Estimating the local false discovery rate under an unknown symmetric null
Pith reviewed 2026-06-27 09:08 UTC · model grok-4.3
The pith
Estimating the surrogate density ratio f(-w)/f(w) yields asymptotic local false discovery rate control under a symmetric null.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the stripped-down two-groups model with symmetric null, the local false discovery rate can be estimated by targeting the surrogate f(-w)/f(w) for w > 0, and any consistent estimator of this surrogate yields asymptotic lfdr control for the procedure that thresholds at the nominal level.
What carries the argument
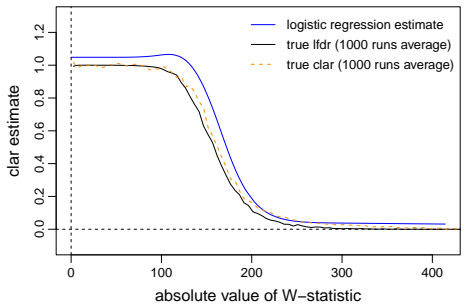
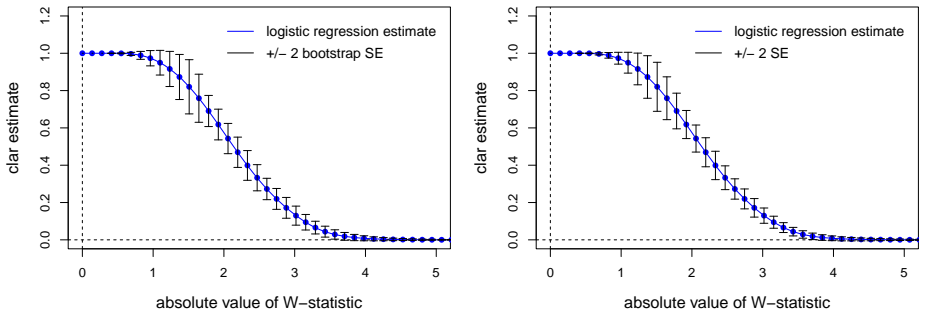
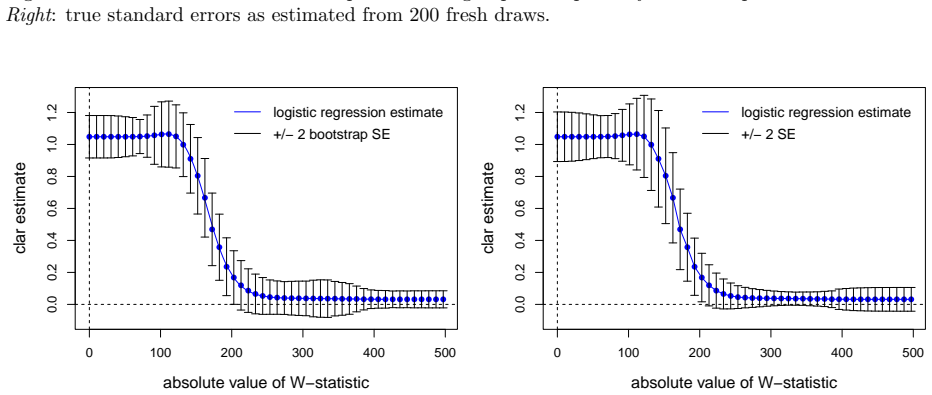
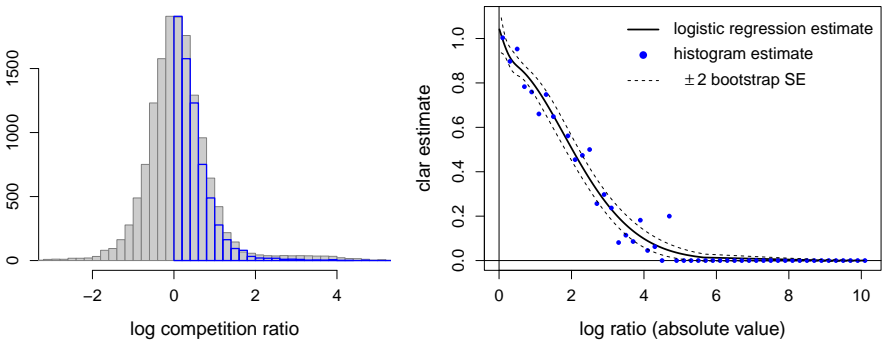
The surrogate density ratio f(-w)/f(w) for positive w, which serves as a proxy for the lfdr and is estimated using logistic regression with natural cubic spline basis functions.
If this is right
- Thresholding the estimated surrogate at level alpha produces a procedure with asymptotic lfdr control at alpha.
- The control property requires no knowledge of the null density beyond its symmetry about zero.
- The logistic regression estimator with splines provides one route to the needed consistency.
