TAROT: Task-Adaptive Refinement of LLM-prior Graphs for Few-shot Tabular Learning
Pith reviewed 2026-06-27 11:07 UTC · model grok-4.3
The pith
Refining LLM-inferred feature relationship graphs task-adaptively improves prediction in few-shot tabular learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TAROT encodes heterogeneous tabular data into unified node semantic representations via USTNE, prompts LLMs to infer semantic relationships from task description and feature names to form an initial graph, applies Task-adaptive Semantic Graph Refinement to remove spurious edges and add task-related ones so the structure aligns with the supervised objective, and finally runs a GNN that performs message passing over the refined graph to capture task-related semantic dependencies for prediction.
What carries the argument
Task-adaptive Semantic Graph Refinement, which prunes spurious or task-unrelated edges and adds missing task-related ones to align an LLM-constructed semantic graph with the downstream supervised objective.
If this is right
- Superior performance on various few-shot tabular learning benchmarks relative to existing traditional and LLM-based methods.
- Avoidance of additional training on unlabeled or generated data and the associated computational overhead.
- Mitigation of privacy and compliance concerns that arise when raw tabular rows are fed directly to LLMs.
- Explicit capture of semantic feature interactions through the refined graph structure in data-scarce regimes.
Where Pith is reading between the lines
- The same refinement logic might transfer to other domains where an LLM supplies an initial graph that must be aligned to a downstream loss.
- If refinement proves to be the dominant contributor, simpler non-LLM graph-construction heuristics paired with the same adaptation step could achieve comparable gains.
- The framework could be tested in semi-supervised tabular regimes beyond strict few-shot by reusing the same task-adaptive graph prior.
- Scalability experiments on wider feature sets would clarify whether the LLM prompting cost remains acceptable as dimensionality grows.
Load-bearing premise
The assumption that LLM-inferred semantic relationships between features, once refined by task-adaptive pruning and addition of edges, will reliably align with the downstream supervised objective and reduce rather than add structural noise.
What would settle it
A controlled ablation on the same few-shot tabular benchmarks in which removing the refinement step or replacing the LLM graph with random edges causes TAROT accuracy to fall below standard non-graph baselines.
Figures




read the original abstract
Few-shot tabular learning provides a cost-effective approach for real-world applications where annotation is costly and collecting sufficient samples for new tasks is difficult. Existing Traditional and LLM-based methods have demonstrated effectiveness in few-shot scenarios. However, traditional methods need additional training on unlabeled or generated data, which incur significant computational overhead. In addition, LLM-based methods that directly feed raw tabular data into LLMs raise privacy and compliance concerns. More importantly, both paradigms largely overlook the semantic relationships between features, which provide structural and semantic prior for constructing a semantic graph. Semantic graph is essential for modeling meaningful feature interactions in few-shot scenarios. In this paper, we propose TAROT, a GNN-based framework that encodes the structural and semantic prior by constructing and refining a task-adaptive semantic graph from this prior, thereby improving predictive performance in few-shot tabular learning. TAROT first encodes heterogeneous tabular data into unified node semantic representations via a Unified Semantic Tabular Node Encoder (USTNE). Then, it prompts LLMs to infer the semantic relationship between features based on the task description and feature names to construct a semantic graph. To mitigate structural noise introduced by the hallucination of LLMs, TAROT introduces Task-adaptive Semantic Graph Refinement that prunes spurious or task-unrelated edges and adds missing task-related ones, aligning the graph structure with the downstream objective. Finally, a GNN performs message passing over the refined graph to capture task-related semantic dependencies for prediction. Extensive experiments on various few-shot tabular learning benchmarks demonstrate the superior performance of TAROT, establishing it as a state-of-the-art approach in this domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TAROT, a GNN-based framework for few-shot tabular learning. It first encodes heterogeneous tabular data into unified node semantic representations via USTNE, prompts LLMs to infer semantic relationships between features from task descriptions and feature names to build an initial semantic graph, applies Task-adaptive Semantic Graph Refinement to prune spurious edges and add missing ones to align with the downstream objective, and finally performs GNN message passing over the refined graph for prediction. The central claim is that this yields superior performance on few-shot tabular benchmarks and establishes a new state-of-the-art.
