NSVQ: Mitigating Codebook Collapse by Stabilizing Encoder Drift in Vector Quantization
Pith reviewed 2026-06-27 13:17 UTC · model grok-4.3
The pith
NSVQ prevents codebook collapse by making the codebook track then lock to encoder movement in vector quantization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
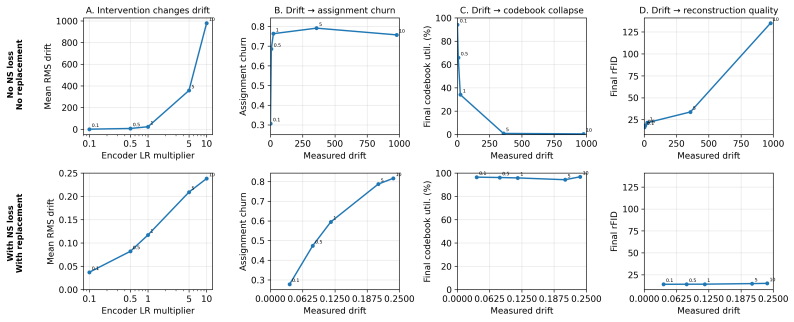
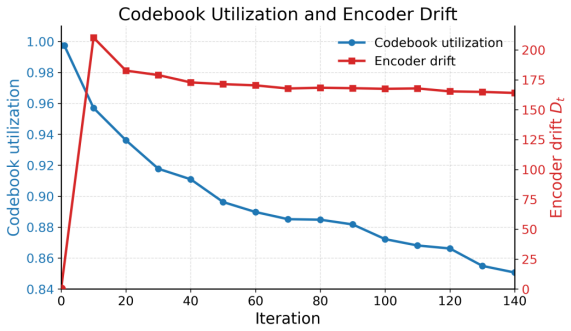
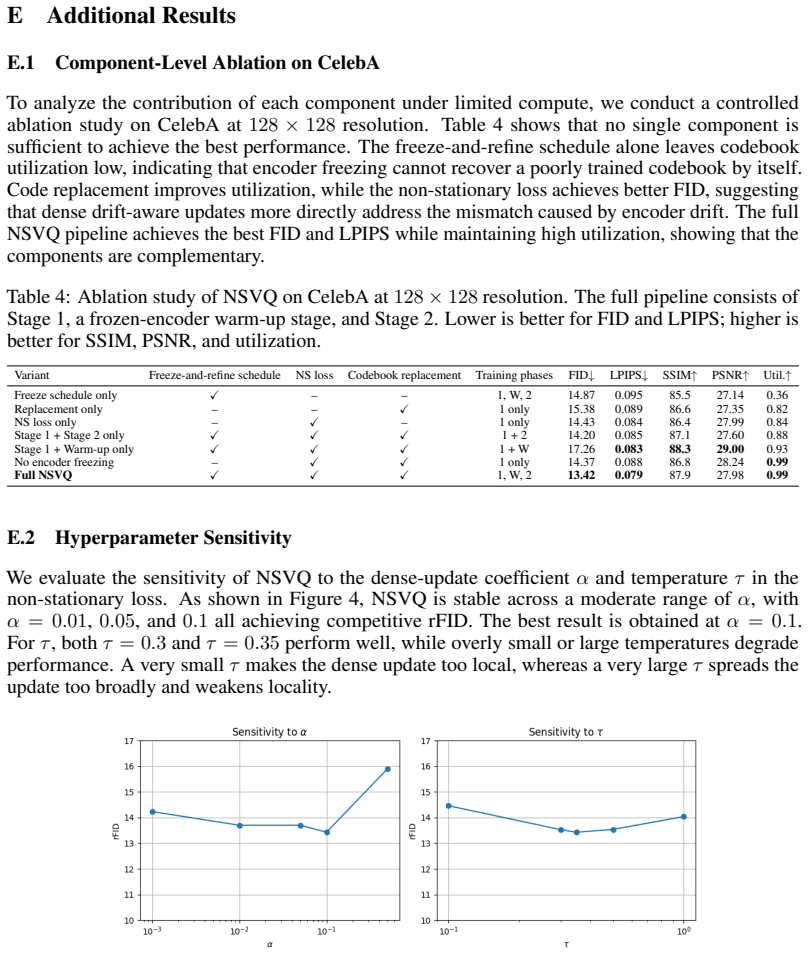
NSVQ is a non-stationary-aware VQ training strategy that combines a dense non-stationary embedding loss, codebook replacement, and stage-wise encoder freezing. It first helps the codebook track encoder drift during early training, then freezes the encoder to consolidate the codebook under a fixed latent geometry, and finally reintroduces adversarial refinement. On ImageNet-1k at 128×128 with 65,536 codes, NSVQ reduces rFID from 2.39 to 2.10 compared with SimVQ, while both methods maintain 100% utilization. Additional latent diffusion experiments show that NSVQ also improves downstream ImageNet generation FID.
