Evaluating Bias in Phoneme-Based Automatic Speech Recognition Systems: An Analysis of IPA Transcription Models
Pith reviewed 2026-06-27 10:14 UTC · model grok-4.3
The pith
IPA-based ASR models show performance disparities across languages and demographic groups that persist after allowing for similar phoneme substitutions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
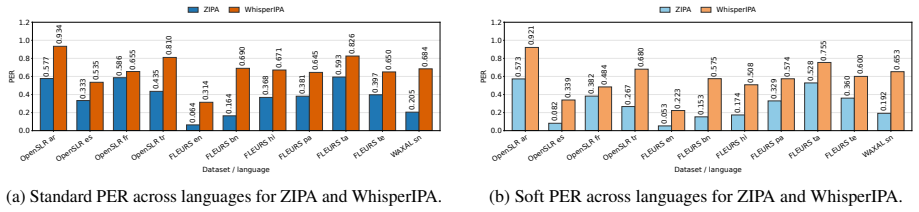
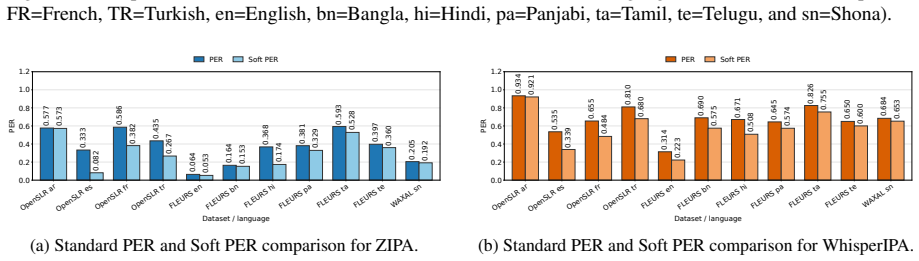
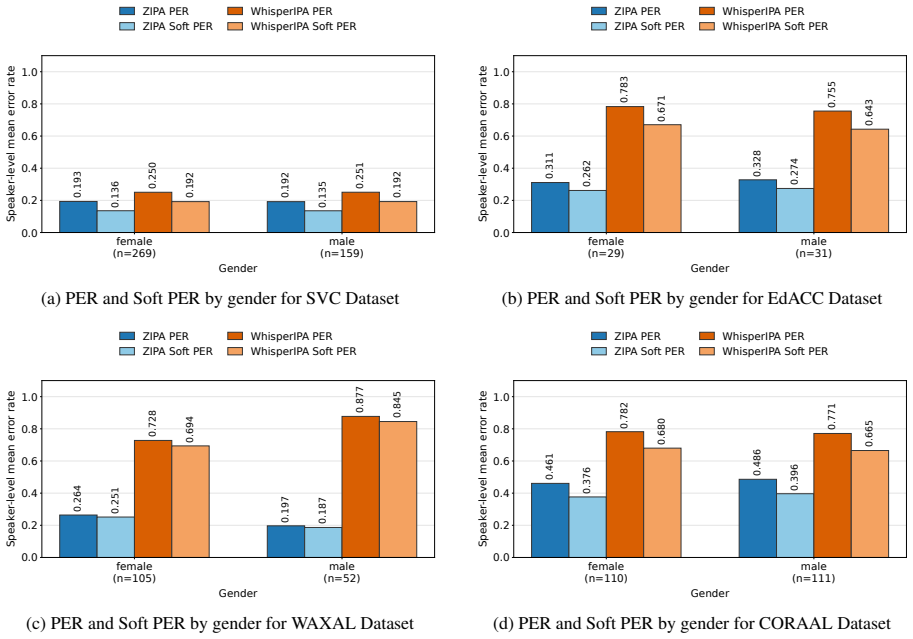
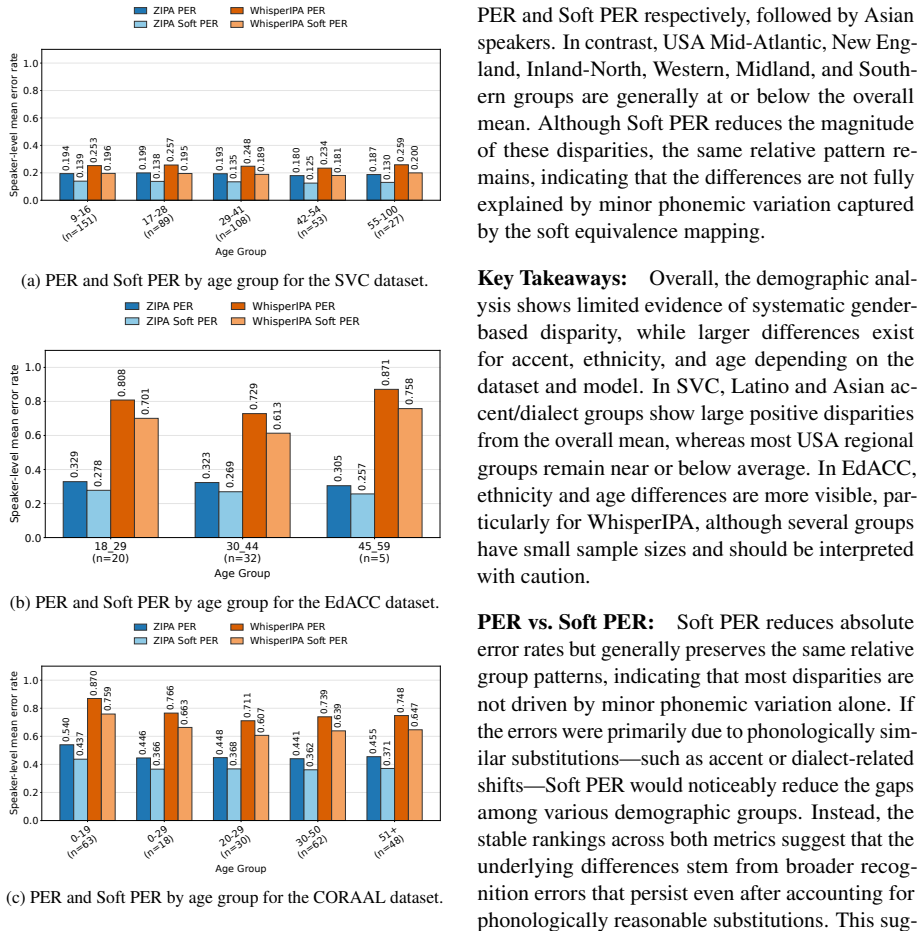
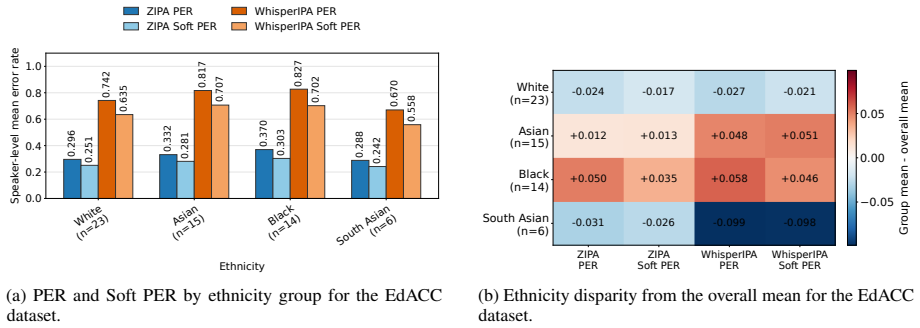
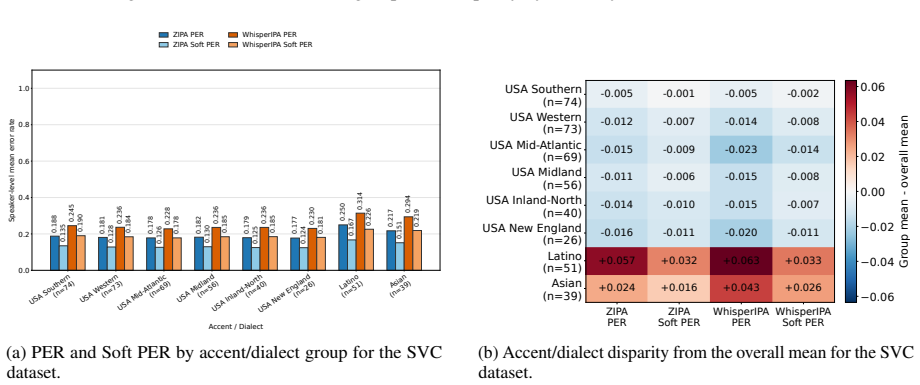
Our analysis examines how performance varies across languages and demographic groups such as gender, accent, ethnicity, and age, revealing persistent disparities even after accounting for acceptable phonemic variation.