Significance. If the refinement step reliably reduces LLM-induced structural noise without introducing overfitting to the scarce labels, the approach would address key limitations of prior work: it avoids the computational cost of additional unlabeled/generated data required by traditional methods and the privacy risks of feeding raw tabular data directly to LLMs, while explicitly incorporating semantic feature relationships that most existing methods overlook.
major comments (2)
- [Abstract] Abstract: the performance claim ('extensive experiments on various few-shot tabular learning benchmarks demonstrate the superior performance of TAROT, establishing it as a state-of-the-art approach') is stated without any quantitative results, dataset names, baseline comparisons, ablation studies, or error bars. This absence makes the central empirical claim impossible to evaluate and is load-bearing for the contribution.
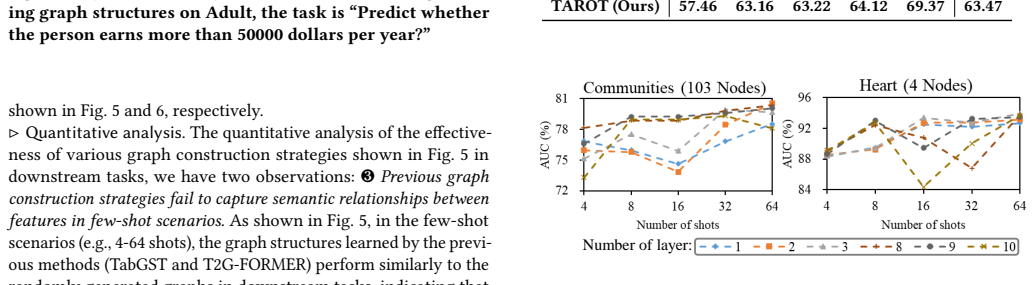
- [Task-adaptive Semantic Graph Refinement] Description of Task-adaptive Semantic Graph Refinement (abstract and §3): the mechanism is described only at high level ('prunes spurious or task-unrelated edges and adds missing task-related ones, aligning the graph structure with the downstream objective'). No equations, algorithm, or pseudocode specify how pruning/addition decisions are made or whether they consult the few-shot labels; without this, the risk that refinement overfits the tiny labeled set (rather than recovering stable semantics) cannot be assessed and directly undermines the noise-reduction claim.
minor comments (1)
- [Abstract] Abstract: the acronym USTNE is introduced without expanding what 'unified' means or how heterogeneous feature types are handled.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify how to strengthen the presentation of our empirical claims and methodological details. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claim ('extensive experiments on various few-shot tabular learning benchmarks demonstrate the superior performance of TAROT, establishing it as a state-of-the-art approach') is stated without any quantitative results, dataset names, baseline comparisons, ablation studies, or error bars. This absence makes the central empirical claim impossible to evaluate and is load-bearing for the contribution.
Authors: We agree that the abstract would be strengthened by including quantitative support for the performance claim. In the revised version we will incorporate specific metrics (e.g., average accuracy gains), the names of the primary benchmarks, key baseline comparisons, and mention of error bars from the experimental tables. revision: yes
-
Referee: [Task-adaptive Semantic Graph Refinement] Description of Task-adaptive Semantic Graph Refinement (abstract and §3): the mechanism is described only at high level ('prunes spurious or task-unrelated edges and adds missing task-related ones, aligning the graph structure with the downstream objective'). No equations, algorithm, or pseudocode specify how pruning/addition decisions are made or whether they consult the few-shot labels; without this, the risk that refinement overfits the tiny labeled set (rather than recovering stable semantics) cannot be assessed and directly undermines the noise-reduction claim.