- The framework applies directly to variable selection problems that transform scores into statistics with symmetric nulls.
- It extends earlier lfdr analysis under known null to the unknown-null case while preserving the control guarantee.
Where Pith is reading between the lines
- The same surrogate idea could be adapted to other multiple-testing procedures that enforce null symmetry.
- Pairing the estimator with knockoff-based selection might tighten local error rates in high-dimensional regression.
- Empirical checks on data sets where symmetry is engineered but the null shape is unknown would test finite-sample behavior.
- Relaxing independence assumptions while retaining symmetry might be a natural next direction.
Load-bearing premise
The null distribution of the test statistics is symmetric about zero.
What would settle it
Simulations in which symmetry holds and a provably consistent estimator of the surrogate is applied, yet the empirical local false discovery proportion among rejections fails to converge to the nominal threshold as sample size increases.
Figures

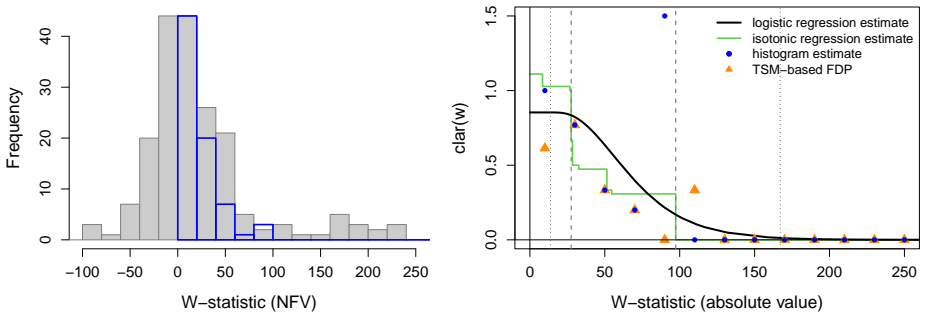
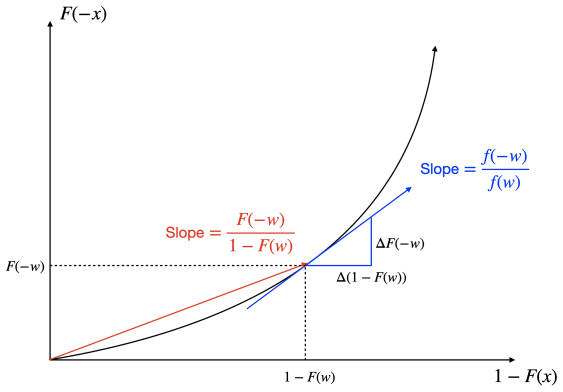
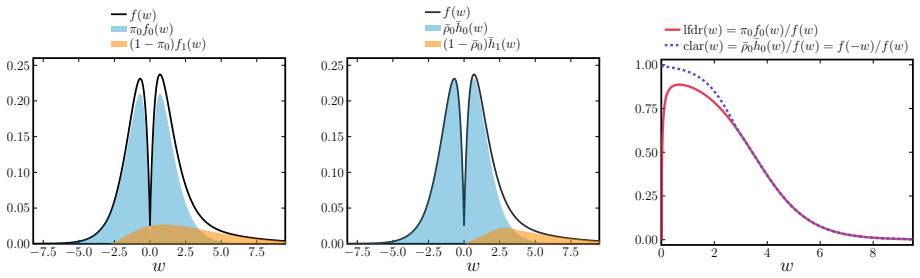
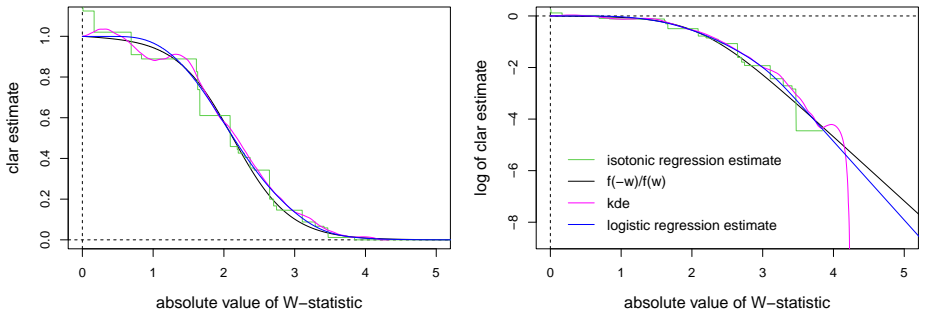


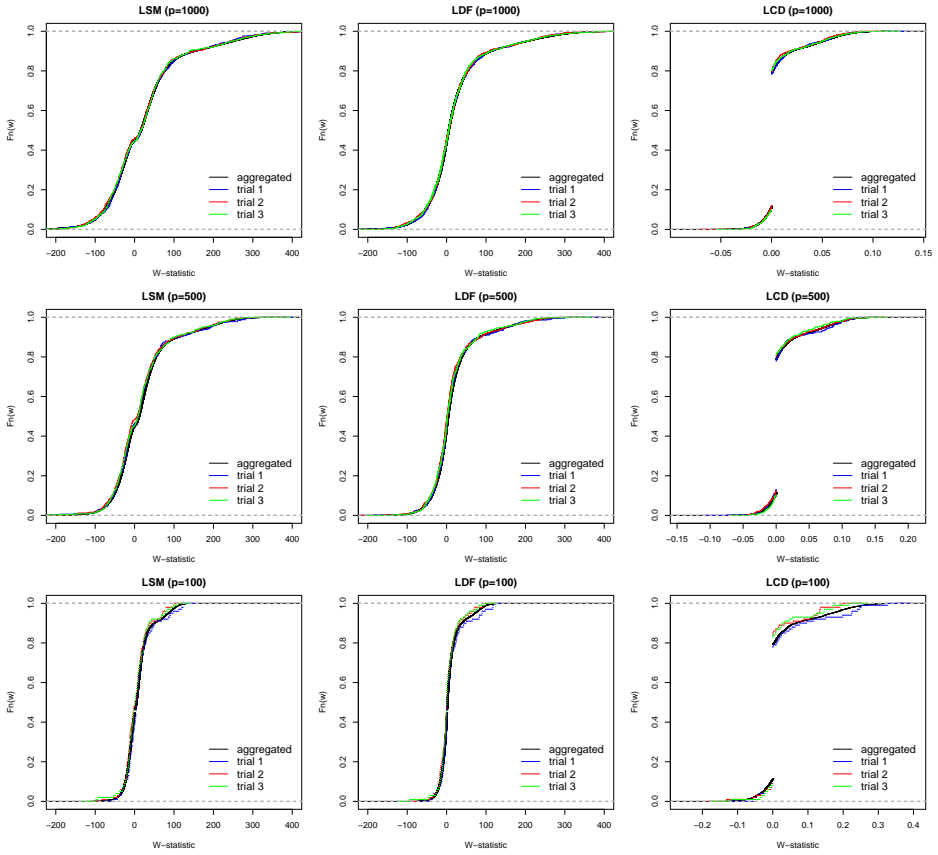
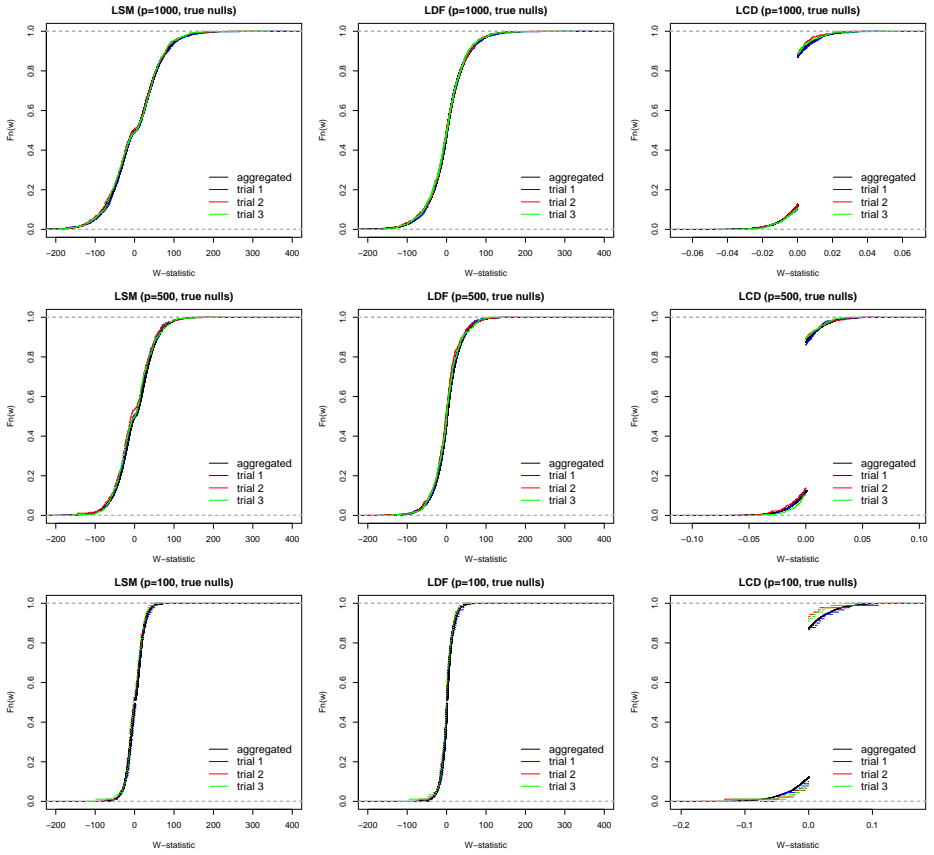
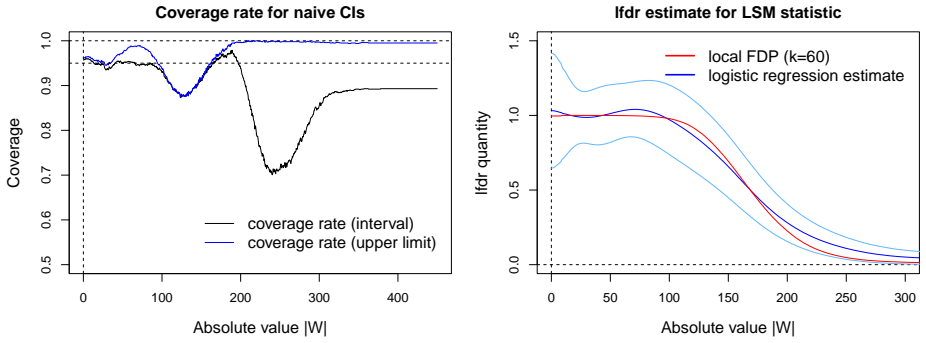
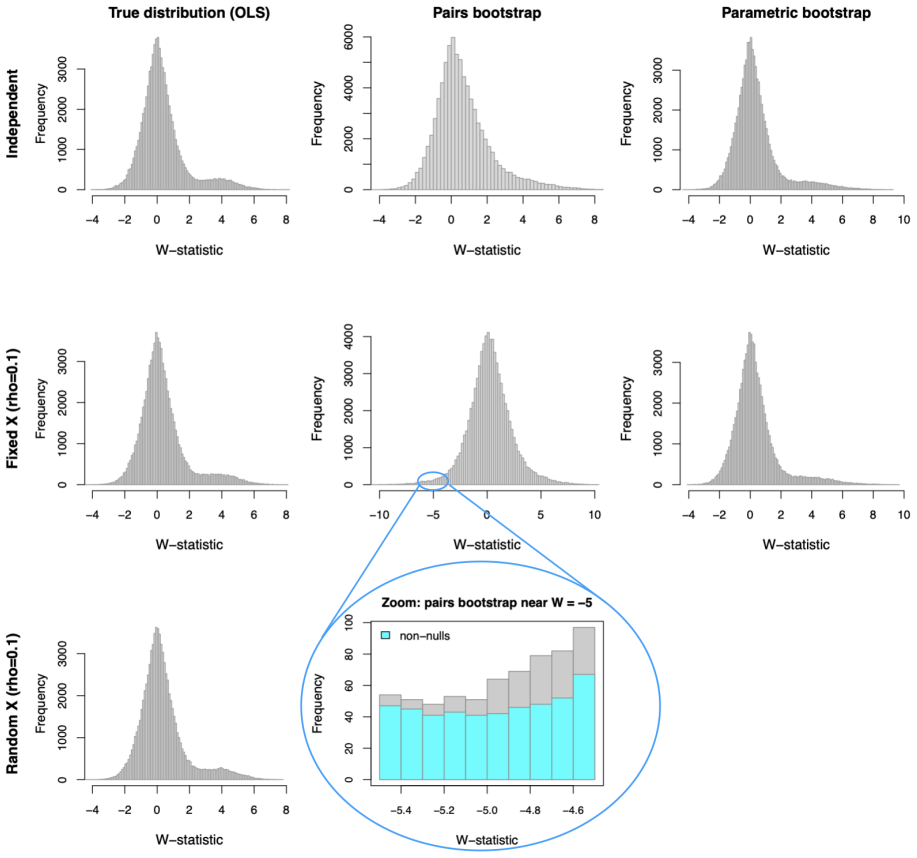
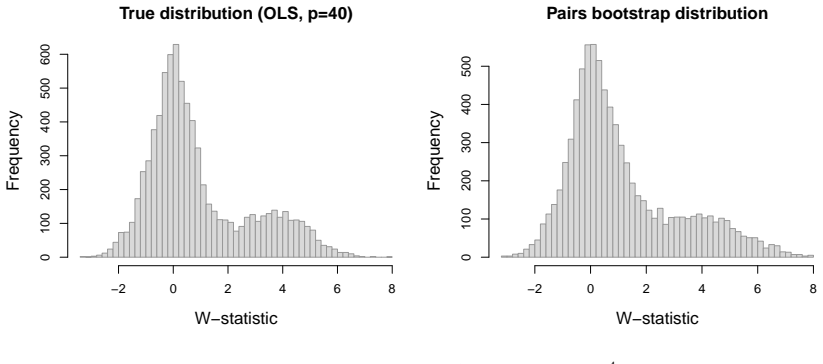

read the original abstract
This paper is concerned with estimating the local false discovery rate (lfdr) in a two-groups model where the only assumption regarding the null distribution is symmetry about zero. Our motivation comes from the contemporary framework for multiple hypothesis testing, particularly relevant in variable selection problems, which transforms any user-specified scores into statistics whose null distributions are symmetric about zero, whereas enrichment to the right of zero is generally expected for the non-nulls. While modern methods such as the knockoff filter (Barber and Candes; 2015) are