Embodied-BenchClaw: An Autonomous Multi-Agent System for Embodied Spatial Intelligence Benchmark Construction
Pith reviewed 2026-06-27 09:47 UTC · model grok-4.3
The pith
An autonomous multi-agent system constructs embodied spatial intelligence benchmarks automatically through a five-stage pipeline with reduced manual effort.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
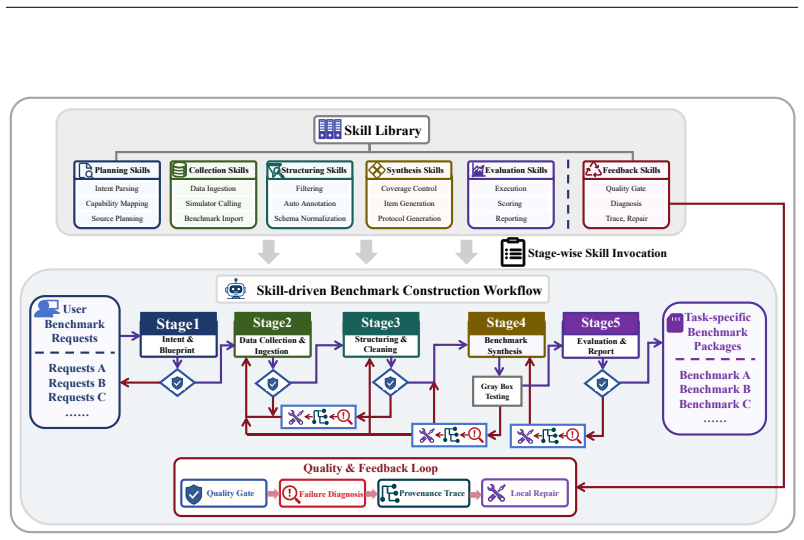
Embodied-BenchClaw is an autonomous agentic system that, given a user-specified evaluation intent, automatically produces a complete and continually updatable benchmark package through a five-stage pipeline coordinated by three agents for planning, construction, and evaluation. It introduces an extensible Skill Library and process quality control to enable benchmark construction that is composable, verifiable, and repairable. The system instantiates multiple benchmarks covering indoor and outdoor spatial reasoning, robotic manipulation, quadruped navigation, UAV understanding, and static benchmark enhancement. Experiments using human evaluation, judge-based assessment, consistency checks, co
What carries the argument
A five-stage pipeline (intent blueprinting, data collection, structuring and cleaning, benchmark synthesis, evaluation reporting) coordinated by planning, construction, and evaluation agents, supported by an extensible Skill Library and process quality control.
If this is right
- Benchmarks can be continually updated as models improve without full manual redesign.
- The system supports construction across diverse embodied carriers and data sources including robots, quadrupeds, and UAVs.
- Resulting benchmarks are verifiable, executable, maintainable, and diagnostically useful.
- Manual effort for benchmark creation is reduced while maintaining quality through built-in controls.
Where Pith is reading between the lines
- This approach could allow benchmarks to evolve in tandem with model progress to avoid rapid saturation.
- Similar agent-coordinated pipelines might apply to benchmark construction in other AI evaluation domains beyond spatial tasks.
- The Skill Library could enable researchers to share and compose benchmark components across projects.
- On-demand benchmark creation tailored to specific evaluation intents becomes feasible for targeted model testing.
Load-bearing premise
The five-stage pipeline coordinated by the three agents produces benchmarks whose quality and diagnostic utility can be reliably assessed and maintained without substantial post-hoc human correction or domain-specific tuning.
What would settle it
Independent human experts review the generated benchmarks and find that a large fraction contain errors, fail executability checks, or lack diagnostic power, requiring extensive manual fixes beyond the described process.
Figures


read the original abstract
Benchmarks are essential for evaluating embodied spatial intelligence, yet their construction is labor-intensive, hard to reuse, and difficult to maintain. Existing embodied benchmarks are often static and may quickly become saturated as models improve, limiting their ability to distinguish new capabilities. We propose Embodied-BenchClaw, an autonomous agentic system for constructing embodied spatial intelligence benchmarks. Given a user-specified evaluation intent, Embodied-BenchClaw automatically produces a complete and continually updatable benchmark package through a five-stage pipeline: intent blueprinting, data collection, structuring and cleaning, benchmark synthesis, and evaluation reporting. The pipeline is coordinated by three agents for planning, construction, and evaluation. To improve reusability and reliability, Embodied-BenchClaw introduces an extensible Skill Library and process quality control, enabling benchmark construction to be composable, verifiable, and repairable. We instantiate multiple benchmarks covering indoor spatial reasoning, outdoor spatial reasoning, robotic manipulation, quadruped robot navigation, UAV/aerial-view understanding, and static benchmark enhancement. These benchmarks span diverse embodied carriers, data sources, and spatial capabilities. Experiments with human evaluation, judge-based assessment, consistency checks, cost analysis, and ablations show that Embodied-BenchClaw can construct verifiable, executable, maintainable, and diagnostically useful embodied spatial benchmarks with reduced manual effort.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Embodied-BenchClaw, an autonomous multi-agent system for automated construction of embodied spatial intelligence benchmarks. Given a user-specified intent, a five-stage pipeline (intent blueprinting, data collection, structuring and cleaning, benchmark synthesis, evaluation reporting) coordinated by three agents (planning, construction, evaluation) produces complete, updatable benchmark packages. An extensible Skill Library and process quality control are introduced to ensure composability, verifiability, and repairability. The system is instantiated across indoor/outdoor spatial reasoning, robotic manipulation, quadruped navigation, UAV understanding, and static benchmark enhancement. Experiments using human evaluation, judge-based assessment, consistency checks, cost analysis, and ablations are claimed to show that the system yields verifiable, executable, maintainable, and diagnostically useful benchmarks with reduced manual effort.
