STCC: A Unified Source-Channel Semantic Token Coding Framework for Semantic Communications
Pith reviewed 2026-06-27 08:17 UTC · model grok-4.3
The pith
A residual MLP encoder learns channel constellations that align noise with semantic token similarities, converting errors into drift rather than random failure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Semantic Token Codec accepts discrete tokens, uses a residual MLP encoder to learn geometrically structured constellations via a triple-loss objective, and thereby forces channel topology to align with the semantic embedding space so that channel noise produces topological errors (Semantic Drift in symbolic modalities, Structural Distortion in perceptual modalities) rather than random corruption.
What carries the argument
The Semantic Token Codec (STC), a residual MLP-based encoder trained with a triple-loss objective that produces geometrically structured constellations aligned to the semantic embedding space.
If this is right
- Channel noise is converted into semantic variations instead of catastrophic random token errors.
- Performance gains appear in low-SNR regimes compared with traditional fixed-constellation systems.
- The transmitter-side mapping works without any change to the receiver or the foundation model itself.
Where Pith is reading between the lines
- If the alignment holds, the same encoder could be retrained on new token vocabularies without redesigning the physical layer.
- The topological-error view suggests that error-correcting codes could be replaced or augmented by semantic-distance metrics in the embedding space.
- Extending the approach to time-varying channels would require checking whether the learned geometry remains stable when the noise statistics change.
Load-bearing premise
A residual MLP encoder trained with a triple-loss objective can generate constellations whose geometry aligns channel topology with the semantic embedding space of foundation models while remaining compatible with them.
What would settle it
An experiment in which additive channel noise applied to the learned constellations produces token errors that are no more semantically similar than errors from a random fixed constellation would falsify the alignment claim.
Figures

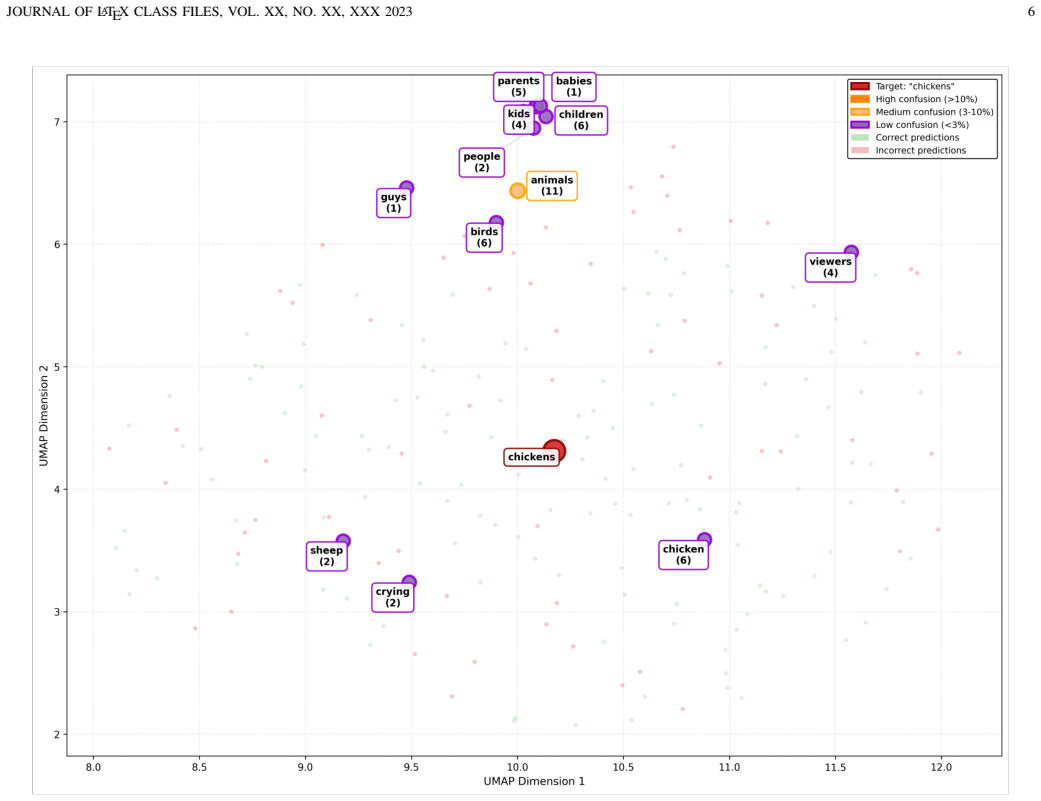
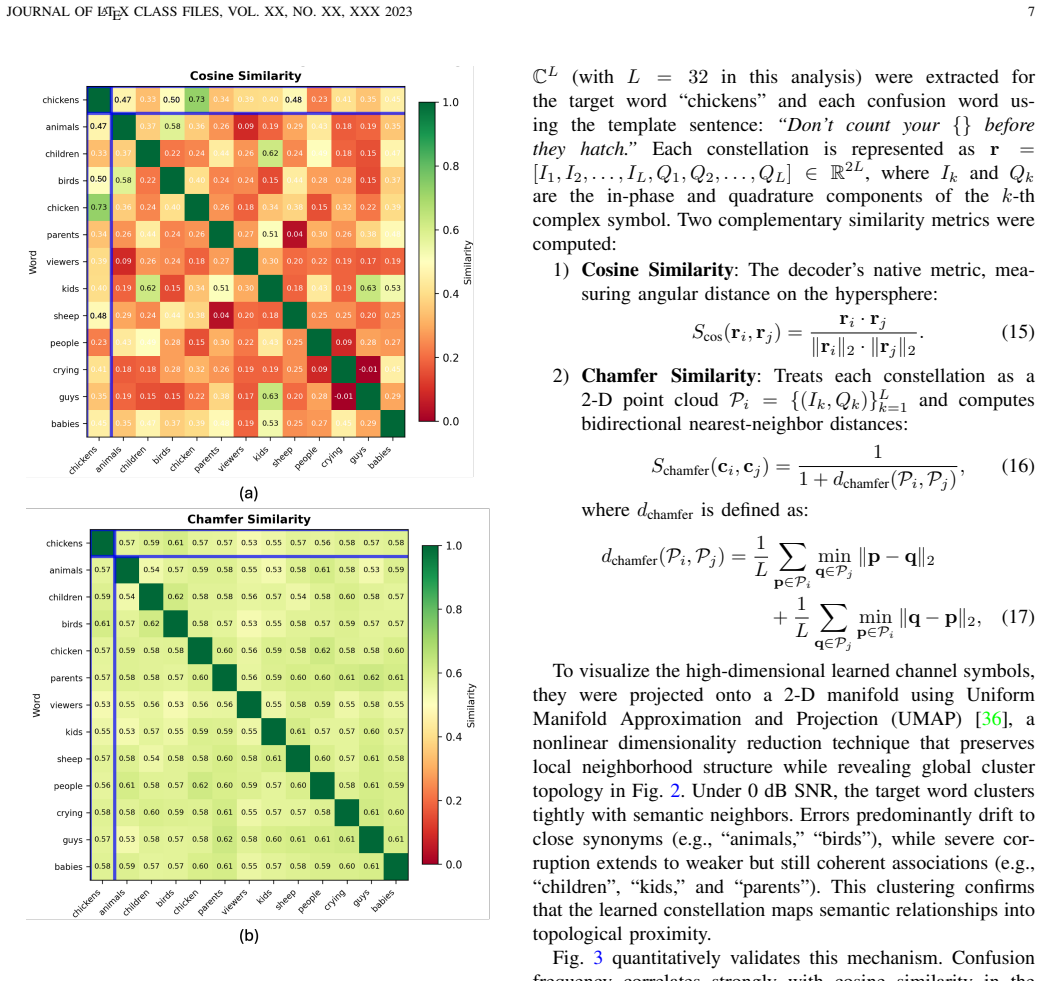



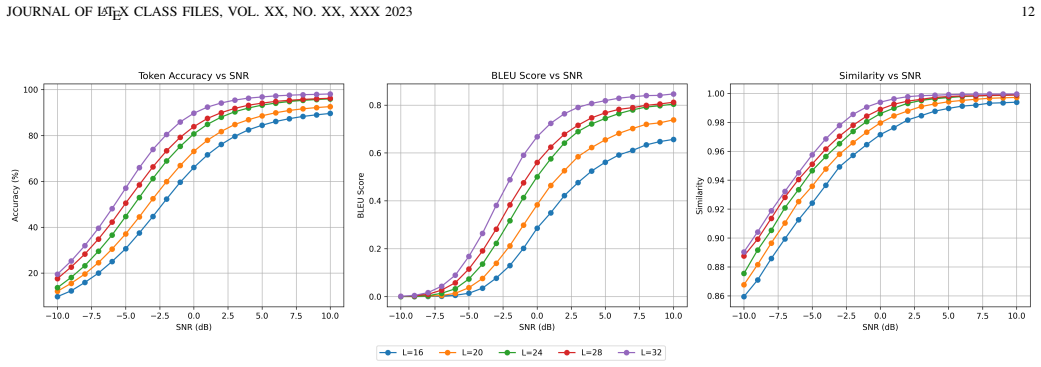
read the original abstract
Deep Joint Source-Channel Coding (JSCC) has emerged as a promising paradigm for overcoming the ``cliff effect" in wireless communications. However, existing Deep JSCC frameworks operate directly on raw analog data such as image pixels rather than the discrete semantic tokens that foundation models require. Moreover, traditional systems employ fixed, hand-designed constellations that treat all tokens equally, leading to catastrophic random errors under channel noise. In this paper, the Semantic Token Codebook Communication (STCC) is proposed as a unified source-channel semantic token coding framework designed to transmit the discrete semantic tokens of foundation models over noisy channels. The core of STCC is the Semantic Token Codec (STC). It accepts discrete tokens as input, which maintains compatibility with foundation models while employing a residual multiple layer perceptron, i.e., MLP-based encoder that learns geometrically structured constellations optimized with a triple-loss objective. This learned mapping forces the channel topology to align with the semantic embedding space, ensuring that channel noise results in topological errors rather than random corruption. This phenomenon is theoretically and empirically characterized, identifying ``Semantic Drift" in symbolic modalities and ``Structural Distortion" in perceptual modalities, where errors shift predictions to semantically or structurally similar tokens. Extensive experiments demonstrate that STCC significantly outperforms traditional systems in low-SNR regimes, effectively converting channel noise into semantic variations without requiring receiver-side modification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Semantic Token Codebook Communication (STCC) framework as a unified source-channel coding approach for transmitting discrete semantic tokens from foundation models over noisy wireless channels. The core Semantic Token Codec (STC) employs a residual MLP-based encoder trained via a triple-loss objective to produce geometrically structured constellations; this is claimed to align channel topology with the semantic embedding space so that additive noise produces only local topological errors (termed Semantic Drift in symbolic modalities and Structural Distortion in perceptual modalities) rather than random corruption. The work asserts both theoretical characterization of these error types and empirical superiority over traditional fixed-constellation systems in low-SNR regimes while preserving compatibility with foundation-model token pipelines.