Authors: The current manuscript presents the refinement at a high level in both the abstract and §3. We will add explicit equations, a formal algorithm, and pseudocode in §3.3 that detail the edge-pruning and edge-addition criteria. These criteria combine LLM-derived semantic scores with a task-specific validation loss computed on a small held-out portion of the few-shot labels; the validation split is used precisely to mitigate direct overfitting to the training labels. We will also expand the discussion of this design choice and its safeguards against label overfitting. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and text describe a procedural GNN framework: USTNE for node encoding, LLM prompting to build an initial semantic graph from feature names and task description, followed by task-adaptive pruning/addition of edges, then message passing. No equations, fitted parameters presented as predictions, uniqueness theorems, or self-citation chains appear. Claims rest on empirical benchmarks rather than any reduction of outputs to inputs by construction. This is the expected non-finding for a methods paper without mathematical derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
Pith/arXiv arXiv 2023
-
[2]
Chenxin An, Jun Zhang, Ming Zhong, Lei Li, Shansan Gong, Yao Luo, Jingjing Xu, and Lingpeng Kong. 2024. Why does the effective context length of LLMs fall short?arXiv preprint arXiv:2410.18745(2024)
arXiv 2024
-
[3]
Arthur Asuncion, David Newman, et al. 2007. UCI machine learning repository
2007
-
[4]
Dara Bahri, Heinrich Jiang, Yi Tay, and Donald Metzler. 2021. Scarf: Self- supervised contrastive learning using random feature corruption.arXiv preprint arXiv:2106.15147(2021)
arXiv 2021
-
[5]
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. 2023. Sparks of artificial general intelligence: Early experiments with gpt-4.arXiv preprint arXiv:2303.12712(2023)
Pith/arXiv arXiv 2023
-
[6]
Longbing Cao. 2022. Ai in finance: challenges, techniques, and opportunities. ACM Computing Surveys (CSUR)55, 3 (2022), 1–38
2022
-
[7]
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert- Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. 2021. Extracting training data from large language models. In30th USENIX security symposium (USENIX Security 21). 2633–2650
2021
-
[8]
Wei-Yu Chen, Yen-Cheng Liu, Zsolt Kira, Yu-Chiang Frank Wang, and Jia- Bin Huang. 2019. A closer look at few-shot classification.arXiv preprint arXiv:1904.04232(2019)
arXiv 2019
-
[9]
Jillian M Clements, Di Xu, Nooshin Yousefi, and Dmitry Efimov. 2020. Sequential deep learning for credit risk monitoring with tabular financial data.arXiv preprint arXiv:2012.15330(2020)
arXiv 2020
-
[10]
Enyan Dai, Wei Jin, Hui Liu, and Suhang Wang. 2022. Towards robust graph neural networks for noisy graphs with sparse labels. InProceedings of the fifteenth ACM international conference on web search and data mining. 181–191
2022
-
[11]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
-
[12]
Hanyu Duan, Yi Yang, and Kar Yan Tam. 2024. Do LLMs Know about Hallu- cination? An Empirical Investigation of LLM’s Hidden States.arXiv preprint arXiv:2402.09733(2024)
arXiv 2024
-
[13]
S.E. Golovenkin, V.A. Shulman, D.A. Rossiev, P.A. Shesternya, S.Yu. Nikulina, Yu.V. Orlova, and V.F. Voino-Yasenetsky. 2020. Myocardial infarction complications. UCI Machine Learning Repository. DOI: https://doi.org/10.24432/C53P5M
-
[14]
Xiawei Guo, Yuhan Quan, Huan Zhao, Quanming Yao, Yong Li, and Weiwei Tu
-
[15]
Tabgnn: Multiplex graph neural network for tabular data prediction.arXiv preprint arXiv:2108.09127(2021)
arXiv 2021
-
[16]
