli, Giuseppe Cartella, Mar- cella Cornia, Marco Bertini, and Rita Cucchiara. Multimodal garment designer: Human-centric latent diffusion models for fashion image editing. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 23393–23402, 2023. 2
2023
-
[2]
Demystifying mmd gans
Mikołaj Bi´nkowski, Danica J Sutherland, Michael Arbel, and Arthur Gretton. Demystifying mmd gans. InProceedings of the International Conference on Learning Representations (ICLR), pages 1–36, 2018. 7
2018
-
[3]
Bookstein
Fred L. Bookstein. Principal warps: Thin-plate splines and the decomposition of deformations.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 11(6): 567–585, 1989. 2
1989
-
[4]
Fashionmirror: Co-attention feature-remapping virtual try-on with sequential template poses
Chieh-Yun Chen, Ling Lo, Pin-Jui Huang, Hong-Han Shuai, and Wen-Huang Cheng. Fashionmirror: Co-attention feature-remapping virtual try-on with sequential template poses. InProceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV), pages 13809–13818,
-
[5]
Size does matter: Size-aware virtual try-on via clothing-oriented transformation try-on network
Chieh-Yun Chen, Yi-Chung Chen, Hong-Han Shuai, and Wen-Huang Cheng. Size does matter: Size-aware virtual try-on via clothing-oriented transformation try-on network. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 7513–7522, 2023. 3, 7, 12
2023
-
[6]
Wear-any-way: Manip- ulable virtual try-on via sparse correspondence alignment
Mengting Chen, Xi Chen, Zhonghua Zhai, Chen Ju, Xuewen Hong, Jinsong Lan, and Shuai Xiao. Wear-any-way: Manip- ulable virtual try-on via sparse correspondence alignment. In Proceedings of the European Conference on Computer Vi- sion (ECCV), pages 124–142, 2024. 3
2024
-
[7]
Viton-hd: High-resolution virtual try-on via misalignment-aware normalization
Seunghwan Choi, Sunghyun Park, Minsoo Lee, and Jaegul Choo. Viton-hd: High-resolution virtual try-on via misalignment-aware normalization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14131–14140, 2021. 2, 6
2021
-
[8]
Improving diffusion models for au- thentic virtual try-on in the wild
Yisol Choi, Sangkyung Kwak, Kyungmin Lee, Hyungwon Choi, and Jinwoo Shin. Improving diffusion models for au- thentic virtual try-on in the wild. InProceedings of the Eu- ropean Conference on Computer Vision (ECCV), pages 206– 235, 2024. 3, 7
2024
-
[9]
Zflow: Gated appearance flow-based virtual try-on with 3d priors
Ayush Chopra, Rishabh Jain, Mayur Hemani, and Balaji Kr- ishnamurthy. Zflow: Gated appearance flow-based virtual try-on with 3d priors. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 5433–5442, 2021. 2
2021
-
[10]
Viton-gt: An image-based virtual try-on model with geometric transformations
Matteo Fincato, Federico Landi, Marcella Cornia, Fabio Ce- sari, and Rita Cucchiara. Viton-gt: An image-based virtual try-on model with geometric transformations. InProceed- ings of the International Conference on Pattern Recognition (ICPR), pages 7669–7676, 2021. 2
2021
-
[11]
Shape controllable virtual try-on for underwear models
Xin Gao, Zhenjiang Liu, Zunlei Feng, Chengji Shen, Kairi Ou, Haihong Tang, and Mingli Song. Shape controllable virtual try-on for underwear models. InProceedings of the ACM International Conference on Multimedia (ACM MM), pages 563–572, 2021. 2
2021
-
[12]
Parser-free virtual try-on via distilling ap- pearance flows
Yuying Ge, Yibing Song, Ruimao Zhang, Chongjian Ge, Wei Liu, and Ping Luo. Parser-free virtual try-on via distilling ap- pearance flows. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8485–8493, 2021. 2
2021
-
[13]
Instance-level human parsing via part grouping network
Ke Gong, Xiaodan Liang, Yicheng Li, Yimin Chen, Ming Yang, and Liang Lin. Instance-level human parsing via part grouping network. InProceedings of the European Confer- ence on Computer Vision (ECCV), pages 770–785, 2018. 5
2018
-
[14]
Generative adversarial networks.Commu- nications of the ACM (CACM), 63(11):139–144, 2020
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks.Commu- nications of the ACM (CACM), 63(11):139–144, 2020. 2
2020
-
[15]
Taming the power of diffusion models for high-quality virtual try-on with appearance flow
Junhong Gou, Siyu Sun, Jianfu Zhang, Jianlou Si, Chen Qian, and Liqing Zhang. Taming the power of diffusion models for high-quality virtual try-on with appearance flow. InProceedings of the ACM International Conference on Multimedia (ACM MM), pages 7599–7607, 2023. 7
2023
-
[16]
