INFRAMIND: Infrastructure-Aware Multi-Agent Orchestration
Pith reviewed 2026-06-27 12:56 UTC · model grok-4.3
The pith
Making the full multi-agent LLM stack observe real-time queue depths, cache pressure, and latencies improves both accuracy and SLO compliance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
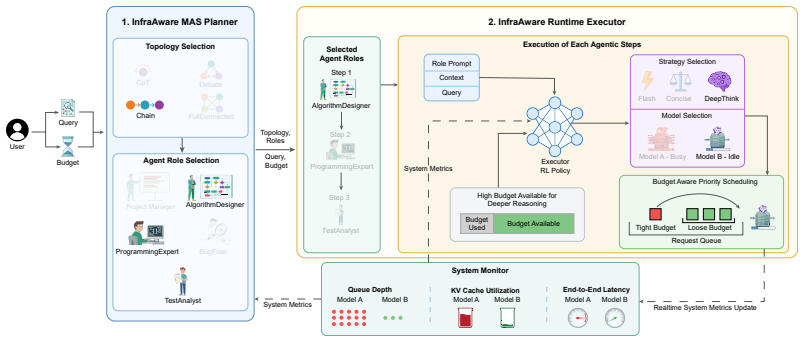
By conditioning topology choice, per-step model selection, and queue ordering on observable infrastructure signals, the hierarchical constrained MDP learns policies that balance quality against latency and sustain service-level objectives under contention.
What carries the argument
Hierarchical constrained MDP that jointly optimizes infra-aware planner, executor, and scheduler via end-to-end reinforcement learning.
If this is right
- At low load the system reaches up to 7.6 percentage points higher accuracy with up to 7 times lower latency than prior methods.
- Under high load it maintains up to 99.9 percent SLO compliance while every baseline falls below 50 percent.
- The planner automatically chooses simpler topologies when queues are long and richer ones when capacity is free.
- Sequential delays in multi-agent pipelines shrink because each step avoids already-congested models.
Where Pith is reading between the lines
- The same signal-driven MDP could be applied to single-model serving or to non-LLM multi-stage pipelines that share accelerators.
- If the RL policy generalizes across hardware generations, the approach could reduce the need for manual capacity planning in large clusters.
- Adding explicit cost or energy signals to the same MDP would let the system optimize for power in addition to latency and accuracy.
Load-bearing premise
Real-time infrastructure signals can be measured with low enough overhead and noise that they improve planner, executor, and scheduler decisions more than the monitoring cost hurts them.
What would settle it
A controlled run in which the added monitoring latency or measurement variance is large enough that the learned policy produces lower accuracy or worse SLO compliance than the non-infra-aware baseline.
Figures




read the original abstract
Existing multi-agent LLM orchestration methods, ranging from brute-force ensembles to learned routers, select models and topologies based on task and model features. However, these methods do not consider the runtime state of the serving infrastructure. On shared GPU clusters under concurrent load, this infrastructure blindness causes systematic resource underutilization: preferred models accumulate deep request queues while equally capable alternatives sit idle. In multi-agent pipelines, where each query triggers multiple sequential model calls, these delays then compound across every downstream step. Closing this gap is challenging because the relevant infrastructure signals (queue depths, KV-cache pressure, latencies) are dynamic and noisy, and they must drive three different decisions: planning, per-step routing, and scheduling. We introduce INFRAMIND, a framework that makes the entire multi-agent stack infrastructure-aware. An infra-aware planner conditions topology and role selection on real-time system load and remaining budget, biasing toward simpler graphs under congestion and richer ones at low load. An infra-aware executor then observes per-model queue depths, cache utilization, and response latencies at each agent step to decide which model to call and how deeply to reason; a budget-aware scheduler further reorders each model's queue so that urgent requests are served first. Cast as a hierarchical constrained MDP and solved end-to-end via reinforcement learning, the system learns to balance quality against latency automatically. Across five benchmarks, INFRAMIND delivers up to +7.6 pp accuracy over the prior baseline at low load with up to 7x lower latency, and sustains up to 99.9% SLO compliance under high load where every baseline drops below 50%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces INFRAMIND, a framework for infrastructure-aware multi-agent LLM orchestration. It augments existing methods by conditioning an infra-aware planner, executor, and budget-aware scheduler on real-time signals such as queue depths, KV-cache pressure, and latencies. These components are cast as a hierarchical constrained MDP solved end-to-end with reinforcement learning to balance quality against latency. The central empirical claim is that, across five benchmarks, the system achieves up to +7.6 pp accuracy over prior baselines at low load (with up to 7x lower latency) and maintains up to 99.9% SLO compliance under high load where all baselines fall below 50%.
Significance. If the performance claims can be substantiated with complete experimental documentation, the work would address a practically relevant gap: the compounding effect of infrastructure state on multi-agent pipelines in shared GPU clusters. The hierarchical MDP formulation and RL solution provide a principled way to incorporate dynamic signals without manual tuning, which could improve utilization in production serving environments.
major comments (1)
- [Abstract] Abstract: The abstract states specific numeric gains (+7.6 pp accuracy, up to 7x lower latency, 99.9% SLO compliance) but supplies no experimental setup, baseline definitions, statistical tests, variance measures, or controls for confounds, so it is impossible to verify whether the data support the claims. This is load-bearing for the central empirical contribution.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in the abstract. We agree that the reported performance numbers require sufficient context for immediate verification and will revise the abstract accordingly while preserving its brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states specific numeric gains (+7.6 pp accuracy, up to 7x lower latency, 99.9% SLO compliance) but supplies no experimental setup, baseline definitions, statistical tests, variance measures, or controls for confounds, so it is impossible to verify whether the data support the claims. This is load-bearing for the central empirical contribution.
