SAGE: Answer-Conditioned Uncertainty Targets for Verbal Uncertainty Alignment
Pith reviewed 2026-06-27 12:51 UTC · model grok-4.3
The pith
SAGE builds answer-conditioned uncertainty targets from repeated model samples to align verbal expressions with actual output distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
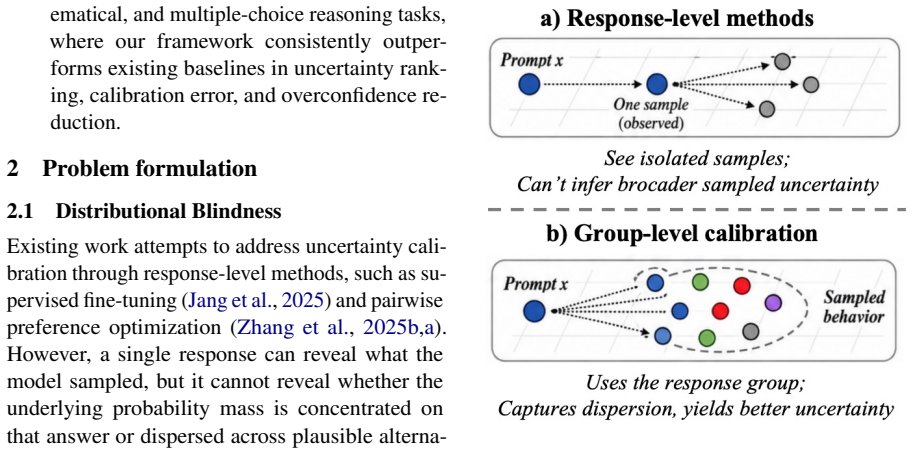
SAGE, Semantic-Answer Guided Entropy, is a group-level uncertainty target that constructs an answer-conditioned uncertainty geometry over sampled responses. It preserves categorical, numeric, and symbolic answer distinctions while maintaining a smooth and scale-preserving calibration signal. When used inside Group-Uncertainty Preference Optimization (GUPO), which supervises verbal uncertainty expressions rather than full responses, the approach yields improved uncertainty ranking, lower calibration error, and reduced overconfidence across factual, mathematical, and multiple-choice reasoning tasks.
What carries the argument
Semantic-Answer Guided Entropy (SAGE), which constructs an answer-conditioned uncertainty geometry over sampled responses to serve as the group-level training target.
If this is right
- Verbal uncertainty expressions become better calibrated to the model's actual output distribution.
- Uncertainty ranking improves on factual, mathematical, and multiple-choice reasoning tasks.
- Calibration error decreases relative to earlier uncertainty targets.
- Overconfidence in generated responses is reduced.
Where Pith is reading between the lines
- The geometry construction might extend to tasks with open-ended or structured outputs not covered in the reported experiments.
- GUPO could be combined with existing preference optimization pipelines that already separate answer and uncertainty channels.
- If the smoothness property holds across model scales, the same target construction may transfer without per-model retuning.
Load-bearing premise
Group rollouts alone are insufficient because the resulting target must also provide a useful training signal, and existing targets only partially satisfy this requirement.
What would settle it
An experiment that applies SAGE targets versus prior group-rollout targets and observes no improvement in uncertainty ranking or calibration error on the factual, mathematical, and multiple-choice tasks would falsify the central benefit.
Figures

read the original abstract
Large language models increasingly express uncertainty through natural-language statements, yet these expressions often fail to reflect the model's sampled behavior. We study verbal uncertainty alignment as a distributional calibration problem: the appropriate uncertainty target for a prompt should be estimated from repeated model outputs rather than from an isolated response. However, group rollouts alone are insufficient, since the resulting target must provide a useful training signal. Existing targets only partially satisfy this requirement. We propose SAGE, Semantic-Answer Guided Entropy, a group-level uncertainty target that constructs an answer-conditioned uncertainty geometry over sampled responses. SAGE preserves categorical, numeric, and symbolic answer distinctions while maintaining a smooth and scale-preserving calibration signal. We further apply this target through Group-Uncertainty Preference Optimization, or GUPO, an uncertainty-channel training framework that supervises verbal uncertainty expressions rather than the full response. Experiments across factual, mathematical, and multiple-choice reasoning tasks show improved uncertainty ranking, lower calibration error, and reduced overconfidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames verbal uncertainty alignment in LLMs as a distributional calibration problem and proposes SAGE (Semantic-Answer Guided Entropy), a group-level target constructed from repeated model outputs that builds an answer-conditioned uncertainty geometry. SAGE is claimed to preserve categorical, numeric, and symbolic distinctions among responses while remaining smooth and scale-preserving. The target is applied via GUPO (Group-Uncertainty Preference Optimization), which supervises only the uncertainty channel rather than full responses. Experiments on factual, mathematical, and multiple-choice reasoning tasks report gains in uncertainty ranking, calibration error, and overconfidence reduction.