able to exploit the null property for controlling the false discovery rate (FDR), an arguably more appropriate goal is to target control of the local false discovery rate for the rejected hypotheses, as proposed in Soloff et al. (2024) where the standard two-groups model (known $f_0$ and independence) is analyzed. Here, we take a step in this direction and propose to estimate the lfdr by targeting the surrogate density ratio $f(-w)/f(w)$, for $w>0$, where $f$ is the marginal density in the aforementioned ``stripped-down'' two-groups model. We study several estimators and propose a logistic regression based method with natural cubic spline basis. We also show that any consistent estimator of this surrogate yields asymptotic lfdr control of the multiple testing procedure that thresholds the estimate at the nominal level.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes estimating the local false discovery rate (lfdr) in a two-groups model under the sole assumption that the null distribution is symmetric about zero. It targets the surrogate ratio r(w) = f(-w)/f(w) for w > 0 (where f is the marginal density) rather than the lfdr directly, studies several estimators, and introduces a logistic regression estimator using natural cubic splines. The central claim is that any consistent estimator of this surrogate yields asymptotic lfdr control for the procedure that rejects when the estimated ratio falls below the nominal level.
Significance. If the asymptotic control result can be established rigorously, the contribution would be significant for multiple testing in settings such as knockoff-based variable selection, where only symmetry of the null is available. The surrogate approach avoids needing a fully specified null density, and the spline-based logistic estimator provides a practical, implementable method. The general consistency claim, if properly qualified, would broaden applicability beyond fully parametric nulls.
major comments (1)