Densepose: Dense human pose estimation in the wild
Riza Alp G ¨uler, Natalia Neverova, and Iasonas Kokkinos. Densepose: Dense human pose estimation in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 7297–7306,
-
[17]
Viton: An image-based virtual try-on network
Xintong Han, Zuxuan Wu, Zhe Wu, Ruichi Yu, and Larry S Davis. Viton: An image-based virtual try-on network. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 7543–7552,
-
[18]
Clothflow: A flow-based model for clothed per- son generation
Xintong Han, Xiaojun Hu, Weilin Huang, and Matthew R Scott. Clothflow: A flow-based model for clothed per- son generation. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision (ICCV), pages 10471–10480, 2019. 2
2019
-
[19]
Progressive limb-aware virtual try-on
Xiaoyu Han, Shengping Zhang, Qinglin Liu, Zonglin Li, and Chenyang Wang. Progressive limb-aware virtual try-on. In Proceedings of the ACM International Conference on Multi- media (ACM MM), pages 2420–2429, 2022. 2
2022
-
[20]
Shape-guided clothing warp- ing for virtual try-on
Xiaoyu Han, Shunyuan Zheng, Zonglin Li, Chenyang Wang, Xin Sun, and Quanling Meng. Shape-guided clothing warp- ing for virtual try-on. InProceedings of the ACM Interna- tional Conference on Multimedia (ACM MM), pages 2593– 2602, 2024. 2
2024
-
[21]
Gans trained by a two time-scale update rule converge to a local nash equilib- rium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium. InProceedings of the Advances in Neural Information Processing Systems (NeurIPS), pages 6626–6637, 2017. 7
2017
-
[22]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. InProceedings of the Advances in Neural Information Processing Systems (NeurIPS), pages 6840–6851, 2020. 2, 3
2020
-
[23]
Ita-mdt: Image-timestep- adaptive masked diffusion transformer framework for image- based virtual try-on
Ji Woo Hong, Tri Ton, Trung X Pham, Gwanhyeong Koo, Sunjae Yoon, and Chang D Yoo. Ita-mdt: Image-timestep- adaptive masked diffusion transformer framework for image- based virtual try-on. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 28284–28294, 2025. 3 9
2025
-
[24]
Up-vton: A unified virtual try-on framework supporting mask, mask- free, and prompt-driven guidance
Youngjoo Jo, Minho Park, and Dong-oh Kang. Up-vton: A unified virtual try-on framework supporting mask, mask- free, and prompt-driven guidance. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6971–6979, 2025. 3
2025
-
[25]
Stableviton: Learning semantic correspon- dence with latent diffusion model for virtual try-on
Jeongho Kim, Gyojung Gu, Minho Park, Sunghyun Park, and Jaegul Choo. Stableviton: Learning semantic correspon- dence with latent diffusion model for virtual try-on. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8176–8185, 2024. 2, 3, 7
2024
-
[26]
Promptdresser: Improving the quality and control- lability of virtual try-on via generative textual prompt and prompt-aware mask
Jeongho Kim, Hoiyeong Jin, Sunghyun Park, and Jaegul Choo. Promptdresser: Improving the quality and control- lability of virtual try-on via generative textual prompt and prompt-aware mask. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 16026–16036, 2025. 3
2025
-
[27]
High-resolution virtual try-on with misalignment and occlusion-handled conditions
Sangyun Lee, Gyojung Gu, Sunghyun Park, Seunghwan Choi, and Jaegul Choo. High-resolution virtual try-on with misalignment and occlusion-handled conditions. InPro- ceedings of the European Conference on Computer Vision (ECCV), pages 204–219, 2022. 2, 7
2022
-
[28]
Controlling virtual try-on pipeline through render- ing policies
Kedan Li, Jeffrey Zhang, Shao-Yu Chang, and David Forsyth. Controlling virtual try-on pipeline through render- ing policies. InProceedings of the IEEE/CVF Winter Con- ference on Applications of Computer Vision (WACV), pages 5866–5875, 2024. 3
2024
-
[29]
Anyfit: Controllable virtual try-on for any combination of attire across any scenario
Yuhan Li, Hao Zhou, Wenxiang Shang, Ran Lin, Xuanhong Chen, and Bingbing Ni. Anyfit: Controllable virtual try-on for any combination of attire across any scenario. InPro- ceedings of the Advances in Neural Information Processing Systems (NeurIPS), pages 83164–83196, 2024. 3
2024
-
[30]
Virtual try-on with pose-garment keypoints guided inpaint- ing
Zhi Li, Pengfei Wei, Xiang Yin, Zejun Ma, and Alex C Kot. Virtual try-on with pose-garment keypoints guided inpaint- ing. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision (ICCV), pages 22788–22797, 2023. 2