Significance. If the claimed alignment mechanism and error characterizations hold, the framework could meaningfully advance semantic communications by enabling direct transmission of discrete tokens from large models without analog pixel-level processing or receiver-side changes, potentially converting channel impairments into semantically coherent variations. This addresses a recognized gap between deep JSCC and token-based AI systems and may improve reliability in challenging wireless conditions.
major comments (2)
- [Abstract] Abstract: The central claim that the triple-loss objective 'forces the channel topology to align with the semantic embedding space' is unsupported because no explicit loss terms, distance-preservation regularizers, or derivations are provided showing that constellation geometry is regressed or contrasted against foundation-model embedding distances. Without such a term the observed error patterns could arise from generic rate-distortion or clustering optimization rather than the asserted topological alignment, rendering the Semantic Drift / Structural Distortion characterization load-bearing but unsubstantiated.
- [Abstract] Abstract: The manuscript states that the error phenomenon is 'theoretically and empirically characterized' yet supplies neither the theoretical analysis (e.g., any distance or topology metric) nor quantitative experimental results (performance curves, tables, or SNR comparisons) needed to evaluate whether the triple-loss actually produces the claimed structured constellations or outperforms baselines.
minor comments (1)
- [Abstract] Abstract: The description of the residual MLP encoder and triple-loss objective would benefit from at least a high-level equation or component breakdown to clarify how compatibility with discrete tokens is maintained.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and have revised the abstract to better substantiate the claims while preserving the high-level nature of the summary.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the triple-loss objective 'forces the channel topology to align with the semantic embedding space' is unsupported because no explicit loss terms, distance-preservation regularizers, or derivations are provided showing that constellation geometry is regressed or contrasted against foundation-model embedding distances. Without such a term the observed error patterns could arise from generic rate-distortion or clustering optimization rather than the asserted topological alignment, rendering the Semantic Drift / Structural Distortion characterization load-bearing but unsubstantiated.
Authors: The abstract is intentionally concise. The triple-loss objective is explicitly defined in Section 3.2, consisting of a reconstruction term, a robustness term under channel noise, and a semantic alignment term implemented via contrastive loss that directly regresses pairwise distances in the learned constellation to those in the foundation-model embedding space. The derivation of topological alignment follows from this contrastive regularizer. We have added a one-sentence summary of the alignment component to the revised abstract. revision: yes
-
Referee: [Abstract] Abstract: The manuscript states that the error phenomenon is 'theoretically and empirically characterized' yet supplies neither the theoretical analysis (e.g., any distance or topology metric) nor quantitative experimental results (performance curves, tables, or SNR comparisons) needed to evaluate whether the triple-loss actually produces the claimed structured constellations or outperforms baselines.
Authors: Section 4 provides the theoretical characterization, defining distance-based metrics for Semantic Drift (symbolic) and Structural Distortion (perceptual) along with a topology-preservation analysis. Section 5 contains the empirical evaluation, including SNR performance curves, tables comparing against fixed-constellation baselines, and ablation studies on the triple-loss components. To address the concern, we have inserted brief references to these sections and key quantitative outcomes into the revised abstract. revision: yes