- [Abstract] Abstract (central claim on asymptotic lfdr control): The assertion that 'any consistent estimator' of the surrogate r(w) = f(-w)/f(w) yields asymptotic lfdr control for the data-dependent thresholding procedure is load-bearing but appears incomplete. Pointwise consistency in probability at fixed w does not automatically guarantee that the proportion of rejected hypotheses with true lfdr exceeding the nominal level vanishes asymptotically, because the rejection set is random and depends on the estimator near the threshold. A precise statement of the required convergence mode (e.g., uniform consistency on a neighborhood of the cutoff or convergence in a norm controlling symmetric differences of level sets) together with the corresponding proof would be needed to substantiate the result.
minor comments (2)
- [Abstract] The abstract states that 'several estimators' are studied before proposing the logistic spline method, but provides no enumeration or comparison; adding a brief list or reference to the relevant section would improve clarity.
- The connection between the proposed surrogate and the lfdr control result in Soloff et al. (2024) is referenced but not expanded; a short paragraph contrasting the known-null case with the symmetry-only case would help readers follow the extension.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comment on the asymptotic lfdr control claim is well-taken and highlights an important technical point. We address it directly below and will revise the manuscript to strengthen the statement and supporting arguments.
read point-by-point responses
-
Referee: The assertion that 'any consistent estimator' of the surrogate r(w) = f(-w)/f(w) yields asymptotic lfdr control for the data-dependent thresholding procedure is load-bearing but appears incomplete. Pointwise consistency in probability at fixed w does not automatically guarantee that the proportion of rejected hypotheses with true lfdr exceeding the nominal level vanishes asymptotically, because the rejection set is random and depends on the estimator near the threshold. A precise statement of the required convergence mode (e.g., uniform consistency on a neighborhood of the cutoff or convergence in a norm controlling symmetric differences of level sets) together with the corresponding proof would be needed to substantiate the result.
