Flow Matching with In-Context Priors for Out-of-Distribution Brain Dynamics
Pith reviewed 2026-06-27 10:42 UTC · model grok-4.3
The pith
A diffusion transformer generates realistic fMRI dynamics for unseen cognitive tasks from language descriptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
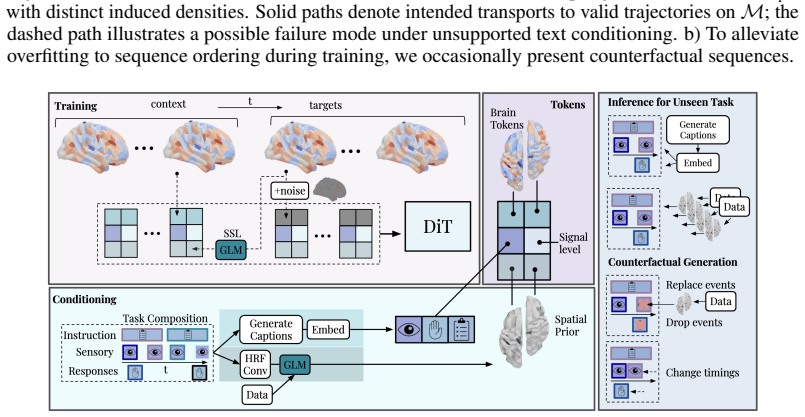
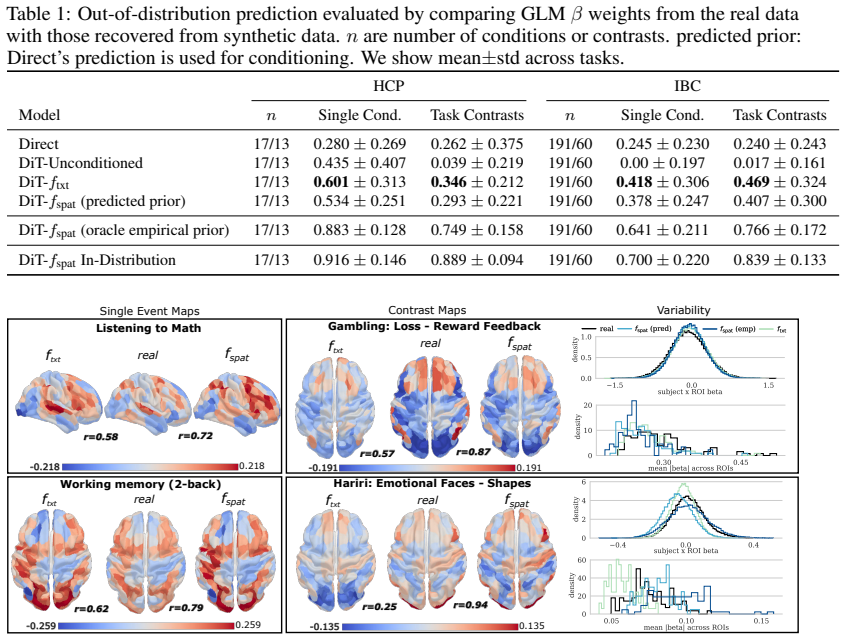
The per-timestep conditioned diffusion transformer injects compositional language and optional spatial priors in-context to generate whole-cortex fMRI dynamics during unseen cognitive tasks, recovering region-specific recruitment and spatial activation patterns from language alone.
What carries the argument
Per-timestep conditioned diffusion transformer that receives in-context compositional language descriptions of tasks together with optional spatial priors.
If this is right
- Language alone recovers region-specific recruitment across tasks and held-out spatial activation patterns.
- Spatial priors complement the text pathway by anchoring generation where language performance degrades.
- The model retains compositional structure needed for counterfactual task specification.
- Zero-shot generation enables in-silico design and evaluation of novel cognitive experiments before empirical validation.
- Predictive performance can be characterized relative to the training manifold across hundreds of held-out conditions.
Where Pith is reading between the lines
- The same in-context conditioning could be tested on other neural time-series modalities such as EEG or MEG.
- Generated dynamics could serve as synthetic training data to improve downstream decoding models for rare task conditions.
- Performance gaps between language-only and language-plus-spatial conditions could guide which tasks require new empirical recordings.
Load-bearing premise
In-context language descriptions of tasks supply enough compositional structure to support zero-shot generalization to unseen cognitive tasks outside the training distribution.
What would settle it
Empirical fMRI recordings for a held-out task that show spatial activation patterns substantially different from those produced by the model would falsify the claim of faithful generation.