What carries the argument
The NSVQ training schedule, which pairs a dense non-stationary embedding loss with codebook replacement and staged encoder freezing to first follow then stabilize the latent distribution.
If this is right
- Full codebook utilization is preserved at 65,536 entries on ImageNet-1k.
- Reconstruction rFID improves from 2.39 to 2.10 relative to SimVQ under identical codebook size.
- Downstream latent diffusion models trained on the resulting latents achieve lower generation FID on ImageNet.
- The staged freeze-then-refine schedule can be inserted into existing VQ pipelines without changing the encoder or decoder architecture.
Where Pith is reading between the lines
- Similar drift-tracking losses could be tested on audio or video VQ models where codebook collapse is also reported.
- The replacement step might be replaced by softer reassignment rules in future variants without losing the core benefit.
- Freezing the encoder after initial alignment may reduce the total number of training steps needed to reach stable utilization.
- The method's emphasis on non-stationary statistics could be adapted to other quantization schemes that rely on straight-through gradients.
Load-bearing premise
Encoder drift is the main driver of codebook collapse, and the three-part NSVQ schedule will track and then consolidate the codebook without creating new instabilities or needing heavy retuning.
What would settle it
Run NSVQ and SimVQ side-by-side on ImageNet-1k at 128×128 with 65,536 codes and check whether rFID drops below 2.39 or codebook utilization falls below 100 percent.
Figures





read the original abstract
Vector quantization is central to modern generative modeling pipelines, but large-codebook VQ models often suffer from codebook collapse. We identify encoder drift as a key driver of this failure: as the encoder moves the latent distribution, sparsely updated code vectors can lag behind, lose assignments, and increase quantization error, creating a feedback loop through the straight-through estimator. We propose NSVQ, a non-stationary-aware VQ training strategy that combines a dense non-stationary embedding loss, codebook replacement, and stage-wise encoder freezing. NSVQ first helps the codebook track encoder drift during early training, then freezes the encoder to consolidate the codebook under a fixed latent geometry, and finally reintroduces adversarial refinement. Experiments on ImageNet-1k show that NSVQ improves reconstruction quality while maintaining full codebook utilization. On ImageNet-1k at 128$\times$128 with 65,536 codes, NSVQ reduces rFID from 2.39 to 2.10 compared with SimVQ, while both methods maintain 100\% utilization. Additional latent diffusion experiments show that NSVQ also improves downstream ImageNet generation FID.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies encoder drift as a driver of codebook collapse in large-codebook vector quantization and proposes NSVQ, a three-component training strategy (dense non-stationary embedding loss, codebook replacement, stage-wise encoder freezing) that first tracks drift, then consolidates the codebook under a fixed encoder, and finally allows adversarial refinement. On ImageNet-1k at 128×128 with 65,536 codes it reports an rFID reduction from 2.39 (SimVQ) to 2.10 while preserving 100 % utilization; downstream latent-diffusion experiments also show improved generation FID.
Significance. If the reported metric gains are reproducible and the three-stage procedure proves robust, NSVQ supplies a practical, empirically grounded intervention for a recurring failure mode in VQ-based generative pipelines; the concrete rFID delta on a standard benchmark with full utilization maintained is a clear strength.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the central empirical claim (rFID drop from 2.39 to 2.10, 100 % utilization) is presented without ablations that isolate the contribution of the dense non-stationary loss, the replacement rule, or the stage-wise freezing schedule; this absence directly undermines in the causal role attributed to encoder drift.
- [Method] Method description: no quantitative verification (e.g., code-assignment histograms, drift-norm plots, or controlled ablations) is supplied to establish that encoder drift is the primary driver rather than a correlate; the three-stage procedure therefore rests on an untested mechanistic assumption that is load-bearing for the proposed remedy.
minor comments (2)
- [Abstract] The abstract states the three stages at a high level; a concise numbered list or diagram in the method section would improve readability.