What carries the argument
The Soft PER metric, which tolerates linguistically similar phoneme substitutions when scoring model IPA transcriptions against grapheme-to-phoneme reference outputs.
Load-bearing premise
The chosen grapheme-to-phoneme reference systems supply an unbiased and accurate ground truth, and the demographically annotated corpora contain representative samples without unmeasured selection effects.
What would settle it
Re-running the evaluation on the same models but with alternative G2P reference systems or on newly collected demographically balanced corpora that produces no statistically significant performance differences across the reported groups would falsify the claim of persistent disparities.
Figures
read the original abstract
The popularization of automatic speech recognition (ASR) systems has increased exploration of the demographic biases related to race, age, gender, and accent, often formed from imbalanced training data. Most of these studies focused on standard grapheme-based ASR systems with comparatively little emphasis on phoneme-based systems, such as models that produce International Phonetic Alphabet (IPA) representations. As ASR systems shift toward multilingual support and low-resource language modeling, IPA-based layers serve as a critical, language-agnostic foundation. In this study, we evaluate the performance of two state-of-the-art open-source ASR systems, WhisperIPA and ZIPA, that generate IPA transcriptions across diverse accents and language sources. Our evaluation includes existing multilingual speech corpora and demographically annotated English-language corpora. We measure model performance by comparing model-generated IPA transcriptions against grapheme-to-phoneme (G2P) systems using both standard phoneme error rate (PER) and a proposed Soft PER metric that tolerates linguistically similar phoneme substitutions. Our analysis examines how performance varies across languages and demographic groups such as gender, accent, ethnicity, and age, revealing persistent disparities even after accounting for acceptable phonemic variation. These findings provide insight into potential sources of bias and inform the development of more inclusive and linguistically robust phoneme-based ASR systems. Our code and data will be made publicly available to the community.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates bias in two open-source phoneme-based ASR systems (WhisperIPA and ZIPA) that produce IPA transcriptions. It compares model outputs against grapheme-to-phoneme (G2P) references on multilingual speech corpora and demographically annotated English corpora, using both standard phoneme error rate (PER) and a proposed Soft PER metric that tolerates linguistically similar substitutions. The central claim is that performance varies across languages and demographic groups (gender, accent, ethnicity, age), with persistent disparities remaining even after the Soft PER adjustment for acceptable phonemic variation. The authors position the work as informing more inclusive IPA-based ASR development and commit to releasing code and data.
Significance. If the reported disparities can be shown to reflect model behavior rather than reference or metric artifacts, the study would add to fairness research in speech technology by focusing on phoneme-based, language-agnostic systems that are increasingly used for multilingual and low-resource ASR. The Soft PER proposal is a methodological step forward, and the public data release would support reproducibility. The work is timely given the shift toward IPA layers in ASR.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: The claim of 'persistent disparities even after accounting for acceptable phonemic variation' rests on the assumption that G2P reference systems supply an unbiased ground truth. Standard G2P converters encode canonical or prestige pronunciations that systematically diverge from accented or demographically varied realizations; the Soft PER tolerance for 'linguistically similar' substitutions does not incorporate an explicit model of accent-induced variation (e.g., dialect rules or forced-alignment priors). This assumption is load-bearing for the central claim that observed PER/Soft PER gaps isolate model bias rather than reference mismatch.
- [Results] Results section: No sample sizes per demographic subgroup, confidence intervals, or statistical significance tests are reported for the claimed disparities. Without these quantities it is impossible to determine whether the reported differences across gender/accent/ethnicity/age are robust or could arise from sampling variation or unmeasured selection effects in the demographically annotated corpora.
minor comments (3)
- [Methods] The abstract lists the corpora only generically ('existing multilingual speech corpora and demographically annotated English-language corpora'); the Methods section should name the specific datasets, their sizes, and how demographic labels were obtained and validated.
- [Evaluation Metrics] Notation: Define 'Soft PER' formally (including the exact similarity criterion and substitution costs) in the first use rather than relying on the prose description.
