Learning from almost nothing: How neural networks survive heavy input corruption
Pith reviewed 2026-06-27 14:04 UTC · model grok-4.3
The pith
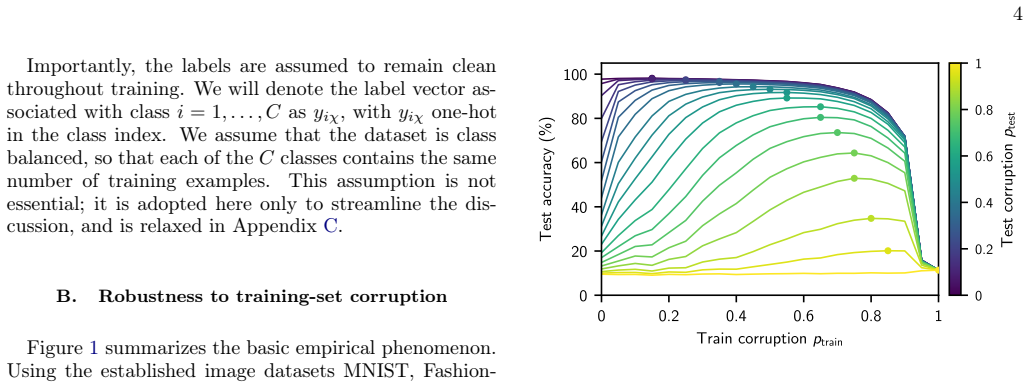
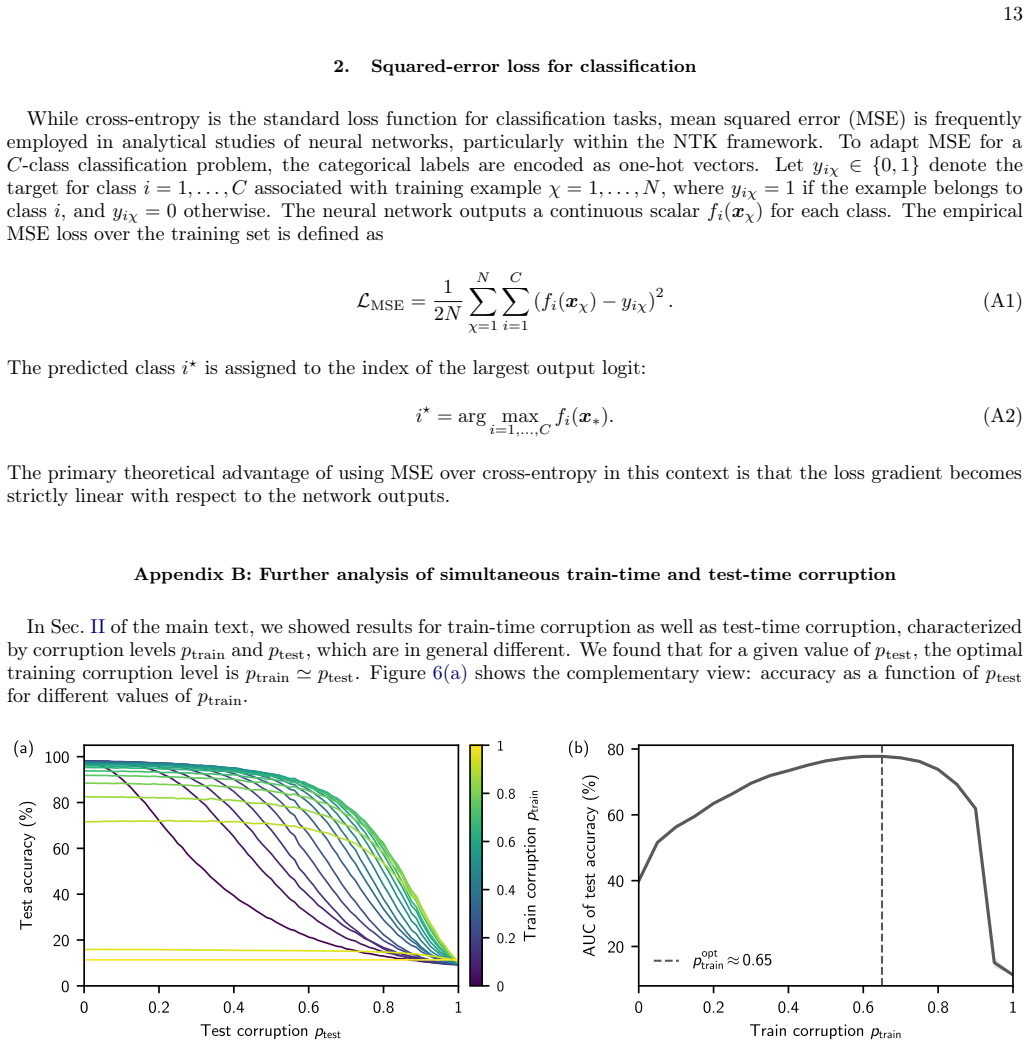
Neural networks classify inputs over 90 percent corrupted by assigning each test point to the nearest class mean from the training set.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
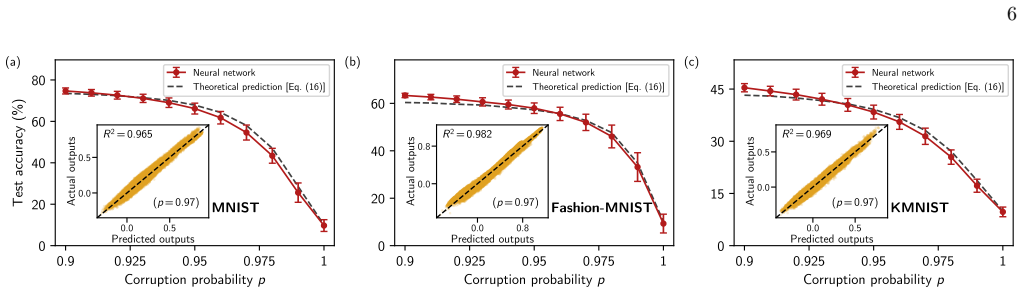
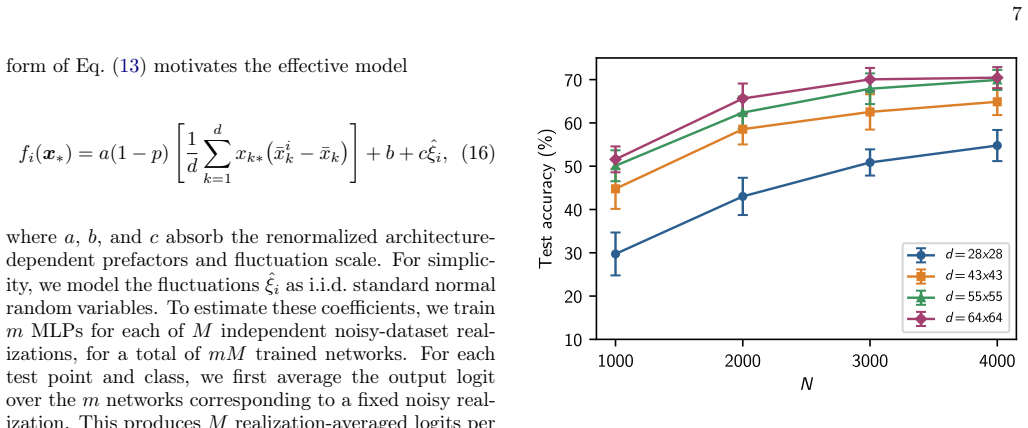
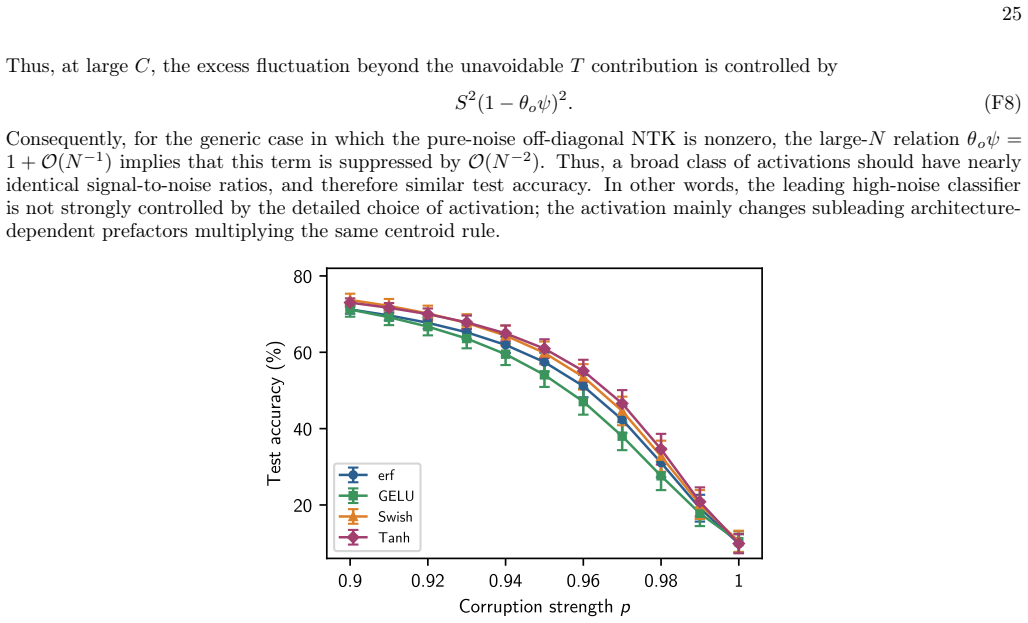
In the heavy-corruption regime an infinite-width network implements the nearest-class-mean rule, assigning each test point to the class whose training-set average it most closely resembles. This leading-order decision rule is universal across MLP architectures of any depth and across wide classes of activation functions and noise distributions. The centroid mechanism closely matches finite-width behavior and supplies an analytically tractable explanation for why learning succeeds when individual training examples carry almost no signal.
What carries the argument
The nearest-class-mean prototype rule, which compares a test point to the average of each training class and selects the closest match.
If this is right
- The same nearest-class-mean rule governs networks of arbitrary depth.
- The rule emerges for a wide family of activation functions and both additive and replacement noise.
- Finite-width networks closely follow the infinite-width centroid predictions in the heavy-corruption regime.
- Learning can succeed even though each individual training example is almost uninformative.
Where Pith is reading between the lines
- The centroid mechanism may extend to other architectures such as transformers when input corruption dominates.
- Explicitly regularizing networks toward class centroids could improve robustness under extreme noise.
- The result suggests that prototype-based explanations could apply to other regimes where signal per example is low.
Load-bearing premise
The mean-field description of infinite-width networks captures the dominant term in the heavy-corruption limit so that higher-order corrections never flip the classification outcome.
What would settle it
Train an MLP on a corrupted dataset, compute the class centroids from the training set, and check whether the network's test predictions match the nearest-centroid rule on a majority of points; systematic mismatch would falsify the leading-order claim.