Authors: We agree that the abstract statement is imprecise and that pointwise consistency alone is insufficient to control the random rejection set. The manuscript's theorem assumes consistency of the estimator in a mode that ensures the measure of the symmetric difference between the estimated and oracle level sets vanishes in probability (implicit in the proof via the continuous mapping theorem applied to the thresholded indicator). However, this mode is not stated explicitly in the abstract or highlighted in the main text. In the revision we will (i) replace the abstract claim with a precise statement requiring uniform consistency on compact neighborhoods of the threshold or L1 convergence of the level-set indicators, (ii) add a short paragraph in Section 3.3 spelling out the required convergence mode, and (iii) expand the proof sketch in the supplement to verify that the proportion of false rejections vanishes. These changes will be made without altering the core result. revision: yes
Circularity Check
Minor self-citation to prior work; central claim on surrogate consistency is independent
full rationale
The surrogate r(w) = f(-w)/f(w) is defined directly from the marginal density in the stripped-down two-groups model and is independent of the lfdr quantity. The paper states that it shows any consistent estimator of this surrogate yields asymptotic lfdr control, presenting this as a derivation within the current manuscript rather than reducing it to a prior result by construction. The citation to Soloff et al. (2024) supports only the motivation and the known-f0 case, not the load-bearing step for the unknown-null extension here. No self-definitional, fitted-input, or ansatz-smuggling patterns appear in the provided claims or equations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The null distribution is symmetric about zero in the two-groups model.