Authors: We accept this point. The full experimental protocol (five benchmarks, baseline definitions as prior multi-agent routers and ensembles, evaluation under controlled low/high load with real cluster traces, 5-run averages with reported variance, and SLO definitions) appears in Sections 4–5, but the abstract does not reference it. We will revise the abstract to add one concise clause: 'Evaluated on five standard benchmarks against prior orchestration baselines under simulated and production cluster loads (5 runs, std < 0.8 pp), INFRAMIND achieves...' This directly addresses verifiability without lengthening the abstract substantially. No other changes to the empirical claims are needed. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper frames INFRAMIND as an empirical RL solution to a hierarchical constrained MDP whose planner, executor, and scheduler are conditioned on observable infrastructure signals. All central claims (accuracy gains, latency reductions, SLO compliance) are presented as outcomes of end-to-end training and benchmark evaluation rather than quantities derived from or defined in terms of themselves. No equations, fitted-parameter loops, self-citations, or ansatzes appear in the provided text that would reduce any prediction to its inputs by construction; the architecture is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reinforcement learning on a hierarchical constrained MDP can learn effective policies that balance quality, latency, and SLOs from the described infrastructure signals.
Reference graph
Works this paper leans on
-
[1]
Program synthesis with large language models.arXiv preprint arXiv:2108.07732,
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732,
-
[2]
Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
-
[3]
Gartner Predicts 40% of Enterprise Apps Will Feature Task-Specific AI Agents by 2026, Up from Less Than 5% in
Gartner. Gartner Predicts 40% of Enterprise Apps Will Feature Task-Specific AI Agents by 2026, Up from Less Than 5% in
2026
-
[4]
Gartner Press Release. https://www.gartner.com/en/newsr oom/press-releases/2025-08-26-gartner-predicts-40-percent-of-enterprise- apps-will-feature-task-specific-ai-agents-by-2026-up-from-less-than-5- percent-in-2025,
2025
-
[5]
Accessed: 2026-04-29. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
Pith/arXiv arXiv 2026
-
[6]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
-
[7]
Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
-
[8]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186,
-
[9]
Mistral 7b.ArXiv, abs/2310.06825,
Albert Qiaochu Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b.ArXiv, abs/2310.06825,
-
[10]
Jeremy Kahn
URLhttps://api.semanticscholar.org/CorpusID:263830494. Jeremy Kahn. Bloomberg, the OG of financial data firms, has a potent new AI agent. How it built it holds lessons for other companies. Fortune. https://fortune.com/2026/04/28/bloomberg- askb-ai-agents-lessons-from-bloomberg-cto-shawn-edwards-eye-on-ai/ ,
2026
-
[11]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
Accessed: 2026-04-29. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626,
2026
-
[12]
Chung Laung Liu and James W Layland
Accessed: 2026-04-29. Chung Laung Liu and James W Layland. Scheduling algorithms for multiprogramming in a hard- real-time environment.Journal of the ACM (JACM), 20(1):46–61,
2026
-
[13]
Routellm: Learning to route llms with preference data.arXiv preprint arXiv:2406.18665,
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E Gonzalez, M Waleed Kadous, and Ion Stoica. Routellm: Learning to route llms with preference data.arXiv preprint arXiv:2406.18665,
-
[14]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 3982–3992,
2019
-
[15]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
-
[16]
Mixture-of-agents enhances large language model capabilities.arXiv preprint arXiv:2406.04692, 2024a
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou. Mixture-of-agents enhances large language model capabilities.arXiv preprint arXiv:2406.04692, 2024a. Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi- task l...
-
[17]
Ronald J Williams
Accessed: 2026-04-29. Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning.Machine learning, 8(3):229–256,
2026
-
[18]
R2-router: A new paradigm for llm routing with reasoning.arXiv preprint arXiv:2602.02823,
Jiaqi Xue, Qian Lou, Jiarong Xing, and Heng Huang. R2-router: A new paradigm for llm routing with reasoning.arXiv preprint arXiv:2602.02823,
-
[19]
doi: 10.52202/079017-2910. URL https://proceedings.neurips.cc/paper_files/pap er/2024/file/a6deba3b2408af45b3f9994c2152b862-Paper-Conference.pdf. Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model progr...
-
[20]
LR scheduler ReduceLROnPlateau (patience 3, factor 0.5) PPO clipϵ0.2 PPO mini-epochsK3 Entropy coefficientα H 0.10 Initialλ 0 0.2 λlearning rateη λ 0.001 λmax 1.0 Budget tiers (s) {10, 30, 50, 100, 200, 300} Arrival rates (req/min) {10, 30, 50, 100, 200} vLLMmax_num_seqs16 (all models) Total parameters∼471K B Dataset Details Table 6: Dataset splits used i...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.