- [Experiments] No error bars, multiple random seeds, or training-curve figures are referenced; adding these would strengthen the reproducibility of the reported FID numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical isolation of components and mechanistic verification. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central empirical claim (rFID drop from 2.39 to 2.10, 100 % utilization) is presented without ablations that isolate the contribution of the dense non-stationary loss, the replacement rule, or the stage-wise freezing schedule; this absence directly undermines in the causal role attributed to encoder drift.
Authors: We agree that the current experiments do not include ablations that separately quantify the contribution of each NSVQ component. This limits the strength of the causal attribution to encoder drift. In the revised manuscript we will add a dedicated ablation study that reports rFID and utilization when each component is removed or disabled in turn, while keeping all other training details fixed. revision: yes
-
Referee: [Method] Method description: no quantitative verification (e.g., code-assignment histograms, drift-norm plots, or controlled ablations) is supplied to establish that encoder drift is the primary driver rather than a correlate; the three-stage procedure therefore rests on an untested mechanistic assumption that is load-bearing for the proposed remedy.
Authors: The manuscript motivates encoder drift from observed training dynamics and the straight-through estimator feedback loop, yet we acknowledge that direct quantitative evidence such as drift-norm trajectories or assignment histograms is not provided. We will incorporate these visualizations and supporting measurements in the Method and Experiments sections of the revision to substantiate the mechanistic premise. revision: yes
Circularity Check
No significant circularity; empirical method only
full rationale
The paper describes an empirical training procedure (dense non-stationary loss + replacement + stage-wise freezing) and reports benchmark rFID numbers on ImageNet. No derivation chain, uniqueness theorem, or prediction is claimed; the central results are direct experimental comparisons rather than quantities forced by the method's own definitions or self-citations. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yoshua Bengio, Nicholas Léonard, and Aaron Courville
URLhttps://arxiv.org/abs/2106.08254. Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432,
-
[2]
Yifan Chang, Jie Qin, Limeng Qiao, Xiaofeng Wang, Zheng Zhu, Lin Ma, and Xingang Wang
URL https://arxiv.org/ abs/1308.3432. Yifan Chang, Jie Qin, Limeng Qiao, Xiaofeng Wang, Zheng Zhu, Lin Ma, and Xingang Wang. Scalable training for vector-quantized networks with 100% codebook utilization.arXiv preprint arXiv:2509.10140,
-
[3]
Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, and Ilya Sutskever
URL https://arxiv.org/abs/2509.10140. Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, and Ilya Sutskever. Jukebox: A generative model for music.arXiv preprint arXiv:2005.00341,
arXiv 2005
-
[4]
Patrick Esser, Robin Rombach, and Björn Ommer
URL https://arxiv.org/abs/ 2005.00341. Patrick Esser, Robin Rombach, and Björn Ommer. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12873–12883,
Pith/arXiv arXiv 2005
-
[5]
Xianghong Fang, Yuan Yuan, Dehan Kong, and Tim G
URLhttps://arxiv.org/abs/2012.09841. Xianghong Fang, Yuan Yuan, Dehan Kong, and Tim G. J. Rudner. VQ-Transplant: Efficient VQ-module integration for pre-trained visual tokenizers. InInternational Conference on Learning Representations,
arXiv 2012
-
[6]
Wengang Guo, Kaiyan Lin, and Wei Ye
doi: 10.1109/18.720541. Wengang Guo, Kaiyan Lin, and Wei Ye. Deep embedded k-means clustering. In2021 IEEE International Conference on Data Mining Workshops (ICDMW), pages 686–694. IEEE,
-
[7]
doi: 10.1109/ICDMW53433. 2021.00090. Minyoung Huh, Brian Cheung, Pulkit Agrawal, and Phillip Isola. Straightening out the straight-through estimator: Overcoming optimization challenges in vector quantized networks. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 14096–14113,
-
[9]
URL https://arxiv. org/abs/2503.17760. Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, pages 3730–3738,