Circularity Check
No circularity; framework claims rest on proposed architecture without self-referential reductions
full rationale
The provided abstract and description introduce the STCC framework and STC encoder (residual MLP trained with triple-loss) as a design choice whose intended effect is stated directly. No equations, fitted parameters renamed as predictions, self-citations as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the text. The alignment claim is presented as a consequence of the architecture rather than derived by construction from inputs that presuppose the same alignment. This is the common case of a self-contained proposal whose validity can be assessed externally via experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Semantic Communications: Overview, Open Issues, and Future Research Directions,
X. Luo, H.-H. Chen, and Q. Guo, “Semantic Communications: Overview, Open Issues, and Future Research Directions,”IEEE Wireless Communications, vol. 29, no. 1, pp. 210–219, 2022
2022
-
[2]
A Paradigm Shift toward Semantic Communications,
K. Niu, J. Dai, S. Yao, S. Wang, Z. Si, X. Qin, and P. Zhang, “A Paradigm Shift toward Semantic Communications,”IEEE Communica- tions Magazine, vol. 60, pp. 113–119, 2022
2022
-
[3]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” in North American Chapter of the Association for Computational Linguis- tics, 2019
2019
-
[4]
Taming Transformers for High- Resolution Image Synthesis,
P. Esser, R. Rombach, and B. Ommer, “Taming Transformers for High- Resolution Image Synthesis,”2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 12 868–12 878, 2020
2021
-
[5]
MaskGIT: Masked Generative Image Transformer,
H. Chang, H. Zhang, L. Jiang, C. Liu, and W. T. Freeman, “MaskGIT: Masked Generative Image Transformer,”2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11 305–11 315, 2022
2022
-
[6]
Design of Low-Density Parity Check Codes for 5G New Radio,
T. J. Richardson and S. Kudekar, “Design of Low-Density Parity Check Codes for 5G New Radio,”IEEE Communications Magazine, vol. 56, pp. 28–34, 2018
2018
-
[7]
Joint Source and Channel Coding,
M. Fresia, F. P ´erez-Cruz, H. V . Poor, and S. Verd ´u, “Joint Source and Channel Coding,”IEEE Signal Processing Magazine, vol. 27, pp. 104– 113, 2010
2010
-
[8]
Joint source- channel turbo decoding of entropy-coded sources,
A. Guyader, ´E. Fabre, C. M. Guillemot, and M. Robert, “Joint source- channel turbo decoding of entropy-coded sources,”IEEE J. Sel. Areas Commun., vol. 19, pp. 1680–1696, 2001
2001
-
[9]
Deep Joint Source- Channel Coding for Wireless Image Transmission,
E. Bourtsoulatze, D. B. Kurka, and D. G ¨und¨uz, “Deep Joint Source- Channel Coding for Wireless Image Transmission,”IEEE Transactions on Cognitive Communications and Networking, vol. 5, pp. 567–579, 2019
2019
-
[10]
Deep Learning Enabled Semantic Communication Systems,
H. Xie, Z. Qin, G. Y . Li, and B.-H. Juang, “Deep Learning Enabled Semantic Communication Systems,”IEEE Transactions on Signal Pro- cessing, vol. 69, pp. 2663–2675, 2020
2020
-
[11]
Deep Learning for Joint Source- Channel Coding of Text,
N. Farsad, M. Rao, and A. Goldsmith, “Deep Learning for Joint Source- Channel Coding of Text,” in2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 2326– 2330
2018
-
[12]
A perceptually mo- tivated approach for low-complexity speech semantic communication,
X. Chen, J. Wang, L. Xu, J. Huang, and Z. Fei, “A perceptually mo- tivated approach for low-complexity speech semantic communication,” IEEE Internet of Things Journal, vol. 11, no. 12, pp. 22 054–22 065, 2024
2024
-
[13]
Deep Joint Source Channel Coding for Wireless Image Transmission with OFDM,