Reference graph
Works this paper leans on
-
[1]
2023 , institution =
Tibshirani, Ryan , title =. 2023 , institution =
2023
-
[2]
2012 , publisher=
Density ratio estimation in machine learning , author=. 2012 , publisher=
2012
-
[3]
Large-scale simultaneous hypothesis testing: the choice of a null hypothesis , author=. J. Amer. Statist. Assoc. , volume=. 2004 , publisher=
2004
-
[4]
Biometrika , pages=
A frequentist local false discovery rate , author=. Biometrika , pages=. 2026 , publisher=
2026
-
[5]
Electron
Arias-Castro, Ery and Chen, Shiyun , TITLE =. Electron. J. Stat. , FJOURNAL =. 2017 , NUMBER =
2017
-
[6]
arXiv preprint , volume=
Conformalized Multiple Testing under Unknown Null Distribution with Symmetric Errors , author=. arXiv preprint , volume=
-
[7]
Cand\`es, Emmanuel and Fan, Yingying and Janson, Lucas and Lv, Jinchi , TITLE =. J. R. Stat. Soc. Ser. B. Stat. Methodol. , FJOURNAL =. 2018 , NUMBER =
2018
-
[8]
Xia, Xintao and Cai, Zhanrui , TITLE =. J. Mach. Learn. Res. , FJOURNAL =. 2023 , PAGES =
2023
-
[9]
Controlling false discovery rate using
Xing, Xin and Zhao, Zhigen and Liu, Jun S , fjournal=. Controlling false discovery rate using. J. Amer. Statist. Assoc. , volume=
-
[10]
A Scale-Free Approach for False Discovery Rate Control in Generalized Linear Models , author =. J. Amer. Statist. Assoc. , volume =. 2023 , fjournal =
2023
-
[11]
, author=
Adaptive false discovery rate control under independence and dependence. , author=. Journal of Machine Learning Research , volume=
-
[12]
Conditional calibration for false discovery rate control under dependence , author=. Ann. Statist. , volume=. 2022 , publisher=
2022
-
[13]
Oracle and adaptive compound decision rules for false discovery rate control , author=. J. Amer. Statist. Assoc. , volume=. 2007 , publisher=
2007
-
[14]
The Annals of Applied Statistics , volume=
Replicability analysis for genome-wide association studies , author=. The Annals of Applied Statistics , volume=. 2014 , publisher=
2014
-
[15]
Proceedings of the Second Berkeley Symposium on Mathematical Statistics and Probability , year=
Asymptotically subminimax solutions of compound statistical decision problems , author=. Proceedings of the Second Berkeley Symposium on Mathematical Statistics and Probability , year=
-
[16]
Statistica Sinica , pages=
Generalized maximum likelihood estimation of normal mixture densities , author=. Statistica Sinica , pages=
-
[17]
The Annals of Mathematical Statistics , pages=
Consistency of the maximum likelihood estimator in the presence of infinitely many incidental parameters , author=. The Annals of Mathematical Statistics , pages=. 1956 , publisher=
1956
-
[18]
On the theory of mortality measurement:
Grenander, Ulf , journal=. On the theory of mortality measurement:. 1956 , publisher=
1956
-
[19]
NSF-CBMS regional conference series in probability and statistics , pages=
Mixture models: theory, geometry and applications , author=. NSF-CBMS regional conference series in probability and statistics , pages=. 1995 , organization=
1995
-
[20]
Convex optimization, shape constraints, compound decisions, and empirical
Koenker, Roger and Mizera, Ivan , fjournal=. Convex optimization, shape constraints, compound decisions, and empirical. J. Amer. Statist. Assoc. , volume=. 2014 , publisher=
2014
-
[21]
Soloff, J. A. , title =. GitHub repository , howpublished =. 2020 , publisher =
2020
-
[22]
Koenker, Roger and Gu, Jiaying , journal=
-
[23]
arXiv preprint arXiv:1810.07897 , year=
Two-component mixture model in the presence of covariates , author=. arXiv preprint arXiv:1810.07897 , year=
-
[24]
1972 , publisher=
Statistical inference under order restrictions; the theory and application of isotonic regression , author=. 1972 , publisher=
1972
-
[25]
Finite-sample confidence envelopes for shape-restricted densities , author=. Ann. Statist. , pages=. 1995 , publisher=
1995
-
[26]
The tight constant in the
Massart, Pascal , journal=. The tight constant in the. 1990 , publisher=
1990
-
[27]
Estimating the proportion of true null hypotheses, with application to