-
[10]
doi: 10.1109/ICCV .2015.425. Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite scalar quantization: VQ-V AE made simple. InInternational Conference on Learning Representations,
-
[11]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer
URL https://arxiv.org/abs/ 1906.00446. Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695,
Pith/arXiv arXiv 1906
-
[12]
Aurko Roy, Ashish Vaswani, Arvind Neelakantan, and Niki Parmar
URLhttps://arxiv.org/abs/2112.10752. Aurko Roy, Ashish Vaswani, Arvind Neelakantan, and Niki Parmar. Theory and experiments on vector quantized autoencoders.arXiv preprint arXiv:1805.11063,
-
[13]
URLhttps://arxiv.org/abs/1805.11063. Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. Imagenet large scale visual recognition challenge.International Journal of Computer Vision, 115(3):211–252,
-
[14]
Yuqing Wang, Zhijie Lin, Yao Teng, Yuanzhi Zhu, Shuhuai Ren, Jiashi Feng, and Xihui Liu
URL https://arxiv.org/abs/ 1711.00937. Yuqing Wang, Zhijie Lin, Yao Teng, Yuanzhi Zhu, Shuhuai Ren, Jiashi Feng, and Xihui Liu. Bridging continuous and discrete tokens for autoregressive visual generation. InProceedings of the IEEE/CVF International Conference on Computer Vision,
-
[15]
Will Williams, Sam Ringer, Tom Ash, John Hughes, David MacLeod, and Jamie Dougherty
URLhttps://arxiv.org/abs/2503.16430. Will Williams, Sam Ringer, Tom Ash, John Hughes, David MacLeod, and Jamie Dougherty. Hierarchical quantized autoencoders.arXiv preprint arXiv:2002.08111,
arXiv 2002
-
[16]
URL https://arxiv.org/abs/2002. 08111. Jiahui Yu, Xin Li, Jing Yu Koh, Han Zhang, Ruoming Pang, James Qin, Alexander Ku, Yuanzhong Xu, Jason Baldridge, and Yonghui Wu. Vector-quantized image modeling with improved VQGAN. InInternational Con- ference on Learning Representations,
2002
-
[17]
Borui Zhang, Qihang Rao, Wenzhao Zheng, Jie Zhou, and Jiwen Lu
doi: 10.1109/TASLP.2021.3129994. Borui Zhang, Qihang Rao, Wenzhao Zheng, Jie Zhou, and Jiwen Lu. Quantize-then-rectify: Efficient VQ-V AE training.arXiv preprint arXiv:2507.10547,
-
[18]
Jiahui Zhang, Fangneng Zhan, Christian Theobalt, and Shijian Lu
URLhttps://arxiv.org/abs/2507.10547. Jiahui Zhang, Fangneng Zhan, Christian Theobalt, and Shijian Lu. Regularized vector quantization for tokenized image synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18467–18476,
-
[19]
URLhttps://arxiv.org/abs/2303.06424. Yue Zhao, Fuzhao Xue, Scott Reed, Linxi Fan, Yuke Zhu, Jan Kautz, Zhiding Yu, Philipp Krähenbühl, and De-An Huang. QLIP: Text-aligned visual tokenization unifies auto-regressive multimodal understanding and generation.arXiv preprint arXiv:2502.05178,
-
[20]
Chuanxia Zheng and Andrea Vedaldi
URLhttps://arxiv.org/abs/2502.05178. Chuanxia Zheng and Andrea Vedaldi. Online clustered codebook. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22798–22807,
-
[21]
Scaling the codebook size of VQGAN to 100,000 with a utilization rate of 99%
Lei Zhu, Fangyun Wei, Yanye Lu, and Dong Chen. Scaling the codebook size of VQGAN to 100,000 with a utilization rate of 99%. InAdvances in Neural Information Processing Systems, 2024a. URL https://arxiv.org/abs/2406.11837. Yongxin Zhu, Bocheng Li, Yifei Xin, Zhihua Xia, and Linli Xu. Addressing representation collapse in vector quantized models with one l...
-
[22]
Because the encoder has already been updated usingx 1, the latent position ofx 2 changes approximately as z(1) e (x2)≈z (0) e (x2) +J (0) θ (x2)∆θ(0).(30) However, becausec q2 was not selected when processingx 1, it does not directly move: c(1) q2 =c (0) q2 .(31) This creates an immediate asymmetry: the latent feature ofx2 has drifted, but its previously ...
2018
-
[23]
Stage 2 then reintroduces adversarial refinement under the same fixed latent geometry
At this point, freezing no longer prevents the encoder from learning a VQ-compatible representation; rather, it removes further encoder drift and converts codebook learning into a stable consolidation problem. Stage 2 then reintroduces adversarial refinement under the same fixed latent geometry. Therefore, in NSVQ, encoder freezing is not used as a stand-...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.