Figures






read the original abstract
Flow matching and diffusion models enable conditional generation across domains ranging from images to proteins, with recent extensions to out-of-distribution contexts. Yet generative models of neural time series have largely remained restricted to categorical conditioning, precluding compositional and zero-shot generalization. In this work, we propose a per-timestep conditioned diffusion transformer for generating realistic fMRI brain dynamics during unseen cognitive tasks by injecting both compositional language and optional spatial priors in-context. Such zero-shot generation could enable counterfactual neuroscience by supporting in-silico design and evaluation of novel cognitive experiments before empirical validation. Leveraging this model, we evaluate across hundreds of held-out task conditions and characterize predictive performance in relation to the training manifold. From language alone, the model recovers region-specific recruitment across tasks and held-out spatial activation patterns. Spatial priors, when available, complement the text pathway by anchoring generation in regions of task space where language alone degrades, while retaining the compositional structure needed for counterfactual task specification. To our knowledge this is the first generative model of whole-cortex fMRI dynamics for unseen cognitive tasks, advancing counterfactual neuroscience and data-driven experimental design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a per-timestep conditioned diffusion transformer that uses flow matching to generate whole-cortex fMRI time series for unseen cognitive tasks. Conditioning is performed in-context via compositional language descriptions of tasks together with optional spatial priors. The central claim is that language alone recovers region-specific recruitment patterns and held-out spatial activations, while spatial priors anchor generation in regions where language degrades, thereby enabling zero-shot compositional generalization and counterfactual neuroscience applications. Performance is characterized relative to the training manifold across hundreds of held-out task conditions.
Significance. If the empirical claims hold, the work would represent a meaningful advance over categorical conditioning in generative models of neural dynamics by demonstrating compositional zero-shot extrapolation to novel tasks. This could support in-silico experimental design. However, the absence of any quantitative results, ablations, or task-dissimilarity metrics in the manuscript makes it impossible to assess whether the claimed generalization is achieved or whether the language pathway supplies the required compositional structure.
major comments (3)
- [Abstract] Abstract: the claims that 'from language alone, the model recovers region-specific recruitment across tasks and held-out spatial activation patterns' and that 'spatial priors complement the text pathway' are presented without any quantitative results, error bars, dataset sizes, evaluation metrics, or methodology. These statements are load-bearing for the central claim yet rest on unspecified empirical evaluations.
- [Abstract] Abstract: no measure of task dissimilarity (embedding distances, feature-space separation, or convex-hull analysis) between training and held-out conditions is supplied. Without this, it cannot be determined whether the reported generalization constitutes zero-shot compositional extrapolation or merely interpolation within the training manifold, directly affecting the validity of the OOD claim.
- [Abstract] Abstract: the manuscript states that performance is 'characterized relative to the training manifold' but provides neither the characterization procedure nor an ablation isolating the language pathway, leaving the complementarity claim and the necessity of spatial priors untestable from the given text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract requires additional quantitative support and will revise it to include specific metrics, error bars, dataset details, and references to the evaluation methodology. We will also incorporate task dissimilarity measures and clarify the characterization procedure and ablations in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims that 'from language alone, the model recovers region-specific recruitment across tasks and held-out spatial activation patterns' and that 'spatial priors complement the text pathway' are presented without any quantitative results, error bars, dataset sizes, evaluation metrics, or methodology. These statements are load-bearing for the central claim yet rest on unspecified empirical evaluations.
Authors: We agree the abstract is too concise on these points. In the revision we will expand it to report concrete quantitative results (e.g., mean Pearson correlation and standard deviation across held-out tasks), dataset sizes (number of subjects and total held-out conditions), and the primary evaluation metrics, while directing readers to the Methods and Results sections for full methodology. revision: yes
-
Referee: [Abstract] Abstract: no measure of task dissimilarity (embedding distances, feature-space separation, or convex-hull analysis) between training and held-out conditions is supplied. Without this, it cannot be determined whether the reported generalization constitutes zero-shot compositional extrapolation or merely interpolation within the training manifold, directly affecting the validity of the OOD claim.
Authors: We acknowledge the importance of this validation. We will add a quantitative task-dissimilarity analysis (language-embedding distances and feature-space separation between training and held-out task conditions) to the revised manuscript, including a new figure or table that supports the zero-shot claim. revision: yes
-
Referee: [Abstract] Abstract: the manuscript states that performance is 'characterized relative to the training manifold' but provides neither the characterization procedure nor an ablation isolating the language pathway, leaving the complementarity claim and the necessity of spatial priors untestable from the given text.