M. Yang, C. Bian, and H.-S. Kim, “Deep Joint Source Channel Coding for Wireless Image Transmission with OFDM,”ICC 2021 - IEEE International Conference on Communications, pp. 1–6, 2021
2021
-
[14]
Semantic Communication System Based on Semantic Slice Models Propagation,
C. Dong, H. Liang, X. Xu, S. Han, B. Wang, and P. Zhang, “Semantic Communication System Based on Semantic Slice Models Propagation,” IEEE Journal on Selected Areas in Communications, vol. 41, pp. 202– 213, 2023
2023
-
[15]
MD- VSC—Efficient Wireless Model Division Video Semantic Communi- cation,
Z. Bao, H. Liang, C. Dong, C. Li, X. Xu, and P. Zhang, “MD- VSC—Efficient Wireless Model Division Video Semantic Communi- cation,”IEEE Internet of Things Journal, vol. 12, no. 2, pp. 1109–1124, 2025
2025
-
[16]
A Semantic Com- munication System for Point Cloud,
X. Liu, H. Liang, Z. Bao, C. Dong, and X. Xu, “A Semantic Com- munication System for Point Cloud,”IEEE Transactions on Vehicular Technology, vol. 74, no. 1, pp. 894–910, 2025
2025
-
[17]
Robust Semantic Communications for Speech Transmission,
Z. Weng, Z. Qin, and G. Y . Li, “Robust Semantic Communications for Speech Transmission,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[18]
Hierarchical V AE Based Semantic Communica- tions for POMDP Tasks,
D. Chen and W. Hua, “Hierarchical V AE Based Semantic Communica- tions for POMDP Tasks,” inICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 5540–5544
2024
-
[19]
Deep Joint Source- Channel Coding for Multi-Task Network,
M. Wang, Z. Zhang, J. Li, M. Ma, and X. Fan, “Deep Joint Source- Channel Coding for Multi-Task Network,”IEEE Signal Processing Letters, vol. 28, pp. 1973–1977, 2021
1973
-
[20]
Wireless Image Re- trieval at the Edge,
M. Jankowski, D. G ¨und¨uz, and K. Mikolajczyk, “Wireless Image Re- trieval at the Edge,”IEEE Journal on Selected Areas in Communications, vol. 39, pp. 89–100, 2020
2020
-
[21]
Collaborative Semantic Communication for Edge Inference,
W. F. Lo, N. Mital, H. Wu, and D. G ¨und¨uz, “Collaborative Semantic Communication for Edge Inference,”IEEE Wireless Communications Letters, vol. 12, pp. 1125–1129, 2023
2023
-
[22]
DeepJSCC-Q: Channel Input Constrained Deep Joint Source-Channel Coding,
T.-Y . Tung, D. B. Kurka, M. Jankowski, and D. G¨und¨uz, “DeepJSCC-Q: Channel Input Constrained Deep Joint Source-Channel Coding,” inICC 2022 - IEEE International Conference on Communications, 2022, pp. 3880–3885
2022
-
[23]
Image Semantic Communication over Fading Channel: A Learned Broadcast Approach,
K. Ma, S. Shao, and M. Tao, “Image Semantic Communication over Fading Channel: A Learned Broadcast Approach,” in2023 IEEE 24th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), 2023, pp. 66–70
2023
-
[24]
Joint Coding-Modulation for Digital Semantic Communications via Variational Autoencoder,
Y . Bo, Y . Duan, S. Shao, and M. Tao, “Joint Coding-Modulation for Digital Semantic Communications via Variational Autoencoder,”IEEE Transactions on Communications, vol. 72, no. 9, pp. 5626–5640, 2024
2024
-
[25]
Device-Edge Digital Semantic Communication with Trained Non-Linear Quantization,
L. Guo, W. Chen, Y . Sun, and B. Ai, “Device-Edge Digital Semantic Communication with Trained Non-Linear Quantization,” in2023 IEEE 97th Vehicular Technology Conference (VTC2023-Spring), 2023, pp. 1– 5
2023
-
[26]
sDAC—Semantic Digital Analog Converter for Semantic Communications,
Z. Bao, H. Liang, X. Liu, C. Li, C. Dong, X. Xu, C. Guo, H. Chen, and P. Zhang, “sDAC—Semantic Digital Analog Converter for Semantic Communications,”IEEE Transactions on Communications, vol. 73, no. 11, pp. 11 061–11 077, 2025
2025
-
[27]
OFDM-Based Digital Semantic Communication With Importance Awareness,
C. Liu, C. Guo, Y . Yang, W. Ni, and T. Q. S. Quek, “OFDM-Based Digital Semantic Communication With Importance Awareness,”IEEE Transactions on Communications, vol. 72, no. 10, pp. 6301–6315, 2024
2024
-
[28]