Langaas, Mette and Lindqvist, Bo Henry and Ferkingstad, Egil , fjournal=. Estimating the proportion of true null hypotheses, with application to. J. Roy. Statist. Soc. Ser. B , volume=. 2005 , publisher=
2005
-
[28]
Empirical
Efron, Bradley and Tibshirani, Robert and Storey, John D and Tusher, Virginia , fjournal=. Empirical. J. Amer. Statist. Assoc. , volume=. 2001 , publisher=
2001
-
[29]
Empirical
Efron, Bradley and Tibshirani, Robert , journal=. Empirical. 2002 , publisher=
2002
-
[30]
Controlling the false discovery rate: a practical and powerful approach to multiple testing , author=. J. Roy. Statist. Soc. Ser. B , FJOURNAL =
-
[31]
Lei, Lihua and Fithian, William , fjournal=. J. Roy. Statist. Soc. Ser. B , volume=. 2018 , publisher=
2018
-
[32]
Compound decision theory and empirical
Zhang, Cun-Hui , fjournal=. Compound decision theory and empirical. Ann. Statist. , volume=. 2003 , publisher=
2003
-
[33]
Bayes, oracle
Efron, Bradley , fjournal=. Bayes, oracle. Statist. Sci. , volume=. 2019 , publisher=
2019
-
[34]
Bayes and empirical
Tang, Weihua and Zhang, Cun-Hui , year=. Bayes and empirical
-
[35]
Weighted false discovery rate control in large-scale multiple testing , author=. J. Amer. Statist. Assoc. , volume=. 2018 , publisher=
2018
-
[36]
Operating characteristics and extensions of the false discovery rate procedure , author=. J. Roy. Statist. Soc. Ser. B , volume=. 2002 , publisher=
2002
-
[37]
-investing: a procedure for sequential control of expected false discoveries , author=. J. Roy. Statist. Soc. Ser. B , volume=. 2008 , publisher=
2008
-
[38]
A direct approach to false discovery rates , author=. J. Roy. Statist. Soc. Ser. B , volume=. 2002 , publisher=
2002
-
[39]
High-dimensional classification via nonparametric empirical
Dicker, Lee H and Zhao, Sihai D , journal=. High-dimensional classification via nonparametric empirical. 2016 , publisher=
2016
-
[40]
On the nonparametric maximum likelihood estimator for
Saha, Sujayam and Guntuboyina, Adityanand , fjournal=. On the nonparametric maximum likelihood estimator for. Ann. Statist. , volume=. 2020 , publisher=
2020
-
[41]
Biometrika , volume=
False discovery rates and copy number variation , author=. Biometrika , volume=. 2011 , publisher=
2011
-
[42]
Post-Selection Inference Following Aggregate Level Hypothesis Testing in Large-Scale Genomic Data , author=. J. Amer. Statist. Assoc. , volume=. 2018 , publisher=
2018
-
[43]
arXiv preprint arXiv:1808.00631 , year=
A Scan Procedure for Multiple Testing , author=. arXiv preprint arXiv:1808.00631 , year=
-
[44]
Large-scale multiple testing under dependence , author=. J. Roy. Statist. Soc. Ser. B , volume=. 2009 , publisher=
2009
-
[45]
Optimal control of false discovery criteria in the two-group model , author=. J. Roy. Statist. Soc. Ser. B , volume=. 2021 , publisher=
2021
-
[46]
Bayesians, frequentists, and scientists , author=. J. Amer. Statist. Assoc. , volume=. 2005 , publisher=
2005
-
[47]
arXiv preprint arXiv:1908.08444 , year=
Hierarchical Bayes Modeling for Large-Scale Inference , author=. arXiv preprint arXiv:1908.08444 , year=
arXiv 1908
-
[48]
Biostatistics , volume=
False discovery rates: a new deal , author=. Biostatistics , volume=. 2017 , publisher=
2017
-
[49]
Biometrical Journal , volume=
On the false discovery rate and expected type I errors , author=. Biometrical Journal , volume=. 2001 , publisher=
2001
-
[50]
Bioinformatics , volume=
Identifying differentially expressed genes using false discovery rate controlling procedures , author=. Bioinformatics , volume=. 2003 , publisher=
2003
-
[51]
arXiv preprint arXiv:2106.15743 , year=
BONuS: Multiple multivariate testing with a data-adaptive test statistic , author=. arXiv preprint arXiv:2106.15743 , year=
-
[52]
An improved
Simes, R John , journal=. An improved. 1986 , publisher=
1986
-
[53]
General maximum likelihood empirical Bayes estimation of normal means , author=. Ann. Statist. , volume=. 2009 , publisher=
2009
-
[54]
2009 , publisher=
Empirical processes with applications to statistics , author=. 2009 , publisher=
2009
-
[55]
1992 , publisher=
Poisson processes , author=. 1992 , publisher=
1992
-
[56]
1967 , publisher=
Renewal theory , author=. 1967 , publisher=
1967
-
[57]