- [Discussion] The manuscript should include a limitations paragraph addressing the possibility that G2P canonical bias affects all demographic groups unequally.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which identifies key areas for strengthening our analysis of bias in phoneme-based ASR. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: The claim of 'persistent disparities even after accounting for acceptable phonemic variation' rests on the assumption that G2P reference systems supply an unbiased ground truth. Standard G2P converters encode canonical or prestige pronunciations that systematically diverge from accented or demographically varied realizations; the Soft PER tolerance for 'linguistically similar' substitutions does not incorporate an explicit model of accent-induced variation (e.g., dialect rules or forced-alignment priors). This assumption is load-bearing for the central claim that observed PER/Soft PER gaps isolate model bias rather than reference mismatch.
Authors: We agree that G2P systems typically reflect canonical pronunciations and that our Soft PER does not explicitly encode accent-specific rules or forced-alignment priors. This is a valid limitation on interpreting absolute bias versus reference mismatch. However, the same G2P references are applied uniformly across all demographic groups and languages, so relative performance gaps remain informative about model behavior. We will revise the Evaluation and Discussion sections to explicitly acknowledge this assumption, add caveats on the scope of our claims, and note that future work could incorporate accent-aware references. This strengthens rather than undermines the central findings. revision: partial
-
Referee: [Results] Results section: No sample sizes per demographic subgroup, confidence intervals, or statistical significance tests are reported for the claimed disparities. Without these quantities it is impossible to determine whether the reported differences across gender/accent/ethnicity/age are robust or could arise from sampling variation or unmeasured selection effects in the demographically annotated corpora.
Authors: We accept this point. The current manuscript omits these details, which are necessary for assessing robustness. In the revised Results section we will report subgroup sample sizes, bootstrap confidence intervals for PER and Soft PER, and appropriate statistical tests (e.g., permutation or t-tests with multiple-comparison correction) for the demographic comparisons. This will allow readers to evaluate whether observed gaps exceed sampling variation. revision: yes
Circularity Check
No circularity: purely empirical evaluation
full rationale
The paper performs an empirical comparison of two IPA-based ASR systems (WhisperIPA and ZIPA) against G2P references on existing corpora, reporting PER and a defined Soft PER metric across demographic slices. No equations, derivations, fitted parameters presented as predictions, or self-citation chains appear in the abstract or described content. The central claim is an observational finding about performance disparities; it does not reduce to any input by construction. The skeptic concern addresses reference validity and metric assumptions, which is a question of external correctness rather than internal circularity in a derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , pages=
Error detection of grapheme-to-phoneme conversion in text-to-speech synthesis using speech signal and lexical context , author=. 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , pages=. 2017 , organization=
2017
-
[2]
2024 , eprint=
IPA Transcription of Bengali Texts , author=. 2024 , eprint=
2024
-
[3]
Journal of Memory and Language , volume=
Allophones, not phonemes in spoken-word recognition , author=. Journal of Memory and Language , volume=. 2018 , publisher=
2018
-
[4]
International Journal of Language & Communication Disorders , volume=
The agreement of phonetic transcriptions between paediatric speech and language therapists transcribing a disordered speech sample , author=. International Journal of Language & Communication Disorders , volume=. 2024 , publisher=
2024
-
[5]
Linguistics Vanguard , volume=
Assessing the accuracy of existing forced alignment software on varieties of British English , author=. Linguistics Vanguard , volume=. 2020 , publisher=
2020
-
[6]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Performance disparities between accents in automatic speech recognition (student abstract) , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[7]
ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Unveiling performance bias in asr systems: A study on gender, age, accent, and more , author=. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2025 , organization=
2025
-
[8]
doi:10.21437/Interspeech.2017-1746 , issn =
Rachael Tatman and Conner Kasten , year =. doi:10.21437/Interspeech.2017-1746 , issn =
-
[9]
Gender and Dialect Bias in Y ou T ube ' s Automatic Captions
Tatman, Rachael. Gender and Dialect Bias in Y ou T ube ' s Automatic Captions. Proceedings of the First ACL Workshop on Ethics in Natural Language Processing. 2017. doi:10.18653/v1/W17-1606
-
[10]
arXiv preprint arXiv:2502.18434 , year=
Exploring gender disparities in automatic speech recognition technology , author=. arXiv preprint arXiv:2502.18434 , year=
-
[11]
arXiv preprint arXiv:2510.22495 , year=
A Sociophonetic Analysis of Racial Bias in Commercial ASR Systems Using the Pacific Northwest English Corpus , author=. arXiv preprint arXiv:2510.22495 , year=
-
[12]
doi:10.21437/Interspeech.2025-1973 , issn =
Dana Serditova and Kevin Tang and Jochen Steffens , year =. doi:10.21437/Interspeech.2025-1973 , issn =
-
[13]
Linguistically Informed Tokenization Improves ASR for Underresourced Languages
Daul, Massimo Marie and Tosolini, Alessio and Bowern, Claire. Linguistically Informed Tokenization Improves ASR for Underresourced Languages. Proceedings of the Fifth Workshop on NLP Applications to Field Linguistics. 2026. doi:10.18653/v1/2026.fieldmatters-1.4
-
[14]
Sonos Voice Control Bias Assessment Dataset: A Methodology for Demographic Bias Assessment in Voice Assistants
Sekkat, Chloe and Leroy, Fanny and Mdhaffar, Salima and Smith, Blake Perry and Est \`e ve, Yannick and Dureau, Joseph and Coucke, Alice. Sonos Voice Control Bias Assessment Dataset: A Methodology for Demographic Bias Assessment in Voice Assistants. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and ...