Authors: The characterization procedure is detailed in Section 4.2 and the associated figures of the main text. We will add a concise description of the procedure to the abstract and include an explicit ablation isolating the language-only pathway versus the combined language-plus-spatial-priors setting to make the complementarity claim directly testable. revision: yes
Circularity Check
No circularity; empirical claims lack any derivation chain
full rationale
The manuscript text contains no equations, derivations, fitted-parameter predictions, or self-citations that could reduce any claimed result to its inputs by construction. The central assertions (language-conditioned recovery of region-specific recruitment and held-out spatial patterns) are presented solely as outcomes of empirical evaluation on held-out task conditions, with no load-bearing mathematical steps, uniqueness theorems, or ansatzes that reference prior author work. Because no derivation chain exists to inspect, the paper is self-contained against external benchmarks and receives the default non-finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brain-language fusion enables interactive neural readout and in-silico experimentation
Victoria Bosch, Daniel Anthes, Adrien Doerig, Sushrut Thorat, Peter König, and Tim Christian Kietzmann. Brain-language fusion enables interactive neural readout and in-silico experimentation. arXiv preprint arXiv:2509.23941,
-
[2]
Stéphane d’Ascoli, Jérémy Rapin, Yohann Benchetrit, Teon Brookes, Katelyn Begany, Joséphine Raugel, Hubert Banville, and Jean-Rémi King. A foundation model of vision, audition, and language for in-silico neuroscience.arXiv preprint arXiv:2605.04326,
-
[4]
URLhttps://arxiv.org/abs/2603.13361. Sam Gijsen and Kerstin Ritter. EEG-language pretraining for highly label-efficient clinical phenotyp- ing. InProceedings of the 42nd International Conference on Machine Learning. PMLR,
-
[5]
arXiv:2512.11582. Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
-
[6]
Kaplan, Benjamin Warner, Tanishq Mathew Abraham, and Paul S
Connor Lane, Mihir Tripathy, Leema Krishna Murali, Ratna Sagari Grandhi, Shamus Sim Zi Yang, Sam Gijsen, Debojyoti Das, Manish Ram, Utkarsh Kumar Singh, Cesar Kadir Torrico Villanueva, Yuxiang Wei, Will Beddow, Gianfranco Cortés, Suin Cho, Daniel Z. Kaplan, Benjamin Warner, Tanishq Mathew Abraham, and Paul S. Scotti. Scaling vision transformers for functi...
-
[7]
Scaling Vision Transformers for Functional MRI with Flat Maps
doi: 10.48550/arXiv.2510.13768. Accepted to ICML
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.13768
-
[8]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
-
[9]
Audioldm: Text-to-audio generation with latent diffusion models.arXiv preprint arXiv:2301.12503,
Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D Plumbley. Audioldm: Text-to-audio generation with latent diffusion models.arXiv preprint arXiv:2301.12503,
-
[10]
Scalable diffusion transformer for conditional 4d fmri synthesis.arXiv preprint arXiv:2511.22870,
Jungwoo Seo, David Keetae Park, Shinjae Yoo, and Jiook Cha. Scalable diffusion transformer for conditional 4d fmri synthesis.arXiv preprint arXiv:2511.22870,
-
[11]
Sample size evolution in neuroimaging research: An evaluation of highly-cited studies (1990–2012) and of latest practices (2017–2018) in high-impact journals
Denes Szucs and John PA Ioannidis. Sample size evolution in neuroimaging research: An evaluation of highly-cited studies (1990–2012) and of latest practices (2017–2018) in high-impact journals. NeuroImage, 221:117164,
1990
-
[13]
Julius Vetter, Jakob H Macke, and Richard Gao
URLhttps://arxiv.org/abs/2509.20822. Julius Vetter, Jakob H Macke, and Richard Gao. Generating realistic neurophysiological time series with denoising diffusion probabilistic models.Patterns, 5(9),
-
[14]
Yuxiang Wei, Yanteng Zhang, Xi Xiao, Chengxuan Qian, Tianyang Wang, and Vince D Calhoun. fmri-lm: Towards a universal foundation model for language-aligned fmri understanding.arXiv preprint arXiv:2511.21760,
-
[15]
Junfeng Xia, Wenhao Ye, Xuanye Pan, Xinke Shen, Mo Wang, and Quanying Liu. Brain-dit: A universal multi-state fmri foundation model with metadata-conditioned pretraining.arXiv preprint arXiv:2604.12683,
-
[16]
URL https: //www.biorxiv.org/content/10.1101/2025.04.12.648506v1. 13 A Dataset Details We combine four datasets that differ in subject count, task diversity, and recording structure. The Human Connectome Project (HCP; Barch et al. [2013]) provides approximately1,100 subjects across seven tasks, supporting held-out-subject evaluation. The Individual Brain ...
-
[17]
The resulting Direct maps are used both as a baseline in contrast-recovery analyses and as optional predicted spatial priors for the dynamics model
are widely-used in the neuroscience literature. The resulting Direct maps are used both as a baseline in contrast-recovery analyses and as optional predicted spatial priors for the dynamics model. 14 C Additional Model and Optimization Hyperparameters Table 3: Summary of model architecture, dropout probabilities, and optimization hyperparameters. Hyperpar...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.