Figures



read the original abstract
Learning from imperfect data is a central theme in machine learning, connecting practical questions of robustness to fundamental questions of learnability. Here we examine attribute noise: learning from corrupted inputs while keeping the labels intact, a setting that has received considerably less analytical attention than its label-noise counterpart. We consider two types of corruption models: additive noise and replacement noise. Through experiments with multi-layer perceptrons (MLPs) on corrupted classification datasets, we find that neural networks remain robust, maintaining well-above-chance accuracy even when inputs are >90% corrupted -- far beyond human recognition. To understand this robustness, we analyze infinite-width networks in the heavy-corruption regime using a mean-field-inspired approach and derive a leading-order decision rule for the classification outcome: the network implements a prototype rule, the nearest-class-mean, assigning each test point to the class whose training-set average it most closely resembles. This leading-order decision rule is universal across a broad range of MLP architectures, holding for any depth, as well as a wide class of activation functions and noise distributions. The same centroid mechanism closely matches finite-width network behavior in our experiments and provides an interpretable and analytically tractable account of why learning can succeed even when individual training examples carry almost no signal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines learning under heavy attribute noise (corrupted inputs with intact labels) for MLPs. Experiments demonstrate robustness beyond 90% corruption. A mean-field-inspired analysis for infinite-width networks in the heavy-corruption regime derives a leading-order nearest-class-mean decision rule that is claimed to be universal across architectures, depths, activations, and noise distributions, and matches finite-width experiments.
Significance. If the result holds, it offers an analytically tractable explanation for input-noise robustness via a simple prototype mechanism, with potential implications for understanding generalization in noisy settings. The universality and experimental match are notable strengths.
major comments (2)
- [mean-field analysis] The mean-field-inspired derivation of the nearest-class-mean rule as the leading-order decision rule (abstract) requires explicit control showing that higher-order terms in the expansion do not flip the sign of logit differences for a positive-measure set of test points near decision boundaries; without such bounds the universality claim across depths and activations rests on an unverified assumption that the remainder is negligible for classification outcome.
- [experiments] The experimental confirmation that the centroid mechanism matches finite-width network behavior needs quantitative agreement metrics (e.g., fraction of test points where network prediction equals nearest-class-mean) broken down by corruption level and architecture; the current qualitative statement leaves open whether the match holds uniformly or only on average.
minor comments (2)
- Define the precise scaling that constitutes the 'heavy-corruption regime' (e.g., noise variance relative to input dimension) and state the asymptotic limit taken.
- Specify the exact class of activation functions and noise distributions for which the derivation holds, including any technical conditions required.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The two major comments highlight important points for strengthening the theoretical claims and experimental validation. We address each below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [mean-field analysis] The mean-field-inspired derivation of the nearest-class-mean rule as the leading-order decision rule (abstract) requires explicit control showing that higher-order terms in the expansion do not flip the sign of logit differences for a positive-measure set of test points near decision boundaries; without such bounds the universality claim across depths and activations rests on an unverified assumption that the remainder is negligible for classification outcome.
Authors: Our analysis derives the leading-order term in the heavy-corruption asymptotic expansion under the infinite-width mean-field limit; this term yields the nearest-class-mean rule independently of depth, activation function, and noise distribution. The manuscript presents this as the dominant decision rule in the stated regime rather than an exact classifier for all finite corruption levels. While rigorous bounds ensuring higher-order remainders never flip classification outcomes near boundaries would strengthen the result, such control lies beyond the leading-order scope of the current derivation and would require a substantially more technical expansion. The experimental agreement across architectures provides empirical support that the leading term governs behavior in the heavy-noise regime studied. We will add a clarifying paragraph in the discussion section explicitly noting the leading-order nature of the claim and the role of experimental validation. revision: partial
-
Referee: [experiments] The experimental confirmation that the centroid mechanism matches finite-width network behavior needs quantitative agreement metrics (e.g., fraction of test points where network prediction equals nearest-class-mean) broken down by corruption level and architecture; the current qualitative statement leaves open whether the match holds uniformly or only on average.