2023
-
[31]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InProceedings of the International Confer- ence on Learning Representations (ICLR), pages 1–19, 2019. 12
2019
-
[32]
Cp-vton+: Clothing shape and tex- ture preserving image-based virtual try-on
Matiur Rahman Minar, Thai Thanh Tuan, Heejune Ahn, Paul Rosin, and Yu-Kun Lai. Cp-vton+: Clothing shape and tex- ture preserving image-based virtual try-on. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition Workshops (CVPRW), pages 10–14, 2020. 2
2020
-
[33]
Dress code: High- resolution multi-category virtual try-on
Davide Morelli, Matteo Fincato, Marcella Cornia, Federico Landi, Fabio Cesari, and Rita Cucchiara. Dress code: High- resolution multi-category virtual try-on. InProceedings of the European Conference on Computer Vision (ECCV), pages 345–362, 2022. 6
2022
-
[34]
Ladi-vton: latent diffusion textual-inversion enhanced virtual try-on
Davide Morelli, Alberto Baldrati, Giuseppe Cartella, Mar- cella Cornia, Marco Bertini, and Rita Cucchiara. Ladi-vton: latent diffusion textual-inversion enhanced virtual try-on. In Proceedings of the ACM International Conference on Multi- media (ACM MM), pages 8580–8589, 2023. 7
2023
-
[35]
Image based virtual try-on network from unpaired data
Assaf Neuberger, Eran Borenstein, Bar Hilleli, Eduard Oks, and Sharon Alpert. Image based virtual try-on network from unpaired data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5184–5193, 2020. 2
2020
-
[36]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InProceedings of the International Conference on Machine Learning (ICML), pages 8748–8763, 2021. 2, 12
2021
-
[37]
Cloth interactive transformer for virtual try-on.ACM Transactions on Multimedia Computing, Com- munications, and Applications (TOMM), 20(4):1–20, 2023
Bin Ren, Hao Tang, Fanyang Meng, Ding Runwei, Philip HS Torr, and Nicu Sebe. Cloth interactive transformer for virtual try-on.ACM Transactions on Multimedia Computing, Com- munications, and Applications (TOMM), 20(4):1–20, 2023. 2
2023
-
[38]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022. 2, 3
2022
-
[39]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InProceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), pages 234–241,
-
[40]
Towards squeezing-averse virtual try-on via sequential deformation
Sang-Heon Shim, Jiwoo Chung, and Jae-Pil Heo. Towards squeezing-averse virtual try-on via sequential deformation. InProceedings of the AAAI Conference on Artificial Intelli- gence (AAAI), pages 4856–4863, 2024. 7
2024
-
[41]
Improving virtual try-on with garment-focused diffusion models
Siqi Wan, Yehao Li, Jingwen Chen, Yingwei Pan, Ting Yao, Yang Cao, and Tao Mei. Improving virtual try-on with garment-focused diffusion models. InProceedings of the Eu- ropean Conference on Computer Vision (ECCV), pages 184– 199, 2024. 7
2024
-
[42]
Toward characteristic- preserving image-based virtual try-on network
Bochao Wang, Huabin Zheng, Xiaodan Liang, Yimin Chen, Liang Lin, and Meng Yang. Toward characteristic- preserving image-based virtual try-on network. InPro- ceedings of the European Conference on Computer Vision (ECCV), pages 589–604, 2018. 2
2018
-
[43]
Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Process- ing (TIP), 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Process- ing (TIP), 13(4):600–612, 2004. 7
2004
-
[44]
Gp- vton: Towards general purpose virtual try-on via collabora- tive local-flow global-parsing learning
Zhenyu Xie, Zaiyu Huang, Xin Dong, Fuwei Zhao, Haoye Dong, Xijin Zhang, Feida Zhu, and Xiaodan Liang. Gp- vton: Towards general purpose virtual try-on via collabora- tive local-flow global-parsing learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 23550–23559, 2023. 7
2023
-
[45]
Linking garment with person via semantically associated landmarks for virtual try-on
Keyu Yan, Tingwei Gao, Hui Zhang, and Chengjun Xie. Linking garment with person via semantically associated landmarks for virtual try-on. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17194–17204, 2023. 2
2023
-
[46]
Paint by 10 example: Exemplar-based image editing with diffusion mod- els
Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, and Fang Wen. Paint by 10 example: Exemplar-based image editing with diffusion mod- els. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 18381– 18391, 2023. 12
2023
-
[47]
Towards photo-realistic virtual try-on by adaptively generating-preserving image content