Asymptotic minimaxity of false discovery rate thresholding for sparse exponential data , author=. Ann. Statist. , volume=. 2006 , publisher=
2006
-
[58]
Electronic Journal of Statistics , volume=
Contraction and uniform convergence of isotonic regression , author=. Electronic Journal of Statistics , volume=. 2019 , publisher=
2019
-
[59]
Order restricted statistical inference , author=
-
[60]
Nature methods , volume=
Data-driven hypothesis weighting increases detection power in genome-scale multiple testing , author=. Nature methods , volume=. 2016 , publisher=
2016
-
[61]
arXiv preprint arXiv:1701.05179 , year=
Covariate-powered weighted multiple testing with false discovery rate control , author=. arXiv preprint arXiv:1701.05179 , year=
-
[62]
Multiple testing with the structure-adaptive
Li, Ang and Barber, Rina Foygel , fjournal=. Multiple testing with the structure-adaptive. J. Roy. Statist. Soc. Ser. B , volume=. 2019 , publisher=
2019
-
[63]
Simultaneous testing of grouped hypotheses: Finding needles in multiple haystacks , author=. J. Amer. Statist. Assoc. , volume=. 2009 , publisher=
2009
-
[64]
The Annals of Mathematical Statistics , pages=
On the distribution of the number of successes in independent trials , author=. The Annals of Mathematical Statistics , pages=. 1956 , publisher=
1956
-
[65]
, TITLE =
Barber, Rina Foygel and Cand\`es, Emmanuel J. , TITLE =. Ann. Statist. , FJOURNAL =. 2015 , NUMBER =
2015
-
[66]
Excess mass estimates and tests for multimodality , author=. J. Amer. Statist. Assoc. , volume=. 1991 , publisher=
1991
-
[67]
Estimation of a convex density contour in two dimensions , author=. J. Amer. Statist. Assoc. , volume=. 1987 , publisher=
1987
-
[68]
Size, power and false discovery rates , author=. Ann. Statist. , volume=. 2007 , publisher=
2007
-
[69]
The American Statistician , volume=
Calibration of p-values for testing precise null hypotheses , author=. The American Statistician , volume=. 2001 , publisher=
2001
-
[70]
Conference Proceedings on the Frontiers of Statistical Scientific Theory & Industrial Applications (Vol
Using excess mass estimates to investigate the modality of a distribution , author=. Conference Proceedings on the Frontiers of Statistical Scientific Theory & Industrial Applications (Vol. II) , pages=
-
[71]
Proceedings of the National Academy of Sciences , volume=
The effectiveness of nudging: A meta-analysis of choice architecture interventions across behavioral domains , author=. Proceedings of the National Academy of Sciences , volume=. 2022 , publisher=
2022
-
[72]
2009 , publisher=
Nudge: Improving decisions about health, wealth, and happiness , author=. 2009 , publisher=
2009
-
[73]
Proceedings of the National Academy of Sciences , volume=
No evidence for nudging after adjusting for publication bias , author=. Proceedings of the National Academy of Sciences , volume=. 2022 , publisher=
2022
-
[74]
1961 , publisher=
The foundations of statistics reconsidered , author=. 1961 , publisher=
1961
-
[75]
2012 , publisher=
Large-scale inference: empirical Bayes methods for estimation, testing, and prediction , author=. 2012 , publisher=
2012
-
[76]
Appetite , volume=
The application of defaults to optimize parents' health-based choices for children , author=. Appetite , volume=. 2017 , publisher=
2017
-
[77]
Journal of the National Cancer Institute , volume=
Five years of tamoxifen--or more? , author=. Journal of the National Cancer Institute , volume=
-
[78]
Proceedings of the National Academy of Sciences , volume=
Reply to Maier et al., Szaszi et al., and Bakdash and Marusich: The present and future of choice architecture research , author=. Proceedings of the National Academy of Sciences , volume=. 2022 , publisher=
2022
-
[79]
Proceedings of the National Academy of Sciences , volume=
No reason to expect large and consistent effects of nudge interventions , author=. Proceedings of the National Academy of Sciences , volume=. 2022 , publisher=
2022
-
[80]
The Annals of Applied Statistics , volume=
Statistical methods for replicability assessment , author=. The Annals of Applied Statistics , volume=. 2020 , publisher=
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.