Authors: We agree that quantitative metrics will make the experimental match more precise. In the revised version we will add a new table (or supplementary figure) reporting the agreement fraction—defined as the percentage of test points on which the trained finite-width MLP prediction coincides with the nearest-class-mean classifier—stratified by corruption level (50 %, 80 %, 90 %, 95 %) and by architecture (depths 1–5, widths 100–1000). This will allow readers to assess uniformity versus average behavior directly. revision: yes
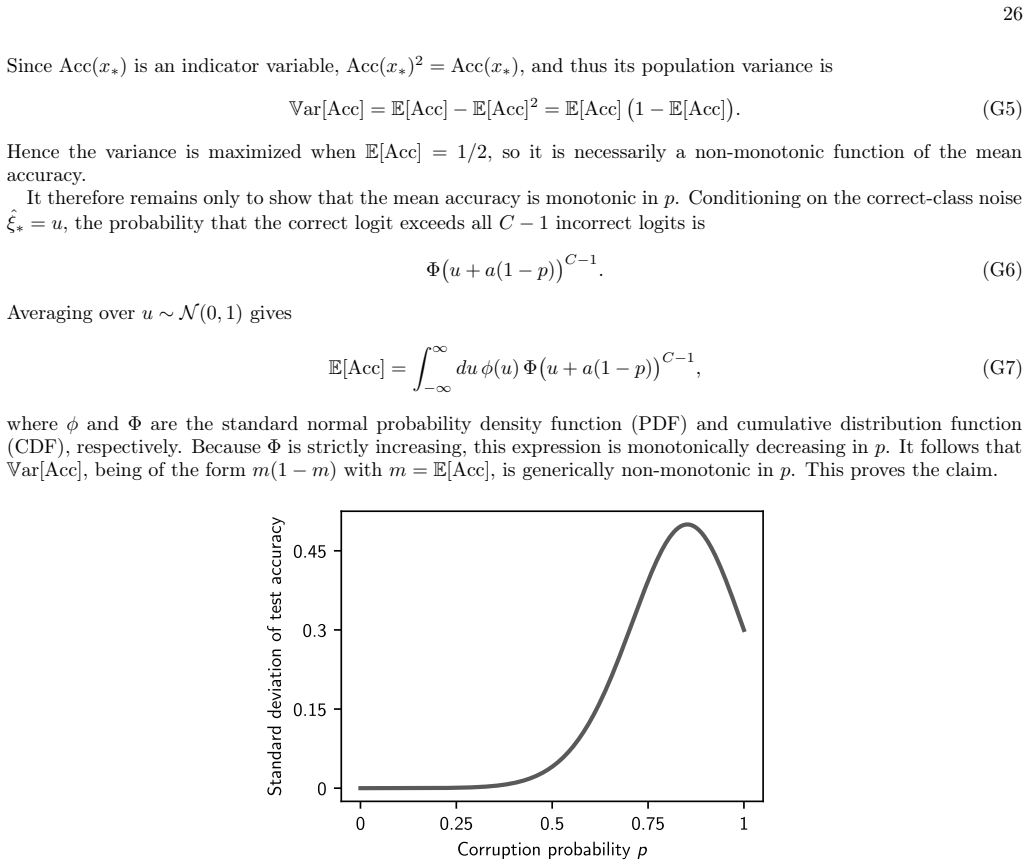
Circularity Check
Mean-field derivation is analytically independent; no reduction to inputs or self-citations
full rationale
The paper derives the nearest-class-mean rule via an explicit mean-field-inspired analysis of infinite-width networks under heavy corruption, yielding a leading-order decision rule that holds for arbitrary depth, activations, and noise distributions. This is an analytical expansion rather than a statistical fit or renaming of empirical patterns. Experiments on finite-width MLPs are presented only as corroboration that the derived rule matches observed behavior, not as the source of the rule itself. No self-citations, fitted parameters renamed as predictions, or ansatzes smuggled via prior work appear in the abstract or described derivation chain. The argument is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Mean-field limit applies to infinite-width MLPs and yields a tractable leading-order decision rule under heavy corruption
- ad hoc to paper Higher-order corrections remain negligible for classification outcome in the heavy-corruption regime
Reference graph
Works this paper leans on
-
[1]
D.AngluinandP.Laird,MachineLearning2,343(1988)
1988
-
[2]
Kearns, Journal of the ACM45, 983 (1998)
M. Kearns, Journal of the ACM45, 983 (1998)
1998
-
[3]
A. Blum, A. Kalai, and H. Wasserman, Journal of the ACM50, 506 (2003)
2003
-
[4]
Frenay and M
B. Frenay and M. Verleysen, IEEE Transactions on Neu- ral Networks and Learning Systems25, 845 (2014)
2014
-
[5]
N.Natarajan, I.S.Dhillon, P.Ravikumar,andA.Tewari, inAdvances in Neural Information Processing Systems 26 (NeurIPS 2013)(2013)
2013
-
[6]
D. Rolnick, A. Veit, S. Belongie, and N. Shavit, Deep learning is robust to massive label noise (2017), arXiv:1705.10694. 11
Pith/arXiv arXiv 2017
-
[7]
Northcutt, L
C. Northcutt, L. Jiang, and I. Chuang, J. Artif. Int. Res. 70, 1373–1411 (2021)
2021
-
[8]
Emmanuel, T
T. Emmanuel, T. Maupong, D. Mpoeleng, T. Semong, B. Mphago, and O. Tabona, Journal of Big Data8, 140 (2021)