Han Yang, Ruimao Zhang, Xiaobao Guo, Wei Liu, Wang- meng Zuo, and Ping Luo. Towards photo-realistic virtual try-on by adaptively generating-preserving image content. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7850–7859,
-
[48]
Texture-preserving diffusion models for high-fidelity virtual try-on
Xu Yang, Changxing Ding, Zhibin Hong, Junhao Huang, Jin Tao, and Xiangmin Xu. Texture-preserving diffusion models for high-fidelity virtual try-on. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7017–7026, 2024. 7
2024
-
[49]
D 4-vton: Dynamic semantics disentangling for differential diffusion based virtual try-on
Zhaotong Yang, Zicheng Jiang, Xinzhe Li, Huiyu Zhou, Junyu Dong, Huaidong Zhang, and Yong Du. D 4-vton: Dynamic semantics disentangling for differential diffusion based virtual try-on. InProceedings of the European Con- ference on Computer Vision (ECCV), pages 36–52, 2024. 3
2024
-
[50]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip- adapter: Text compatible image prompt adapter for text-to- image diffusion models.arXiv preprint arXiv:2308.06721,
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Vtnfp: An image-based virtual try-on network with body and clothing feature preservation
Ruiyun Yu, Xiaoqi Wang, and Xiaohui Xie. Vtnfp: An image-based virtual try-on network with body and clothing feature preservation. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 10511–10520, 2019. 2
2019
-
[52]
Cat-dm: Controllable acceler- ated virtual try-on with diffusion model
Jianhao Zeng, Dan Song, Weizhi Nie, Hongshuo Tian, Tong- tong Wang, and An-An Liu. Cat-dm: Controllable acceler- ated virtual try-on with diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8372–8382, 2024. 3, 7
2024
-
[53]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3836–3847, 2023. 5
2023
-
[54]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 586–595, 2018. 7
2018
-
[55]
Limb-aware vir- tual try-on network with progressive clothing warping.IEEE Transactions on Multimedia (TMM), 26:1731–1746, 2023
Shengping Zhang, Xiaoyu Han, Weigang Zhang, Xiangyuan Lan, Hongxun Yao, and Qingming Huang. Limb-aware vir- tual try-on network with progressive clothing warping.IEEE Transactions on Multimedia (TMM), 26:1731–1746, 2023. 2
2023
-
[56]
Boow-vton: Boosting in-the-wild virtual try-on via mask- free pseudo data training
Xuanpu Zhang, Dan Song, Pengxin Zhan, Tianyu Chang, Jianhao Zeng, Qingguo Chen, Weihua Luo, and An-An Liu. Boow-vton: Boosting in-the-wild virtual try-on via mask- free pseudo data training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26399–26408, 2025. 3
2025
-
[57]
View synthesis by appearance flow
Tinghui Zhou, Shubham Tulsiani, Weilun Sun, Jitendra Ma- lik, and Alexei A Efros. View synthesis by appearance flow. InProceedings of the European Conference on Computer Vi- sion (ECCV), pages 286–301, 2016. 2
2016
-
[58]
Learning flow fields in attention for controllable person image generation
Zijian Zhou, Shikun Liu, Xiao Han, Haozhe Liu, Kam Woh Ng, Tian Xie, Yuren Cong, Hang Li, Mengmeng Xu, Juan- Manuel P ´erez-R´ua, et al. Learning flow fields in attention for controllable person image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2491–2501, 2025. 3
2025
-
[59]
Tryondiffusion: A tale of two unets
Luyang Zhu, Dawei Yang, Tyler Zhu, Fitsum Reda, William Chan, Chitwan Saharia, Mohammad Norouzi, and Ira Kemelmacher-Shlizerman. Tryondiffusion: A tale of two unets. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 4606– 4615, 2023. 2
2023
-
[60]
M&m vto: Multi- garment virtual try-on and editing
Luyang Zhu, Yingwei Li, Nan Liu, Hao Peng, Dawei Yang, and Ira Kemelmacher-Shlizerman. M&m vto: Multi- garment virtual try-on and editing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1346–1356, 2024. 3 11 A. Implementation Details In our experiments, we initialize the weights of Cloth-Net and Adapt-Net...
2024
-
[61]
For inference, the whole virtual try- on pipeline can be executed in approximately 5.7 seconds when running on a single NVIDIA A100 GPU
The training is conducted on paired images with a resolu- tion of 512×384, and we adopt a batch size of 8 throughout the training process. For inference, the whole virtual try- on pipeline can be executed in approximately 5.7 seconds when running on a single NVIDIA A100 GPU. B. User Study Details To provide a more comprehensive evaluation of our pro- pose...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.