2024
-
[15]
Version , volume=
The corpus of regional african american language , author=. Version , volume=
-
[16]
2026 , eprint=
Advanced Modeling of Interlanguage Speech Intelligibility Benefit with L1-L2 Multi-Task Learning Using Differentiable K-Means for Accent-Robust Discrete Token-Based ASR , author=. 2026 , eprint=
2026
-
[17]
Discovering phonetic inventories with crosslingual automatic speech recognition , journal =
Piotr Żelasko and Siyuan Feng and Laureano. Discovering phonetic inventories with crosslingual automatic speech recognition , journal =. 2022 , issn =. doi:https://doi.org/10.1016/j.csl.2022.101358 , url =
-
[18]
doi:10.21437/Interspeech.2025-593 , issn =
Kentaro Onda and Yosuke Kashiwagi and Emiru Tsunoo and Hayato Futami and Shinji Watanabe , year =. doi:10.21437/Interspeech.2025-593 , issn =
-
[19]
2020 , eprint=
That Sounds Familiar: an Analysis of Phonetic Representations Transfer Across Languages , author=. 2020 , eprint=
2020
-
[20]
Toward Responsible
Cunningham, Jay L and Adjagbodjou, Adinawa and Basoah, Jeffrey and Jawara, Jainaba and Kadoma, Kowe and Lewis, Aaleyah , booktitle=. Toward Responsible
-
[21]
2026 , eprint=
PRiSM: Benchmarking Phone Realization in Speech Models , author=. 2026 , eprint=
2026
-
[22]
doi:10.21437/Interspeech.2023-2584 , issn =
Chihiro Taguchi and Yusuke Sakai and Parisa Haghani and David Chiang , year =. doi:10.21437/Interspeech.2023-2584 , issn =
-
[23]
International Conference on Information and Communication Technology for Intelligent Systems , pages=
Automated International Phonetic Alphabet (IPA) Representation for Assamese Speech , author=. International Conference on Information and Communication Technology for Intelligent Systems , pages=. 2025 , organization=
2025
-
[24]
Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Using phoneme representations to build predictive models robust to asr errors , author=. Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[25]
The taste of IPA: Towards open-vocabulary keyword spotting and forced alignment in any language
Zhu, Jian and Yang, Changbing and Samir, Farhan and Islam, Jahurul. The taste of IPA: Towards open-vocabulary keyword spotting and forced alignment in any language. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/20...