Sungwon Han, Jinsung Yoon, Sercan O Arik, and Tomas Pfister. 2024. Large Language Models Can Automatically Engineer Features for Few-Shot Tabular Learning.arXiv preprint arXiv:2404.09491(2024)
arXiv 2024
-
[17]
Stefan Hegselmann, Alejandro Buendia, Hunter Lang, Monica Agrawal, Xiaoyi Jiang, and David Sontag. 2023. Tabllm: Few-shot classification of tabular data with large language models. InInternational Conference on Artificial Intelligence and Statistics. PMLR, 5549–5581
2023
-
[18]
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. 2023. TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second. InThe Eleventh International Conference on Learning Representations
2023
-
[19]
Yufang Hou, Alessandra Pascale, Javier Carnerero-Cano, Tigran Tchrakian, Radu Marinescu, Elizabeth Daly, Inkit Padhi, and Prasanna Sattigeri. 2024. Wikicon- tradict: A benchmark for evaluating llms on real-world knowledge conflicts from wikipedia.Advances in Neural Information Processing Systems37 (2024), 109701–109747
2024
-
[20]
Yujia Hu, Tuan-Phong Nguyen, Shrestha Ghosh, and Simon Razniewski. 2025. Enabling LLM knowledge analysis via extensive materialization. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 16189–16202
2025
-
[21]
Arlind Kadra, Marius Lindauer, Frank Hutter, and Josif Grabocka. 2021. Well- tuned simple nets excel on tabular datasets.Advances in neural information processing systems34 (2021), 23928–23941
2021
-
[22]
Siwon Kim, Sangdoo Yun, Hwaran Lee, Martin Gubri, Sungroh Yoon, and Seong Joon Oh. 2023. Propile: Probing privacy leakage in large language models. Advances in Neural Information Processing Systems36 (2023), 20750–20762
2023
-
[23]
Philippe Laban, Wojciech Kryściński, Divyansh Agarwal, Alexander Richard Fabbri, Caiming Xiong, Shafiq Joty, and Chien-Sheng Wu. 2023. SummEdits: Measuring LLM ability at factual reasoning through the lens of summarization. InProceedings of the 2023 conference on empirical methods in natural language processing. 9662–9676
2023
-
[24]
Yingji Li, Mengnan Du, Rui Song, Xin Wang, Mingchen Sun, and Ying Wang
-
[25]
Mitigating social biases of pre-trained language models via contrastive self-debiasing with double data augmentation.Artificial Intelligence332 (2024), 104143
2024
-
[26]
Jay Chiehen Liao and Cheng-Te Li. 2023. TabGSL: Graph structure learning for tabular data prediction.arXiv preprint arXiv:2305.15843(2023)
arXiv 2023
-
[27]
Ruoxue Liu, Linjiajie Fang, Wenjia Wang, and Bingyi Jing. 2024. D2R2: Diffusion- based Representation with Random Distance Matching for Tabular Few-shot Learning. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[28]
Aya A Mitani and Sebastien Haneuse. 2020. Small data challenges of studying rare diseases.JAMA network open3, 3 (2020), e201965–e201965
2020
-
[29]
M Rubaiyat Hossain Mondal, Subrato Bharati, Prajoy Podder, and Priya Podder
-
[30]
Data analytics for novel coronavirus disease.informatics in medicine unlocked20 (2020), 100374
2020
-
[31]
Jaehyun Nam, Jihoon Tack, Kyungmin Lee, Hankook Lee, and Jinwoo Shin. 2023. STUNT: Few-shot Tabular Learning with Self-generated Tasks from Unlabeled Tables. InThe Eleventh International Conference on Learning Representations
2023
-
[32]
Boris Oreshkin, Pau Rodríguez López, and Alexandre Lacoste. 2018. Tadam: Task dependent adaptive metric for improved few-shot learning.Advances in neural information processing systems31 (2018)
2018
-
[33]
Zhimao Peng, Zechao Li, Junge Zhang, Yan Li, Guo-Jun Qi, and Jinhui Tang
-
[34]
InProceedings of the IEEE/CVF international conference on computer vision
Few-shot image recognition with knowledge transfer. InProceedings of the IEEE/CVF international conference on computer vision. 441–449