Significance. If the central claims hold, the work supplies a concrete mechanism for aligning expressed verbal uncertainty with empirical sampling behavior, addressing a practical gap between isolated responses and group statistics. The explicit preservation of answer-type distinctions while maintaining a usable training signal is a distinguishing feature relative to prior calibration targets.
minor comments (3)
- [Abstract / §2] The abstract states that 'existing targets only partially satisfy this requirement' without naming the targets or quantifying the partial satisfaction; a brief comparison table or explicit list in §2 would strengthen the motivation.
- [Methods] Notation for the uncertainty geometry (e.g., how categorical vs. numeric answers are embedded) is introduced only at a high level; an explicit definition or pseudocode in the methods section would aid reproducibility.
- [§3] The claim that SAGE is 'parameter-free' relative to prior targets should be supported by an explicit statement of which hyperparameters are eliminated versus retained.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work on SAGE and GUPO, including the recognition of its contribution to distributional calibration for verbal uncertainty. The minor_revision recommendation is noted; we will incorporate any editorial or minor clarifications in the revised manuscript. No major comments were listed in the report, so we provide no point-by-point responses below.
Circularity Check
No significant circularity detected
full rationale
The paper introduces SAGE as a new answer-conditioned uncertainty target constructed from group rollouts of model outputs, preserving distinctions across answer types while providing a smooth calibration signal, then applies it via GUPO. No equations, derivations, or self-citations are exhibited in the provided text that reduce the central construction to fitted inputs by definition or import uniqueness from prior author work. The proposal is presented as addressing partial shortcomings of existing targets through a novel geometry, with empirical validation on multiple tasks; this constitutes a self-contained contribution without load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The appropriate uncertainty target for a prompt should be estimated from repeated model outputs rather than from an isolated response.
invented entities (2)
-
SAGE (Semantic-Answer Guided Entropy)
no independent evidence
-
GUPO (Group-Uncertainty Preference Optimization)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Journal of the American Medical Informatics Association : JAMIA , year=
Large language model uncertainty proxies: discrimination and calibration for medical diagnosis and treatment , author=. Journal of the American Medical Informatics Association : JAMIA , year=
-
[2]
Communications Medicine , year=
Multi-model assurance analysis showing large language models are highly vulnerable to adversarial hallucination attacks during clinical decision support , author=. Communications Medicine , year=
-
[3]
iScience , year=
The application of large language models in medicine: A scoping review , author=. iScience , year=
-
[4]
Frontiers in Nutrition , year=
Large language models in clinical nutrition: an overview of its applications, capabilities, limitations, and potential future prospects , author=. Frontiers in Nutrition , year=
-
[5]
Nature , year=
Detecting hallucinations in large language models using semantic entropy , author=. Nature , year=
-
[6]
ArXiv , year=
Language Model Cascades: Token-level uncertainty and beyond , author=. ArXiv , year=
-
[7]
ArXiv , year=
The Internal State of an LLM Knows When its Lying , author=. ArXiv , year=
-
[8]
ArXiv , year=
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author=. ArXiv , year=
-
[9]
ArXiv , year=
Kernel Language Entropy: Fine-grained Uncertainty Quantification for LLMs from Semantic Similarities , author=. ArXiv , year=
-
[10]
ArXiv , year=
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs , author=. ArXiv , year=
-
[11]
Teaching Models to Express Their Uncertainty in Words , author=. Trans. Mach. Learn. Res. , year=
-
[12]
ArXiv , year=
Large Language Models Must Be Taught to Know What They Don't Know , author=. ArXiv , year=
-
[13]
North American Chapter of the Association for Computational Linguistics , year=
A Survey of Confidence Estimation and Calibration in Large Language Models , author=. North American Chapter of the Association for Computational Linguistics , year=
-
[14]
ArXiv , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. ArXiv , year=
-
[15]
ArXiv , year=
Selectively Answering Ambiguous Questions , author=. ArXiv , year=
-
[16]
ArXiv , year=
Verbalized Confidence Triggers Self-Verification: Emergent Behavior Without Explicit Reasoning Supervision , author=. ArXiv , year=
-
[17]
ArXiv , year=
Direct Confidence Alignment: Aligning Verbalized Confidence with Internal Confidence In Large Language Models , author=. ArXiv , year=
-
[18]
ArXiv , year=
Reinforcement Learning for Better Verbalized Confidence in Long-Form Generation , author=. ArXiv , year=