Significance. If the experimental claims are substantiated with quantitative evidence, the work could have substantial impact by shifting embodied benchmark creation from labor-intensive manual processes to automated, maintainable pipelines. This addresses saturation of static benchmarks and enables continual updates as models advance, potentially improving evaluation of spatial capabilities across diverse embodied platforms. The multi-agent coordination and Skill Library represent a structured approach to reusable benchmark engineering.
major comments (3)
- [Abstract / Experiments section] Abstract and § Experiments (or equivalent results section): the manuscript asserts that 'experiments with human evaluation, judge-based assessment, consistency checks, cost analysis, and ablations show' positive outcomes, yet supplies no quantitative metrics, sample sizes, error bars, statistical tests, or raw data tables. Without these, it is impossible to determine whether the central claim—that the five-stage pipeline produces high-quality benchmarks with reduced manual effort—is supported or affected by post-hoc choices.
- [Pipeline / System Architecture section] § Pipeline description (five-stage pipeline and agent coordination): the description of the three-agent system, Skill Library, and process quality control remains at a high architectural level with no pseudocode, prompt templates, decision thresholds, or failure-mode handling. This leaves the weakest assumption—that the pipeline delivers verifiable benchmarks without substantial unaccounted human correction or domain-specific tuning—unexamined by concrete evidence.
- [Instantiation / Evaluation sections] Instantiation and evaluation sections: multiple benchmarks are instantiated across carriers and data sources, but no details are provided on exclusion criteria, inter-annotator agreement for human evaluations, or how 'diagnostically useful' is operationalized and measured. This makes it difficult to assess reproducibility or the strength of the maintainability claim.
minor comments (2)
- [System Architecture] Clarify the exact division of labor among the three agents and how conflicts or quality-control failures are resolved and logged.
- [Instantiation] Provide a table summarizing the instantiated benchmarks, their spatial capabilities, data sources, and carrier types for quick reference.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. The comments highlight important areas where additional details and quantitative evidence are needed to strengthen the manuscript. We address each major comment below and commit to substantial revisions to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract / Experiments section] Abstract and § Experiments (or equivalent results section): the manuscript asserts that 'experiments with human evaluation, judge-based assessment, consistency checks, cost analysis, and ablations show' positive outcomes, yet supplies no quantitative metrics, sample sizes, error bars, statistical tests, or raw data tables. Without these, it is impossible to determine whether the central claim—that the five-stage pipeline produces high-quality benchmarks with reduced manual effort—is supported or affected by post-hoc choices.
Authors: We agree with this assessment. The current manuscript presents the experimental claims at a high level without the supporting quantitative details. In the revised version, we will add comprehensive results sections including quantitative metrics from human evaluations, judge-based assessments, consistency checks, cost analyses, and ablations. These will include sample sizes, error bars, statistical tests, and data tables to allow proper evaluation of the claims. revision: yes
-
Referee: [Pipeline / System Architecture section] § Pipeline description (five-stage pipeline and agent coordination): the description of the three-agent system, Skill Library, and process quality control remains at a high architectural level with no pseudocode, prompt templates, decision thresholds, or failure-mode handling. This leaves the weakest assumption—that the pipeline delivers verifiable benchmarks without substantial unaccounted human correction or domain-specific tuning—unexamined by concrete evidence.
Authors: We acknowledge that the system architecture is described at an architectural level. To provide more concrete evidence, the revised manuscript will include pseudocode for the multi-agent coordination, representative prompt templates for each agent, specific decision thresholds used in quality control, and detailed descriptions of failure-mode handling and repair processes. This will better substantiate the pipeline's reliability. revision: yes
-
Referee: [Instantiation / Evaluation sections] Instantiation and evaluation sections: multiple benchmarks are instantiated across carriers and data sources, but no details are provided on exclusion criteria, inter-annotator agreement for human evaluations, or how 'diagnostically useful' is operationalized and measured. This makes it difficult to assess reproducibility or the strength of the maintainability claim.