-
[35]
Gabrijela Perković, Antun Drobnjak, and Ivica Botički. 2024. Hallucinations in llms: Understanding and addressing challenges. In2024 47th MIPRO ICT and Electronics Convention (MIPRO). IEEE, 2084–2088
2024
-
[36]
G Elizabeth Rani, M Sakthimohan, M Navaneethakrishnan, S Mahendran, S Dhivya, and M Jayaprakash. 2023. Amazon Employee Access System using Machine Learning Algorithms. In2023 International Conference on Intelligent Systems for Communication, IoT and Security (ICISCoIS). IEEE, 417–421
2023
-
[37]
Frank Seide, Gang Li, Xie Chen, and Dong Yu. 2011. Feature engineering in context-dependent deep neural networks for conversational speech transcription. In2011 IEEE Workshop on Automatic Speech Recognition & Understanding. IEEE, 24–29
2011
-
[38]
K Shailaja, Banoth Seetharamulu, and MA Jabbar. 2018. Machine learning in healthcare: A review. In2018 Second international conference on electronics, com- munication and aerospace technology (ICECA). IEEE, 910–914
2018
-
[39]
Dylan Slack and Sameer Singh. 2023. Tablet: Learning from instructions for tabular data.arXiv preprint arXiv:2304.13188(2023)
arXiv 2023
-
[40]
Jake Snell, Kevin Swersky, and Richard Zemel. 2017. Prototypical networks for few-shot learning.Advances in neural information processing systems30 (2017)
2017
-
[41]
Joaquin Vanschoren, Jan N Van Rijn, Bernd Bischl, and Luis Torgo. 2014. OpenML: networked science in machine learning.ACM SIGKDD Explorations Newsletter 15, 2 (2014), 49–60
2014
-
[42]
Xingchen Wan, Ruoxi Sun, Hanjun Dai, Sercan Arik, and Tomas Pfister. 2023. Better zero-shot reasoning with self-adaptive prompting. InFindings of the Asso- ciation for Computational Linguistics: ACL 2023. 3493–3514. KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. Ruxue Shi, Yili Wang, Mengnan Du, Hangting Ye, Yi Chang and Xin Wang
2023
-
[43]
Bo Wang, Tao Shen, Guodong Long, Tianyi Zhou, Ying Wang, and Yi Chang
-
[44]
InProceedings of the Web Conference 2021
Structure-augmented text representation learning for efficient knowledge graph completion. InProceedings of the Web Conference 2021. 1737–1748
2021
-
[45]
Xindi Wang, Mahsa Salmani, Parsa Omidi, Xiangyu Ren, Mehdi Rezagholizadeh, and Armaghan Eshaghi. 2024. Beyond the limits: A survey of techniques to extend the context length in large language models.arXiv preprint arXiv:2402.02244 (2024)
arXiv 2024
-
[46]
Yaqing Wang, Quanming Yao, James T Kwok, and Lionel M Ni. 2020. Generalizing from a few examples: A survey on few-shot learning.ACM computing surveys (csur)53, 3 (2020), 1–34
2020
-
[47]
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al
-
[48]
Emergent abilities of large language models.arXiv preprint arXiv:2206.07682 (2022)
Pith/arXiv arXiv 2022
-
[49]
Jiahuan Yan, Jintai Chen, Yixuan Wu, Danny Z Chen, and Jian Wu. 2023. T2g- former: organizing tabular features into relation graphs promotes heterogeneous feature interaction. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 10720–10728
2023
-
[50]
Yifan Yao, Jinhao Duan, Kaidi Xu, Yuanfang Cai, Zhibo Sun, and Yue Zhang. 2024. A survey on large language model (llm) security and privacy: The good, the bad, and the ugly.High-Confidence Computing4, 2 (2024), 100211
2024
-
[51]
I-Cheng Yeh, King-Jang Yang, and Tao-Ming Ting. 2009. Knowledge discovery on RFM model using Bernoulli sequence.Expert Systems with applications36, 3 (2009), 5866–5871. A Algorithm of TAROT Table 5: Prompt𝑝used by TAROT of Adult dataset. Meta Information𝑝 𝑚𝑒𝑡𝑎 Task objective: Does this person earn more than 50000 dollars per year? features descriptions: a...
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.