2021
-
[9]
Matsuoka, IEEE Transactions on Systems, Man, and Cybernetics22, 436 (1992)
K. Matsuoka, IEEE Transactions on Systems, Man, and Cybernetics22, 436 (1992)
1992
-
[10]
Holmström and P
L. Holmström and P. Koistinen, IEEE Transactions on Neural Networks3, 24 (1992)
1992
-
[11]
C. M. Bishop, Neural Computation7, 108 (1995)
1995
-
[12]
An, Neural Computation8, 643 (1996)
G. An, Neural Computation8, 643 (1996)
1996
-
[13]
Sietsma and R
J. Sietsma and R. J. Dow, Neural Networks4, 67 (1991)
1991
-
[14]
R. Reed, S. Oh, and R. Marks, in[Proceedings 1992] IJCNN International Joint Conference on Neural Net- works, Vol. 3 (1992) pp. 147–152 vol.3
1992
-
[15]
R.M.Zur, Y.Jiang, L.L.Pesce,andK.Drukker,Medical Physics36, 4810 (2009)
2009
-
[16]
O. H. Ramírez-Agudelo Sr, N. Gorea, A. Reif, L. Bonasera, and M. Karl Sr, inApplications of Machine Learning 2025, Vol. 13606 (SPIE, 2025) pp. 197–212
2025
-
[17]
Globerson and S
A. Globerson and S. Roweis, inProceedings of the 23rd International Conference on Machine Learning, ICML ’06 (Association for Computing Machinery, New York, NY, USA, 2006) p. 353–360
2006
-
[18]
Dekel and O
O. Dekel and O. Shamir, inProceedings of the 25th In- ternational Conference on Machine Learning, ICML ’08 (Association for Computing Machinery, New York, NY, USA, 2008) p. 216–223
2008
-
[19]
Van Der Maaten, M
L. Van Der Maaten, M. Chen, S. Tyree, and K. Q. Wein- berger, inProceedings of the 30th International Confer- ence on International Conference on Machine Learning - Volume 28, ICML’13 (JMLR.org, 2013) p. I–410–I–418
2013
-
[20]
D. Hendrycks, N. Mu, E. D. Cubuk, B. Zoph, J. Gilmer, and B. Lakshminarayanan, Augmix: A simple data pro- cessing method to improve robustness and uncertainty (2020), arXiv:1912.02781 [stat.ML]
arXiv 2020
-
[21]
D. Hendrycks and T. G. Dietterich, CoRR abs/1903.12261(2019), 1903.12261
Pith/arXiv arXiv 1903
- [22]
-
[23]
LeCun, C
Y. LeCun, C. Cortes, and C. Burges, ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist2(2010)
2010
-
[24]
T. Clanuwat, M. Bober-Irizar, A. Kitamoto, A. Lamb, K. Yamamoto, and D. Ha, arXiv preprint arXiv:1812.01718 (2018), arXiv:1812.01718 [cs.CV]
Pith/arXiv arXiv 2018
-
[25]
H. Xiao, K. Rasul, and R. Vollgraf, arXiv preprint arXiv:1708.07747 (2017), arXiv:1708.07747 [cs.LG]
Pith/arXiv arXiv 2017
-
[26]
A.Jacot, F.Gabriel,andC.Hongler,inAdvances in Neu- ral Information Processing Systems 31 (NeurIPS 2018) (2018) pp. 8571–8580, arXiv:1806.07572
arXiv 2018
-
[27]
Tibshirani, T
R. Tibshirani, T. Hastie, B. Narasimhan, and G. Chu, Proceedings of the National Academy of Sciences99, 6567 (2002)