-
[19]
ArXiv , year=
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension , author=. ArXiv , year=
-
[20]
ArXiv , year=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. ArXiv , year=
-
[21]
ArXiv , year=
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark , author=. ArXiv , year=
-
[22]
ArXiv , year=
Qwen2.5 Technical Report , author=. ArXiv , year=
-
[23]
ArXiv , year=
Finetuning Language Models to Emit Linguistic Expressions of Uncertainty , author=. ArXiv , year=
-
[24]
2026 , url=
ORCE: Order-Aware Alignment of Verbalized Confidence in Large Language Models , author=. 2026 , url=
2026
-
[25]
arXiv preprint arXiv:2509.19580 , year=
Llms4all: A review of large language models across academic disciplines , author=. arXiv preprint arXiv:2509.19580 , year=
-
[26]
Proceedings of the 30th International Conference on Intelligent User Interfaces , pages=
Clear: Towards contextual llm-empowered privacy policy analysis and risk generation for large language model applications , author=. Proceedings of the 30th International Conference on Intelligent User Interfaces , pages=
-
[27]
Soups , year=
The obvious invisible threat: Llm-powered gui agents’ vulnerability to fine-print injections , author=. Soups , year=
-
[28]
CIKM , year=
Cheffusion: Multimodal foundation model integrating recipe and food image generation , author=. CIKM , year=
-
[29]
arXiv , year=
Adaptive Testing for LLM Evaluation: A Psychometric Alternative to Static Benchmarks , author=. arXiv , year=
-
[30]
arXiv , year=
CrochetBench: Can Vision-Language Models Move from Describing to Doing in Crochet Domain? , author=. arXiv , year=
-
[31]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Deliberate reasoning in language models as structure-aware planning with an accurate world model , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[32]
The Fourteenth International Conference on Learning Representations , year=
Enhancing Language Model Reasoning with Structured Multi-Level Modeling , author=. The Fourteenth International Conference on Learning Representations , year=
-
[33]
arXiv preprint arXiv:2602.01672 , year=
Scaling Search-Augmented LLM Reasoning via Adaptive Information Control , author=. arXiv preprint arXiv:2602.01672 , year=
-
[34]
Findings of the Association for Computational Linguistics: EACL 2026 , pages=
MAPRO: Recasting Multi-Agent Prompt Optimization as Maximum a Posteriori Inference , author=. Findings of the Association for Computational Linguistics: EACL 2026 , pages=
2026
-
[35]
arXiv preprint arXiv:2510.05445 , year=
AgentRouter: A Knowledge-Graph-Guided LLM Router for Collaborative Multi-Agent Question Answering , author=. arXiv preprint arXiv:2510.05445 , year=
-
[36]
Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
NG-Router: Graph-Supervised Multi-Agent Collaboration for Nutrition Question Answering , author=. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[37]
arXiv preprint arXiv:2604.05149 , year=
EvolveRouter: Co-Evolving Routing and Prompt for Multi-Agent Question Answering , author=. arXiv preprint arXiv:2604.05149 , year=
-
[38]
arXiv preprint arXiv:2601.18106 , year=
GLEN-Bench: A Graph-Language based Benchmark for Nutritional Health , author=. arXiv preprint arXiv:2601.18106 , year=
-
[39]
arXiv preprint arXiv:2602.02455 , year=
Drift-Bench: Diagnosing Cooperative Breakdowns in LLM Agents under Input Faults via Multi-Turn Interaction , author=. arXiv preprint arXiv:2602.02455 , year=
-
[40]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
LM-polygraph: Uncertainty estimation for language models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
2023
-
[41]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Fact-checking the output of large language models via token-level uncertainty quantification , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[42]
arXiv preprint arXiv:2602.03309 , year=
Entropy-Gated Selective Policy Optimization: Token-Level Gradient Allocation for Hybrid Training of Large Language Models , author=. arXiv preprint arXiv:2602.03309 , year=
-
[43]
arXiv preprint arXiv:2306.13063 , year=
Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms , author=. arXiv preprint arXiv:2306.13063 , year=
-
[44]
ArXiv , year=
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models , author=. ArXiv , year=
-
[45]
ArXiv , year=
LUQ: Long-text Uncertainty Quantification for LLMs , author=. ArXiv , year=
-
[46]
ArXiv , year=
Graph-based Uncertainty Metrics for Long-form Language Model Outputs , author=. ArXiv , year=
-
[47]
Advances in Neural Information Processing Systems , volume=
Kernel language entropy: Fine-grained uncertainty quantification for llms from semantic similarities , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
arXiv preprint arXiv:2605.21801 , year=
Why Semantic Entropy Fails: Geometry-Aware and Calibrated Uncertainty for Policy Optimization , author=. arXiv preprint arXiv:2605.21801 , year=
-
[49]
Advances in Neural Information Processing Systems , volume=
Autodata: A multi-agent system for open web data collection , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.