Communica- tion Beyond Transmitting Bits: Semantics-Guided Source and Channel Coding,
J. Dai, P. Zhang, K. Niu, S. Wang, Z. Si, and X. Qin, “Communica- tion Beyond Transmitting Bits: Semantics-Guided Source and Channel Coding,”IEEE Wireless Communications, vol. 30, pp. 170–177, 2021
2021
-
[29]
Joint Source-Channel Coding for Channel-Adaptive Digital Semantic Communications,
J. Park, Y . Oh, S. Kim, and Y .-S. Jeon, “Joint Source-Channel Coding for Channel-Adaptive Digital Semantic Communications,”IEEE Trans- actions on Cognitive Communications and Networking, vol. 11, no. 1, pp. 75–89, 2025
2025
-
[30]
Token Communications: A Large Model-Driven Framework for Cross-Modal Context-Aware Semantic Communications,
L. Qiao, M. B. Mashhadi, Z. Gao, R. Tafazolli, M. Bennis, and D. Niy- ato, “Token Communications: A Large Model-Driven Framework for Cross-Modal Context-Aware Semantic Communications,”IEEE Wireless Communications, vol. 32, no. 5, pp. 80–88, 2025
2025
-
[31]
Adaptive Semantic Token Communication for Transformer-based Edge Inference,
A. Devoto, J. Pomponi, M. Merluzzi, P. D. Lorenzo, and S. Scardapane, “Adaptive Semantic Token Communication for Transformer-based Edge Inference,”ArXiv, vol. abs/2505.17604, 2025
-
[32]
ToDMA: Large Model-Driven Token-Domain Multiple Access for Semantic Com- munications,
L. Qiao, M. B. Mashhadi, Z. Gao, R. Schober, and D. G ¨und¨uz, “ToDMA: Large Model-Driven Token-Domain Multiple Access for Semantic Com- munications,”ArXiv, vol. abs/2505.10946, 2025
-
[33]
Semantic Packet Aggregation for Token Communication via Genetic Beam Search,
S. Lee, J. Park, J. Choi, and H. Park, “Semantic Packet Aggregation for Token Communication via Genetic Beam Search,” in2025 IEEE 26th International Workshop on Signal Processing and Artificial Intelligence for Wireless Communications (SPAWC), 2025, pp. 1–5
2025
-
[34]
Text- Guided Token Communication for Wireless Image Transmission,
B. Liu, L. Qiao, Y . Wang, Z. Gao, Y . Ma, K. Ying, and T. Qin, “Text- Guided Token Communication for Wireless Image Transmission,” in 2025 IEEE/CIC International Conference on Communications in China (ICCC), 2025, pp. 1–6
2025
-
[35]
Attention is All you Need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is All you Need,” inNeural Information Processing Systems, 2017
2017
-
[36]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
L. McInnes and J. Healy, “UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction,”ArXiv, vol. abs/1802.03426, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
Decoupled Weight Decay Regularization,
I. Loshchilov and F. Hutter, “Decoupled Weight Decay Regularization,” inInternational Conference on Learning Representations, 2017
2017
-
[38]
Pointer Sentinel Mixture Models
S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointer Sentinel Mixture Models,”ArXiv, vol. abs/1609.07843, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[39]
ImageNet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” in2009 IEEE Conference on Computer Vision and Pattern Recognition, 2009, pp. 248–255
2009
-
[40]
Bleu: a Method for Automatic Evaluation of Machine Translation,
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a Method for Automatic Evaluation of Machine Translation,” inAnnual Meeting of the Association for Computational Linguistics, 2002
2002
-
[41]
The Un- reasonable Effectiveness of Deep Features as a Perceptual Metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The Un- reasonable Effectiveness of Deep Features as a Perceptual Metric,”2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 586–595, 2018
2018
-
[42]
Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank,
R. Socher, A. Perelygin, J. Wu, J. Chuang, C. D. Manning, A. Ng, and C. Potts, “Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank,” inConference on Empirical Methods in Natural Language Processing, 2013
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.