Authors: We will revise the instantiation and evaluation sections to include the requested details: explicit exclusion criteria for generated benchmark items, inter-annotator agreement metrics (e.g., Cohen's kappa or similar) for human evaluations, and a clear definition and measurement protocol for 'diagnostically useful' benchmarks, including specific diagnostic metrics and how they are quantified. These additions will enhance the reproducibility and support for the maintainability claims. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents a system architecture and experimental results for an agentic benchmark construction pipeline. No equations, fitted parameters, derivations, or self-citations appear in the provided text. Claims rest on described outputs, human evaluations, and ablations rather than reducing to self-definitional inputs or author-overlapping citations. The derivation chain is self-contained with no load-bearing steps matching the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ben- chagents: Automated benchmark creation with agent interaction
Natasha Butt, Varun Chandrasekaran, Neel Joshi, Besmira Nushi, and Vidhisha Balachandran. Ben- chagents: Automated benchmark creation with agent interaction. InICLR 2025 Workshop on Navigating and Addressing Data Problems for Foundation Models,
2025
-
[2]
Jiafei Duan, Samson Yu, Hui Li Tan, Hongyuan Zhu, and Cheston Tan
URL https://arxiv.org/abs/2605.11887. Jiafei Duan, Samson Yu, Hui Li Tan, Hongyuan Zhu, and Cheston Tan. A survey of embodied ai: From simulators to research tasks.IEEE Transactions on Emerging Topics in Computational Intelligence, 6(2):230–244,
-
[3]
Lingyue Fu, Bolun Zhang, Hao Guan, Yaoming Zhu, Lin Qiu, Weiwen Liu, Xuezhi Cao, Xunliang Cai, Weinan Zhang, and Yong Yu. Automatically benchmarking llm code agents through agent- driven annotation and evaluation.arXiv preprint arXiv:2510.24358,
-
[4]
Huan-ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Yiran Wu, et al. A survey of self-evolving agents: On path to artificial super intelligence.arXiv preprint arXiv:2507.21046, 1,
-
[5]
Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations, volume 2024, pp
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations, volume 2024, pp. 54107–54157,
2024
-
[6]
Dynabench: Rethinking bench- marking in nlp
Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vidgen, Grusha Prasad, Amanpreet Singh, Pratik Ringshia, et al. Dynabench: Rethinking bench- marking in nlp. InProceedings of the 2021 conference of the North American chapter of the Association for Computational Linguistics: human language technologies, pp. 4110–4124,
2021
-
[7]
Chenxin Li, Zhengyang Tang, Huangxin Lin, Yunlong Lin, Shijue Huang, Shengyuan Liu, Bowen Ye, Rang Li, Lei Li, Benyou Wang, et al. Claw-eval-live: A live agent benchmark for evolving real-world workflows.arXiv preprint arXiv:2604.28139,
-
[8]
Autobencher: Towards declarative benchmark construction.arXiv preprint arXiv:2407.08351,
Xiang Lisa Li, Farzaan Kaiyom, Evan Zheran Liu, Yifan Mai, Percy Liang, and Tatsunori Hashimoto. Autobencher: Towards declarative benchmark construction.arXiv preprint arXiv:2407.08351,
-
[9]
Eureka: Human-level reward design via coding large language models.arXiv preprint arXiv:2310.12931,
13 Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayara- man, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Eureka: Human-level reward design via coding large language models.arXiv preprint arXiv:2310.12931,
-
[10]
Ajay Mandlekar, Soroush Nasiriany, Bowen Wen, Iretiayo Akinola, Yashraj Narang, Linxi Fan, Yuke Zhu, and Dieter Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations.arXiv preprint arXiv:2310.17596,
-
[11]
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of everyday tasks for gener- alist robots.arXiv preprint arXiv:2406.02523,
-
[12]
Rui Yang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja Venkat Koripella, Marziyeh Movahedi, Manling Li, et al. Embodiedbench: Comprehen- sive benchmarking multi-modal large language models for vision-driven embodied agents.arXiv preprint arXiv:2502.09560,
-
[13]
Shuo Yang, Wei-Lin Chiang, Lianmin Zheng, Joseph E Gonzalez, and Ion Stoica. Rethinking benchmark and contamination for language models with rephrased samples.arXiv preprint arXiv:2311.04850,
-
[14]
Self-rewarding language models.arXiv preprint arXiv:2401.10020,
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models.arXiv preprint arXiv:2401.10020,
-
[15]
A2eval: Agentic and automated evaluation for embodied brain
Shuai Zhang, Jiayu Hu, Zijie Chen, Zeyuan Ding, Yi Zhang, Yingji Zhang, Ziyi Zhou, Junwei Liao, Shengjie Zhou, Yong Dai, et al. A2eval: Agentic and automated evaluation for embodied brain. arXiv preprint arXiv:2602.01640, 2026a. Zhe Zhang, Runlin Liu, Aishan Liu, Xingyu Liu, Xiang Gao, and Hailong Sun. Code2bench: Scaling source and rigor for dynamic benc...
-
[16]
Webarena: A realistic web environment for build- ing autonomous agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for build- ing autonomous agents. InInternational Conference on Learning Representations, volume 2024, pp. 15585–15606,
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.