-
[26]
ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Leveraging IPA and articulatory features as effective inductive biases for multilingual ASR training , author=. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2025 , organization=
2025
-
[27]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
ZIPA: A family of efficient models for multilingual phone recognition , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[28]
Listen, attend and spell: A neural network for large vocabulary conversational speech recognition , year=
Chan, William and Jaitly, Navdeep and Le, Quoc and Vinyals, Oriol , booktitle=. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition , year=
-
[29]
2020 , eprint=
Contextual RNN-T For Open Domain ASR , author=. 2020 , eprint=
2020
-
[30]
doi:10.21437/Interspeech.2022-10340 , issn =
Fangjun Kuang and Liyong Guo and Wei Kang and Long Lin and Mingshuang Luo and Zengwei Yao and Daniel Povey , year =. doi:10.21437/Interspeech.2022-10340 , issn =
-
[31]
Efficient Conformer-Based CTC Model for Intelligent Cockpit Speech Recognition , year=
Guo, Hanzhi and Chen, Yunshu and Xie, Xukang and Xu, Gaopeng and Guo, Wei , booktitle=. Efficient Conformer-Based CTC Model for Intelligent Cockpit Speech Recognition , year=
-
[32]
Advances in neural information processing systems , volume=
wav2vec 2.0: A framework for self-supervised learning of speech representations , author=. Advances in neural information processing systems , volume=
-
[33]
Proceedings of the 40th International Conference on Machine Learning , articleno =
Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[34]
Arun Babu and Changhan Wang and Andros Tjandra and Kushal Lakhotia and Qiantong Xu and Naman Goyal and Kritika Singh and Patrick. 2022 , booktitle =. doi:10.21437/Interspeech.2022-143 , issn =
-
[35]
Gale, Robert C. and Salem, Alexandra C. and Fergadiotis, Gerasimos and Bedrick, Steven. Mixed Orthographic/Phonemic Language Modeling: Beyond Orthographically Restricted Transformers ( BORT ). Proceedings of the 8th Workshop on Representation Learning for NLP (RepL4NLP 2023). 2023. doi:10.18653/v1/2023.repl4nlp-1.18
-
[36]
Evaluating Workflows for Creating Orthographic Transcripts for Oral Corpora by Transcribing from Scratch or Correcting ASR -Output
Gorisch, Jan and Schmidt, Thomas. Evaluating Workflows for Creating Orthographic Transcripts for Oral Corpora by Transcribing from Scratch or Correcting ASR -Output. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[37]
Fang, Anjie and Filice, Simone and Limsopatham, Nut and Rokhlenko, Oleg , title =. 2020 , isbn =. doi:10.1145/3397271.3401050 , booktitle =
-
[38]
Automated International Phonetic Alphabet (IPA) Representation for Assamese Speech
Devi, Kumari Jayashree and Sarma, Parismita. Automated International Phonetic Alphabet (IPA) Representation for Assamese Speech. ICT for Intelligent Systems. 2026
2026
-
[39]
arXiv preprint arXiv:2509.12647 , year=
PAC: Pronunciation-Aware Contextualized Large Language Model-based Automatic Speech Recognition , author=. arXiv preprint arXiv:2509.12647 , year=
-
[40]
, author=
Language identification on code-switching utterances using multiple cues. , author=. Interspeech , pages=
-
[41]
Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing , pages=
Learning to predict code-switching points , author=. Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing , pages=
2008
-
[42]
Oriental COCOSDA 2017 , pages=
AIShell-1: An Open-Source Mandarin Speech Corpus and A Speech Recognition Baseline , author=. Oriental COCOSDA 2017 , pages=
2017
-
[43]
2026 , eprint=
WAXAL: A Large-Scale Multilingual African Language Speech Corpus , author=. 2026 , eprint=
2026
-
[44]
arXiv preprint arXiv:2308.15710 , year=
Speech wikimedia: A 77 language multilingual speech dataset , author=. arXiv preprint arXiv:2308.15710 , year=
-
[45]
Proceedings of the twelfth language resources and evaluation conference , pages=
Artie bias corpus: An open dataset for detecting demographic bias in speech applications , author=. Proceedings of the twelfth language resources and evaluation conference , pages=
-
[46]
arXiv preprint arXiv:2408.12734 , year=
Towards measuring fairness in speech recognition: Fair-speech dataset , author=. arXiv preprint arXiv:2408.12734 , year=
-
[47]
Goriely, Z \'e bulon and Buttery, Paula. IPA CHILDES & G 2 P +: Feature-Rich Resources for Cross-Lingual Phonology and Phonemic Language Modeling. Proceedings of the 29th Conference on Computational Natural Language Learning. 2025. doi:10.18653/v1/2025.conll-1.33
-
[48]
Journal of Open Source Software , volume=