2002
-
[28]
J. Snell, K. Swersky, and R. S. Zemel, CoRR abs/1703.05175(2017), 1703.05175
Pith/arXiv arXiv 2017
-
[29]
Guerriero, B
S. Guerriero, B. Caputo, and T. Mensink, inICLR Work- shop(2018)
2018
- [30]
-
[31]
M. E. A. Seddik and M. Tamaazousti, Proceedings of the AAAI Conference on Artificial Intelligence36, 8204 (2022)
2022
-
[32]
V. Kothapalli, Neural collapse: A review on modelling principles and generalization (2023), arXiv:2206.04041 [cs.LG]
arXiv 2023
-
[33]
Mei and A
S. Mei and A. Montanari, Communications on Pure and Applied Mathematics75, 667 (2022)
2022
- [34]
-
[35]
Hu and Y
H. Hu and Y. M. Lu, IEEE Transactions on Information Theory69, 1932 (2023)
1932
-
[36]
Montanari and B
A. Montanari and B. N. Saeed, inProceedings of the 35th Conference on Learning Theory (COLT), Proceedings of Machine Learning Research, Vol. 178 (PMLR, 2022) pp. 4310–4312
2022
-
[37]
Bahri, B
Y. Bahri, B. Hanin, A. Brossollet, V. Erba, C. Keup, R. Pacelli, and J. B. Simon, Journal of Statistical Me- chanics: Theory and Experiment2024, 104012 (2024)
2024
-
[38]
We use the convention that a depthLnetwork hasL−1 hidden layers
-
[39]
D. A. Roberts, S. Yaida, and B. Hanin,The principles of deep learning theory, Vol. 46 (Cambridge University Press Cambridge, MA, USA, 2022)
2022
-
[40]
In contrast, the value of the sec- ond moment can affect the orientation of the centroid rule, as discussed below
The value of the first moment is inconsequential for the rest of the calculation; a nonzero first moment simply renormalizes the constantsr(ℓ),s (ℓ), andt (ℓ) introduced later in the subsection. In contrast, the value of the sec- ond moment can affect the orientation of the centroid rule, as discussed below
-
[41]
Price, IRE Transactions on Information Theory4, 69 (2003)
R. Price, IRE Transactions on Information Theory4, 69 (2003)
2003
-
[42]
Abramowitz and I
M. Abramowitz and I. A. Stegun,Handbook of Mathe- matical Functions(Dover, New York, 1965)
1965
-
[43]
NIST digital library of mathematical functions,https: //dlmf.nist.gov/, Chapter 18, release 1.2.x, F. W. J. Olveret al., eds. 12 Appendix A: Experimental details
-
[44]
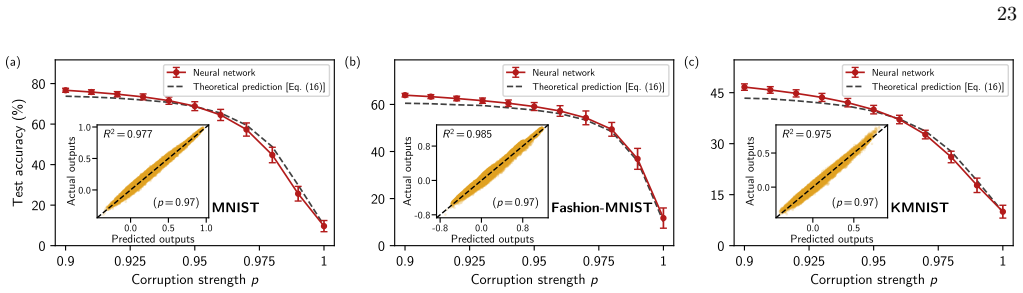
Experimental setup For reference, Table I gathers the datasets, corruption schemes, model architectures, and training protocols used to produce each figure in the main text. TABLE I. Compact summary of the experimental settings used in the main text and appendix. Figure Dataset and corruption Model and training Fig. 1 Balanced MNIST, Fashion-MNIST, KMNIST...
2048
-
[45]
To adapt MSE for a C-class classification problem, the categorical labels are encoded as one-hot vectors
Squared-error loss for classification While cross-entropy is the standard loss function for classification tasks, mean squared error (MSE) is frequently employed in analytical studies of neural networks, particularly within the NTK framework. To adapt MSE for a C-class classification problem, the categorical labels are encoded as one-hot vectors. Lety iχ ...
-
[46]
The clean training features are denoted byx∈R d×N, while the corrupted training features are denoted by˜x∈R d×N
Setup We consider a training set withNexamples,Cclasses, and feature dimensiond. The clean training features are denoted byx∈R d×N, while the corrupted training features are denoted by˜x∈R d×N. The clean labels are denoted byy∈R N×C, withy i ∈R N the one-hot target vector for classi= 1, . . . , C. A clean test feature is denoted by x∗ ∈R d. The notation i...
-
[47]
First, Price’s theorem gives the following derivatives of Gaussian expectations with respect to the covariance
Useful identities We collect several identities used repeatedly below. First, Price’s theorem gives the following derivatives of Gaussian expectations with respect to the covariance. For one-dimensional Gaussian expectations, ∂ ∂Kαα ⟨gh⟩Kαα =⟨g ′h′⟩Kαα + 1 2 ⟨g′′h⟩Kαα + 1 2 ⟨gh′′⟩Kαα .(C14) For two-dimensional Gaussian expectations withα̸=β, ∂ ∂Kαα ⟨gαhβ⟩...
-
[48]
1 2 ⟨σ′′ ασβ⟩K(l) δK (l) αα +⟨σ ′ ασ′ β⟩K(l) δK (l) αβ + 1 2 ⟨σασ′′ β⟩K(l) δK (l) ββ # ,(C33) 1 Cw δΘ(l+1) αβ =δ αβ
Influence of input perturbations on the output We now compute how a perturbation in the first-layer Bayesian kernel propagates to the output. Let ˜K (l) αβ =K (l) αβ +δK (l) αβ +O(δK 2), ˜Θ(l) αβ = Θ(l) αβ +δΘ (l) αβ +O(δK 2).(C30) The unperturbed kernels satisfy the pure-noise recursions Θ(l+1) αβ =C b +C w ⟨σασβ⟩K(l) +⟨σ ′ ασ′ β⟩K(l)Θ(l) αβ ,(C31) K (l+...
-
[49]
Since Eq
Output fluctuations under Gaussian kernel perturbations We now isolate the fluctuation term obtained by taking δK (1) αβ = 1√ d ηαβ,(C43) whereη αβ is a mean-zero Gaussian random tensor. Since Eq. (C42) is linear inηαβ, the induced output fluctuation is also Gaussian. It is therefore enough to compute its covariance. The basic identity is E Cov1 β(ηαβ, yβ...
-
[50]
∂K (1) αα ∂ϵ # +T 1→L ∗χ ∆Ei α
The output for an arbitrary i.i.d. noise model For an arbitrary i.i.d. noise model, the first-layer perturbation is δK (1) αβ =ϵ ∂K (1) αβ ∂ϵ + 1√ d ηαβ.(C61) Substituting this into Eq. (C42), and using the fluctuation result Eq. (C59), gives the general high-noise output. Here, we assume the dataset has been partitioned intoCequally represented classes. ...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.