Phonemizer: Text to phones transcription for multiple languages in python , author=. Journal of Open Source Software , volume=
-
[49]
Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018) , year=
Epitran: Precision G2P for many languages , author=. Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018) , year=
2018
-
[50]
Taubert, Sebastian , title =. 2025 , version =. doi:10.5281/zenodo.15229718 , url =
-
[51]
2021 , url =
kfcd , title =. 2021 , url =
2021
-
[52]
Proceedings of the Twelfth Language Resources and Evaluation Conference , pages=
AlloVera: A multilingual allophone database , author=. Proceedings of the Twelfth Language Resources and Evaluation Conference , pages=
-
[53]
, author=
Montreal forced aligner: Trainable text-speech alignment using kaldi. , author=. Interspeech , volume=
-
[54]
Journal of Phonetics , volume=
Introducing parselmouth: A python interface to praat , author=. Journal of Phonetics , volume=. 2018 , publisher=
2018
-
[55]
The Edinburgh International Accents of English Corpus: Towards the Democratization of English ASR , year=
Sanabria, Ramon and Bogoychev, Nikolay and Markl, Nina and Carmantini, Andrea and Klejch, Ondrej and Bell, Peter , booktitle=. The Edinburgh International Accents of English Corpus: Towards the Democratization of English ASR , year=
-
[56]
arXiv preprint arXiv:2503.20212 , year=
Dolphin: A large-scale automatic speech recognition model for eastern languages , author=. arXiv preprint arXiv:2503.20212 , year=
-
[57]
2024 , eprint=
Anatomy of Industrial Scale Multilingual ASR , author=. 2024 , eprint=
2024
-
[58]
arXiv preprint arXiv:2511.09690 , year=
Omnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages , author=. arXiv preprint arXiv:2511.09690 , year=
-
[59]
Peng, Yifan and Sudo, Yui and Shakeel, Muhammad and Watanabe, Shinji. OWSM - CTC : An Open Encoder-Only Speech Foundation Model for Speech Recognition, Translation, and Language Identification. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.549
-
[60]
2023 , publisher =
ctaguchi , title =. 2023 , publisher =
2023
-
[61]
2025 , eprint=
POWSM: A Phonetic Open Whisper-Style Speech Foundation Model , author=. 2025 , eprint=
2025
-
[62]
2020 , publisher =
Facebook AI , title =. 2020 , publisher =
2020
-
[63]
2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , pages=
Exploring data augmentation in bias mitigation against non-native-accented speech , author=. 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , pages=. 2023 , organization=
2023
-
[64]
Speech Communication , volume=
Uneven success: automatic speech recognition and ethnicity-related dialects , author=. Speech Communication , volume=. 2022 , publisher=
2022
-
[65]
, author=
Understanding Racial Disparities in Automatic Speech Recognition: The Case of Habitual" be". , author=. Interspeech , pages=
-
[66]
Proceedings of the national academy of sciences , volume=
Racial disparities in automated speech recognition , author=. Proceedings of the national academy of sciences , volume=. 2020 , publisher=
2020
-
[67]
Proceedings of the 12th Workshop on NLP for Similar Languages, Varieties and Dialects , pages=
Adapting Whisper for regional dialects: Enhancing public services for vulnerable populations in the United Kingdom , author=. Proceedings of the 12th Workshop on NLP for Similar Languages, Varieties and Dialects , pages=
-
[68]
doi:10.21437/Interspeech.2022-836 , issn =
Yuanyuan Zhang and Yixuan Zhang and Bence Halpern and Tanvina Patel and Odette Scharenborg , year =. doi:10.21437/Interspeech.2022-836 , issn =
-
[69]
Applied Sciences , volume=
Automatic speech recognition (asr) systems for children: A systematic literature review , author=. Applied Sciences , volume=. 2022 , publisher=
2022
-
[70]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Hey, siri! why are you biased against women?(student abstract) , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[71]
A literature review , author=
Hey ASR system! Why aren’t you more inclusive? Automatic speech recognition systems’ bias and proposed bias mitigation techniques. A literature review , author=. International conference on human-computer interaction , pages=. 2022 , organization=
2022
-
[72]
arXiv preprint arXiv:2103.15122 , year=
Quantifying bias in automatic speech recognition , author=. arXiv preprint arXiv:2103.15122 , year=
-
[73]
International Conference on Learning Representations , volume=
Zipformer: A faster and better encoder for automatic speech recognition , author=. International Conference on Learning Representations , volume=
-
[74]
2021 , eprint=
MediaSpeech: Multilanguage ASR Benchmark and Dataset , author=. 2021 , eprint=
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.